이산 표현
one-hot encoding
단어를 벡터로 표현을 해보자.
단어 사전을 구성하고 해당 단어를 1로 그 밖의 단어는 0으로 표현한다.
사전: 개, 고양이, 늑대, 사자, 송어, 잉어
단어: 개[1,0,0,0,0,0] 고양이[0,1,0,0,0,0]
one-hot encoding의 한계
사전의 크기가 커질수록 용량이 커지게 된다.
유사성을 비교할 수 없다.
분산 표현
분산 표현
그렇게 나오게 된 것이 분산표현이다.
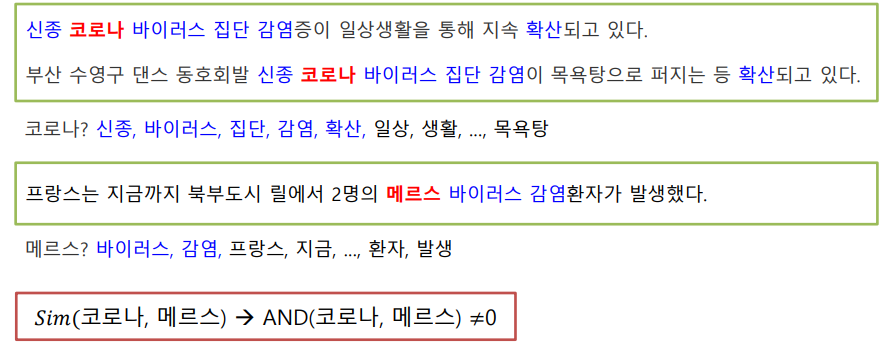
이렇게 단어를 문맥에 기반하여 표현하는 방법을 뜻한다.
공기 행렬(Co-Occurrence Matrix)
예문: I like deep learning. I like NLP. I enjoy flying.
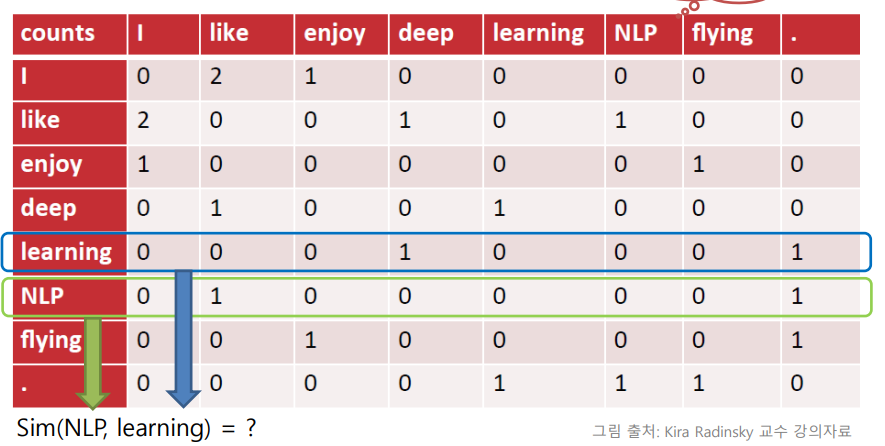
I가 나온후 like가 나오는 경우는 2번이기 때문에 2가 된다. 이렇게 단어들 간의 관계를 나타내는 방법을 공기 행렬이라고 부른다. 그렇다면 이렇게 나온 벡터의 유사도는 어떻게 판단할까?
코사인 유사도(Cosine similarity)
길이로 정규화된 내적을 바탕으로 두 벡터 사이의 유사도를 측정하는 척도이다.
NLP와 learning의 유사도는 즉 0.5가 된다.
이렇게 공기 행렬을 통해 유사도를 측정하게 된다면 학습 데이터가 많아질 수록 차원의 수가 커지게 된다. 그래서 이러한 문제를 해결하기 위해 사용한 방식이 특이값 분해(SVD)이다.
SVD
행렬을 특정한 구조로 분해하는 방식이다.
