1. 네이버 API 사용 등록
- 네이버 개발자 센터
- https://developers.naver.com/main/
- Application
- 어플리케이션 등록
- 어플리케이션 이름 ds_study
- 사용 API
- 검색
- 데이터랩(검색어트렌드)
- 데이터랩(쇼핑인사이트)
- 환경추가
- WEB 설정
- http://localhost
- Clienct ID: 4YFAD6PigZUIR1NfQmZL
- Clienct Secret: wroWePTst4
- https://developers.naver.com/apps/#/myapps/H2_6lcavpVyHW8211rUq/overview
2. 네이버 검색 API 사용하기
-
https://developers.naver.com/docs/serviceapi/search/blog/blog.md#%EB%B8%94%EB%A1%9C%EA%B7%B8 # 개발 가이드
-
urllib: http 프로토콜에 따라서 서버의 요청/응답을 처리하기 위한 모듈
-
urllib.request: 클라이언트의 요청을 처리하는 모듈
-
urllib.parse: url 주소에 대한 분석
검색: 블로그(blog)
# 네이버 검색 API예제는 블로그를 비롯 전문자료까지 호출방법이 동일하므로 blog검색만 대표로 예제를 올렸습니다.
# 네이버 검색 Open API 예제 - 블로그 검색을 사용한 것
# 파이썬을 검색했을 때 블로그에서 나타나는 결과들만 나옴
# 아래 코드는 https://developers.naver.com/docs/serviceapi/search/blog/blog.md#python 에서
# > 도큐먼트 > 서비스 API > 검색에서 > 검색 API 블로그 검색 구현 예제 > python 을 복붙한 것임
import os
import sys
import urllib.request
client_id = "4YFAD6PigZUIR1NfQmZL" # 여기에 내 id
client_secret = "wroWePTst4" # 여기에 내 시크릿
encText = urllib.parse.quote("파이썬") # quote : 한글이 들어오면 utf-8 인코딩을 해줌
url = "https://openapi.naver.com/v1/search/blog?query=" + encText # json 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # xml 결과
# 위 주소가 네이버 블로그 검색 결과는 가져오는 주소이다.
# urllib : http 프로토콜에 따라서 서버의 요청/응답을 처리하기 위한 모듈
# urllib.request : 클라이언트의 요청을 처리하는 모듈
# urllib.parse : url 주소에 대한 분석
# urllib.parse.quote : 한글 등 영어가 아닌 글자가 들어오면 utf-8 인코딩을 해줌
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode() # 200인지 확인하는 용도
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)
>>
{
"lastBuildDate":"Tue, 11 Apr 2023 23:23:18 +0900",
"total":389915,
"start":1,
"display":10,
"items":[
{
"title":"<b>파이썬<\/b>자격증 취득 독학보다 학원이 좋은 이유",
"link":"https:\/\/blog.naver.com\/hyunju7647\/223021791438",
"description":"그래서 처음으로 코딩을 배워보기 위해 <b>파이썬<\/b>자격증을 취득하게 되었습니다. <b>파이썬<\/b>자격증을 가장 먼저 취득한 이유는 기초코딩 중에서 가장 배우기 쉽다고 해서 취득하게 되었는데요. 기초코딩에는 C언어와... ",
"bloggername":"슈퍼더블디",
"bloggerlink":"blog.naver.com\/hyunju7647",
"postdate":"20230220"
},
{
"title":"<b>파이썬<\/b>학원을 다니면서 공부해야하는 이유",
"link":"https:\/\/blog.naver.com\/sow723\/223024072662",
"description":"개발자와는 전혀 관계 없던 제가 <b>파이썬<\/b>학원을 다니면서 이 쪽으로 취업에 성공할 줄이야 아무도... 그래서 일단 비전공자도 쉽게 배울 수 있다는 언어를 배우기 위해서 #<b>파이썬<\/b>학원 을 다녀보게 되었습니다.... ",
"bloggername":"Onelog",
"bloggerlink":"blog.naver.com\/sow723",
"postdate":"20230222"
},
{
"title":"<b>파이썬<\/b>학원 알뜰한 준비과정",
"link":"https:\/\/blog.naver.com\/djhyul\/223065807088",
"description":"생겨서 <b>파이썬<\/b>학원으로 갈만한 곳을 알아보기 시작했죠. 그린컴퓨터아카데미는 제가 알아보고 다니기 시작했던 학원인데 이곳에서는 기초가 된다는 <b>파이썬<\/b>이나 영상편집 IT 관련 수업들을 진행하고 있다고... ",
"bloggername":"서대전점",
"bloggerlink":"blog.naver.com\/djhyul",
"postdate":"20230405"
},
.....
