
스타벅스 데이터 가져오기
from selenium import webdriver
# 페이지 접근
driver = webdriver.Chrome("../driver/chromedriver.exe")
driver.get("https://www.starbucks.co.kr/store/store_map.do")
>> # 아래처럼 나오면 페이지가 잘 열렸다는 뜻
C:\Users\hjh\AppData\Local\Temp\ipykernel_62876\3859599457.py:4: DeprecationWarning: executable_path has been deprecated, please pass in a Service object
driver = webdriver.Chrome("../driver/chromedriver.exe")
-----------------
# '지역검색' 선택
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
search_tag = driver.find_element(By.CSS_SELECTOR, value='#container > div > form > fieldset > div > section > article.find_store_cont > article > header.loca_search')
action = ActionChains(driver)
action.click(search_tag)
action.perform()
-------------------
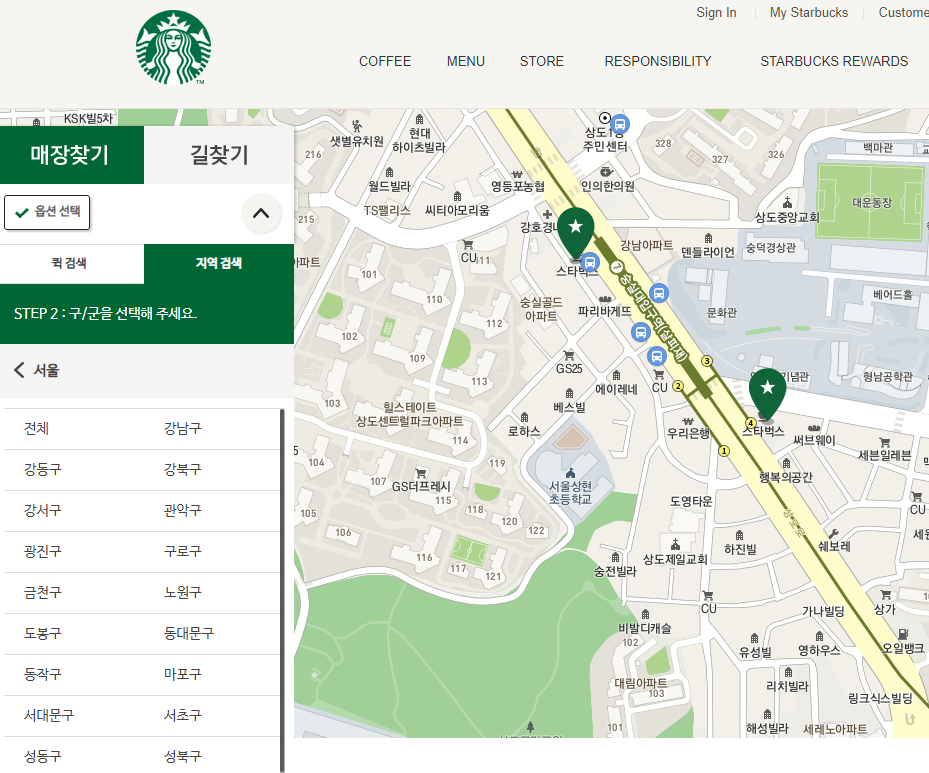
# '서울' 선택
seoul_tag = driver.find_element(By.CSS_SELECTOR, value='#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a')
action = ActionChains(driver)
action.click(seoul_tag)
action.perform()
--------------------
# '전체 선택)
seoul_tag = driver.find_element(By.CSS_SELECTOR, value='#mCSB_2_container > ul > li:nth-child(1) > a')
action = ActionChains(driver)
action.click(seoul_tag)
action.perform()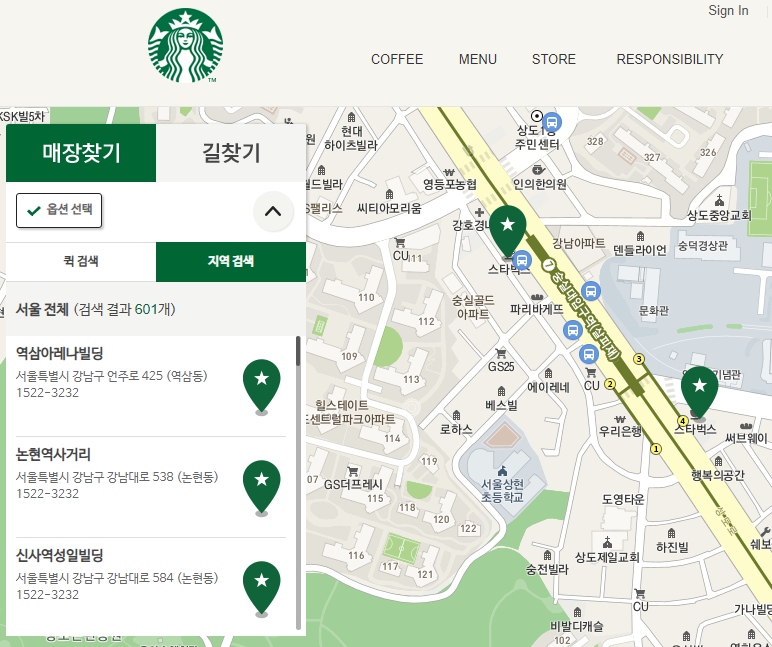
import pandas as pd
import time
