1. 소개 (Introduction)
Segment Anything Model (SAM)은 일반적인 이미지 분할에서 뛰어난 zero-shot 능력과 유연한 기하학적 프롬프트 활용성을 보여주며 등장과 동시에 큰 반향을 일으켰다. 하지만 SAM 역시 만능은 아니어서, 학습 데이터 분포에서 벗어나거나 데이터가 부족한 특정 도메인에서는 성능 저하를 보이곤 한다. 예를 들어 항공 이미지, 의료 이미지, 또는 X-ray, Sonar, SAR 이미지와 같은 non-RGB 이미지들이 여기에 해당된다.
기존에 SAM을 특정 도메인에 adaptation시키려는 연구들은 주로 fully supervised 방식을 사용했다. 이 방식은 대량의 레이블링된 학습 데이터를 필요로 하기 때문에, 실제 현장에서 데이터를 수집하고 가공하는 데 많은 비용과 시간이 소요되는 현실적인 어려움이 있었다.
이러한 배경에서, 이 논문은 CAT-SAM (ConditionAl Tuning network for few-shot adaptation of SAM)을 제안한다. CAT-SAM의 핵심 목표는 소량의 데이터(few-shot)만을 사용하여 다양한 downstream 도메인에 SAM을 데이터 효율적으로 적응시키는 것이다.
✨ 추천 자료:
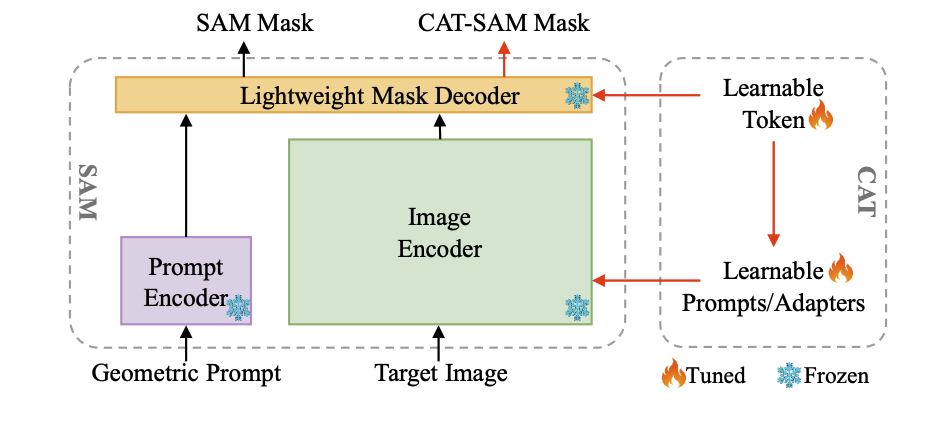
- 이해를 돕기 위해 논문의 Figure 1을 참고하면 CAT-SAM의 전체적인 구조를 파악하는 데 도움이 된다. 이 그림은 SAM과 CAT (Conditional Aligned Tuning) 모듈이 어떻게 상호작용하여 CAT-SAM 마스크를 생성하는지 보여준다.
