
업무상 텍스트 데이터 포멧을 변경하는 일이 종종 있는데, pandas 패키지로 쉽게 변경이 가능함
당연히 pandas 패키지가 설치된 것을 가정하지만, 아닌 분들도 있기 때문에 설치 명령어도 아래 추가함 (파이선 패키지 입니다. 다른 언어는 안되요)
$ pip install pandas이번 포스터의 목표는 아래 요구사항을 만족하는 전처리를 할 계획입니다.
1. 원본 데이터의 포멧은 .tsv 형식으로 되어있으며, 변경할 포멧은 .csv 형식으로 변경
2. 원본 데이터 전체에서 필요한 몇 개의 컬럼만 사용하여 전처리
3. 컬럼의 헤더 이름 변경
4. 컬럼 포지션(순서) 변경
참고로, .csv, .tsv 포멧은 어떤 구분자를 사용하여 데이터를 구분할 것인지 차이입니다.
.csv: Comma-Separated-Values
.tsv: Tab-Separated-Values
이제 pandas를 사용하여 데이터 포멧을 변경해 봅시다.
예제 데이터는 glue라는 데이터 중 일부를 가져왔고. 아래 형태로 test_input.tsv 이름으로 사용합니다.
index genre filename year sentence1 sentence2 score
0 main-captions MSRvid 2012test A man with a hard hat is dancing. A man wearing a hard hat is dancing. 5.000
1 main-captions MSRvid 2012test A young child is riding a horse. A child is riding a horse. 4.750
2 main-captions MSRvid 2012test A man is feeding a mouse to a snake. The man is feeding a mouse to the snake. 5.000
3 main-captions MSRvid 2012test A woman is playing the guitar. A man is playing guitar. 2.400
4 main-captions MSRvid 2012test A woman is playing the flute. A man is playing a flute. 2.750
- 데이터 정보확인
import pandas as pd
df = pd.read_csv('test_input.tsv', sep='\t') # test_input.tsv 파일 읽기
df.info() # 정보 출력포멧상 문제도 없고, 7개의 컬럼으로 구성된 것, 각 컬럼의 이름과 데이터 타입도 확인할 수 있어요
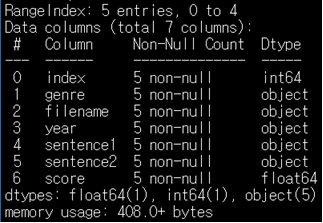
- 포멧을 .tsv 에서 .csv 로 변경
import pandas as pd
df = pd.read_csv('test_input.tsv', sep='\t') # test_input.tsv 파일 읽기
df.to_csv('test_output_1.csv',index=False) # test_output_1.csv 파일 쓰기 read/write 관련 명령어 1줄씩만 있으면 포멧 변경은 쉽게 되요
아래는 출력 결과입니다. tab에서 comma(,)로 값을 구분합니다.
index,genre,filename,year,sentence1,sentence2,score
0,main-captions,MSRvid,2012test,A man with a hard hat is dancing.,A man wearing a hard hat is dancing.,5.0
1,main-captions,MSRvid,2012test,A young child is riding a horse.,A child is riding a horse.,4.75
2,main-captions,MSRvid,2012test,A man is feeding a mouse to a snake.,The man is feeding a mouse to the snake.,5.0
3,main-captions,MSRvid,2012test,A woman is playing the guitar.,A man is playing guitar.,2.4
4,main-captions,MSRvid,2012test,A woman is playing the flute.,A man is playing a flute.,2.75
- 원본 데이터에서 필요한 몇 개의 컬럼만 읽어서 .csv 로 변경
(예제 코드는 index, sentence1, sentence2, score 컬럼 값만 사용해서 데이터를 가공해요)
import pandas as pd
#test_input.tsv 파일 읽기 + 특정 컬럼만 읽기
df = pd.read_csv('test_input.tsv', sep='\t', usecols=['index', 'sentence1','sentence2','score'])
df.to_csv('test_output_2.csv',index=False) # 특정 컬러만 파일에 쓰기read 명령어에서 옵션(usecols)으로 읽고 싶은 컬럼 이름을 추가하기만 하면 됩니다. 아래는 출력 결과에요.