from urllib.request import urlopen, Request
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
# 해당 페이지 html 읽어오기
req = driver.page_source
# html = urlopen(req).read()
soup_tmp = BeautifulSoup(req, "html.parser")
soup_tmp
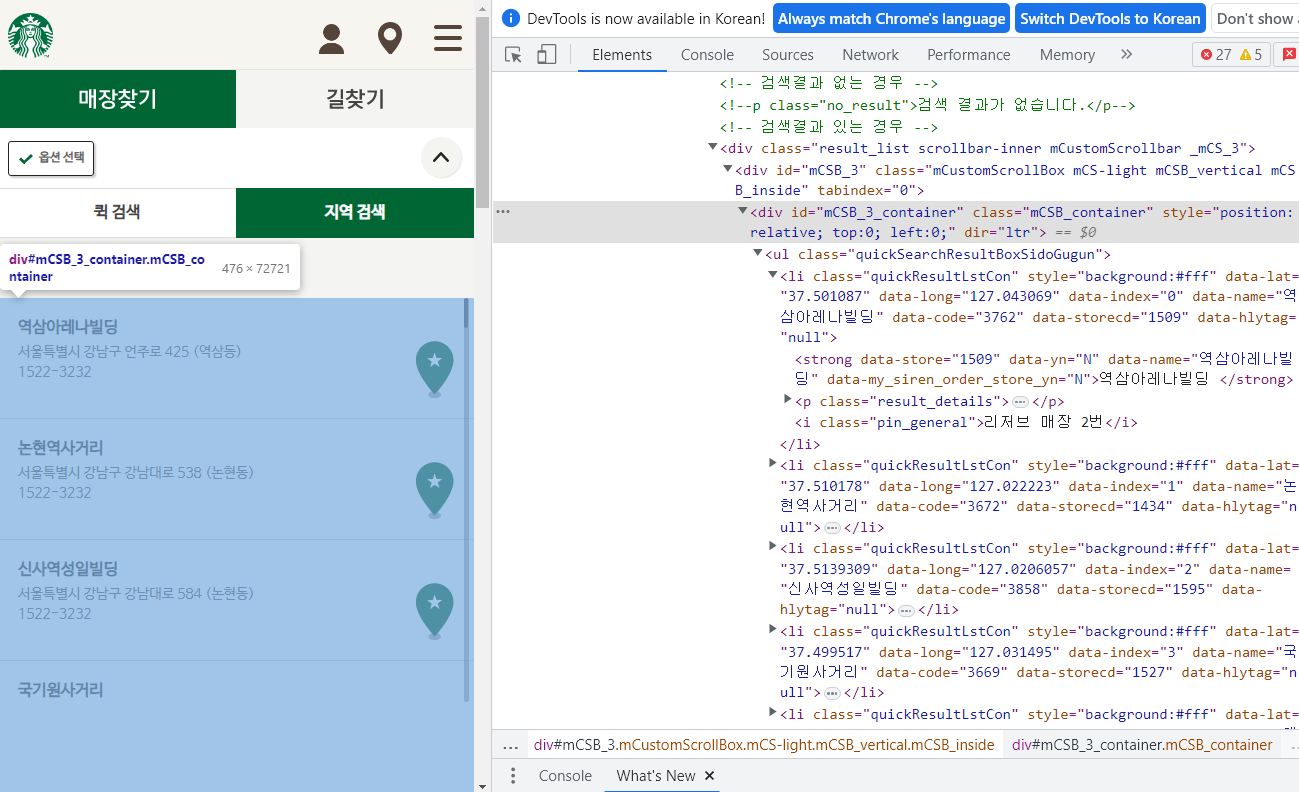
# 매장 목록 전체부분 찾기
content = soup_tmp.find("div", id = "mCSB_3_container")
content
contents = content.find_all("li")
contents[0] # 첫번째만 출력
>>
<li class="quickResultLstCon" data-code="3762" data-hlytag="null" data-index="0" data-lat="37.501087" data-long="127.043069" data-name="역삼아레나빌딩" data-storecd="1509" style="background:#fff"> <strong data-my_siren_order_store_yn="N" data-name="역삼아레나빌딩" data-store="1509" data-yn="N">역삼아레나빌딩 </strong> <p class="result_details">서울특별시 강남구 언주로 425 (역삼동)<br/>1522-3232</p> <i class="pin_general">리저브 매장 2번</i></li>
--------------------------
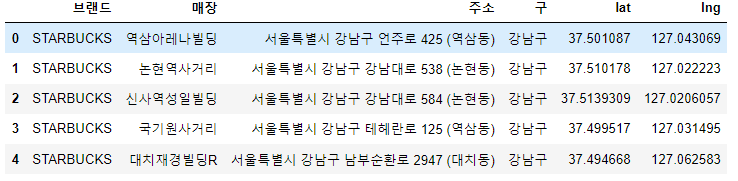
contents[0]['data-name']
>> '역삼아레나빌딩'
--------------------------
contents[0]['data-lat']
>> '37.501087'
--------------------------
contents[0]['data-long']
>> '127.043069'
--------------------------
address = content.find("p").text.replace("1522-3232","")
address
>> '서울특별시 강남구 언주로 425 (역삼동)'
--------------------------
address.split()
>> ['서울특별시', '강남구', '언주로', '425', '(역삼동)']
--------------------------
address.split()[1]
