
python의 비동기를 나는 javascript의 비동기와 비교하여 이해하고 싶다. 특히 나는 nodejs 기반 서버 프로그래밍을 경험해본 적이 있어 그것과 비교하고 싶다. 우선 NodeJS로 비동기를 이해해보겠다.
비동기란?
“비동기”로 작업을 한다는 것은 동기로 작업을 수행한다는 것을 먼저 이해하는 것이 필요하다. “동기”로 작업 한다는 것은 다른 작업의 결과를 기다리며 일을 한다는 것이다.
이게 무슨말인가? 싶겠다. 그러므로 예시를 들어보자.
동기란?
현재 A task와 B task가 있다고 생각을 해보자. 상황을 가정해서 taskA는 runtime에서 직접 동작 해야하는 작업이고, taskB는 runtime 외부에서 동작해야하는 작업이라 하자. A task는 이렇게 동작한다.
taskA {
...
taskB
...
}task A를 수행하다가, task B를 호출해야하는 구조이다. 그럼 당연히 우리가 생각하기에는 “A task를 진행하다가, B task를 수행하고, B task가 끝나면, A task를 마저 마무리한다”가 자연스러운 흐름이겠다.
이 구조에서는 A task가 B task의 결과를 기다린다고 해석할 수 있다. 이게 너무 자연스럽다고 생각하는 것은 당연하다. 왜냐하면 우리가 작성하는 코드들은 대부분 이렇게 동작을 해왔기 때문이다. 그러면 계속 이렇게 작업을 하는게 무슨 문제가 있는가? 라고 질문이 떠오를텐데, task B가 오래 걸릴 경우 문제가 발생한다.
task C가 추가로 있다고 생각해보겠다.
taskA {
taskA_앞
taskB // 60분 걸림
taskA_뒤
}
taskC {
...
}나는 task A를 수행하고 task C를 수행하라고 명령을 내렸다. 하지만 task A가 60분이 걸리기 때문에, task C는 최소 60분이 지난 후에야 실행될 수 있을 것이다. 이것마저 너무 자연스러울 수 있는데, 만약에 task A와 task C가 전혀 상관없는 작업이라면 어떨까? task C는 task A보다 늦게 호출되었다는 이유로 지연이 되어야 한다. 이것은 실제 예시로 들자면 만약에 server에 여러 유저가 동시에 많은 요청을 보내는 경우에, 한 유저가 task A를 호출하게 되면 모든 다른 유저가 서버가 해당 작업을 마무리할 때까지 기다려야하는 문제가 발생한다.
이 문제는 task A가 task B의 결과를 기다려야하기 때문에 발생한다. 그럼 이렇게 해보면 어떨까?
taskA {
taskA_앞
rest_taskA_and_do_taskB(after_taskB-> taskA_뒤) // 60분 걸린 후, task A를 마저 수행해줘
}
taskC {
...
}task B를 호출한 후, task A는 잠시 쉬게 하는 것이다. 쉰다는 것과 기다리는 것은 조금 다른데, 기다리는 것은 thread가 일을 하는 중이라는 것, 쉰다는 것은 thread가 일을 하지 않는다는 것이다. task A는 task B가 끝나야 일을 할 수 있으므로, 잠시 쉬게하고 다른 일을 할 수 있는 상황으로 만드는 것이다. task B는 처음에 runtime 외부에서 동작을 한다고 가정했기 때문에 작업의 전체적인 진행과 연관이 없다. 그러므로 task B를 다른 어떤 장치의 도움을 받아 진행을 시키고, task C와 같은 다른 일을 처리할 수 있다.
이렇게 일하는 것을 “비동기”로 일을 한다고 한다. 그럼 이정도로 정리할 수 있겠다.
"기다리지 않고 다음 일부터 한다”
실제 예시
이를 이제 javascript에서 어떻게 구현하고 있는 지 보겠다.
console.log("1");
setTimeout(() => {
console.log("2 (비동기)");
}, 1000);
console.log("3");setTimeout 함수는 유명한 javascript 비동기 함수의 예시로, 일정시간을 기다린 후 “callback 함수”를 실행해주는 함수이다.
위에서 내가 설명한 예시와 동일한데, 이렇게 생각하면 좋다.
❗setTimeout 함수가 끝나면, callback 함수를 실행해줘. 나는 이 함수가 끝나길 기다려야 해서, 다음 일을 먼저 하도록 해.
그래서 위의 함수는 실행결과가 1, 3, 2 순서로 나오게 된다.
