
우선 데이터 읽기
천단위 콤마 제거 thousands=","
import numpy as np
import pandas as pd
-------------------
# 데이터 읽기
crime_raw_data = pd.read_csv("../data/02. crime_in_Seoul.csv",
thousands=",", # 천단위 콤마 제거, 숫자형으로 반환됨
encoding="euc-kr")
crime_raw_data.head()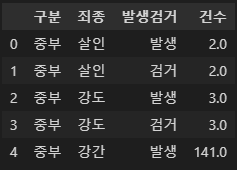
crime_raw_data.info()
>> # RangeIndex: 65534인데, 310 non-null.. 이상하다
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 65534 entries, 0 to 65533
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 구분 310 non-null object
1 죄종 310 non-null object
2 발생검거 310 non-null object
3 건수 310 non-null float64
dtypes: float64(1), object(3)
memory usage: 2.0+ MB
------------------------------------
crime_raw_data["죄종"].unique()
>> # nan 값이 있다.
array(['살인', '강도', '강간', '절도', '폭력', nan], dtype=object).isnull() :nan 만 가져오기
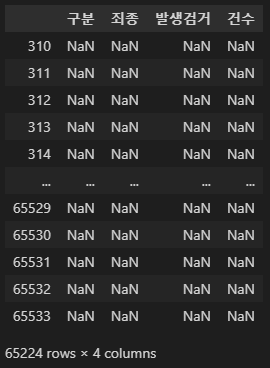
crime_raw_data[crime_raw_data["죄종"].isnull()]
>>
.notnull() :nan이 아닌 것 들만 가져오기
crime_raw_data = crime_raw_data[crime_raw_data["죄종"].notnull()]
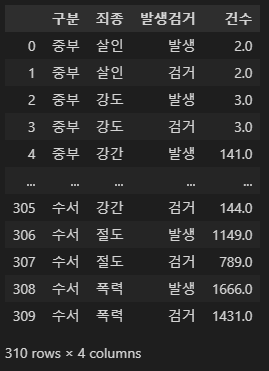
crime_raw_data
>>
crime_raw_data.info()
>>
<class 'pandas.core.frame.DataFrame'>
Int64Index: 310 entries, 0 to 309
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 구분 310 non-null object
1 죄종 310 non-null object
2 발생검거 310 non-null object
3 건수 310 non-null float64
dtypes: float64(1), object(3)
memory usage: 12.1+ KBPandas pivot_table(피봇테이블)
index : 행(가로)
column : 열(세로)
value : 값
- index, columns, values, aggfunc(연산식)
예제 데이터
df = pd.read_excel("../data/02. sales-funnel.xlsx")
df.head()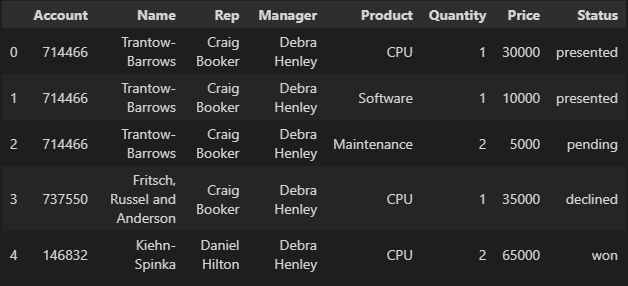
피봇 테이블로 만들기
pd.pivot_table(df, index="Name")
>> (이하 아래에선 아래 출력은 생략한다)
C:\Users\hjh\AppData\Local\Temp\ipykernel_39776\173636478.py:1: FutureWarning: pivot_table dropped a column because it failed to aggregate. This behavior is deprecated and will raise in a future version of pandas. Select only the columns that can be aggregated.
pd.pivot_table(df, index="Name")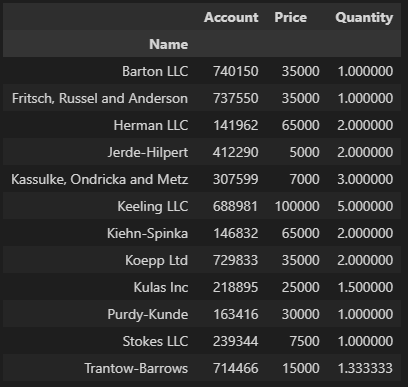
인덱스 index 설정(index="컬럼명")
- index="컬럼명"
- pd.pivot_table(df, index="Name")
- df.pivot_table(index="Name")
- 데이터는 df, 인덱스는 Name
# Name 컬럼을 인덱스로 설정
df.pivot_table(index="Name")
# 같은 표현 = pd.pivot_table(df, index="Name")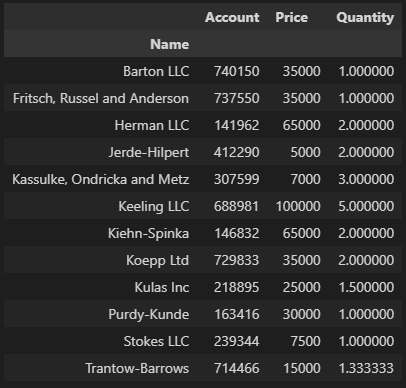
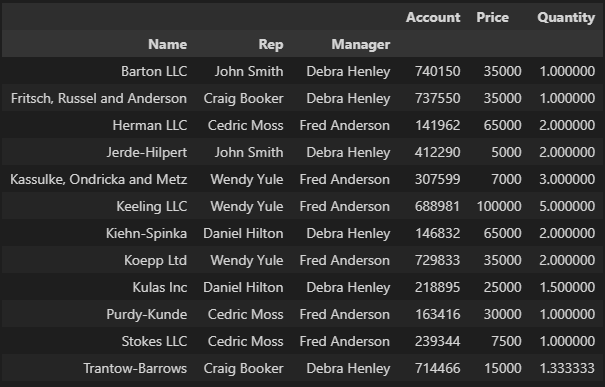
멀티 인덱스 설정
# 멀티 인덱스 설정 : 인덱스를 여러개 지정할 수 있음
df.pivot_table(index=["Name", "Rep", "Manager"])
values 지정(values="컬럼명")
# 멀티 인덱스 설정
df.pivot_table(index=["Name", "Rep"], values="Price")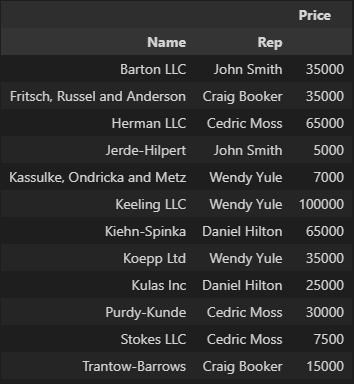
aggfunc 옵션 :values에 함수 적용
- values에 함수를 적용할 수 있다.