2. Method
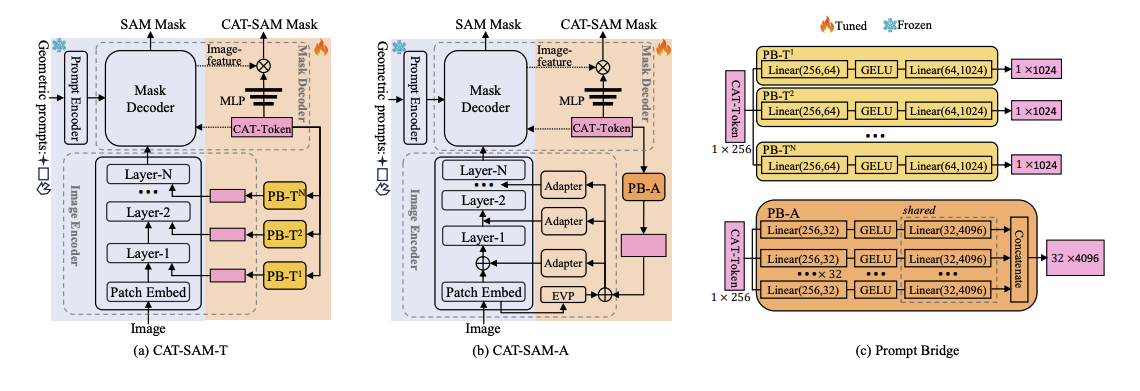
CAT-SAM은 SAM을 특정 도메인에 효과적으로, 그리고 데이터 효율적으로 적응시키기 위해 설계된 Conditional Tuning network이다. 이 논문의 핵심 아이디어는 SAM의 육중한 Image Encoder와 가벼운 Mask Decoder 간에 발생할 수 있는 tuning imbalance 문제를 해결하는 것이다. 이를 위해 "decoder-conditioned joint tuning"이라는 새로운 전략을 제시한다.
이 전략을 구현하기 위해 prompt bridge라는 구조를 설계했다. prompt bridge는 Mask Decoder에서 추출된 domain-specific features를 Image Encoder로 매핑하는 역할을 한다. 이를 통해 Image Encoder와 Mask Decoder가 서로 정보를 주고받으며 시너지 효과를 내어, 소량의 타겟 샘플만으로도 상호 보완적인 적응이 가능해진다.
CAT-SAM은 두 가지 주요 변형으로 개발되었다:
- CAT-SAM-T: Image Encoder의 입력 공간에 학습 가능한 learnable prompt tokens를 주입하는 방식이다.
- CAT-SAM-A: Image Encoder의 Transformer layers에 경량 adapter networks를 삽입하는 방식이다.
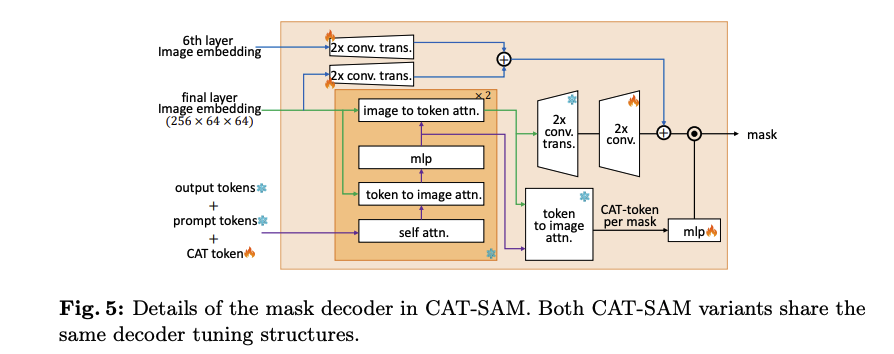
Mask Decoder 튜닝의 경우, 기존 SAM의 디코더는 고정시킨 상태로 둔다. 대신, 학습 가능한 CAT-Token을 새롭게 도입하여 SAM의 원래 출력 토큰 및 프롬프트 토큰과 concatenate하여 Mask Decoder의 입력으로 사용한다. 이 CAT-Token은 학습 과정에서 업데이트되며, 새롭게 추가된 3계층 MLP (Multi-Layer Perceptron)의 dynamic weights를 생성하는 데 활용된다. 최종적으로 이렇게 생성된 가중치와 이미지 특징들이 결합되어 타겟 마스크를 예측하게 된다.
파라미터 효율성 측면에서 CAT-SAM은 매우 가볍다. ViT-L 기반의 SAM과 비교했을 때, CAT-SAM-T는 약 1.1% (3.3M), CAT-SAM-A는 약 0.6% (1.9M)의 매우 적은 추가 파라미터만을 사용한다.