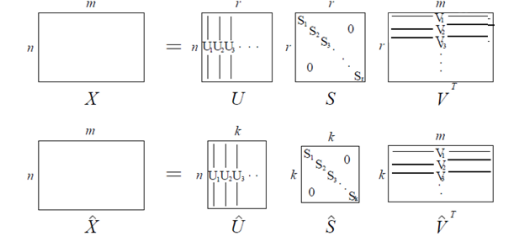

이렇게 SVD를 통해 차원의 저주를 해결 하였지만 여전히 문제점이 존재한다.
-
계산에 너무 오랜 시간이 소요됨
n*m 행렬을 계산하는데 O(mn^2)이 걸림
-
유연성의 부족
새로운 단어나 문서가 추가될 경우에 SVD를 처음부터 다시 수행해야함
Word2Vec
embedding
이러한 공기 행렬에서의 문제점을 해결하기 위해 나온 것이 word2vec 이다. 기존의 공기 행렬을 사용하게 된다면 encoding된 one-hot 벡터들의 크기가 너무 커져 계산량이 많아지는 문제점이 존재했다. 이를 해결하기 위해 도입한 핵심 개념은 ‘embedding’ 이다.
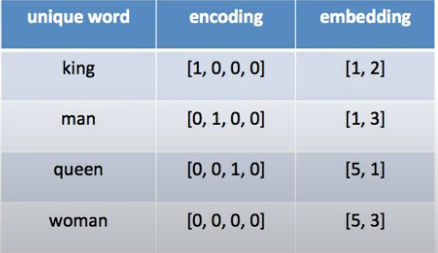
출처: 허민석 유튜브
embedding의 특징은 3가지로 표현할 수 있다.
-
저차원
Encoding 과는 다르게 단순한 2차원 으로 표현이 가능하다. 2차원 뿐만 아니라 사용자가 원하는 차원으로 embedding이 가능하다.
-
유사도
Encoding에서 코사인 유사도를 이용하여 단어들 간의 유사성을 얻을 수 있었듯이 embedding 에서도 단어들 간의 유사성을 얻을 수 있다.
-
훈련 데이터로 학습
Encoding 방법에서는 수동으로 표현하였지만 embedding 방법은 훈련을 통해 표현이 가능하다.
Word2vec은 단어를 embedding 하는 모델 중 하나라고 설명할 수 있다. word2vec 모델을 훈련시키는 방법은 2가지가 존재한다.
-
CBoW(Continuous Bag of Words)
주변에 있는 단어들로 중간에 있는 단어를 예측하는 방법
-
Skip-gram
중심 단어를 보고 어떤 주변 단어가 존재하는지 예측하는 모델
CBoW(Continuous Bag of Words)
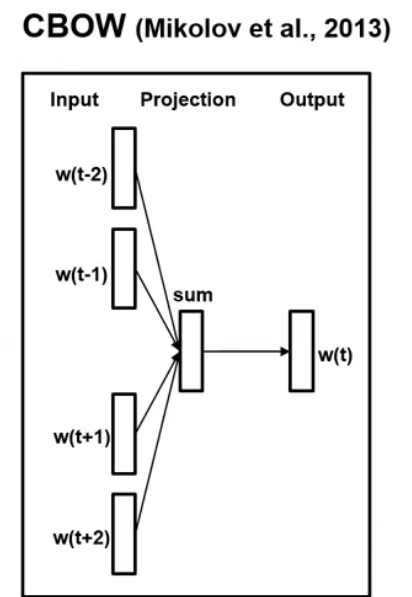
CBoW는 주변에 있는 단어들로 중간에 있는 단어들을 예측 하는 방법이다. 이 때, 예측해야 하는 단어를 중심 단어(center word) 라 하고, 예측에 사용되는 단어들을 주변 단어(context word)라고 한다. 중심 단어를 예측하기 위해서는 앞뒤로 몇 개의 단어를 볼지 결정하게 되는데, 그 크기를 윈도우window)라고 한다.