- 디폴트는 평균
- 합산 등의 다른 함수를 적용할 때는 aggfunc 옵션을 지정한다.
- 합계 : np.sum
- 평균 : np.mean
- 갯수 : len
연산 1개인 경우
# Price 컬럼 sum 연산 적용
df.pivot_table(index=["Name", "Rep"], values="Price", aggfunc=np.sum)
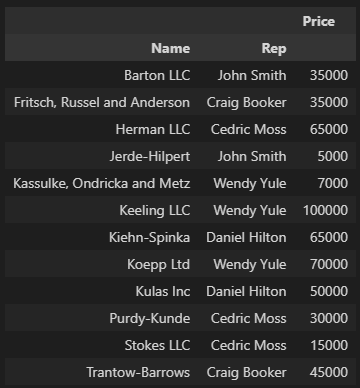
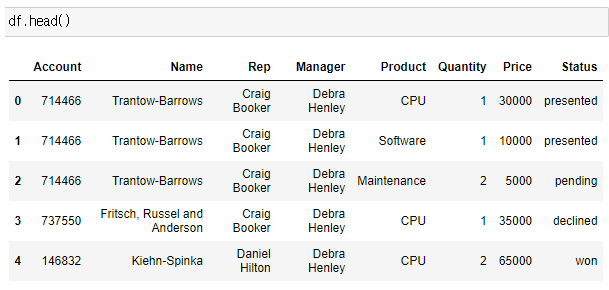
df.head()

df.pivot_table(index=["Name", "Rep"],
values="Price",
columns="Product",
aggfunc=np.sum,
fill_value=0)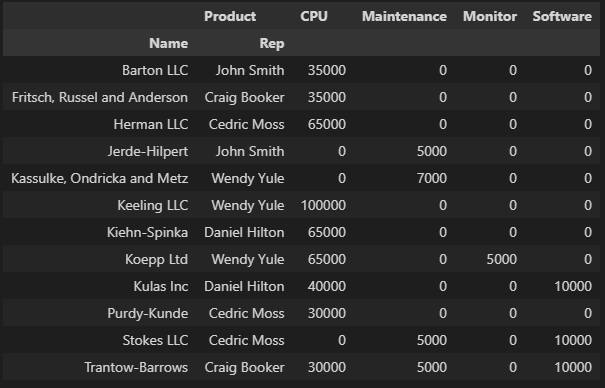
crime_raw_data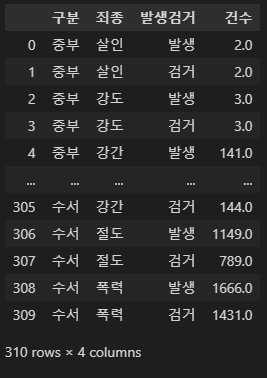
연산 2개인 이상인 경우
- 리스트를 감싸서 작성하면 된다.
# 아래는 그냥 예시
# Price 컬럼 sum 연산 적용
df.pivot_table(index=["Manager", "Rep"],
values="Price",
aggfunc=[np.sum, len])
--------------------------------------columns 옵션 : 분류 지정
crime_staion = crime_raw_data.pivot_table(
crime_raw_data,
index="구분",
columns=["죄종", "발생검거"],
aggfunc=[np.sum])
crime_staion.head()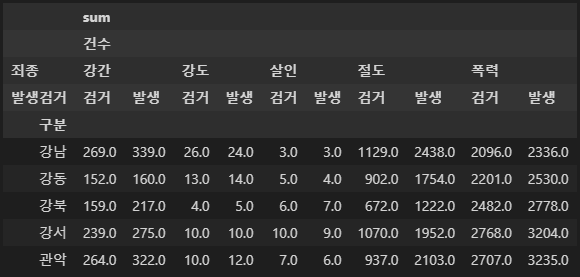
멀티인덱스, 멀티컬럼
crime_staion.columns
>>
MultiIndex([('sum', '건수', '강간', '검거'),
('sum', '건수', '강간', '발생'),
('sum', '건수', '강도', '검거'),
('sum', '건수', '강도', '발생'),
('sum', '건수', '살인', '검거'),
('sum', '건수', '살인', '발생'),
('sum', '건수', '절도', '검거'),
('sum', '건수', '절도', '발생'),
('sum', '건수', '폭력', '검거'),
('sum', '건수', '폭력', '발생')],
names=[None, None, '죄종', '발생검거'])
droplevel() : [] 다중 컬럼에서 특정 컬럼 제거
crime_staion.columns = crime_staion.columns.droplevel([0, 1])
crime_staion.columns
>>
MultiIndex([('강간', '검거'),
('강간', '발생'),
('강도', '검거'),
('강도', '발생'),
('살인', '검거'),
('살인', '발생'),
('절도', '검거'),
('절도', '발생'),
('폭력', '검거'),
('폭력', '발생')],
names=['죄종', '발생검거'])
crime_staion.head()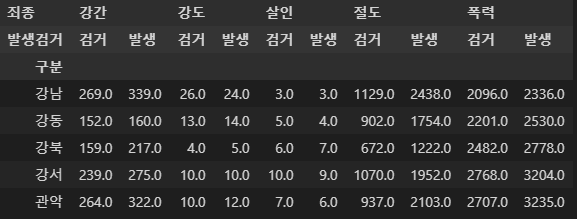