하지만 위의 callback 함수 형태를 요즘은 잘 사용하지 않는다. callback은 비동기 함수의 결과를 전달받아 사용해야하는 경우가 많은데, callback 함수에서 또 비동기 함수를 그 결과를 바탕으로 호출할 수 있다. 이 경우에 callback 지옥이라 하는 유명한 가독성 떨어지는 형태의 코드를 맞이하게 된다. 그래서 요즘은 promise기반의 async/await 형태로 비동기 함수를 호출한다.
async function main() {
try {
const result = await getData();
console.log(result);
} catch (err) {
console.error(err);
}
}근데 정확하게 async가 뭘까
필자는 이 내용이 항상 찜찜했다. 다들 알고 있는 내용이라고 생각하지만 조금 애매하게 알고 있는 경우가 있듯이, 나에게 async가 정확하게 그런 개념이었다. 그래서 조금 생각을 해봤다.
async는 일반적으로 “함수를 비동기 함수로 만들어 주는 keyword”라고 정의된다. 그럼 비동기로 일을 한다는 것은 결과를 기다리지 않고 가디릴 일이 생기면 다른 일을 할 수 있게 하는 것이니까 이런 상황을 가정해 보겠다.
function taskA() {
console.log("taskA 앞");
taskB();
console.log("taskA 뒤");
}
async function taskB() {
console.log("taskB 앞");
console.log("taskB 뒤");
}
taskA();이렇게 동작을 시키면, 이렇게 저 말에 따르면 이렇게 생각해볼 여지가 생긴다.
“taskB가 비동기 함수이니까, 이 함수의 결과를 기다리지 않겠지? 그러므로 taskB를 호출만하고 taskA를 모두 실행한 다음에 예약되어있던 taskB를 실행하겠지?”
하지만 해보면 알겠지만, 이렇게 동작하지 않는다. 결과는 taskA앞 → taskB앞 → taskB뒤→ taskA뒤 이렇게 동기적으로 수행된다. 어라? 라고 생각할 수 있는데, 우선 몇가지 헷갈릴 수 있는 점을 짚고 가자.
async가 붙었다고 해서 원래 동기적인 흐름이 비동기적으로 변경되지 않는다.
이건 어찌보면 당연한건데, async keyword를 붙였다고 해서 내가 작성한 모든 코드 내용이 흐름을 가지지 않는다면 원하는 코드를 작성할 수 없을 것이다. 우리가 원하는 것은 오래 걸리는 일이나 지금 말고 나중에 처리되어야 하는 일은 그 일이 끝날 때까지 기다리지말고 다른 일을 하게 해주자는 것이다.
비동기 함수도 호출이 되면 우선 반드시 callstack에 올라간다.
함수는 호출되면 그게 동기함수던지 비동기함수던지 반드시 바로 실행된다. 이를 실행하기 위해 call stack에 올라가 작업을 곧바로 시작한다. 비동기함수를 호출했다고 해서 결과를 안기다리기 때문에 본래 하던 작업을 계속 하는게 아니다.
우리는 이를 통해 async의 정의를 조금 더 자세하게 해볼 수 있겠다.
“함수가 비동기적인 흐름을 만들어 낼 수도 있게 만드는 keyword”
왜냐면 항상 비동기로 만들어 줄 것 같은 keyword이면서 그렇지 않았기 때문. 그럼 async를 붙여서 비동기 함수로 만든 taskB를 어떻게 비동기로 동작하게 할 수 있을까? 즉 어떻게 하면 taskB의 결과를 기다리지 않고 taskA가 마저 하던 일을 진행할 수 있을까?
Await의 등장
좋다. 그러면 이번에는 한줄을 추가한 상황을 가정해 보겠다.
function taskA() {
console.log("taskA 앞");
taskB();
console.log("taskA 뒤");
}
async function taskB() {
console.log("taskB 앞");
await 0; // Promise.resolve(0);
console.log("taskB 뒤");
}
taskA();async function 안에 await을 사용하지 않으면 가끔 경고 문구를 터미널 창에서 만날 수 있다. “이 함수는 async keyword를 사용했지만 아무런 효과가 없습니다”. 실제로 우린 방금 그런 상황에서 실험을 했었고, 그래서 과연 await을 안에 억지로라도 추가하면 어떤 일이 발생하는 지 봐보자.
taskA 앞
taskB 앞
taskA 뒤
taskB 뒤..! 정말로 taskB의 결과를 기다리지 않고 taskA가 마저 하던 일을 마무리 했다. 어떻게 이것이 가능했을까?