>> '강남구'
--------------------------
# 매장 전체 데이터 가져오기
sbuck = []
for item in contents:
name = item['data-name']
lat = item['data-lat']
lng = item['data-long']
address = item.find("p").text.replace("1522-3232","")
store_gu = address.split()[1]
data = {
'브랜드' : 'STARBUCKS',
'매장' : name,
'주소' : address,
'구' : store_gu,
'lat' : lat,
'lng' : lng
}
sbuck.append(data)
sbuck
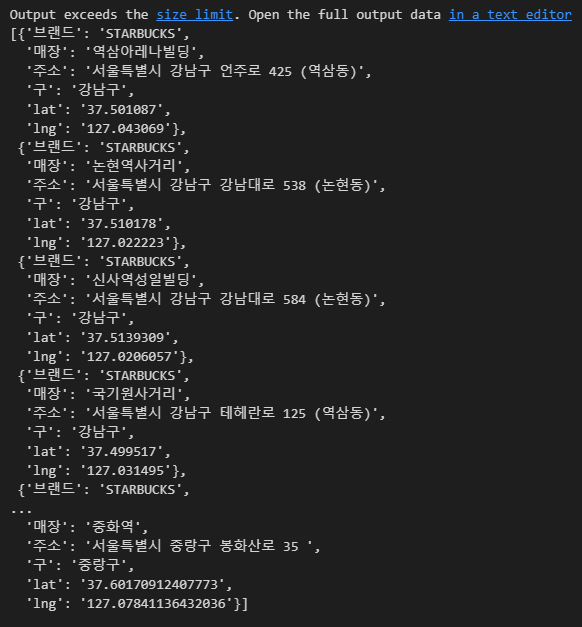
len(sbuck)
>> 601
---------------------
# 데이터 프레임에 넣기
df_sbuck = pd.DataFrame(sbuck)
df_sbuck.to_csv('../data/sbuck_list.csv', encoding='utf-8')
df_sbuck.head()

이디야 데이터 가져오기
# 페이지 접근
driver = webdriver.Chrome("../driver/chromedriver.exe")
driver.get("https://ediya.com/contents/find_store.html#c")
>> # 아래처럼 나오면 페이지가 잘 열렸다는 뜻
C:\Users\hjh\AppData\Local\Temp\ipykernel_62876\876157215.py:2: DeprecationWarning: executable_path has been deprecated, please pass in a Service object
driver = webdriver.Chrome("../driver/chromedriver.exe")
----------------------------
# '주소' 선택
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
search_tag = driver.find_element(By.CSS_SELECTOR, value='#contentWrap > div.contents > div > div.store_search_pop > ul > li:nth-child(2) > a')
action = ActionChains(driver)
action.click(search_tag)
action.perform()
---------------------------