crime_staion.index
>> 인덱스 목록:(경찰서 목록)
Index(['강남', '강동', '강북', '강서', '관악', '광진', '구로', '금천', '남대문', '노원', '도봉',
'동대문', '동작', '마포', '방배', '서대문', '서부', '서초', '성동', '성북', '송파', '수서',
'양천', '영등포', '용산', '은평', '종로', '종암', '중랑', '중부', '혜화'],
dtype='object', name='구분')columns 설정(columns=컬럼명)
(아래는 구글링해서 퍼옴)
- product를 컬럼으로 지정
# product를 컬럼으로 지정
df.pivot_table(index=["Manager", "Rep"],
values="Price",
columns="Product",
aggfunc=np.sum)
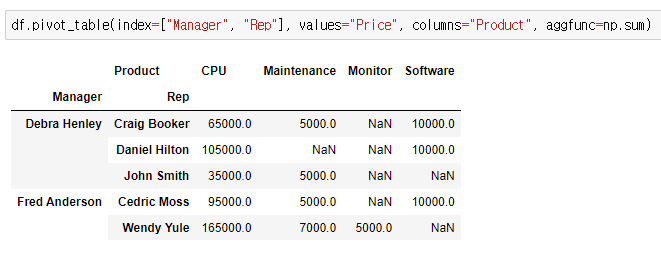
fill_value 옵션 : NaN 값 설정
- fill_value=채울 값
NaN 값 채우기 전
# product를 컬럼으로 지정
df.pivot_table(index=["Manager", "Rep"],
values="Price",
columns="Product",
aggfunc=np.sum)
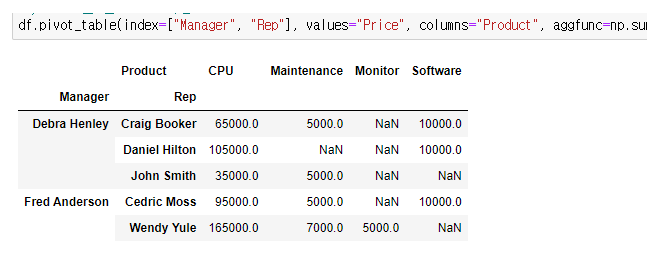
NaN 값 0으로 채운 후
# NaN 값 설정 : fill_value
df.pivot_table(index=["Manager", "Rep"],
values='Price',
columns="Product",
aggfunc=np.sum,
fill_value=0)
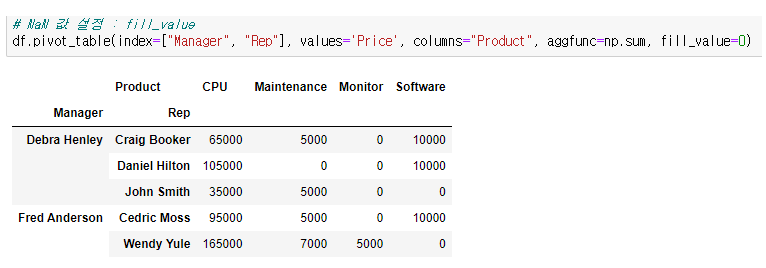
2개 이상 index, values 설정
# 2개 이상 index, values 설정
df.pivot_table(index=["Manager", "Rep", "Product"],
values=["Price", "Quantity"],
aggfunc=np.sum,
fill_value=0)
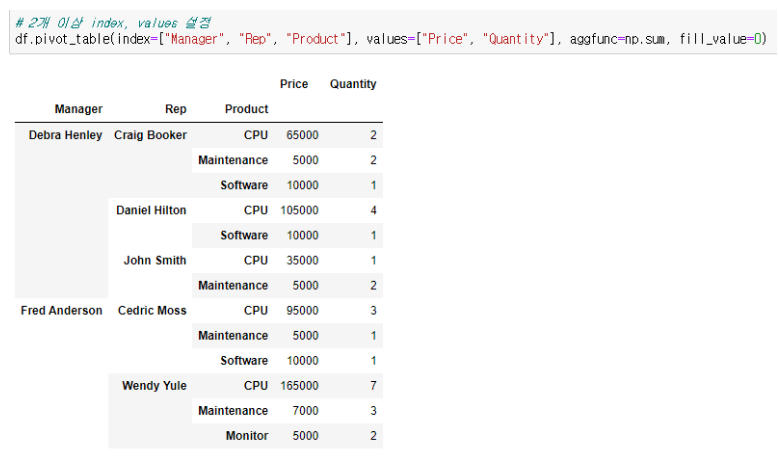
aggfunc 2개 이상 설정
# aggfunc 2개 이상 설정
df.pivot_table(
index=["Manager", "Rep", "Product"],
values=["Price", "Quantity"],
aggfunc=[np.sum, np.mean],
fill_value=0,
margins=True, # 총계(All)추가
)
Google Maps를 이용한 데이터 정리
- 경찰서 이름을 가지고 해당 경찰서가 속해있는 구를 알아내자
- 구글맵을 이용해서 구글 검색처럼 경찰서 이름을 검색해서 해당 구를 알아낼 수 있다.
- Google Map API Key 가 필요하다.
google Manps API 설치
모듈 설치
- conda install -c conda-forge googlemaps
import
- import googlemaps
실행
- gmaps_key = "___" (본인 키를 넣는다.