Promise
await keyword는 promise를 반환하는 함수 앞에 사용된다. promise를 간단하게 설명하자면 callback 지옥을 좀 더 가독성 좋게 읽기 위해서 개발자들이 고안해낸 방법으로, 미래의 어느 시점에 작업이 성공했는지 실패했는지 결과를 주겠다는 ‘약속’을 객체로 표현한 것이다. 그래서 처음에는 pending 상태를 가지다 함수가 종료되면 결과에 따라 성공과 실패로 나뉘게 된다.
이를 비동기 처리에 어떻게 사용하게 되냐면, async function은 처음에 무조건 promise를 pending으로 먼저 반환을 한다. 이게 참 이해가 되면서도 안되는 내용인데, 반환을 해놓고 promise의 내용을 update 하기 위해서 function 내부 내용을 진행한다. 그니까 return을 했다고 해서 지금 당장 사용이 가능한 값은 아니란 것이다. 아직 함수가 진행중이라 성공했는지 실패했는지 알 수 없으니까. 그리고 나서 자신이 일을 다 했음을 처음에 return 했던 promise의 상태를 바꿈으로 처리한다.
await은 반드시 promise를 반환하는 함수 앞에 사용된다고 했다. promise가 pending이 아닌 다른 상태가 될 때까지 기다리겠다는 의미인 것이다.
Await은 그래서 어떻게 일을 하는건데
await은 우선 함수의 실행을 멈춘다. 그리고 await으로 호출한 비동기 함수를 호출한다. await 아래 부분은 기다리고 있는 비동기 함수의 결과가 resolve(성공)이라면 실행할 call back 함수로 설정하고 이를 event loop의 microtask queue에 등록한다. 그리고 지금 올라와있는 call stack의 stack frame을 파괴 시킨다. 전부 파괴시키는 건 아니고, 해당 async function 부분을 파괴시키는 것이다.
처음 접하는 내용이라면 뭐..뭐라고..? 라는 반응이 정상이다.
우선은 위의 코드가 어떻게 저런 결과를 만들었는지 부터 봐보자.
- taskA가 호출된다
- call stack에 taskA가 등록된다
- taskA 앞이 출력된다
- taskB가 호출되며 바로 promise 객체를 pending상태로 반환한다
- call stack에 taskB가 등록된다
- taskB 앞이 출력된다
- await에 의해 taskB 뒤 출력 부분이 microtask queue에 callback으로 등록되며 taskB의 stack frame이 call stack에서 파괴된다
- promise가 애초에 resolve된 상태로 주어졌기 때문에 곧바로 callback은 microtask queue에 수행 가능 상태로 들어오게 된다
- call stack에 남은 부분을 수행하게 된다. 남은 부분이란 task A 뒤를 출력하는 일이다
- call stack에 taskA를 전부 실행했으므로 taskA의 stack frame이 파괴된다. 그러므로 call stack은 빈다
- call stack이 비었기 때문에 event loop가 우선 microtask queue 가 비었는 지 확인한다
- microtask queue에 수행할 수 있는 callback 함수가 있어 call stack에 등록한다
- taskB 뒤가 출력된다
이를 이해하기 위해서 우리는 우선 event loop에 대해서 알아야 한다
Event loop는 뭔데
event loop는 자바스크립트의 비동기를 실제로 달성해주는 매커니즘이다. 웹 브라우저의 이벤트루프와 node의 이벤트루프가 조금 다른데, 웹 브라우저의 이벤트 루프가 더 간단하므로 우선 설명하겠다.
