Pretrained language model을 설명하기에 앞서 전이학습(Transfer Learning)의 개념에 대한 이해가 있어야 한다.
전이 학습(Transfer Learning)
전이 학습 개념
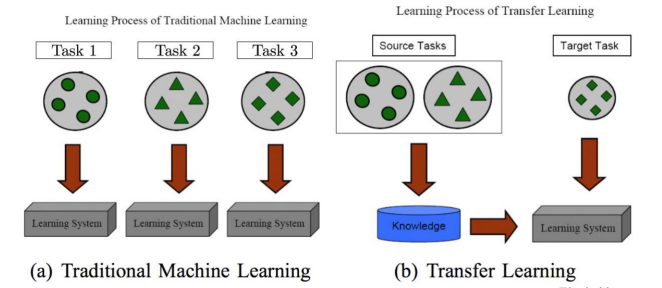
전이 학습이란 모델을 학습시키는 방법 중 하나로, 사전 작업(source task)에 애하여 학습된 정보를 목표 작업(target task)에 확용하는 방법이다.
전이 학습은 학습 데이터가 부족해도 목표 작업에 대한 수렴 속도 및 성능 향상을 꾀할 수 있다.
전이 학습 유형
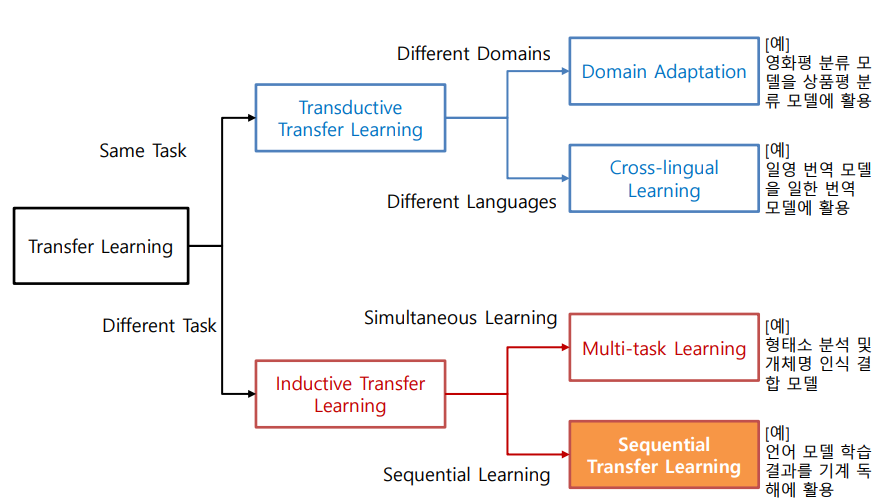
이렇게 목적별로 전이 학습의 종류가 4가지로 나뉘게 되는데 오늘 살펴볼 Pretrained Language Model 에 해당하는 전이 학습 유형은 Sequential Transefer Learning이다.
Inductive TL: Sequential Transfer Learning
Sequential Transfer Learning(순차 전이 학습) 이란 사전 작업과 목표 작업이 다르고 각 작업에 대하여 순차적으로 학습을 수행하는 전이 학습 방법이다.
순차 전이 학습은 다음과 같은 경우에 사용된다.
- 사전 작업과 목표 작업에 대한 데이터를 동시에 사용할 수 없는 경우
- 사전 작업 학습 데이터가 목표 작업 학습 데이터보다 많은 경우
- 여러 목표 작업에 대한 적용이 필요한 경우
이러한 사전학습 언어 모델에는 여러 종류가 있는데 오늘 살펴볼 모델은 BERT 모델이다.
BERT
BERT란?
BERT(Bidirectional Encoder Representation for Transformer) 모델은 대표적인 Pretrained Language Model이며 2018년 구글에서 개발된 모델이다.
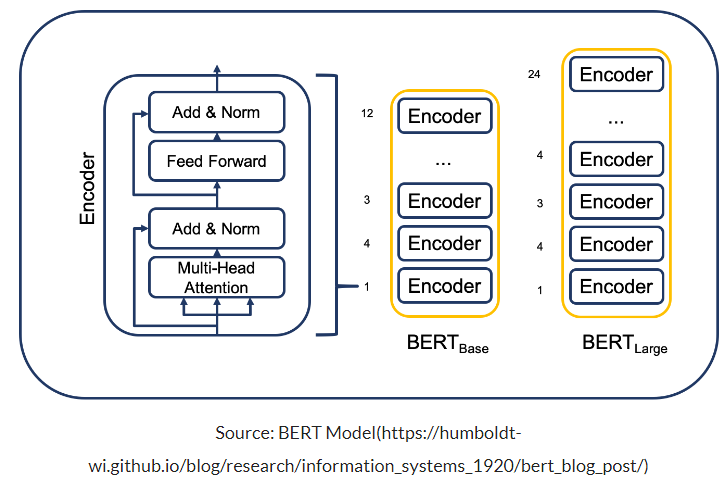
BERT의 이름에서 알 수 있듯이 BERT는 Transformer 구조를 변형한 모델이다. BERT는 Transformer의 Encoder만 사용한다는 것이다.그리고 Bidirectional이란 이름에서 알 수 있듯이, BERT는 왼쪽과 오르쪽의 토큰으로부터 즉 양쪽의 정보로 학습된 모델이다.