학습 시에는 사전 학습된 SAM의 파라미터는 freeze시키고, 새롭게 추가된 튜닝 모듈의 파라미터만 업데이트한다. 학습에는 bounding box, 무작위 선택점, 거친 마스크 등 다양한 종류의 기하학적 프롬프트를 혼합하여 사용한다. inference 시에는 먼저 적응된 Image Encoder를 통해 입력 이미지로부터 adaptive image embeddings를 생성한다. 이 임베딩은 SAM의 prompt encoder에서 나온 프롬프트 토큰과 결합되어 Mask Decoder의 입력으로 사용된다. 이후, 학습된 CAT-Token과 관련 MLP를 통해 최종 마스크를 예측한다.
3. 실험 결과 (Experimental Results)
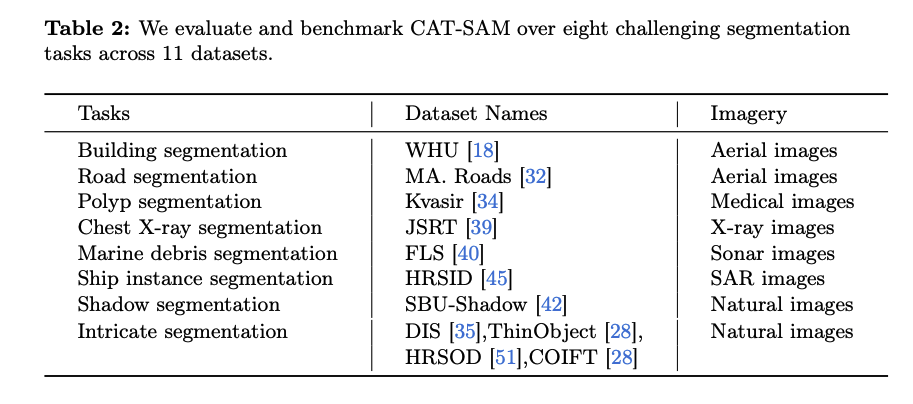
CAT-SAM의 성능은 8개의 다양한 분할 작업과 관련된 11개의 데이터셋을 대상으로 한 광범위한 실험을 통해 검증되었다. 실험에 사용된 데이터셋들은 SAM이 기존에 어려움을 겪었던 항공 이미지, 의료 이미지, 그리고 X-ray, Sonar, SAR 이미지와 같은 non-RGB 이미지 등 다양한 실제 환경의 도메인을 포함하고 있다.
평가 지표로는 단일 클래스 데이터셋 (WHU, Kvasir, SBU-Shadow, MA. Roads)에 대해서는 표준적인 mask Intersection over Union (IoU)를 사용했다. 다중 클래스를 포함하는 JSRT, FLS 데이터셋의 경우, 각 클래스별 IoU와 전체 클래스의 평균 IoU를 측정했다. 그 외 DIS, ThinObject, HRSOD, COIFT 데이터셋에서는 mIoU와 경계선 품질을 평가하는 mBIoU를, HRSID 데이터셋에서는 instance segmentation 성능을 나타내는 AP, AP50, AP75를 사용했다.
-
Ablation Studies: CAT-SAM-T와 CAT-SAM-A를 구성하는 각 모듈이 전체 성능에 얼마나 기여하는지 분석했다. 그 결과, 제안된 prompt bridge를 통한 조건부 공동 튜닝 방식이 Image Encoder와 Mask Decoder 간의 tuning imbalance를 효과적으로 완화하며, 일관되게 상당한 성능 향상을 가져오는 것을 확인했다. 단순히 각 부분을 독립적으로 튜닝하는 것보다 우수한 결과를 보였다.