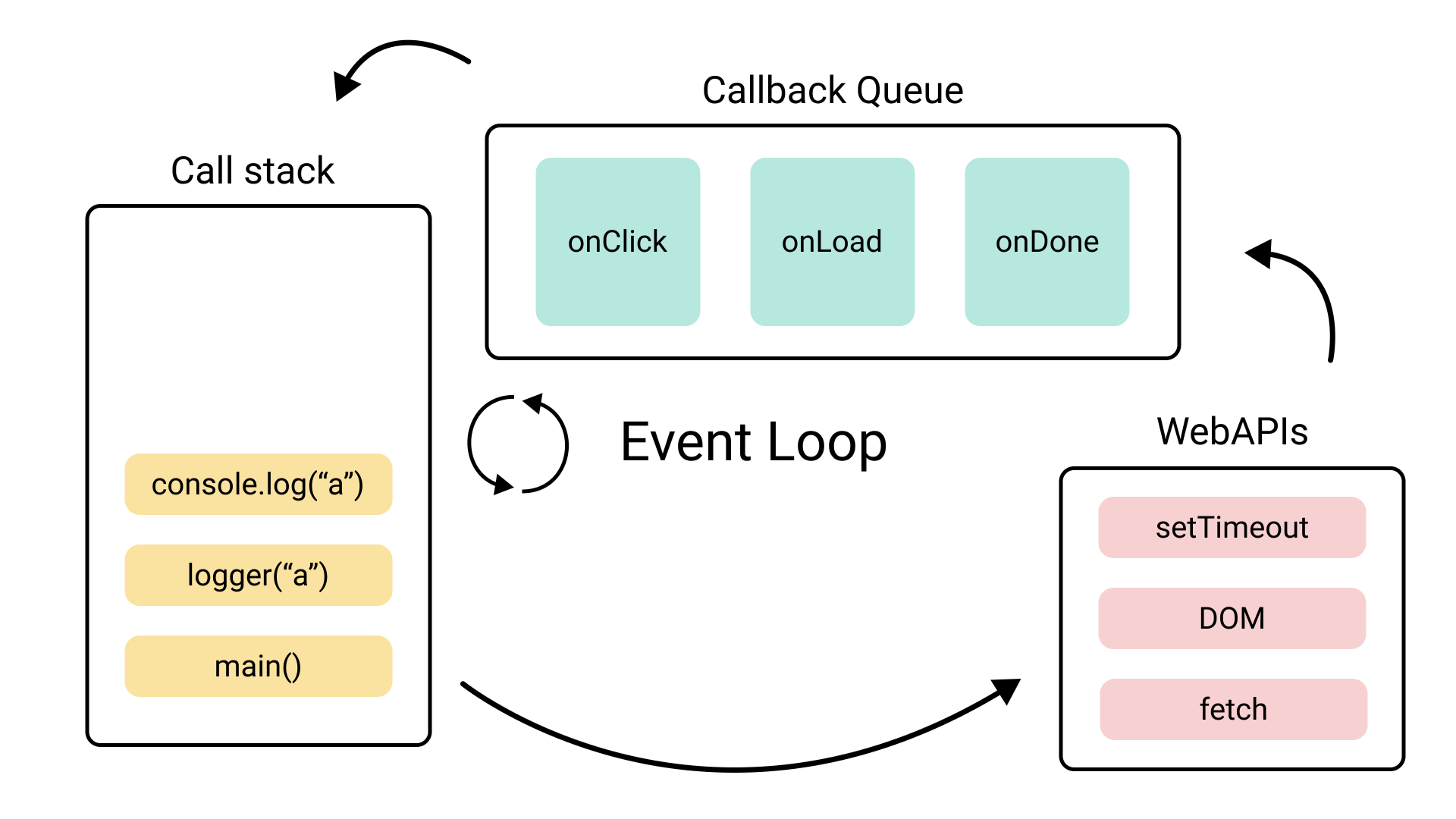
이벤트루프는 위의 4가지 구성요소를 가진다.
- Call Stack: 자바스크립트 함수 호출이 쌓이는 스택
- Web APIs: 타이머, 네트워크 요청 등을 처리하는 브라우저의 API / 비동기 작업을 수행함
- Callback Queue: 비동기 작업이 완료되면 해당 콜백 함수가 이 큐에 추가
- Event Loop: call stack이 비어 있을 때 callback queue에서 콜백 함수를 꺼내 call stack에 추가하여 실행
event loop는 간단히 말해서 call stack이 비면, callback queue에서 callback 함수를 실행해주는 매커니즘이다. 비동기 작업이 완료되면 등록되었던 callback 함수들은 callback queue에 쌓이게 되고, 이를 event loop가 감시하고 있다가 작업을 수행하게 된다.
하지만 다른 일들보다 더빨리 처리되어야 하는 일들이 간혹 있다. callback queue는 기본적으로 FIFO 구조이기 때문에 먼저 끝난 일이 무조건 먼저 실행되는 구조라 priority가 높은 작업을 먼저 수행할 수 없는 문제가 있다. 이를 위해 priority가 높은 multilevel queue 구조를 event loop구조에서 운영한다. 이 priority가 높은 queue우리는 microtask queue 라고 한다.