- gmaps = googlemaps.Client(key=gmaps_key)
단순 테스트
gmaps.geocode("서울영등포경찰서", language="ko")
>>
[{'address_components': [{'long_name': '608',
'short_name': '608',
'types': ['premise']},
{'long_name': '국회대로',
'short_name': '국회대로',
'types': ['political', 'sublocality', 'sublocality_level_4']},
{'long_name': '영등포구',
'short_name': '영등포구',
'types': ['political', 'sublocality', 'sublocality_level_1']},
{'long_name': '서울특별시',
'short_name': '서울특별시',
'types': ['administrative_area_level_1', 'political']},
{'long_name': '대한민국',
'short_name': 'KR',
'types': ['country', 'political']},
{'long_name': '150-043',
'short_name': '150-043',
'types': ['postal_code']}],
'formatted_address': '대한민국 서울특별시 영등포구 국회대로 608',
'geometry': {'location': {'lat': 37.5260441, 'lng': 126.9008091},
'location_type': 'ROOFTOP',
'viewport': {'northeast': {'lat': 37.5273930802915,
'lng': 126.9021580802915},
'southwest': {'lat': 37.5246951197085, 'lng': 126.8994601197085}}},
'partial_match': True,
'place_id': 'ChIJ1TimJLaffDURptXOs0Tj6sY',
'plus_code': {'compound_code': 'GWG2+C8 대한민국 서울특별시',
'global_code': '8Q98GWG2+C8'},
'types': ['establishment', 'point_of_interest', 'police']}]tmp = gmaps.geocode("서울영등포경찰서", language="ko")
tmp[0].get("geometry")["location"]["lat"]
>> 37.5260441
- 구글맵API에서 데이터 얻기
- 전체 결과 크기가 1인 list 형이라서 tmp[0]으로 접근.
- 큰 리스트 안에 dict 형이다
- dict 형에서 데이터를 얻는 get명령을 사용
- 전체 주소에서 필요한 구 이름만 가져오기
tmp[0].get("formatted_address").split()[2]
>> '영등포구'crime_staion.head()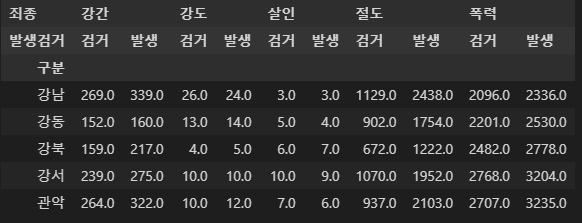
- 구별, 위도, 경도 컬럼 만들어서 nan 값으로 채우기 > 반복문 사용위함
crime_staion["구별"] = np.nan
crime_staion["lat"] = np.nan
crime_staion["lng"] = np.nan
crime_staion.head()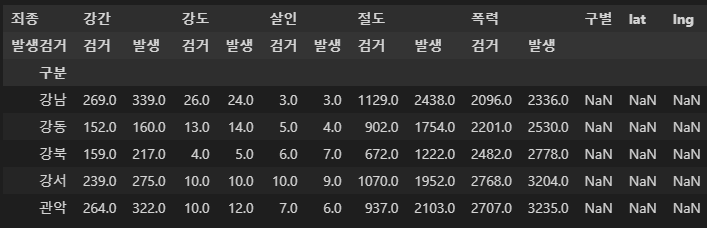
iterrows()
- Pandas 데이터 프레임은 대부분은 2차원
- 이럴때 for 문을 사용하면 n번째라는 지정을 반복해서 가독률이 떨어짐
- Pandas 데이터 프레임으로 반복문을 만들때 iterrows() 라는 옵션을 사용하면 편함.
- 받을 때, 인덱스와 내용으로 나누어 받는 것만 주의.
count = 0
for idx, rows in crime_staion.iterrows():
station_name = "서울" + str(idx) + "경찰서"
tmp = gmaps.geocode(station_name, language="ko")
tmp_gu = tmp[0].get("formatted_address")
lat = tmp[0].get("geometry")["location"]["lat"]