# 검색어를 입력할 공간 찾기
# 해당 페이지에서 개발자도구에서 클릭하려는 페이지의 html 값에 우클릭 > copy > copy selector
# 복사한 값을 아래 value 값에 넣어줌
keyword = driver.find_element(By.CSS_SELECTOR, value="#keyword")
---------------------------
gu_list = ['강남구', '강북구', '강서구', '관악구', '광진구', '금천구', '노원구', '도봉구', '동작구',
'마포구', '서대문구', '서초구', '성북구', '송파구', '양천구', '영등포구', '은평구',
'종로구', '중구', '강동구', '구로구', '동대문구', '성동구', '용산구', '중랑구']
# 검색어 입력
keyword.clear() # 기존에 입력한 검색어 지우기
keyword.send_keys(gu_list[0]) # 일단 강남구 넣어봄
# 클릭
# 해당 페이지에서 개발자도구에서 클릭하려는 페이지의 html 값에 우클릭 > copy > copy selector
# 복사한 값을 아래 value 값에 넣어줌
search_btn = driver.find_element(By.CSS_SELECTOR, value="#keyword_div > form > button")
search_btn.click()
------------------------------------
# 해당 페이지의 데이터 가져오기
req = driver.page_source
# html = urlopen(req).read()
soup_tmp = BeautifulSoup(req, "html.parser")
soup_tmp

# 강남구 모든 매장 목록이 선택되는 html 가져오기
content = soup_tmp.find("div", class_ = "result_list")
contents = content.find_all("li")
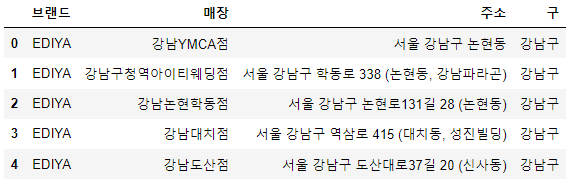
contents[0] # 강남YMCA점
>>
<li class="item"><a href="#c" onclick="panLatTo('0','0','0');fnMove();"><div class="store_thum"><img src="../images/customer/store_thum.gif"/></div><dl><dt>강남YMCA점</dt> <dd>서울 강남구 논현동</dd></dl></a></li>
-------------------------------