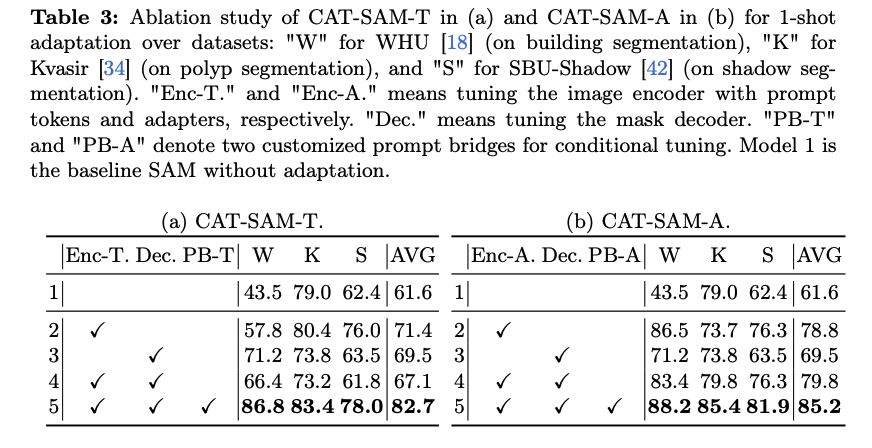
-
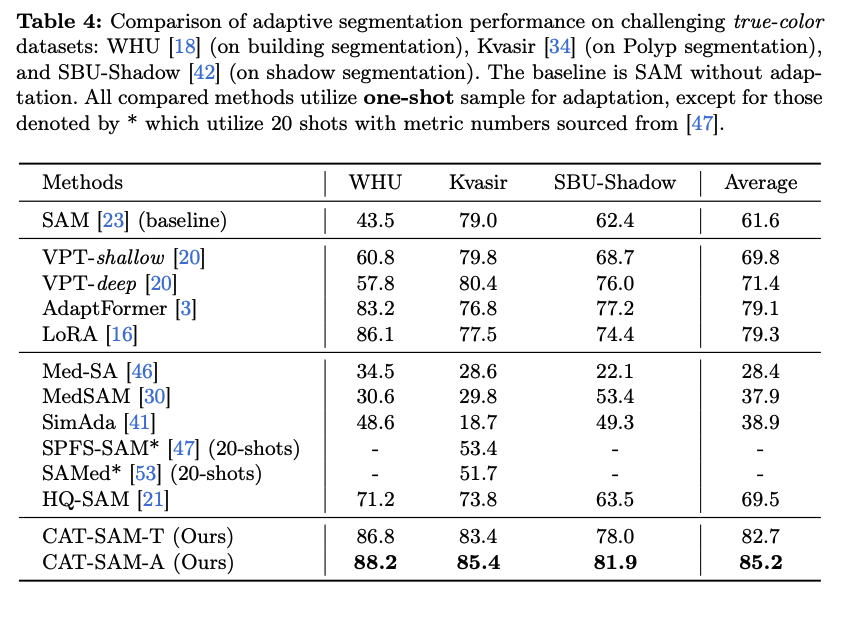
One-Shot Adaptation: CAT-SAM은 매우 도전적인 one-shot 적응 시나리오에서도 뛰어난 성능을 보였다. 기존의 여러 foundation model 튜닝 방법론 (VPT, AdaptFormer, LoRA) 및 SAM 기반 adaptation 방법론 (Med-SA, MedSAM, SimAda, HQ-SAM 등)과 비교했을 때, CAT-SAM 변형들이 일관되게 더 우수한 분할 성능을 달성했다. 특히 CAT-SAM-A가 약간 더 나은 성능을 나타냈는데, 이는 네트워크 구조 변경의 효과로 분석된다.