자 이제 위의 함수 실행을 이를 바탕으로 설명해보겠다.
-
await에 의해 taskB 뒤 출력 부분이 microtask queue에 callback으로 등록되며 taskB의 stack frame이 call stack에서 파괴된다
await으로 호출된 비동기 함수 task B가 존재하고 task A는 이 결과가 반환되어야 작업을 할 수 있으므로 비동기 함수 task A는 잠깐 쉬게 된다. 쉰다는 것은 call stack이 다른 일을 할 수 있도록 비켜주고, 나는 await이 끝나 callback 함수가 callstack에 올라왔을 때 일을 재개할 것이라는 의미이다. 그래서 callback 함수를 등록하기 위해 await 뒷부분을 callback 함수로 등록, call stack에서 비켜주기 위해 stack frame에서 호출한 함수를 파괴한다.
11. call stack이 비었기 때문에 event loop가 우선 microtask queue 가 비었는 지 확인한다
이것이 event loop의 핵심 동작이다. call stack이 비게되면 event loop는 수행 가능한 callback 함수를 찾아 call stack에 순차적으로 넣어 실행하게 된다.
await의 callback은 왜 microtask queue에 들어갈까? await을 한다는 것은 나의 작업이 오래걸릴 것 같기 때문에 다른 작업을 먼저 수행해도 되지만, 그렇다고 나의 일이 늦게 끝나길 바라는 것은 아니다. 마치 나의 작업은 동기 작업으로 이뤄지는 것처럼 순서대로 빠르게 진행되길 원한다. 그러므로 여타 다른 실제 I/O처리의 callback 함수와 다르게 반응성을 좋게 하기 위해 우선 처리가 된다.
Node.js의 event loop는 뭐가 다른데
node.js의 event loop는 브라우저의 event loop보다 복잡하다. node.js는 서버로 사용하기 위해서 만들어진 javascript runtime이기 때문에 운영체제를 통한 시스템 레벨 작업을 동반하는 경우가 많다. 그러므로 event loop가 관리하는 callback queue가 조금 더 복잡하게 관리되어야 하고, 브라우저에서 비동기 처리를 담당하는 web apis가 있듯이 시스템과 통신하며 비동기 처리를 담당해줄 무언가가 있어야 한다.
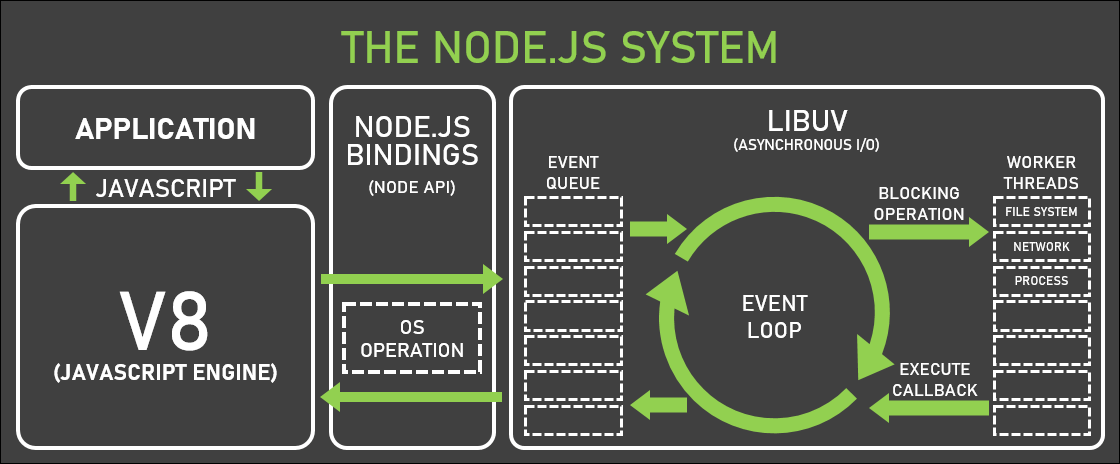
이를 위해 Libuv라고 하는 C library를 node는 사용한다. libuv는 몇가지 특징을 가진다.