contents[0].find("dt").text.strip()
>> '강남YMCA점'
------------------------------
contents[6].find("dd").text.strip()
>> '서울 강남구 밤고개로21길 8 (율현동, 세곡프라자)'
------------------------------
# 강남구 매장 수
len(contents)
>> 44
------------------------------
# 모든 구에 구마다 모든 매장 목록 가져오기
gu_list = ['강남구', '강북구', '강서구', '관악구', '광진구', '금천구', '노원구', '도봉구', '동작구',
'마포구', '서대문구', '서초구', '성북구', '송파구', '양천구', '영등포구', '은평구',
'종로구', '중구', '강동구', '구로구', '동대문구', '성동구', '용산구', '중랑구']
ediya = []
for gu in gu_list:
# 검색어 입력
time.sleep(3)
keyword.clear() # 기존에 입력한 검색어 지우기
keyword.send_keys('서울' + ' ' + gu)
# 클릭
# 해당 페이지에서 개발자도구에서 클릭하려는 페이지의 html 값에 우클릭 > copy > copy selector
# 복사한 값을 아래 value 값에 넣어줌
search_btn = driver.find_element(By.CSS_SELECTOR, value="#keyword_div > form > button")
search_btn.click()
req = driver.page_source
# html = urlopen(req).read()
soup_tmp = BeautifulSoup(req, "html.parser")
content = soup_tmp.find("div", class_ = "result_list")
contents = content.find_all("li")
for item in contents:
name = item.find("dt").text.strip()
address = item.find("dd").text.strip()
store_gu = address.split()[1]
data = {
'브랜드' : 'EDIYA',
'매장' : name,
'주소' : address,
'구' : store_gu,
}
ediya.append(data)
ediya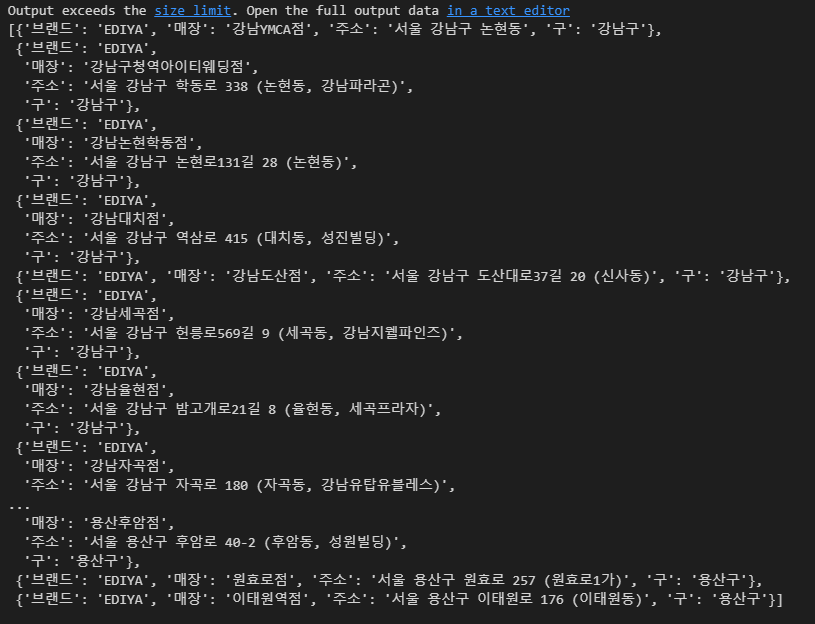
len(ediya)
>>> 672
----------------
# 데이터 프레임에 넣기
df_ediya = pd.DataFrame(ediya)