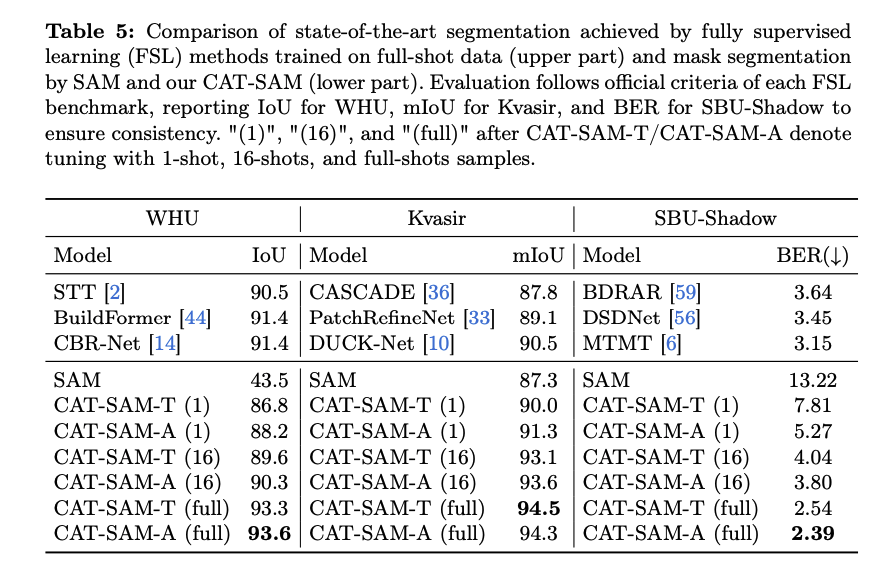
- Full-Shot Learning: CAT-SAM은 기본적으로 소량 데이터 적응에 초점을 맞추고 있지만, 전체 학습 데이터를 사용한 full-shot 경우에도 그 효과를 검증했다. 놀랍게도, 기존의 fully supervised learning (FSL) 기반 State-of-the-Art (SOTA) 방법들보다 일관되게 우수한 성능을 달성했다. 더욱이, 단 16개의 타겟 샘플만으로 학습한 CAT-SAM이 전체 데이터로 학습한 FSL 방법들과 견줄만한 성능을 보였다는 점은, foundation model로부터의 효과적인 지식 전달과 CAT-SAM의 높은 데이터 효율성을 시사한다.
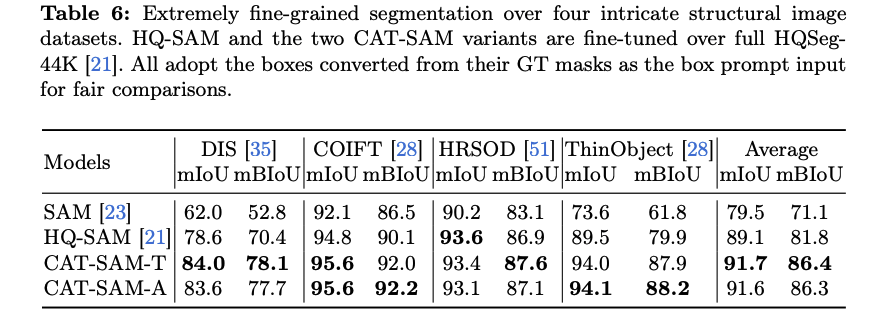
- Fine-grained Segmentation: 매우 세밀하고 복잡한 구조를 가진 객체들을 분할하는 작업에서도 CAT-SAM 변형들은 HQ-SAM 및 원본 SAM보다 뚜렷하게 향상된 성능을 보였다. 이는 CAT-SAM의 조건부 튜닝 방식이 어려운 downstream 작업에 SAM을 효과적으로 적응시킬 수 있음을 보여준다.
-
Non-RGB Domains: SAM의 원본 학습 데이터와 분포상 큰 차이를 보이는 non-RGB 이미지 데이터셋 (JSRT (X-ray), FLS (Sonar), HRSID (SAR))에서도 CAT-SAM의 성능을 평가했다. 그 결과, 소량의 샘플 (1-shot 또는 16-shot)만을 사용했음에도 불구하고 원본 SAM 대비 상당한 성능 개선을 이루었다. 이는 CAT-SAM이 큰 domain discrepancy가 있는 경우에도 효과적으로 적응할 수 있음을 나타낸다.