lng = tmp[0].get("geometry")["location"]["lng"]
crime_staion.loc[idx, "lat"] = lat
crime_staion.loc[idx, "lng"] = lng
crime_staion.loc[idx, "구별"] = tmp_gu.split()[2]
print(count) # 동작 확인용
count += 1
>>
0
1
2
...
30
crime_station = crime_staion
crime_station.head()
위아래 두 줄의 컬럼들을 하나로 합치기
tmp = [
crime_staion.columns.get_level_values(0)[n] + crime_station.columns.get_level_values(1)[n]
for n in range(0, len(crime_station.columns.get_level_values(0)))
]
tmp
>>
['강간검거',
'강간발생',
'강도검거',
'강도발생',
'살인검거',
'살인발생',
'절도검거',
'절도발생',
'폭력검거',
'폭력발생',
'구별',
'lat',
'lng']crime_station.columns = tmp
crime_station.head()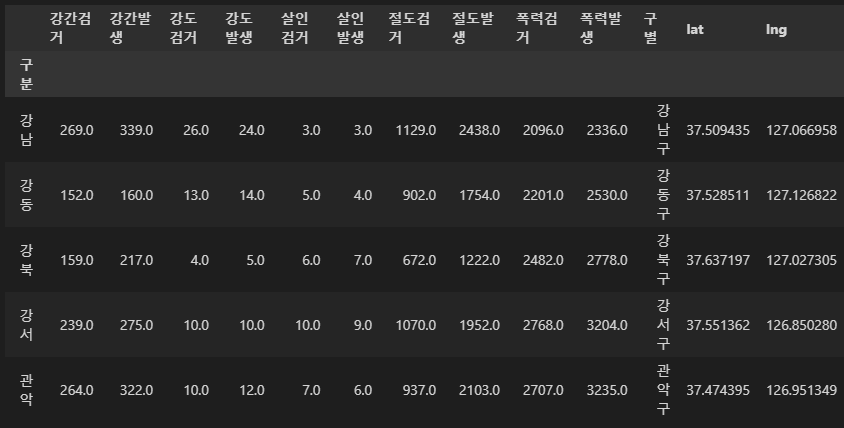
데이터 저장
crime_station.to_csv("../data/test.csv", sep=",", encoding="utf-8")구별 데이터로 정리
데이터 읽어오기
pd.read_csv("../data/test.csv")
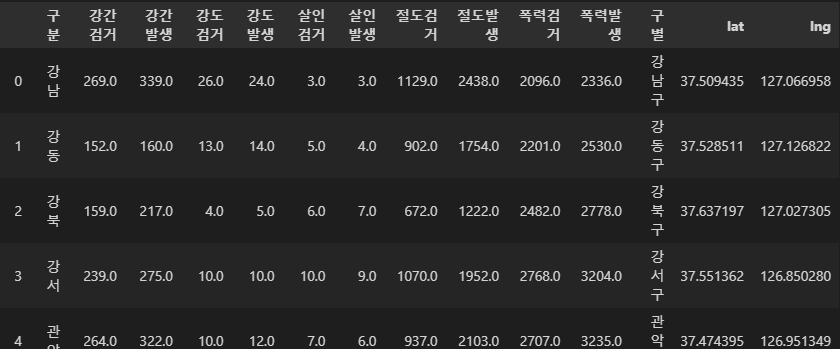
index_col : 원하는 컬럼을 인덱스로 지정
- index_col 미기재 : 인덱스로 번호가 들어감
- index_col = 0 : 컬럼중 왼쪽 첫번째 컬럼이 인덱스로 지정됨
- index_col = "컬럼" : 지정한 컬럼이 인덱스로 지정됨
crime_anal_station = pd.read_csv("../data/test.csv", index_col=0, encoding="utf-8")
crime_anal_station.head()
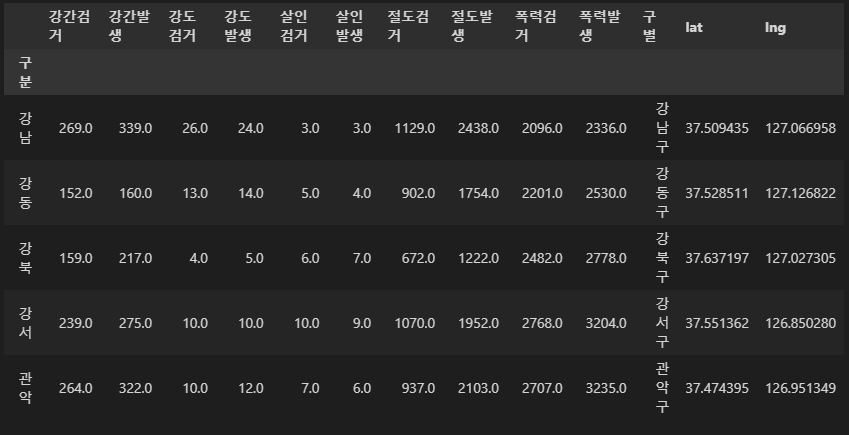
axis : 축
- axis는 어떤 걸 기준으로 값을 구할지를 명시해주는 '축'과 같다
- 아래에 그림에서 x,y,z축들을 axis로 표현한 것도 같은 맥락이다.
- axis=1은 책을 옆으로 쌓는 것과 같다. 가로로 쌓여서 진행방향이 행 방향이다.
- axis=0은 책을 위로 쌓는 것과 같다. 눕혀진 책이 차곡차곡 세로로 쌓이는 형태라 진행방향이 열 방향이다.
- 즉 axis=0 : 열, axis=1 : 행
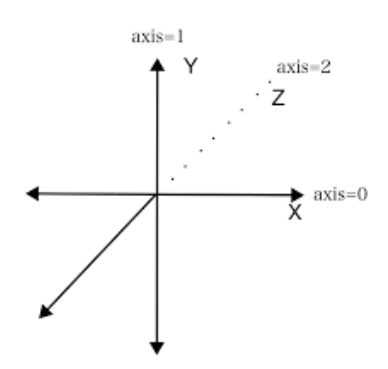
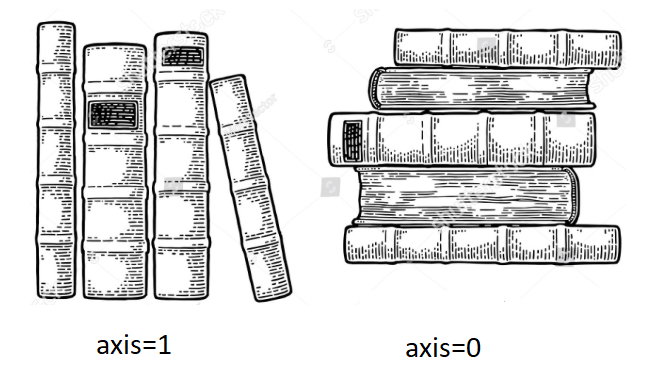
- axis=0은 각 열(row)의 모든 행(column)에 대해 동작한다. 진행방향 세로. 결과값이 행으로 나타남.
- axis=1은 각 행(column)의 모든 열(row)에 대해 동작한다. 진행방향 가로. 결과값이 열로 나타남.
컬럼 제거 : del, drop
del df['컬럼명']
drop
-
작은 예제 1. (컬럼 값들이 인덱스를 축으로 정렬되어 있다)
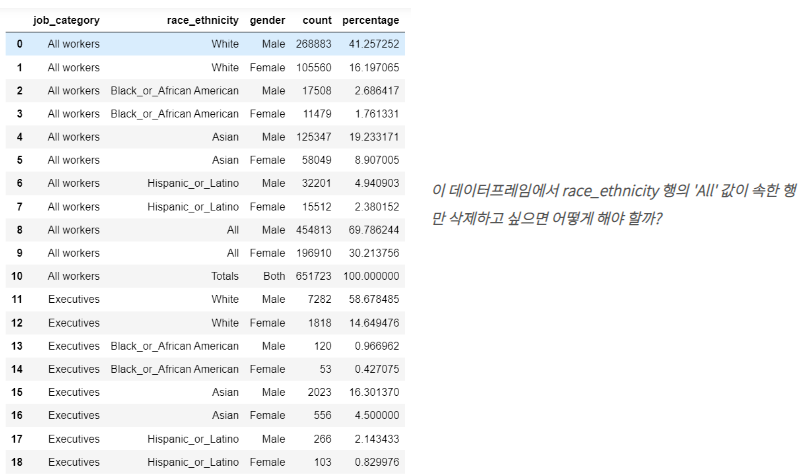
-
drop 안쓰고 없애기
condition=df['race_ethnicity']!='All'- drop의 기본 형태
df.drop('row or column 이름', axis='index or 0' or 'columns or 1')
- index 값을 지우고 싶을 땐 axis=0, column을 지우고 싶을 땐 axis=1을 붙어주면 되는데, axis를 생략하고 싶으면 아래처럼 쓰자.
df.drop(index='row이름') / df.drop(columns='column이름')
- 이제 위의 사례를 수행해보자. 'race_ethnicity'가 'All'인 행들을 모두 삭제하려면 먼저 이 행들의 index 번호를 알아야 한다. column 값들은 모두 index를 축으로 정렬되어 있기 때문이다.