df_ediya.to_csv('../data/ediya_list.csv', encoding='utf-8')
df_ediya.head()
이디야는 스타벅스 근처에 있는지 분석
# 데이터 합치기
df_sum = pd.concat([df_sbuck,df_ediya])
df_sum.reset_index(drop=True,inplace=True)
df_sum.tail()
# matplotlib 한글대응
import matplotlib.pyplot as plt
# import matplotlib as mpl
from matplotlib import rc
import seaborn as sns
plt.rcParams['axes.unicode_minus'] = False # 마이너스 부호로 인해 한글깨짐현상 방지
rc("font", family='Malgun Gothic')
%matplotlib inline
# 동일 : get_ipython().run_inline_magic("matplotlib", 'inline')
-----------------
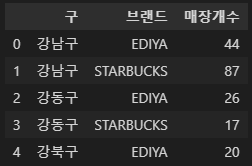
cafe_cnt = df_sum.groupby(['구', '브랜드'])['매장'].count().reset_index(name = '매장개수')
cafe_cnt.head()
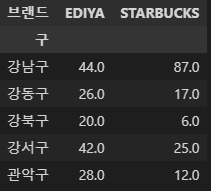
df_sum["값"]=1
cafe_cnt2 = df_sum.pivot_table(index="구", columns="브랜드", values='값', aggfunc=np.sum)
cafe_cnt2.head()
plt.figure(figsize = (20, 8))
sns.barplot(
data = cafe_cnt,
x = cafe_cnt['구'],
y = cafe_cnt['매장개수'],
hue = '브랜드',
palette = 'Set2'
)
plt.show()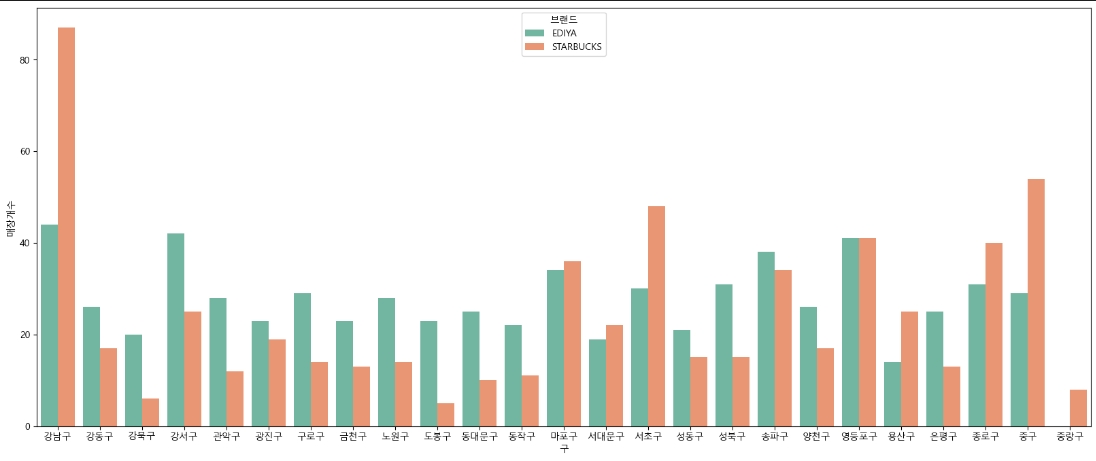
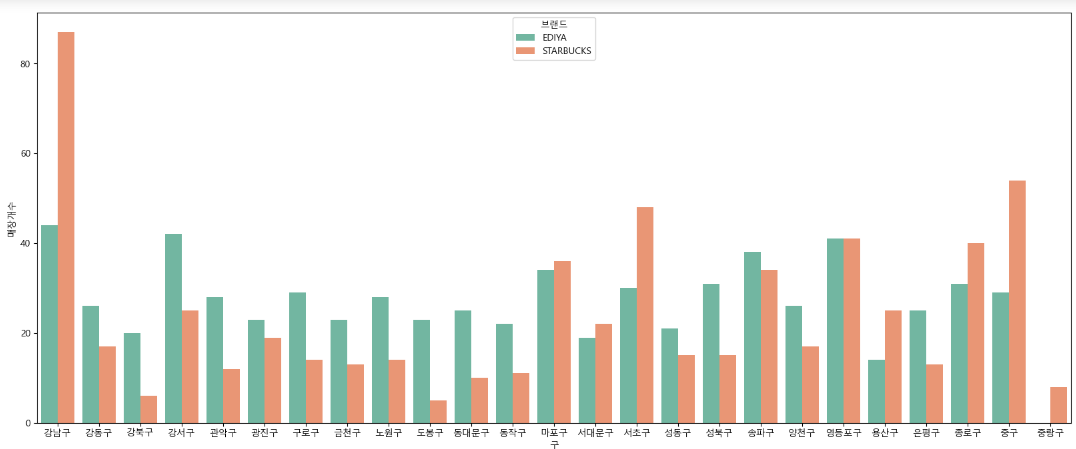
# 결론
- 스타벅스는 강남구, 마포구, 서초구, 송파구, 영등포구, 종로구, 중구에 밀집해있고, 특히 강남구에 많이 분포돼 있다.
- 그래서 스타벅스는 구별로 밀집도가 상이하다
- 그러나 이디야는 중랑구를 제외한 모든 지역에 스타벅스보다는 상대적으로 골고루 분포해있다.
- 그래서 이디야가 스타벅스 매장 근처에 있다고는 볼 수 없다.
아래는 전체코드(time이 추가되었다.)