----------------------------
response, response.getcode(), response.code, response.status
# response.getcode() 반환값이 200이 와야 정상이다
>>
(<http.client.HTTPResponse at 0x1e88606f3a0>, 200, 200, 200)
----------------------------
# 글자로 읽을 경우, decode utf-8 설정
print(response_body.decode("utf-8"))
>>
{
"lastBuildDate":"Tue, 11 Apr 2023 23:23:18 +0900",
"total":389915,
"start":1,
"display":10,
"items":[
{
"title":"<b>파이썬<\/b>자격증 취득 독학보다 학원이 좋은 이유",
"link":"https:\/\/blog.naver.com\/hyunju7647\/223021791438",
"description":"그래서 처음으로 코딩을 배워보기 위해 <b>파이썬<\/b>자격증을 취득하게 되었습니다. <b>파이썬<\/b>자격증을 가장 먼저 취득한 이유는 기초코딩 중에서 가장 배우기 쉽다고 해서 취득하게 되었는데요. 기초코딩에는 C언어와... ",
"bloggername":"슈퍼더블디",
"bloggerlink":"blog.naver.com\/hyunju7647",
"postdate":"20230220"
},
{
"title":"<b>파이썬<\/b>학원을 다니면서 공부해야하는 이유",
"link":"https:\/\/blog.naver.com\/sow723\/223024072662",
"description":"개발자와는 전혀 관계 없던 제가 <b>파이썬<\/b>학원을 다니면서 이 쪽으로 취업에 성공할 줄이야 아무도... 그래서 일단 비전공자도 쉽게 배울 수 있다는 언어를 배우기 위해서 #<b>파이썬<\/b>학원 을 다녀보게 되었습니다.... ",
"bloggername":"Onelog",
"bloggerlink":"blog.naver.com\/sow723",
"postdate":"20230222"
},......
검색: 책(book)
# 네이버 검색 API예제는 블로그를 비롯 전문자료까지 호출방법이 동일하므로 blog검색만 대표로 예제를 올렸습니다.
# 네이버 검색 Open API 예제 - 책 검색, 파이썬과 관련된 책 정보가 나옴
# 위 검색 블로그와 코드는 동일하다
import os
import sys
import urllib.request
client_id = "H2_6lcavpVyHW8211rUq"
client_secret = "D1XBjnKTe9"
encText = urllib.parse.quote("파이썬")
url = "https://openapi.naver.com/v1/search/book?query=" + encText # json 결과, 위에서는 blog 지금은 book
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # xml 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)
>>
{
"lastBuildDate":"Tue, 11 Apr 2023 23:26:58 +0900",
"total":863,
"start":1,
"display":10,
"items":[
{
"title":"혼자 공부하는 파이썬 (1:1 과외하듯 배우는 프로그래밍 자습서)",
"link":"https:\/\/search.shopping.naver.com\/book\/catalog\/32507605957",