A = df2[df2['race_ethnicity'] == 'All'].index
>> # A의 출력값으로 위와 같이 All이 속한 모든 index 번호가 정렬되어 나오는 것을 확인할 수 있다.
Int64Index([8, 9, 19, 20, 30, 31, 41, 42], dtype='int64')- 이제 A를 drop 함수에 적용하려면 axis를 index로 걸어서 해야 한다. A가 'All'들의 index 번호를 보유하고 있기 때문이다. 어떤 특정한 조건을 걸고 싶을 땐 A 자리에 데이터프레임이 아닌 인덱스를 제공해야 에러없이 정상적으로 작동하는 것을 꼭 기억하자.
df2.drop(A,axis='index',inplace=True)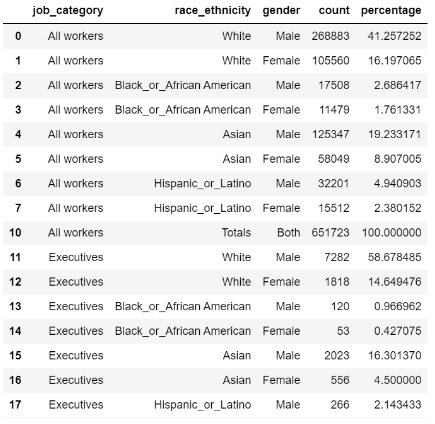
-
작은 예제 1. 끝
-
작은 예제 2. 아래 데이터프레임에 drop, mean, median, rank 함수를 적용하며 axis의 개념을 이해해보자.
df=pd.DataFrame(dict1)
df
>>>
name english_score math_score
0 dongwook 50.0 86
1 sineui 89.0 31
2 ikjoong 68.0 91
3 yoonsoo NaN 75
df.drop([1,2],axis=0)
>>>
name english_score math_score
0 dongwook 50.0 86
3 yoonsoo NaN 75
drop 함수에 파라미터로 삭제할 열을 넣고 axis=0을 넣고 살펴보니
세로로 차곡차곡 쌓여있던 인덱스 1,2번의 책들만 삭제됐다. axis 매개변수 앞에는 삭제할 row 이름이나 column 이름을 지정해주면 선택적으로 삭제할 수 있다.
df.drop('english_score',axis=1)
>>>
name math_score
0 dongwook 86
1 sineui 31
2 ikjoong 91
3 yoonsoo 75
이번엔 axis=1로 했더니 영어점수 열에 속한 모든 레코드들이 삭제된 걸 확인할 수 있다.
참고로 drop은 기존 df을 건들이지 않고 새로운 df을 만들어서 리턴하므로 'inplace=True'를 추가해야 기존 df에 결과값이 저장된다.
mean() : 평균
df[['english_score','math_score']].mean(axis=0)
>>>
english_score 69.00
math_score 70.75
dtype: float64
mean(axis=0)은 직역하면 행(row)들의 평균을 구한다. 이다.
앞에 df[['english_score','math_score']] 라고 특정 열을 기준으로 데이터프레임 범위를 지정해줬으니 'english_score','math_score'열들의 라는 말이 추가된다.
합치면 english_score','math_score'열(column)에 포함된 행(row)들의 평균을 구한다.
얼핏 보면 가로 방향으로 평균을 구해야 될 것 같아서 헷갈리지만, axis=0이 열 방향으로 작동한다는 걸 생각하면 각 열의 평균을 구하는 결과값이 나오는 걸 이해할 수 있다.
df[['english_score','math_score']].mean(axis=1)
>>>
0 68.0
1 60.0
2 79.5
3 75.0
dtype: float64
역시 옆으로 쌓이는 책을 생각해보면, axis=1은 행 방향으로 진행한다.
0 인덱스의 english_score의 값(50.0)과 math_score의 값(86)의 평균은 68.0
각 행(row)에 포함된 각 열(column) 값의 평균이 구해졌다.
median() : 중간값
df[['english_score','math_score']].mean(axis=1)
>>>
df.median(axis=0)
>>>
english_score 68.0
math_score 80.5
dtype: float64
median도 mean 함수와 비슷한 결과값이 리턴된다.
median은 값들의 중간값을 알려주는 함수인데, 이런 함수들은 문자열은 취급하지 않으니 당연히 'name'열 값들은 계산되지 않았다.
df.median(axis=1)
>>>
0 76.0
1 88.0
2 68.0
3 68.0
dtype: float64
rank() : 순위
df[['english_score','math_score']].rank(axis=0)
>>>
english_score math_score
0 1.0 3.0
1 3.0 1.0
2 2.0 4.0
3 NaN 2.0
rank 함수는 각 행이나 열의 안에 있는 요소들끼리의 순위를 매긴다.
진행방향이 세로인 axis=0을 매개로 해줬으니 각 열들 안에서 순위가 매겨진다. 결측값은 순위 안매겨짐(깍두기).
df[['english_score','math_score']].rank(axis=1)
>>>
english_score math_score
0 1.0 2.0
1 2.0 1.0
2 1.0 2.0
3 NaN 1.0
rank(axis=1)은 가로 방향에 있는 레코드끼리 순위를 매긴다.
0 인덱스의 학생은 영어를 수학보다 잘한다. 1 인덱스의 학생은 그 반대.