# 스타벅스 데이터 가져오기
import pandas as pd
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from urllib.request import urlopen, Request
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
# 페이지 접근
driver = webdriver.Chrome("./driver/chromedriver.exe")
driver.get("https://www.starbucks.co.kr/store/store_map.do")
# '지역검색' 선택
time.sleep(3)
search_tag = driver.find_element(By.CSS_SELECTOR, value='#container > div > form > fieldset > div > section > article.find_store_cont > article > header.loca_search')
action = ActionChains(driver)
action.click(search_tag)
action.perform()
# '서울' 선택
time.sleep(3)
seoul_tag = driver.find_element(By.CSS_SELECTOR, value='#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a')
action = ActionChains(driver)
action.click(seoul_tag)
action.perform()
# '전체 선택)
time.sleep(3)
seoul_tag = driver.find_element(By.CSS_SELECTOR, value='#mCSB_2_container > ul > li:nth-child(1) > a')
action = ActionChains(driver)
action.click(seoul_tag)
action.perform()
# html
time.sleep(4)
req = driver.page_source
soup_tmp = BeautifulSoup(req, "html.parser")
content = soup_tmp.find("div", id = "mCSB_3_container")
contents = content.find_all("li")
# 데이터 가져오기
time.sleep(3)
sbuck = []
for item in contents:
name = item['data-name']
lat = item['data-lat']
lng = item['data-long']
address = item.find("p").text.replace("1522-3232","")
store_gu = address.split()[1]
data = {
'브랜드' : 'STARBUCKS',
'매장' : name,
'주소' : address,
'구' : store_gu,
'lat' : lat,
'lng' : lng
}
sbuck.append(data)
# 데이터 프레임에 넣기
time.sleep(3)
df_sbuck = pd.DataFrame(sbuck)
driver.close() # 크롬창 닫기
df_sbuck.head() # 데이터프레임 출력
# 이디야 데이터 가져오기
# 페이지 접근
driver = webdriver.Chrome("./driver/chromedriver.exe")
driver.get("https://ediya.com/contents/find_store.html#c")
# '주소' 선택
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
time.sleep(3)
search_tag = driver.find_element(By.CSS_SELECTOR, value='#contentWrap > div.contents > div > div.store_search_pop > ul > li:nth-child(2) > a')
action = ActionChains(driver)
action.click(search_tag)
action.perform()
# 검색어를 입력할 공간 찾기
# 해당 페이지에서 개발자도구에서 클릭하려는 페이지의 html 값에 우클릭 > copy > copy selector
# 복사한 값을 아래 value 값에 넣어줌
time.sleep(3)
keyword = driver.find_element(By.CSS_SELECTOR, value="#keyword")
gu_list = ['강남구', '강북구', '강서구', '관악구', '광진구', '금천구', '노원구', '도봉구', '동작구',
'마포구', '서대문구', '서초구', '성북구', '송파구', '양천구', '영등포구', '은평구',
'종로구', '중구', '강동구', '구로구', '동대문구', '성동구', '용산구', '중랑구']
ediya = []
for gu in gu_list:
# 검색어 입력
time.sleep(5)
keyword.clear() # 기존에 입력한 검색어 지우기
keyword.send_keys('서울' + ' ' + gu)
# 클릭
# 해당 페이지에서 개발자도구에서 클릭하려는 페이지의 html 값에 우클릭 > copy > copy selector
# 복사한 값을 아래 value 값에 넣어줌
search_btn = driver.find_element(By.CSS_SELECTOR, value="#keyword_div > form > button")
search_btn.click()
req = driver.page_source
# html = urlopen(req).read()
soup_tmp = BeautifulSoup(req, "html.parser")
content = soup_tmp.find("div", class_ = "result_list")
contents = content.find_all("li")
for item in contents:
name = item.find("dt").text.strip()
address = item.find("dd").text.strip()
store_gu = address.split()[1]
data = {
'브랜드' : 'EDIYA',
'매장' : name,
'주소' : address,
'구' : store_gu,
}
ediya.append(data)
# 데이터 프레임에 넣기
time.sleep(3)
df_ediya = pd.DataFrame(ediya)
driver.close() # 크롬창 닫기
df_ediya.head() # 데이터프레임 출력
# 이디야는 스타벅스 근처에 있는지 분석
import matplotlib.pyplot as plt
# import matplotlib as mpl
from matplotlib import rc
import seaborn as sns
import numpy as np
plt.rcParams['axes.unicode_minus'] = False # 마이너스 부호로 인해 한글깨짐현상 방지
rc("font", family='Malgun Gothic')
%matplotlib inline
# 동일 : get_ipython().run_inline_magic("matplotlib", 'inline')
# 데이터 합치기
df_sum = pd.concat([df_sbuck,df_ediya])
df_sum.reset_index(drop=True,inplace=True)
# df_sum.tail()
cafe_cnt = df_sum.groupby(['구', '브랜드'])['매장'].count().reset_index(name = '매장개수')
df_sum["값"]=1
cafe_cnt2 = df_sum.pivot_table(index="구", columns="브랜드", values='값', aggfunc=np.sum)
plt.figure(figsize = (20, 8))
sns.barplot(
data = cafe_cnt,
x = cafe_cnt['구'],
y = cafe_cnt['매장개수'],
hue = '브랜드',
palette = 'Set2'
)
plt.show()
위 글은 제로베이스 데이터 취업 스쿨의 강의자료를 참고하여 작성되었습니다.

허재