-
Single Point Prompts: SAM의 장점 중 하나는 다양한 기하학적 프롬프트를 사용할 수 있다는 것이다. 단일 전경 포인트를 프롬프트로 사용한 평가에서도 CAT-SAM은 우수한 분할 성능을 유지했다. 이는 CAT-SAM이 SAM 고유의 유연한 프롬프트 활용성을 보존하면서도 적응 성능을 높였음을 보여준다.
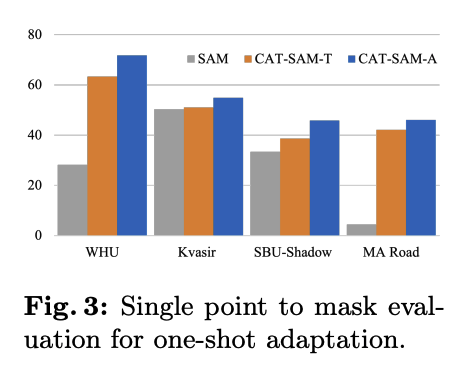
-
Visual Illustrations (시각적 결과 전반): 정성적 비교 결과, CAT-SAM은 단 한 장의 타겟 샘플만으로도 원본 SAM의 마스크 품질을 현저하게 향상시키는 것을 시각적으로 명확히 확인할 수 있었다.
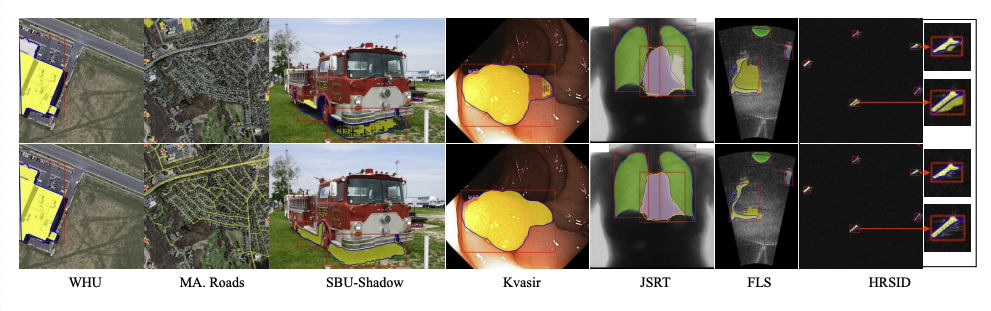
4. 결론 (Conclusion)
이 논문은 SAM을 소량의 데이터만으로 특정 도메인에 효과적으로 적응시키기 위한 새로운 Conditional Tuning network인 CAT-SAM을 제안했다. CAT-SAM의 핵심은 SAM의 육중한 Image Encoder와 가벼운 Mask Decoder 간의 tuning imbalance를 완화하고, 이를 통해 효율적인 SAM adaptation을 가능하게 하는 decoder-conditioned joint tuning 메커니즘이다. 이를 구현하기 위해 두 네트워크 모듈 (인코더와 디코더)이 튜닝 과정에서 서로 효과적으로 상호작용할 수 있도록 prompt bridge 구조를 설계했다. 또한, 널리 사용되는 두 가지 대표적인 parameter-efficient tuning 전략인 prompt tuning 및 adapter 방식에 이 prompt bridge를 통합하여 두 가지 CAT-SAM 변형 (CAT-SAM-T, CAT-SAM-A)을 개발했다.
11개의 다양한 분할 데이터셋에 대한 포괄적인 실험 결과는, 제안된 두 가지 CAT-SAM 변형 모두 매우 도전적인 one-shot 시나리오에서조차 우수한 도메인 적응 효율성을 일관되게 보여주었음을 강조한다.
다만, CAT-SAM은 SAM 자체에 의존하기 때문에 연산량이 여전히 많아 real-time 처리가 어렵다는 점, 그리고 특히 데이터가 매우 부족하면서도 도메인 복잡성이 높은 경우 (예: 다중 클래스를 가진 Sonar 이미지)에는 실제 다양한 환경에 적용되기 위해 적응 성능의 추가적인 개선이 필요하다는 한계점도 언급하고 있다.