- 작은 예제 2. 끝
- pivot_table을 이용해서 구별로 정리하자
- pivot_table의 func을 sum으로 잡자
- 필요없는 컬럼은 제거(del)
crime_anal_gu = pd.pivot_table(crime_anal_station, index="구별", aggfunc=np.sum)
del crime_anal_gu["lat"]
crime_anal_gu.drop("lng", axis=1, inplace=True)
crime_anal_gu.head()
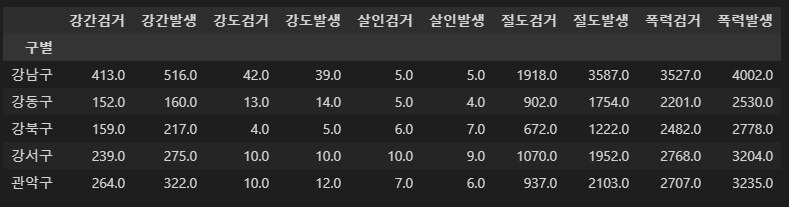
- 검거율을 만들자
crime_anal_gu["강도검거"] / crime_anal_gu["강도발생"]
>>
구별
강남구 1.076923
강동구 0.928571
강북구 0.800000
강서구 1.000000
관악구 0.833333
광진구 0.545455
구로구 1.300000
금천구 1.000000
노원구 1.500000
도봉구 1.000000
동대문구 1.200000
동작구 1.000000
마포구 1.750000
서대문구 0.800000
서초구 0.769231
성동구 1.666667
성북구 1.000000
송파구 0.800000
양천구 1.000000
영등포구 0.736842
용산구 1.111111
은평구 0.777778
종로구 0.750000
중구 0.875000
중랑구 1.000000
dtype: float64div() : 나누기
- 다수의 컬럼을 다수의 컬럼으로 나누기
num = ["강간검거", "강도검거", "살인검거", "절도검거", "폭력검거" ]
den = ["강간발생", "강도발생", "살인발생", "절도발생", "폭력발생" ]
crime_anal_gu[num].div(crime_anal_gu[den].values).head()
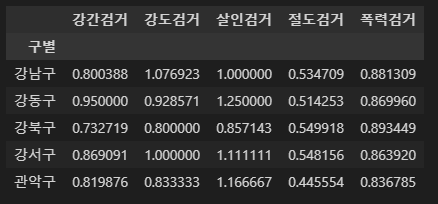
- 다수의 컬럼을 다수의 컬럼으로 나눈 후, 새로운 컬럼들에 각각 넣기
taget = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율" ]
num = ["강간검거", "강도검거", "살인검거", "절도검거", "폭력검거" ]
den = ["강간발생", "강도발생", "살인발생", "절도발생", "폭력발생" ]
crime_anal_gu[taget] = crime_anal_gu[num].div(crime_anal_gu[den].values) * 100
crime_anal_gu.head()
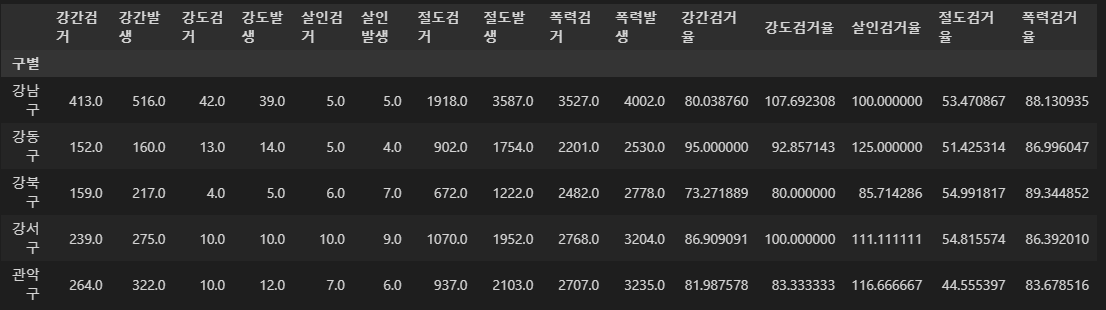
- 필요없는 컬럼 지우기
del crime_anal_gu["강간검거"]
del crime_anal_gu["강도검거"]
del crime_anal_gu["살인검거"]
del crime_anal_gu["절도검거"]
del crime_anal_gu["폭력검거"]
crime_anal_gu.head()
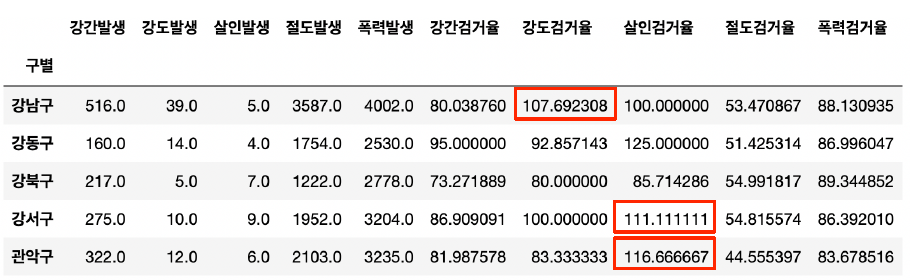
- 검거율이 100을 넘을 수 없는데 100이 넘는 게 있다.
- 강제로 100 이상의 수치는 100으로 만든다.
- 100보다 큰 숫자찾아서 100으로 맞추기
crime_anal_gu[crime_anal_gu[taget] > 100] = 100
crime_anal_gu.head()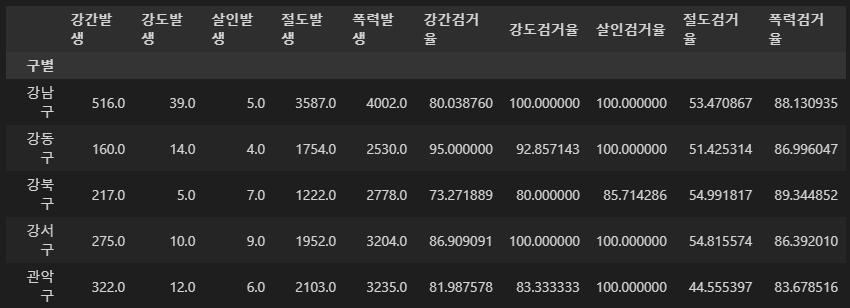

rename() 컬럼 이름 바꾸기
- 컬럼 이름 바꾸기
crime_anal_gu.rename(columns={"강간발생":"강간",
"살인발생":"살인",
"폭력발생":"폭력",
"강도발생":"강도",
"절도발생":"절도"},
inplace=True)
crime_anal_gu.head()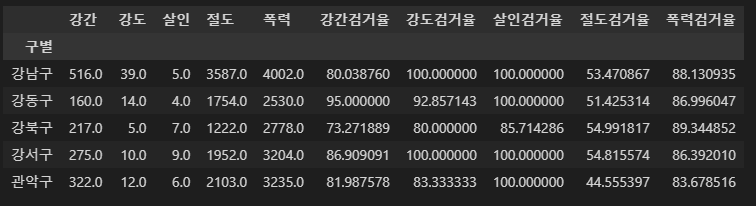
범죄 데이터 정렬을 위한 데이터 정리
정규화
- 본래의 데이터프레임은 두고, 정규화된 데이터를 따로 만들자
- 최고값을 1로 두고, 최소값은 0으로.