event queue가 총 6개의 phase로 이루어져 있고, 이를 round robin으로 순회하면서 일을 처리한다. 우선적으로 처리해야하는 일을 위해 마찬가지로 microtask queue를 운영한다
| Phase | 설명 | 대표 예시 |
|---|---|---|
| 1. timers | setTimeout, setInterval에 설정된 시간이 지난 경우 콜백 실행 | setTimeout(() => ...) |
| 2. pending callbacks | 시스템 콜백 처리 (예: TCP 에러 후 처리) | 내부 콜백 |
| 3. idle, prepare | Node 내부 작업용 | 거의 사용하지 않음 |
| 4. poll | I/O 이벤트 대기 및 처리 (파일 읽기 등) | fs.readFile(...) |
| 5. check | setImmediate() 콜백 처리 | setImmediate(() => ...) |
| 6. close callbacks | close 이벤트 콜백 처리 | socket.on("close", ...) |
phase 중간 중간에 process.nextTick()과 microtask queue를 확인하고 있다면 우선적으로 실행한다. process.nextTick()은 가장 최우선적으로 실행해야하는 것, 그게 없다면 microtask queue에 담겨있는 일을 실행한다.
기본적으로 4개의 worker thread pool이 존재해서 CPU 작업이나 파일 시스템처럼 비동기 I/O가 어려운 작업을 백그라운드에서 멀티스레드로 처리한다
이것이 node.js가 시스템 레벨의 I/O 작업을 비동기로 처리할 수 있는 마법같은 힘이다. I/O와 같은 작업은 OS레벨의 시스템 콜이 필요한 경우가 많기 때문에 이와 관련된 작업은 javascript call stack에서 처리할 수 없다. 그러므로 이를 비동기적으로 요청해놓고 call stack은 I/O에 block되지 않고 영원히 일을 할 수 있다. 그래서 event loop 기반 node.js는 두 가지 특성을 가진다.
싱글스레드 - blocking 모델이다
call stack에 올라오는 코드가 cpu 집약적인 연산이 필요하다면 event loop는 callstack이 비지 않으므로 제대로 실행될 수 없을 것이다. 그래서 node.js는 이런 연산에 약하다.
non-blocking I/O 모델이다
하지만 수없이 많은 I/O 요청에도 callstack은 이것에 blocking 되지 않으므로 비동기 I/O처리에 굉장히 강력하다.
Python의 비동기
우선 기본적인 python의 동작 방식은 동기 + single thread 방식이다. 하지만 비동기 프로그래밍을 지원하기 위해서 python 3.4에서부터 asyncio library를 통해 event loop를 제공하기 시작했다. 그래서 python은 event loop가 자체 내장은 아니지만, library를 통해 제공한다.
import asyncio
def taskA():
print("taskA 앞")
taskB()
print("taskA 뒤")
async def taskB():
print('taskB 앞')
await asyncio.sleep(1)
print('taskB 뒤')
taskA()위와 같이 asyncio library를 import하면 async keyword를 사용할 수 있게 된다. 그럼 이제 node.js와 완전히 동일한 형태로 코드를 작성했기 때문에 동일하게 작동하길 기대하며 코드를 실행해 보겠다.
taskA 앞
taskA 뒤어라? 분명히 node와 동일한 구성으로 실행했는데 이번에는 taskB가 완전히 실행되지 않았다. 그 이유는 python의 async/await이 javascript의 그것과 다른 의미를 가지기 때문이다. python의 async function은 await 없이 호출 시 coroutine 객체를 만드는 것 외에는 아무런 동작을 하지 않는다. await keyword를 앞에 작성해야만 coroutine을 수행하게 된다.
Coroutine?
그럼 coroutine에 대하여 먼저 알아보자.
main routine + sub routine
우리가 일반적으로 알고 있는 함수의 흐름은 main + sub routine으로 표현한다. main routine에서 다른 함수를 호출하면, sub routine으로 함수가 호출되는 구조이다. 그래서 sub routine 함수가 실행이 완료될 때까지 main routine은 함수를 추가로 실행하지 않으며, sub routine은 main routine에 종속적인 관계라 호출 하는 쪽과 호출 당하는 쪽이 정해져있다.