"image":"https:\/\/shopping-phinf.pstatic.net\/main_3250760\/32507605957.20230328162527.jpg",
"author":"윤인성",
"discount":"19800",
"publisher":"한빛미디어",
"pubdate":"20220601",
"isbn":"9791162245651",
"description":"혼자 해도 충분하다! 1:1 과외하듯 배우는 파이썬 프로그래밍 자습서\n\n『혼자 공부하는 파이썬』이 더욱 흥미있고 알찬 내용으로 개정되었습니다. 프로그래밍이 정말 처음인 입문자도 따라갈 수 있는 친절한 설명과 단계별 학습은 그대로! 혼자 공부하더라도 체계적으로 계획을 세워 학습할 수 있도록 ‘혼공 계획표’를 새롭게 추가했습니다. 또한 입문자가 자주 물어보는 질문과 오류 해결 방법을 적재적소에 배치하여 예상치 못한 문제에 부딪혀도 좌절하지 않고 끝까지 완독할 수 있도록 도와줍니다. 단순한 문법 암기와 코딩 따라하기에 지쳤다면, 새로운 혼공파와 함께 ‘누적 예제’와 ‘도전 문제’로 프로그래밍의 신세계를 경험해 보세요! 배운 내용을 씹고 뜯고 맛보고 즐기다 보면 응용력은 물론 알고리즘 사고력까지 키워 코딩 실력이 쑥쑥 성장할 것입니다.\n\n이 책은 독학으로 파이썬을 배우는 입문자가 ‘꼭 필요한 내용을 제대로 학습’할 수 있도록 구성했습니다. 뭘 모르는지조차 모르는 입문자의 막연한 마음에 십분 공감하여 과외 선생님이 알려주듯 친절하게, 핵심적인 내용만 콕콕 집어줍니다. 책의 첫 페이지를 펼쳐서 마지막 페이지를 덮을 때까지, 혼자서도 충분히 파이썬을 배울 수 있다는 자신감과 확신이 계속될 것입니다!\n\n베타리더와 함께 입문자에게 맞는 난이도, 분량, 학습 요소 등을 적극 반영했습니다. 어려운 용어와 개념은 한 번 더 풀어쓰고, 복잡한 설명은 눈에 잘 들어오는 그림으로 풀어냈습니다. ‘혼자 공부해 본’ 여러 입문자의 초심과 눈높이가 책 곳곳에 반영된 것이 이 책의 가장 큰 장점입니다."
},
{
"title":"Do it! 점프 투 파이썬 (이미 200만명이 이 책으로 프로그래밍을 시작했다!)",
"link":"https:\/\/search.shopping.naver.com\/book\/catalog\/32456895000",
"image":"https:\/\/shopping-phinf.pstatic.net\/main_3245689\/32456895000.20230117163337.jpg",
"author":"박응용",
"discount":"16920",
"publisher":"이지스퍼블리싱",
"pubdate":"20190620",
"isbn":"9791163030911",
"description":"파이썬 4년 연속 베스트셀러 1위!\n《Do it! 점프 투 파이썬》 전면 개정판 출시!\n\n문과생도 중고등학생도 직장인도 프로그래밍에 눈뜨게 만든 바로 그 책이 전면 개정판으로 새로 태어났다! 2016년 《Do it! 점프 투 파이썬》으로 출간되었던 이 책은 약 4년 동안의 피드백을 반영하여 초보자가 더 빠르게 입문하고, 더 깊이 있게 공부할 수 있도록 개정되었다. 특히 ‘나 혼자 코딩’과 ‘코딩 면허 시험 20제’ 등 독자의 학습 흐름에 맞게 문제를 보강한 점이 눈에 띈다. 실습량도 두 배로 늘었다.\n\n4년 동안 압도적 1위! 위키독스 누적 방문 200만! 수많은 대학 및 학원의 교재 채택 등! 검증은 이미 끝났다. 코딩을 처음 배우는 중고등학생부터 나만의 경쟁력이 필요한 문과생, 데이터 분석과 인공지능\/머신러닝으로 커리어를 뻗어 나가고 싶은 직장인까지! 프로그래밍의 세계에 풍덩 빠져 보자."
},......
-------------------------검색: 쇼핑(shop)