col = ["살인", "강도", "강간", "절도", "폭력"]
crime_anal_norm = crime_anal_gu[col] / crime_anal_gu[col].max()
crime_anal_norm.head()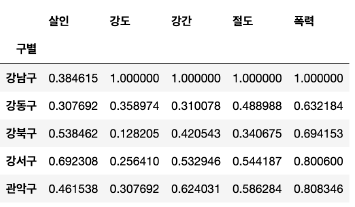
col2 = ["살인검거율", "강도검거율", "강간검거율", "절도검거율", "폭력검거율"]
crime_anal_norm[col2] = crime_anal_gu[col2]
crime_anal_norm.head()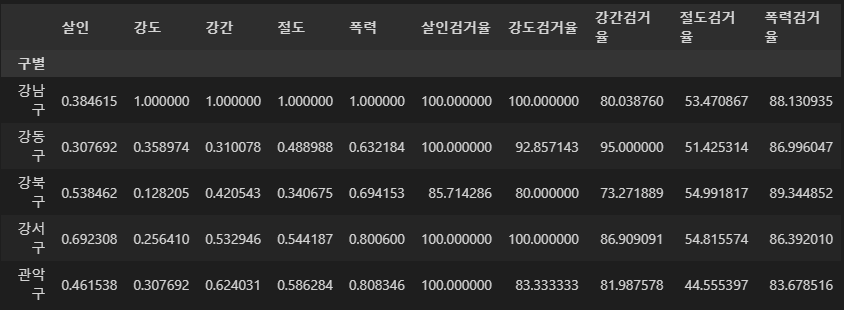
- 데이터 정리 완료
- 구별 CCTV 자료에서 인구수와 CCTV 수 가져오기
result_CCTV = pd.read_csv("../data/01. CCTV_result.csv", index_col="구별", encoding="utf-8")
result_CCTV.head()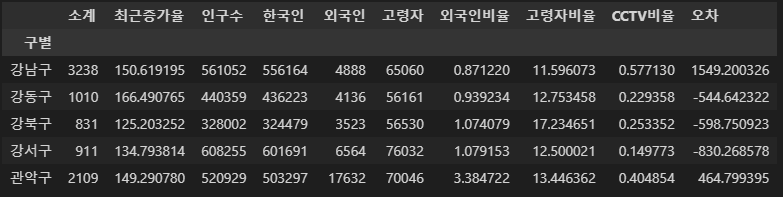
crime_anal_norm[["인구수", "CCTV"]] = result_CCTV[["인구수", "소계"]]
crime_anal_norm.head()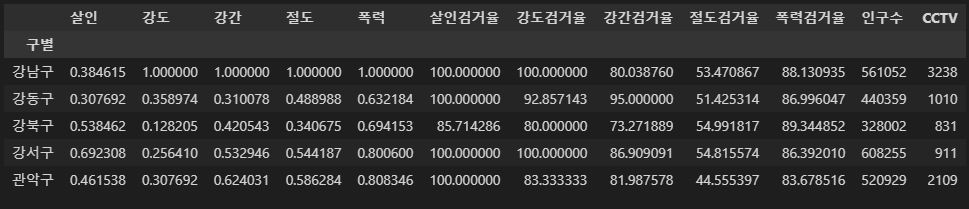
- 정규화된 범죄발생 건수 전체의 평균을 구해서 범죄의 대표값으로 사용하자
col = ["강간", "강도", "살인", "절도", "폭력"]
crime_anal_norm["범죄"] = np.mean(crime_anal_norm[col], axis=1)
crime_anal_norm.head()

- 검거율의 평균을 구해서 검거의 대표값으로 사용하자
col = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율"]
crime_anal_norm["검거"] = np.mean(crime_anal_norm[col], axis=1)
crime_anal_norm.head()
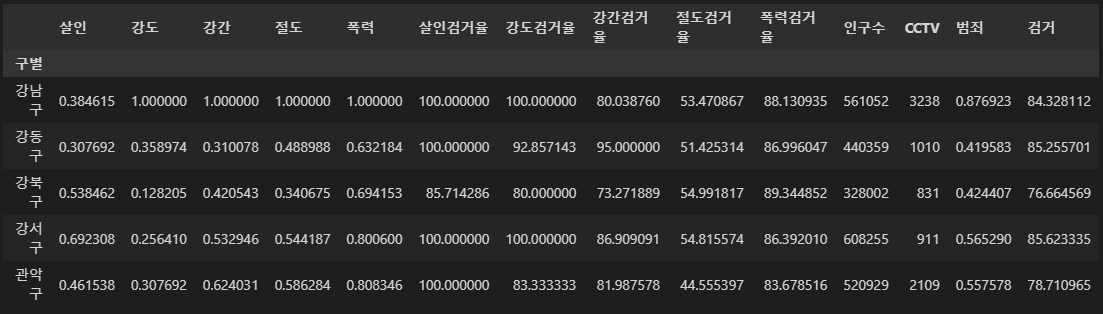
crime_anal_norm
위 글은 제로베이스 데이터 취업 스쿨의 강의자료를 참고하여 작성되었습니다.
