Introduction
Transformer
Self-Attention 기반의 구조를 가진 Transformer는 NLP 태스크에서 성공적인 성능을 발휘한 모델이다. Transformer는 다음과 같은 특징을 가지고 있다.
- 높은 연산 효율성(Computational Efficiency)
- 확장성(Scalbility)
즉, Transformer는 데이터셋이 크면 클수록 모델의 성능이 포화되지 않고, 성능이 향상된다는 특징이 있다. Transformer는 이러한 특징들 때문에 매우 큰 1000억개의 파라미터를 가진 모델도 훈련할 수 있게 되었다. 하지만 이러한 Transformer 모델은 컴퓨터 비전 분야에서는 제대로 적용이 되지 않았다. Transformer는 Inductive Bias가 많이 부족하여 많은 데이터셋을 활용해야만 가능하기에, 하드웨어 가속기와의 호환성 문제가 발생했기 때문이다.
Vision Transformer(ViT)
NLP 태스크에서 큰 성공을 거둔 Transformer를 컴퓨터 비전 분야에 적용한 것이 Vision Transformer(ViT)이다. ViT는 이미지를 패치 단위로 분할한 후 Sequence로 입력하는 방식으로 기존의 Transformer 구조와 동일하다. 기존의 Transformer모델과 같이 모든 경우를 고려할 수 있을만큼 거대한 데이터셋으로 학습할 경우 굉장히 우수한 성능을 보이게 된다. 하지만 CNN기반의 모델들 처럼 지역정보를 활용하지 못하기 때문에 방대한 데이터셋이 없다면 성능이 저하된다는 단점이 여전히 존재한다.
Method
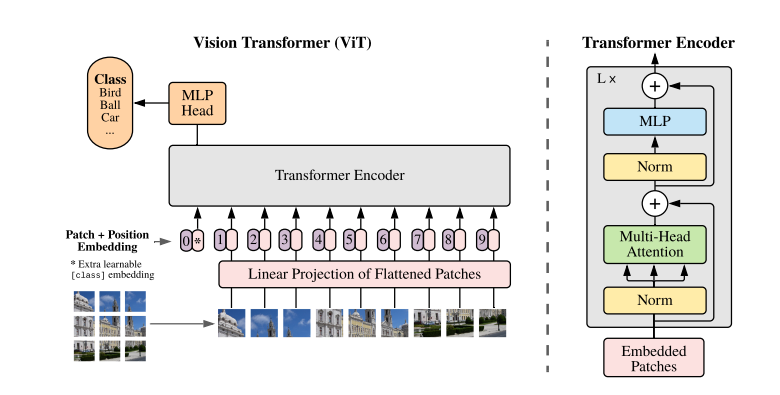
모델 Overview
ViT는 이미지를 텍스트 Sequence처럼 활용하는 구조이다. 이미지를 고정된 크기의 패치로 나누어주고, 각각의 패치를 Linear Embedding, Positional Embedding 과정을 거치며 Transformer의 Encoder로 들어가게 된다. 여기서 Positional Embedding이란 각 패치의 위치정보를 입력하는 것을 말한다. 위의 그림의 왼쪽 상단 이미지가 Positional Embedding 과정을 거치면 1의 값이 임베딩 되는 것을 알 수 있다. 이때 0번 포지션에는 이미지의 추가 정보인 클래스 정보가 들어가게 된다. 이를 통해 ViT를 이미지 분류 테스크로 활용할 수 있게 된다. 이렇게 Transformer Encoder를 통과한 후 MLP(Multi-Layer-Perceptron)을 거쳐 최종적인 이미지 분류값이 나오게 되는 것 이다. 이러한 과정을 정리하자면 다음과 같다.
💡 Input 이미지 → Embedding → Transformer Encoder → MLP Head→ ClassificationEmbedding
Embedding이 어떻게 진행되는지 쉽게 이해하기 위해 실제 수치를 이용하여 계산해 보자. RGB 채널값을 가지는 이미지는 의 차원을 가지게 된다. 즉, 3차원 벡터 형태인 것 이다. 하지만 우리가 Transformer Encoder에 이미지 벡터를 입력하기 위해서는 여러개의 1차원으로 바꾸어 주어야 한다. 이렇게 여러개의 1차원 벡터를 만드는 과정을 Embedding 이라고 하고, 여기서 사용된 기술이 Linear Projection of Flattened Patches이다.
그렇다면 어떻게 1차원 벡터로 변경할 수 있을까? 바로 앞서 설명했던 패치를 활용해서 바꿀 수 있다. 하나의 이미지가 들어왔을 때, 형태의 패치로 나눌 수 있다. 만약 형태의 이미지가 들어왔고, 크기의 패치로 나누고 싶다면, 총 196개의 패치가 생성된다. 이렇게 나누어진 패치들을 하나씩 쌓아올려 Transformer Encoder에 들어가게 되는 것 이다. 그렇다면 각각의 패치는 768차원의 벡터가 되는데 이를 D라고 부르고 이는 모든 레이어 전체에서 동일하다.