index,sentence1,sentence2,score
0,A man with a hard hat is dancing.,A man wearing a hard hat is dancing.,5.0
1,A young child is riding a horse.,A child is riding a horse.,4.75
2,A man is feeding a mouse to a snake.,The man is feeding a mouse to the snake.,5.0
3,A woman is playing the guitar.,A man is playing guitar.,2.4
4,A woman is playing the flute.,A man is playing a flute.,2.75
- 헤더 이름 바꾸기
- 기존 헤더 정보: index, sentence1, sentence2, score
- 변경 헤더 정보: idx, sentence1, sentence2, label
import pandas as pd
df = pd.read_csv('test_input.tsv', sep='\t', usecols=['index', 'sentence1','sentence2','score']) #test_input.tsv 파일 읽기 + 특정 컬럼만 읽기
df.set_axis(['idx', 'sentence1','sentence2','label'], axis=1, inplace=True) #헤드 컬럼 이름 바꾸기
df.to_csv('test_output_3.csv',index=False) # 헤더 이름을 변경하여 특정 컬럼만 파일에 쓰기변경할 헤더 정보 명령어(set_axis) 한줄 추가해 주시면 변경됩니다.
아래는 출력 결과에요, 값은 그대로이지만 헤더 컬럼의 이름은 바뀌었습니다.
idx,sentence1,sentence2,label
0,A man with a hard hat is dancing.,A man wearing a hard hat is dancing.,5.0
1,A young child is riding a horse.,A child is riding a horse.,4.75
2,A man is feeding a mouse to a snake.,The man is feeding a mouse to the snake.,5.0
3,A woman is playing the guitar.,A man is playing guitar.,2.4
4,A woman is playing the flute.,A man is playing a flute.,2.75
- 컬럼 포지션 바꾸기
컬럼 순서 뿐 아니라 값들도 같이 다 옮겨 갈거에요. 컬럼의 순서는 아래처럼 변경 합니다.- 컬럼 포지션 변경 전: idx, sentence1, sentence2, label
- 컬럼 포지션 변경 후: sentence1, sentence2, label, idx
import pandas as pd
df = pd.read_csv('test_input.tsv', sep='\t', usecols=['index', 'sentence1','sentence2','score']) #test_input.tsv 파일 읽기 + 특정 컬럼만 읽기
df.set_axis(['idx', 'sentence1','sentence2','label'], axis=1, inplace=True) #헤더 이름 변경하기
df.to_csv('test_output_4.csv',index=False, columns=['sentence1','sentence2','label','idx']) #헤더 이름을 변경하고, 컬럼의 위치까지 변경하여 파일에 쓰기write 명령어에서 옵션(columns)을 추가하고, 변경한 헤더의 이름으로 원하는 순서대로 작성해 주시면 컬럼 위치를 쉽게 변경할 수 있습니다. 아래는 출력 결과입니다.
sentence1,sentence2,label,idx
A man with a hard hat is dancing.,A man wearing a hard hat is dancing.,5.0,0
A young child is riding a horse.,A child is riding a horse.,4.75,1
A man is feeding a mouse to a snake.,The man is feeding a mouse to the snake.,5.0,2
A woman is playing the guitar.,A man is playing guitar.,2.4,3
A woman is playing the flute.,A man is playing a flute.,2.75,4
가공전 원본 데이터랑 비교하면 많이 바뀌었네요,
적은 양의 데이터라면 이런 작업을 excel에서 해도 무방하지만,
2~3줄의 명령어로 원하는 포멧으로 변경가능하니 pandas로 효율성을 높여요
그럼 끝