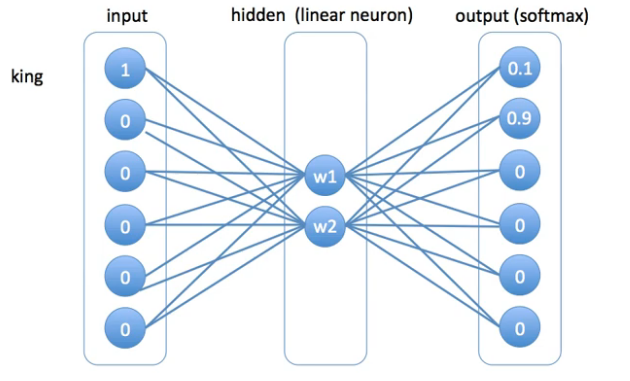
그림을 보면 은닉층이 하나 이므로 딥러닝 모델이 아닌 얕은 신경망 이라고 할 수 있다. 이 모델의 특징으로는 hidden layer 에 일반적으로 사용되는 활성화 함수(sigmoid function)을 사용하지 않고 단순한 linear function을 사용한여 projection layer 라고도 불린다. 그 이유는 hidden 층이 단순히 차원의 수를 줄이기 위해 사용되기 때문이다.
Skip-gram
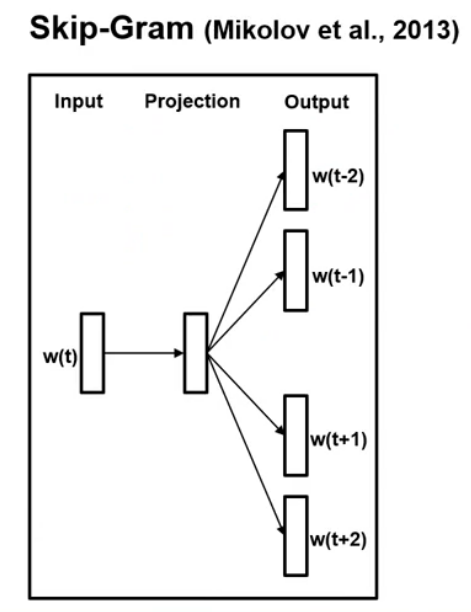
Skip-Gram의 원리는 CBoW와 크게 다르지 않다. ****중심 단어를 보고 어떤 주변 단어가 존재하는지 예측하는 모델이다. 일반적으로 Skip gram이 CBoW보다 성능이 좋다고 알려져 있다.
최종적인 출력은 softmax 함수를 적용하여 확률분포 형태로 나타나게 됩니다. 즉 모든 차원의 softmax를 구하기 위해서는 많은 계산량이 요구되기 때문에 이를 해결하기 위해 2가지 방법을 사용하였다.
- Hierarchical softmax
모든 단어 별 등장 빈도를 고려하여 이진 트리를 구성하는 방법
- Negative sampling
너무 많은 단어들을 계산하지 않고, 몇개만 뽑아서 계산하는 방법
한계점
주변에 있는 일부 단어들 과의 연관성만 학습하므로, 말뭉치 전체의 정보를 학습하지 못한다는 단점이 존재한다. 이러한 문제점을 해결하기 위해 나온 모델이 GloVe 이다.
GloVe(Global Vectors)
GloVe 핵심 아이디어는 global information 을 사용한다는 점이다.