# 네이버 검색 API예제는 블로그를 비롯 전문자료까지 호출방법이 동일하므로 blog검색만 대표로 예제를 올렸습니다.
# 네이버 검색 Open API 예제 - 파이썬 관련 쇼핑 검색
# 위와 코드는 동일하다
import os
import sys
import urllib.request
client_id = "H2_6lcavpVyHW8211rUq"
client_secret = "D1XBjnKTe9"
encText = urllib.parse.quote("파이썬")
url = "https://openapi.naver.com/v1/search/shop?query=" + encText # json 결과, 여기는 shop
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # xml 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)
>>
{
"lastBuildDate":"Tue, 11 Apr 2023 23:28:38 +0900",
"total":139653,
"start":1,
"display":10,
"items":[
{
"title":"국내제작 미니 반달 투웨이 숄더 크로스 호보백",
"link":"https:\/\/search.shopping.naver.com\/gate.nhn?id=22883016920",
"image":"https:\/\/shopping-phinf.pstatic.net\/main_2288301\/22883016920.20200517143913.jpg",
"lprice":"17000",
"hprice":"",
"mallName":"네이버",
"productId":"22883016920",
"productType":"1",
"brand":"",
"maker":"",
"category1":"패션잡화",
"category2":"여성가방",
"category3":"크로스백",
"category4":""
},
{
"title":"보테가베네타 스몰 카세트백 730848 VMAY1 8425(78102)",
"link":"https:\/\/search.shopping.naver.com\/gate.nhn?id=85577969689",
"image":"https:\/\/shopping-phinf.pstatic.net\/main_8557796\/85577969689.jpg",
"lprice":"3061000",
"hprice":"",
"mallName":"비아델루쏘",
"productId":"85577969689",
"productType":"2",
"brand":"보테가베네타",
"maker":"보테가베네타",
"category1":"패션잡화",
"category2":"여성가방",
"category3":"크로스백",
"category4":""
},......3. 상품 검색
- "몰스킨"
# 네이버 검색 API예제는 블로그를 비롯 전문자료까지 호출방법이 동일하므로 blog검색만 대표로 예제를 올렸습니다.
# 네이버 검색 Open API 예제 - 몰스킨 관련 쇼핑 검색
# 위 쇼핑 검색 코드와 동일하다, 몰스킨을 검색했을 뿐
import os
import sys
import urllib.request
client_id = "H2_6lcavpVyHW8211rUq"
client_secret = "D1XBjnKTe9"
encText = urllib.parse.quote("몰스킨") # 몰스킨을 검색함
url = "https://openapi.naver.com/v1/search/shop?query=" + encText # json 결과, 여기는 shop
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # xml 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)
>>
{
"lastBuildDate":"Tue, 11 Apr 2023 23:29:47 +0900",
"total":33204,
"start":1,
"display":10,
"items":[
{
"title":"<b>몰스킨<\/b> 노트 가죽 하드커버 감성 고급 업무용 이쁜 심플",
"link":"https:\/\/search.shopping.naver.com\/gate.nhn?id=82526953942",
"image":"https:\/\/shopping-phinf.pstatic.net\/main_8252695\/82526953942.7.jpg",
"lprice":"28800",
"hprice":"",
"mallName":"베스트펜",
"productId":"82526953942",
"productType":"2",
"brand":"몰스킨",
"maker":"",
"category1":"생활\/건강",
"category2":"문구\/사무용품",
"category3":"노트\/수첩",
"category4":"노트"
},
{
"title":"<b>몰스킨<\/b> 클래식노트 플레인 소프트커버 포켓 Pocket",
"link":"https:\/\/search.shopping.naver.com\/gate.nhn?id=30656121375",
"image":"https:\/\/shopping-phinf.pstatic.net\/main_3065612\/30656121375.20220124025746.jpg",
"lprice":"21840",
"hprice":"",
"mallName":"네이버",
"productId":"30656121375",
"productType":"1",
"brand":"몰스킨",
"maker":"",
"category1":"생활\/건강",
"category2":"문구\/사무용품",
"category3":"노트\/수첩",
"category4":"노트"
},.....