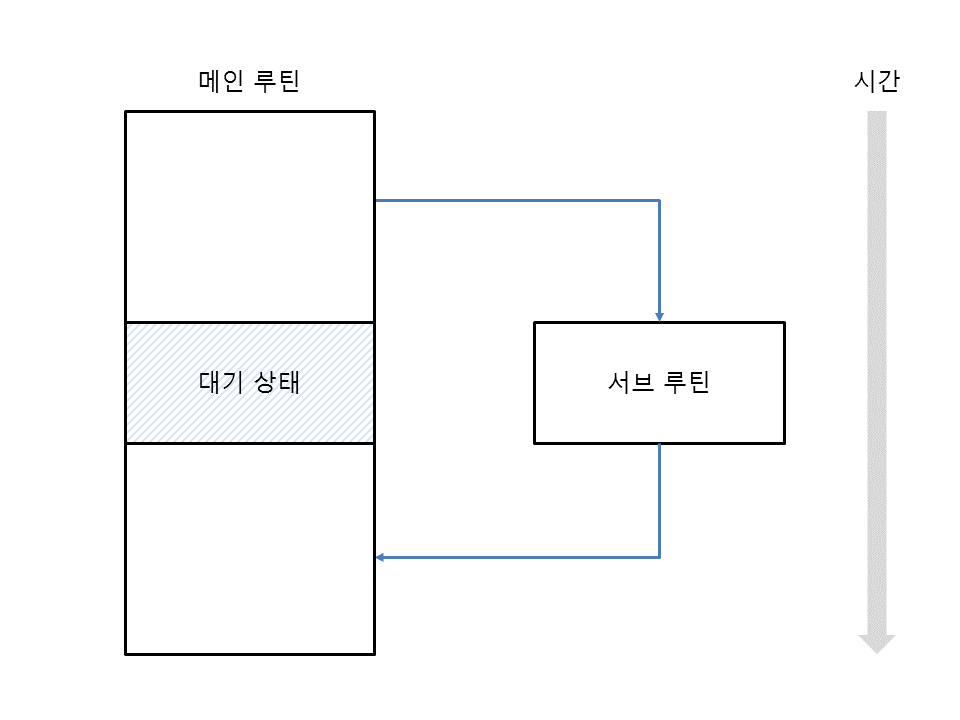
coroutine
반면 coroutine은 두 함수가 대등한 관계이다. 서로가 서로를 호출하는 관계이다. 간단하게 생각해서 여러 스레드 흐름이 하나의 스레드에서 동작하는 상태인 것이다. 그래서 coroutine을 경량 스레드라고 표현한다. thread와 달리 context switching 과 같은 overhead 없이 한 thread 내에서 여러 thread를 활용하는 효과를 내기 때문이다. coroutine은 thread 혹은 process scheduling과 다르게 반드시 non-preemptive이다. 하나의 coroutine에서 다른 coroutine에게 thread를 넘겨줄 때까지 다른 coroutine은 일을 하지 못한다. 그래서 동시성 제어에 대한 권한을 온전히 개발자가 가지게 된다. 이것은 개발의 복잡성을 올리는 단점이기도 하면서, 여러 능동적인 대처가 가능하게 하는 장점이기도 하다.
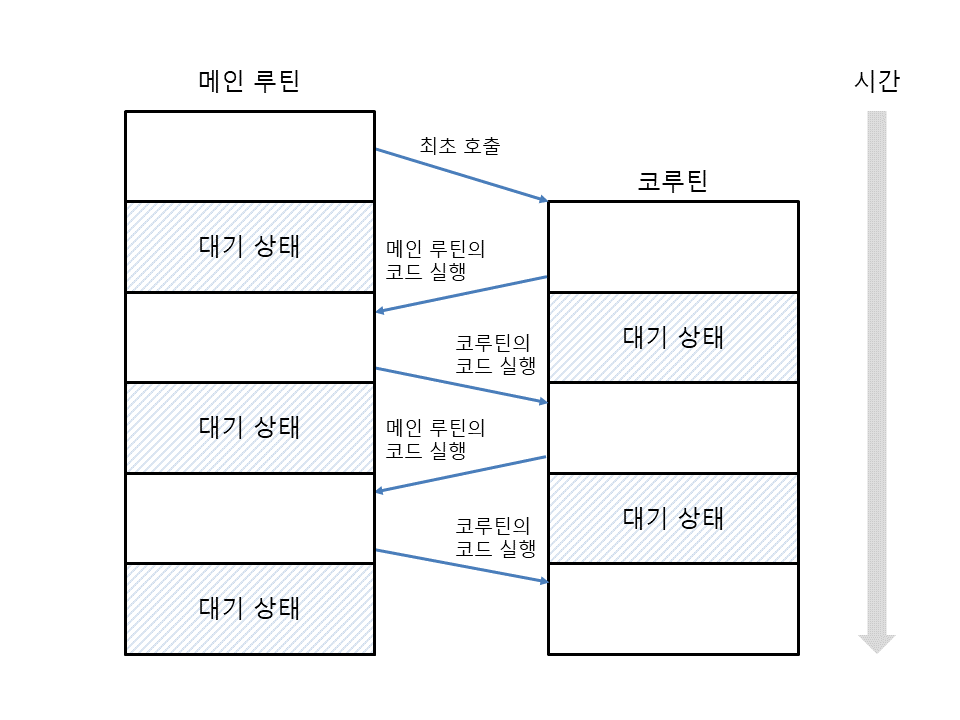
Corutine & event loop
import asyncio
async def taskA():
print("taskA 앞")
await taskB()
print("taskA 뒤")
async def taskB():
print('taskB 앞')
await asyncio.sleep(1)
print('taskB 뒤')
asyncio.run(taskA())다시 원래 코드로 들어와서, 코드를 제대로 동작시키기 위해 await을 추가해봤다. javascript와 비슷한 점은 await은 async 함수의 실행을 멈춘다는 점이고, 다른 점은 callback 함수를 사용하지 않는다는 것이다.