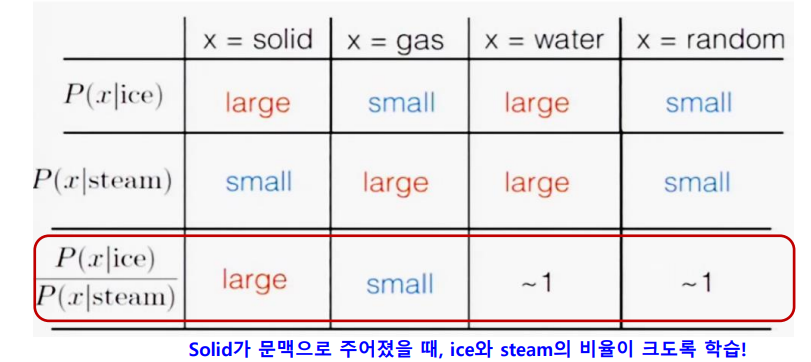
Embedding 벡터 간의 inner product가 말뭉치 전체에 대한 Co-occurrence 확률의 비율과 같도록 mapping함수 설계한다. 쉽게 말해 inner product는 두 벡터의 유사도를 의미하며, 이를 Co-occurrence 확률 비율과 맞춰서 설계함으로써 local 유사도만 반영하던 Word2Vec의 한계 극복하였다.
위에 나와있는 사진은 단어들 간의 co-occurrence 확률을 나타낸 것 이다. 예를 들어 ice라는 단어가 나왔을 때, solid 가 나올 확률은 ‘large’이다. 또한 steam이라는 단어가 나왔을 때 solid가 나올 확률은 ‘small’이다. 앞에서 말했듯이 GloVe의 핵심 아이디어가 embedding 벡터 간의 내적값이 Co-occurrence 확률의 비율과 같도록 설계한 것이다. 즉 Solid가 문맥으로 주어졌을 때, ice와 steam의 Co-occurrence의 비율은 ‘large’이므로 이들의 내적 값도 ‘large’와 유사한 비율을 가져가게 한다는 것 이다.
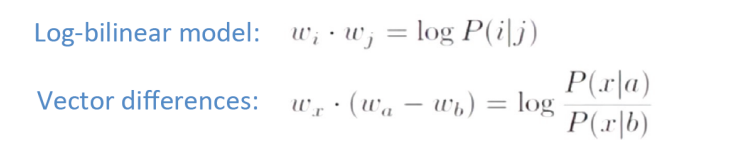
두 벡터 사이의 차이 즉 벡터간의 내적을 위와같은 방법으로 비율로 표현하였다.
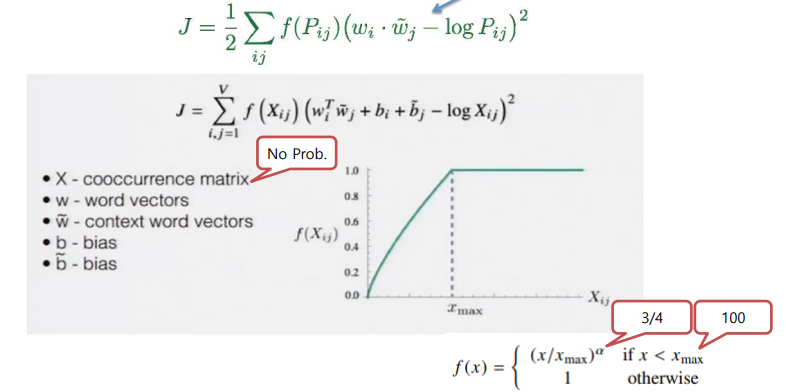
목적함수를 살펴보면 두 벡터의 내적과 co occurence의 차이가 최소가 되도록 되어 있다. 이때 f(x)는 100번보다 큰 것은 1.0의 값으로 유지하기 위한 함수이다.
One-hot → embedding 하는 다른 모델들
fastText
부분단어(n-gram) 으로 학습하여 노이즈에 강하다. 예를 들어 오탈자 같은 경우에 강하다.
Word2vec, GloVe, fastText의 단점
만약 ‘배’ 라는 단어가 있을 떄, 이는 ship, pear, stomach이라는 여러 중의적인 뜻을 포함하고 있다. 따라서 Word2vec, GloVe와 같은 모델에서는 ‘배’라는 vector는 어디에도 속해있지 않게 된다. 이러한 문제점을 해결하기 위해서 문맥의 의미를 통해 vector값을 조절해야 한다.
CoVe
MT-LSTM을 통한 사전학습 MT-LSTM(GloVe)