------------------
from PIL import Image
Image.open("../data/06. molskin plan.png")
3-1 gen_search_url() 만들기
- gen_search_url() : url 만드는 함수 만들기
- encText = urllib.parse.quote("몰스킨")
- url = "https://openapi.naver.com/v1/search/shop?query=" + encText # json 결과
# api_node 뭘 검색할 것인가
# search_text 어떤 단어를 검색할 것인가
# start_num 몇번째부터 검색할 것인가
# disp_num 몇개를 출력해 줄건가
# 네이버 개발자센터 > Documents > 서비스 API > 검색 > 쇼핑
# 위 페이지에서 설명을 보면서 아래 코드를 만듦
# url 만드는 함수 만들기
def gen_search_url(api_node, search_text, start_num, disp_num):
base = "https://openapi.naver.com/v1/search"
node = "/" + api_node + ".json"
param_query = "?query=" + urllib.parse.quote(search_text)
param_start = "&start=" + str(start_num)
param_disp = "&display=" + str(disp_num)
return base + node + param_query + param_start + param_disp
# 모두 str 이므로 이어서 붙을 것
----------------------------
gen_search_url("shop", "TEST", 10, 3)
# 아래와 같이 url을 만들어 준다
>>
'https://openapi.naver.com/v1/search/shop.json?query=TEST&start=10&display=3'3-2 get_result_onepage() 만들기
- url을 받으면 데이터를 요청하고, 반환받는 함수 만들기
import json
import datetime
# 우리가 만든 url 로 요청하고, 반환받는 함수 만들기
def get_result_onpage(url): # 위에서 만든 url 이 들어간다
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id", client_id)
request.add_header("X-Naver-Client-Secret", client_secret)
response = urllib.request.urlopen(request)
print("[%s] Url Request Success" % datetime.datetime.now())
return json.loads(response.read().decode("utf-8"))
---------------------
datetime.datetime.now()
>>
datetime.datetime(2021, 9, 30, 4, 54, 19, 13220)
---------------------
url = gen_search_url("shop", "몰스킨", 1, 5)
one_result = get_result_onpage(url)
>>
[2021-09-30 04:54:19.321877] Url Request Success
---------------------
one_result
>>
{'lastBuildDate': 'Thu, 30 Sep 2021 04:54:19 +0900',
'total': 28313,
'start': 1,
'display': 5,
'items': [{'title': '한정판 <b>몰스킨</b> 2022 해리포터 데일리 다이어리 포캣',
'link': 'https://search.shopping.naver.com/gate.nhn?id=28719894754',
'image': 'https://shopping-phinf.pstatic.net/main_2871989/28719894754.20210906035419.jpg',
'lprice': '31700',
'hprice': '',
'mallName': '네이버',
'productId': '28719894754',
'productType': '1',
'brand': '몰스킨',
'maker': '몰스킨',
'category1': '생활/건강',
'category2': '문구/사무용품',
'category3': '다이어리/플래너',
'category4': '다이어리'},
{'title': '<b>몰스킨</b> 클래식노트 플레인 하드 L',
'link': 'https://search.shopping.naver.com/gate.nhn?id=24031381534',
'image': 'https://shopping-phinf.pstatic.net/main_2403138/24031381534.20200904012957.jpg',
'lprice': '15330',
'hprice': '',
......
-----------------
one_result["items"][0]["title"]
>>
'한정판 <b>몰스킨</b> 2022 해리포터 데일리 다이어리 포캣'
-----------------
one_result["items"][0]["link"]
>>
'https://search.shopping.naver.com/gate.nhn?id=28719894754'
-----------------
one_result["items"][0]["lprice"]
>>
'31700'
-----------------
one_result["items"][0]["mallName"]
>>
'네이버'3-3 get_fields() 만들기
- 데이터 프레임으로 만드는 함수 만들기
one_result["items"][0]
>>
{'title': '한정판 <b>몰스킨</b> 2022 해리포터 데일리 다이어리 포캣',
'link': 'https://search.shopping.naver.com/gate.nhn?id=28719894754',
'image': 'https://shopping-phinf.pstatic.net/main_2871989/28719894754.20210906035419.jpg',