뭐라? callback 함수 없이 어떻게 비동기적인 흐름을 만들 수 있는거지? 싶겠지만 원리는 비슷하다. coroutine 하나 하나의 단위를 task라고 부르는데, task에 원래 함수를 저장하고 어디서부터 다음 호출 때 실행되어야 하는지가 저장된다. 그래서 해당 coroutine이 해당 함수를 다시 호출하거나 함수가 종료될 때까지 실행되는 것이다.
여기서 조금 차이점이 들어나게 되는데, node js는 비동기 함수 완료라는 event가 생기면, callback 함수를 실행하는 느낌이고 python asyncio는 coroutine을 재개하는 느낌이다. 새로운 함수를 실행하는 것과 재개하는 것의 차이 정도인듯 하다. 이걸 nodejs는 call stack이 비었을 때 callback queue를 확인하는 것이고, python asyncio는 수행중인 task가 없으면 ready list에서 수행가능한 task를 가져오는 것이다.
Python vs Node
python은 coroutine간의 협력적 멀티태스킹을 통해 비동기적인 흐름을 만들어 낸 것이다. 과거의 python에도 coroutine을 이용하기 위해 함수의 흐름을 멈추는 방식이 있었기에 가능한 방식이다. 애초에 함수의 흐름을 자유롭게 다루는 방식에서 비동기 처리가 발전했기 때문에 이를 통해 python은 조금 더 세밀한 비동기 컨트롤이 가능해진다. create_task를 통해 event loop에 task를 등록할 수 있고, await으로 coroutine간의 체이닝으로 비동기 흐름을 만들 수도 있다. 명시적으로 여기서 coroutine을 잠시 멈추고 이벤트 루프에게 제어권을 넘기겠다고 선언할 수도 있다.
하지만 nodejs에 비해 python asyncio는 coroutine의 비동거 처리를 위한 absraction layer가 깊기 때문에 (python은 비동기 처리를 목적으로 만들어진 언어가 아니므로) 이를 처리하는 데에 overhead가 발생하고, memory에 coroutine frame을 모두 유지해야해서 메모리 사용량도 많다. 그리고 libuv와 같은 강력한 C 라이브러리에 도움을 받아 I/O를 처리하는 node에 반해 python은 OS의 기능에 거의 의존하기 때문에 I/O 성능이 Node에 비해 떨어진다.
결론
- 서버에서 필요로 하는 연산이 많지 않다
- 대부분의 api서버의 경우 서버 자체에서 계산하는 것이 많이 필요하진 않다
- 주로 I/O 처리만을 담당하는 서버이다
- Node 는 non-blocking I/O model로 설계되었다
- AI를 사용하지 않는 서버이다
- 머신러닝.. javascript에게는 조금 어려울지도..
이런 대부분의 경우에서는 Node 서버를 사용하는 것이 훨씬 유리히다. python은 복잡한 연산이나 강력한 library의 도움을 받아야할 때 사용하는 것이 좋을 것 같다. django만 해도 기본 내장 admin page가 워낙 잘 되어 있어서 개발 공수를 줄여주지 않는가? ‘이런 것도 다 준비되어있어..?’의 최강주자가 python이기 때문에 그럴 것 같다.
나는 전에 AI model을 서빙하는 django server 개발에서 위에 공부했던 동기/비동기, blocking/non-blocking과 같은 개념이 많이 헛갈려서 삽질을 했던 경험이 있었다. 이참에 한번에 다 정리하니 속이 시원하다.