BERT는 book corpus로 부터 800M개의 단어와 English Wikipedia로 부터 2,500M개의 단어를 데이터셋으로 학습하였다.
BERT의 구조
BERT input
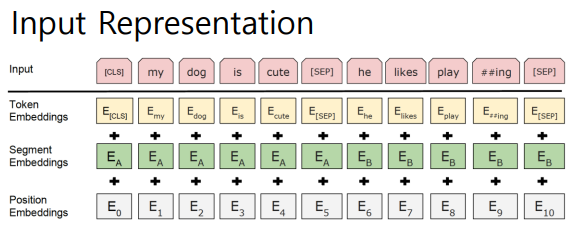
BERT의 input representation은 그림과 같이 3가지 embedding 값의 합으로 구성된다.
Token Embeddings
Token embedding은 word piece방식을 사용한다. 따라서 이전에는 자주 등장하지 않은 단어를 전부 OOV로 처리하였지만 이러한 문제를 word piece방식으로 해결했다. 여기서 특이한 점은 [CLS] 토큰인데 이는 special classification token이며 이는 모든 문장의 시작에 임베딩 된다. 이 [CLS] 토큰에 간단한 classifier를 붙이면 단일 문장 또는 연속된 문장을 분류할 수 있게 된다. [CLS]와는 반대로 문장의 구분을 위해 문장의 끝에는 [SEP] 토큰을 임베팅 한다.
Segment Embeddings
segment embedding은 토큰으로 나누어진 단어들을 다시 하나의 문장으로 만들고 첫 번째 [SEP]토큰까지는 0으로 그 이후 [SEP] 토큰까지는 1 값으로 마스크를 만들어 각 문장들을 구분한다.
Position Embeddings
Position Embedding은 토큰의 순서를 임베딩 한다. 그 이뉴는 transformer의 self attentino구조는 입력의 위치에 대해 고려하지 못하기 때문에 따로 위치 정보를 임베딩하여 위치 정보를 주었다.
BERT의 차별화
self-supervised pre-training
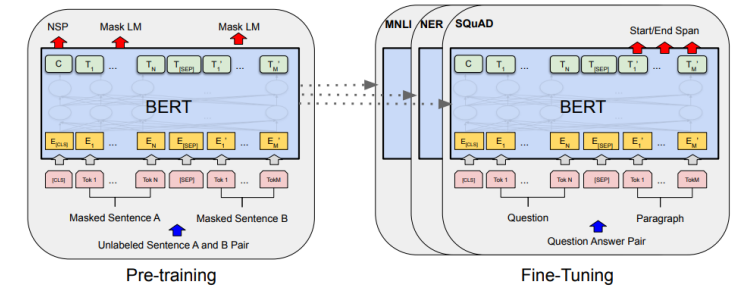
사전 학습을 통해 목표 작업에 대하여 적은 시간과 자원을 사용하여 비교적 높은 성능을 보일 수 있다.
MLM(Masked Language Model)
MLM은 일련의 단어가 주어지면 그 단어를 예측하는 작업니다. 이때 모든 단어들에 대해서 예측하는 것이 아니라 특정한 무작위한 몇개의 토큰만을 masking한다.
토큰 중 15퍼센트는 무작위로 [MASK] 토큰으로 변경한다. 이때 [MASK]토큰 중 80 퍼센트는 그대로 [MASK] 토큰을 가지고 10 퍼센트는 무작위한 단어로 변경한다. 마지막 10 퍼센트는 원래의 단어로 임베딩 된다.
80%[mask] • my dog is hairy -> my dog is [MASK]
10%[random] • my dog is hairy -> My dog is apple
10% unchanged • my dog is hairy -> my dog is hairy
이러한 MLM 과정을 통해서 BERT는 문맥을 파악하는 능력을 길러내게 된다.
NSP
NSP(Next Sentence Prediction)는 두 문장의 관계를 이해하기 위해 BERT의 학습 과정에서 두 번째 문장이 첫 번째 문장의 바로 다음에 오는 문장인지 예측하는 방식이다.
이러한 종류의 이해를 갖춘 사전 학습 모델은 질문 답변과 같은 작업이 가능해 진다.
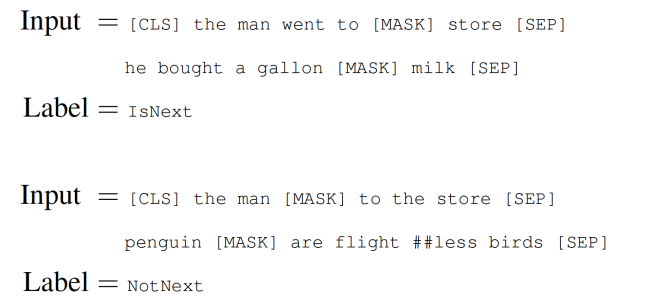
BERT의 이용
- classificatin task
- suquence labeling task
- span prediction task
다음에는 BERT를 활용한 감성분석에 대해 알아보자.