'lprice': '31700',
'hprice': '',
'mallName': '네이버',
'productId': '28719894754',
'productType': '1',
'brand': '몰스킨',
'maker': '몰스킨',
'category1': '생활/건강',
'category2': '문구/사무용품',
'category3': '다이어리/플래너',
'category4': '다이어리'}
----------------------------
import pandas as pd
# 데이터 프레임으로 만드는 함수 만들기
def get_fields(json_data):
title = [each["title"] for each in json_data["items"]] # 위에서 title 값을 가져옴
link = [each["link"] for each in json_data["items"]] # 위에서 link 값을 가져옴
lprice = [each["lprice"] for each in json_data["items"]] # 위에서 lprice 값을 가져옴
mall_name = [each["mallName"] for each in json_data["items"]] # 위에서 mallName 값을 가져옴
# 데이터 프레임으로 만들기
result_pd = pd.DataFrame({
"title": title,
"link": link,
"lprice": lprice,
"mall": mall_name,
}, columns=["title", "lprice", "link", "mall"])
return result_pd
----------------------------
# 위 get_fields 함수에 넣었으므로 데이터프레임으로 만들어져서 나온다
get_fields(one_result)

3-4 delete_tag() 만들기
- 태그 삭제하는 함수 만들기
def delete_tag(input_str):
input_str = input_str.replace("<b>", "") # <b> 이게 있으면 없는걸로 바꿔줘(없애줘)
input_str = input_str.replace("</b>", "") # </b> 이게 있으면 없는걸로 바꿔줘(없애줘)
return input_str
-------------------------
import pandas as pd
# 태그 삭제하는 함수 만들기
def get_fields(json_data):
title = [delete_tag(each["title"]) for each in json_data["items"]] # 바로 위 delete_tag 함수를 넣음
link = [each["link"] for each in json_data["items"]]
lprice = [each["lprice"] for each in json_data["items"]]
mall_name = [each["mallName"] for each in json_data["items"]]
result_pd = pd.DataFrame({
"title": title,
"link": link,
"lprice": lprice,
"mall": mall_name,
}, columns=["title", "lprice", "link", "mall"])
return result_pd
----------------------
get_fields(one_result)
url = gen_search_url("shop", "몰스킨", 1, 5)
json_result = get_result_onpage(url)
pd_result = get_fields(json_result)
>>
[2021-09-30 05:06:54.834953] Url Request Success
----------------------
pd_result

3-5 actMain() : 데이터 모으기
for n in range(1, 1000, 100):
print(n)
>>
1
101
201
301
401
501
601
701
801
901
-----------------------
# actMain() 데이터를 모으는 작업
result_mol = []
for n in range(1, 1000, 100):
url = gen_search_url("shop", "몰스킨", n, 100) # gen_search_url 함수를 쓰고
json_result = get_result_onpage(url) # get_result_onpage 함수를 쓰고
pd_result = get_fields(json_result) # get_fields 함수를 쓰고
result_mol.append(pd_result)
# 위 까지만 하면 result_mol 은 리스트형이고,
# 그안의 각각의 데이터들이 데이터프레임으로 되어있음
result_mol = pd.concat(result_mol)
>>
[2021-09-30 05:09:47.325324] Url Request Success
[2021-09-30 05:09:47.609312] Url Request Success
[2021-09-30 05:09:47.913627] Url Request Success
[2021-09-30 05:09:48.227613] Url Request Success
[2021-09-30 05:09:48.533253] Url Request Success
[2021-09-30 05:09:48.816997] Url Request Success
[2021-09-30 05:09:49.125801] Url Request Success
[2021-09-30 05:09:49.397631] Url Request Success
[2021-09-30 05:09:49.715529] Url Request Success
[2021-09-30 05:09:49.987900] Url Request Success
-----------------------
result_mol.info()
>>
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1000 entries, 0 to 99