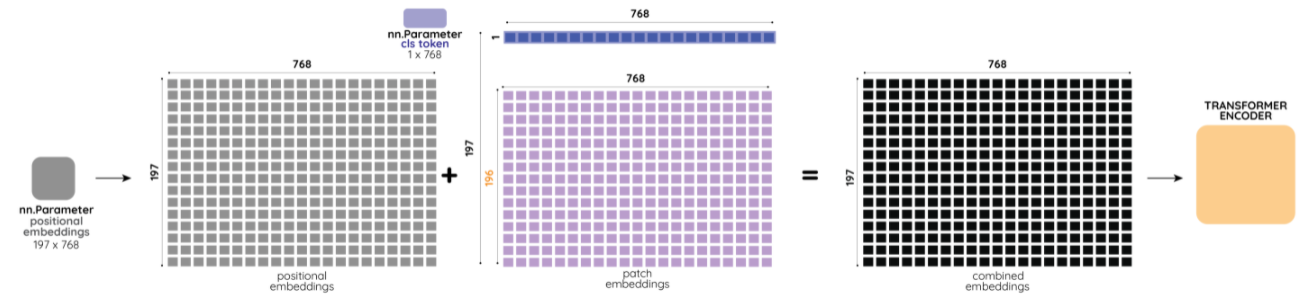
여기까지의 과정이 Patch Embedding 과정이다. 모델 Overview에서 설명했듯이 ViT가 분류 태스크에서 활용되기 위해서는 Positional Embedding이 중요하다. BERT 모델의 ‘cls_token’과 같은 역할을 하는 Class Token을 Patch Embedding 가장 왼쪽(그림 상으로는 가장 위쪽)에 추가하게 된다. 이때 이 Class Token은 학습가능한 파라미터로, 추후 Transformer Encoder를 통과하여 최종적인 분류 문제를 해결할 수 있게 된다.
Transformer Encoder
Transformer Encoder는 기존의 Transformer의 인코더 구조와 동일하다. ViT의 전체과정을 표현한 수식과 함게 어떻게 Transformer Encoder가 작동하는지 살펴보자

(1) 과정은 Embedding 과정으로 은 각각의 패치들을 뜻한다. 총 N개의 패치가 있고 최종적으로 가장 마지막에 추가한 학습가능한 파라미터인 Class Token은 이다. 와 는 각각 Patch Embedding, Positional Embedding 행렬이다.
(2) 과정은 Trandformer Encoder 부분이다. 여기서 MSA란 Multi-head Self-Attention 이다. Transformer Encoder에 Input값이 들어오면 Layer Normalization을 진행한 후 , MSA를 적용하게 된다. 이후 해당 값을 Skip Connection을 해주어 최종적인 Output이 나오게 된다.
(3) 과정은 MLP에 해당하는 수식이다. 주의해야 할 점은 Transformer Encoder가 끝난 후 진행되는 MLP Head가 아닌 Transformer Encoder 내에 존재하는 MLP Layer이다. MLP는 2개의 Hidden Layer와 GELU(Gaussian Error Linear Unit) 활성화 함수로 구성되어 있다. 마찬가지로 Layer Normalization을 진행한 후, MLP를 통과하며 (4)와 같은 최종적인 y값을 얻게 되는 것이다.
MLP Head
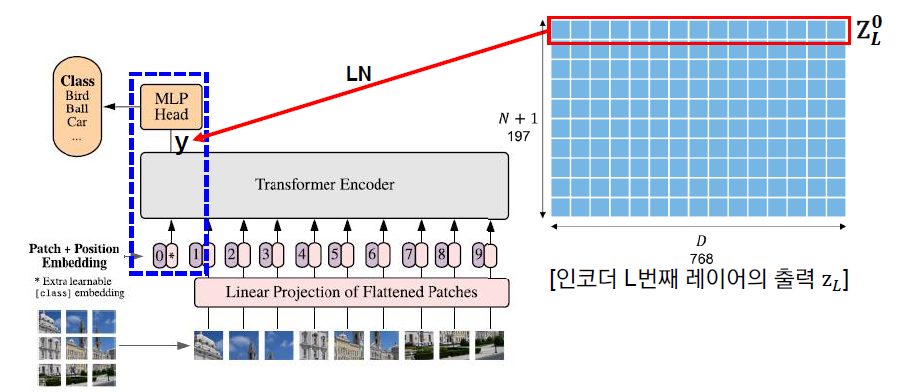
위의 과정을 L번 반복한 후 최종적으로 가장 마지막 Layer의 Output의 첫 번째 벡터인 y가 하나의 Hidden Layer를 통과하여 최종적인 Class 결괏값을 얻게 된다. 이때 Output의 첫 번째 벡터인 y는 바로 Embedding시 학습 가능한 벡터로 쌓아두었던 Class Token 이다.
Experiments
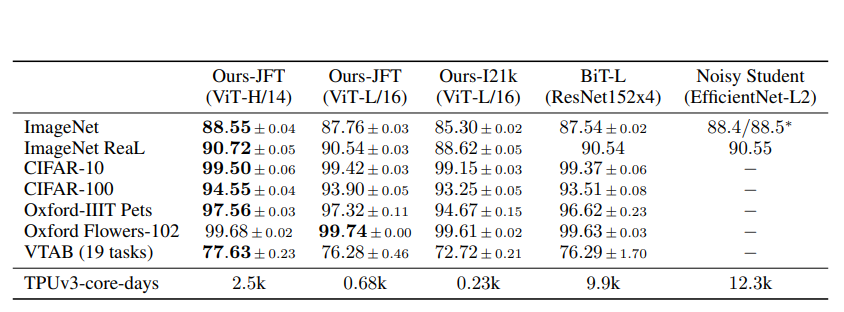
각 데이터셋 별 ViT 모델과 기존 전이학습 SOTA CNN 모델(BiT, Noisy Student) 과의 성능 비교를 하였을 때 모델의 규모가 증가하고 데이터셋의 갯수가 증가할수록 성능이 지속적으로 증가하는 것을 확인할 수 있다.