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 title 1000 non-null object
1 lprice 1000 non-null object
2 link 1000 non-null object
3 mall 1000 non-null object
dtypes: object(4)
memory usage: 39.1+ KB
-----------------------
# 인덱스번호만 다시 수정해준다
result_mol.reset_index(drop=True, inplace=True)
# drop=True : 번호가 잘못 매겨진 index 컬럼을 없애준다
result_mol.info()
>>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 title 1000 non-null object
1 lprice 1000 non-null object
2 link 1000 non-null object
3 mall 1000 non-null object
dtypes: object(4)
memory usage: 31.4+ KB
-----------------------
result_mol.tail()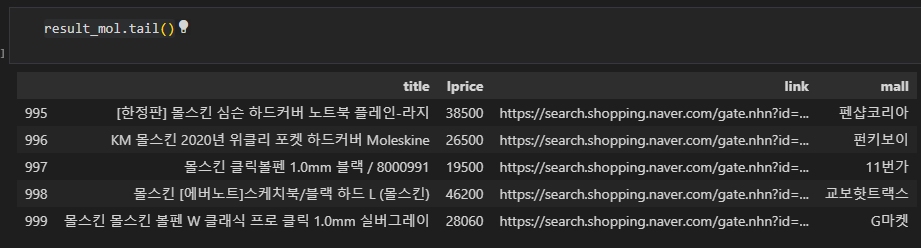
result_mol.info()
>>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 title 1000 non-null object
1 lprice 1000 non-null object
2 link 1000 non-null object
3 mall 1000 non-null object
dtypes: object(4)
memory usage: 31.4+ KB
----------------------------------------
# 가격을 숫자형으로 바꾸기
result_mol["lprice"] = result_mol["lprice"].astype("float")
result_mol.info()
>>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 title 1000 non-null object
1 lprice 1000 non-null float64
2 link 1000 non-null object
3 mall 1000 non-null object
dtypes: float64(1), object(3)
memory usage: 31.4+ KB3-6 to_excel() : xlsxwriter 를 이용해서 엑셀로 저장
# xlsxwriter 를 이용해서 저장
# !pip install xlsxwriter
--------------------------
writer = pd.ExcelWriter("../data/06_molskin_diary_in_naver_shop.xlsx", engine="xlsxwriter")
result_mol.to_excel(writer, sheet_name="Sheet1")
workbook = writer.book
worksheet = writer.sheets["Sheet1"]
worksheet.set_column("A:A", 4) # 엑셀의 A셀의 간격(넓이)을 4로 설정
worksheet.set_column("B:B", 60)
worksheet.set_column("C:C", 10)
worksheet.set_column("D:D", 10)
worksheet.set_column("E:E", 50)
worksheet.set_column("F:F", 10)
worksheet.conditional_format("C2:C1001", {"type": "3_color_scale"}) # {} 안은 엑셀함수임
writer.save()
------------------------------
!ls "../data/06_molskin_diary_in_naver_shop.xlsx"
>>
../data/06_molskin_diary_in_naver_shop.xlsx\
3-7 시각화
import matplotlib.pyplot as plt
import seaborn as sns
import platform
from matplotlib import font_manager, rc
# get_ipython().run_line_magic("matplotlib", "inline")
# # %matplotlib inline
# path = "C:/Windows/Fonts/malgun.ttf"
# if platform.system() == "Darwin":
# rc("font", family="Arial Unicode MS")
# elif platform.system == "Windows":
# font_name = font_manager.FontProperties(fname=path).get_name()
# rc("font", family=font_name)
# else:
# print("Unknown system. sorry ~ ")
# 위 실행하면 에러뜸
# 그래서 아래 실행
import matplotlib.pyplot as plt
# import matplotlib as mpl
from matplotlib import rc
plt.rcParams['axes.unicode_minus'] = False # 마이너스 부호로 인해 한글깨짐현상 방지
rc("font", family='Malgun Gothic')
%matplotlib inline
# 동일 : get_ipython().run_inline_magic("matplotlib", 'inline')
----------------------------------------
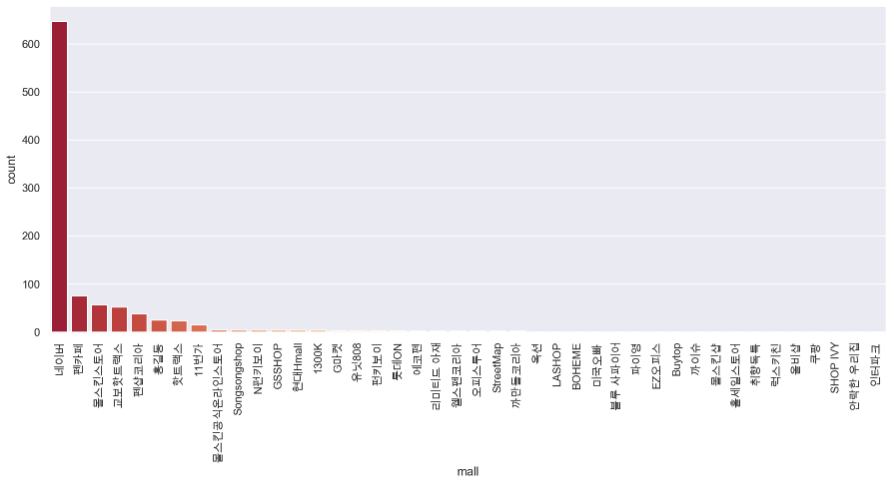
plt.figure(figsize=(15, 6))
sns.countplot(
result_mol["mall"],
data=result_mol,
palette="RdYlGn",
order=result_mol["mall"].value_counts().index
)
plt.xticks(rotation=90)
plt.show()
위 글은 제로베이스 데이터 취업 스쿨의 강의자료를 참고하여 작성되었습니다.

허재