
DML 튜닝
DML 성능에 영향을 미치는 요소
인덱스와 DML 성능
- 인덱스는 정렬된 자료구조이기 때문에 레코드의 삽입, 삭제, 갱신에 따라 인덱스 레코드 또한 변경되어야 한다.
- 따라서 인덱스가 많을수록 DML 성능을 저하시킨다.
DML: 데이터 조작어 - 레코드 조회, 삽입, 삭제, 갱신
무결성 제약과 DML 성능
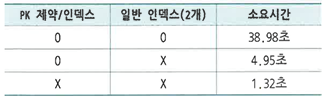
- PK, FK 제약은 실제 데이터를 조회해 보아야 하기 때문에 성능에 큰 영향을 미친다.
조건절과 DML 성능
SELECT문과 마찬가지로 DML문에도 인덱스 튜닝 원리를 적용할 수 있다.
서브쿼리와 DML 성능
SELECT문과 마찬가지로 DML문에도 조인 튜닝 원리를 적용할 수 있다.
Redo 로깅과 DML 성능
-
Redo 로그는 트랜잭션 데이터가 어떤 이유에서건 유실됐을 때, 트랜잭션을 재현함으로써 유실 이전 상태로 복구하는데 사용한다.
-
DML을 수행할 때마다 Redo 로그를 생성해야 하므로 Redo 로깅은 DML 성능에 영향을 미친다.
-
Insert 작업에 대해 Redo 로깅의 생략이 가능한다.
-
Redo 로그의 용도
- Datebase Recovery - 물리적으로 디스크가 깨지는 등의 media Fail 발생 시 데이터베이스를 복구하기 위해 사용한다.
- Cashe Recovery - 버퍼캐시에 저장된 변경사항이 디스크 상의 데이터 블록에 아직 기록되지 않은 상태에서 인스턴스가 비정상적으로 종료될 때 트랜잭션 데이터를 복구하기 위해 사용한다.
- Fast Commit - 변경된 메모리 버퍼블록을 디스크 상의 데이터 블록에 반영하는 작업은 랜덤 액세스 방식으로 이루어지므로 느리다. 반면 로그는 따라서 트랜잭션에 의한 변경사항을 우선 Append 방식으로 빠르게 로그 파일에 기록하고, 변경된 메모리 버퍼블록과 데이터파일 블록 간 동기화는 나중에 배치 방식으로 일괄 수행한다.
Undo 로깅과 DML 성능
-
Undo에는 변경된 블록을 이전 상태로 되돌리는데 필요한 정보를 로깅한다.
-
DML을 수행할 때마다 Undo를 생성해야 하므로 Undo 로깅은 DML 성능에 영향을 미친다.
-
오라클에서는 Undo 로그를 생략하는 방법이 제공되지 않는다.
-
Undo 용도
- Transaction Rollback: 트랜잭션에 의한 변경사항을 최종 커밋하지 않고 롤백하고자 할 때 Rollback 데이터 이용
- Transaction Recovery: 인스턴스 Crash 발생 후 Redo를 이용해 최종 커밋되지 않은 변경사항까지 모두 복구된다. 따라서 시스템이 셧다운된 시점에 아직 커밋되지 않았던 트랜잭션들을 모두 롤백해야 하는데, 이때 Undo 데이터 사용
- Read Consistency: 읽기 일관성을 위해 사용된다. 데이터를 읽다가 블록이 변경되어도 읽기를 수행한 시점의 데이터를 읽을 수 있도록 쿼리 시작 시점으로 Undo 데이터를 적용한다.
Lock과 DML 성능
- Lock은 트랜잭션 격리성 수준에 따라 DML 성능에 직접적인 영향을 미친다.
커밋과 DML 성능
- 커밋은 DML과 별개로 실행하지만, DML을 끝내려면 커밋까지 완료해야 한다.
- 특히 DML이 Lock에 의해 블로킹된 경우, 커밋은 DML 성능과 직결된다.
- 이때 DML을 완료할 수 있게 Lock을 푸는 열쇠가 바로 커밋이다.
DB 버퍼캐시
- 서버 프로세스는 버퍼캐시를 통해 데이터를 읽고 쓴다.
- DBWR(Database Writer) 프로세스를 통해 버퍼캐시에서 변경된 블록(Dirty 블록)을 모아 주기적으로 데이터파일에 일괄 기록한다.
Redo 로그버퍼
- 버퍼캐시는 휘발성이므로 DBWR가 버퍼캐시에 가한 변경사항(Dirty 블록)을 Redo 로그에도 기록한다.
- 따라서 버퍼캐시 데이터가 유실되더라도 Redo 로그를 이용해 언제든 복구할 수 있다.
- 하지만 Redo 로그도 파일이기 때문에 Append 방식으로 기록하더라도 디스크 I/O는 느리다. 이를 해결하기위해 오라클은 로그버퍼를 이용한다.
- Redo 로그 파일에 기록하기 전에 먼저 로그버퍼에 기록한다. 로그버퍼에 기록한 내용은 나중에 LGWR(Log Writer) 프로세스가 Redo 로그파일에 일괄 기록한다.
- LGWR 프로세스가 Redo 로그를 기록하는 작업은 디스크 I/O
트랜잭션 데이터 저장 과정
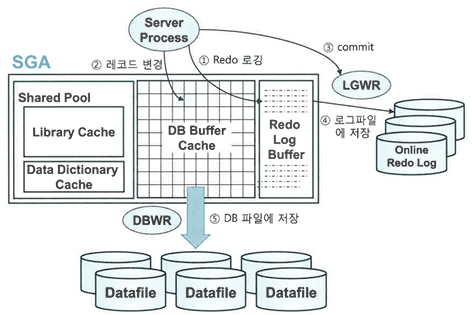
① DML문을 실행하면 Redo 로그버퍼에 변경사항을 기록한다.
② 버퍼블록에서 데이터를 변경(추가/수정/삭제)한다. 물론 버퍼캐시에서 블록을 찾지못하면 데이터파일에서 읽는 작업부터 한다.
③ 커밋
④ LGWR 프로세스가 Redo 로그버퍼 내용을 로그파일에 일괄 저장한다.
⑤ DBWR 프로세스가 변경된 버퍼블록들은 데이터파일에 일괄 저장한다.
- 메모리 버퍼캐시는 휘발성이기 때문에 Redo 로그가 필요하다.
- 하지만 Redo 로그마저 휘발성인 로그버퍼에 기록한다.
- 이를 해결하기 위해 DBWR과 LGWR 프로세스는 '주기적으로' 깨어나 각각 Dirty 블록과 Redo 로그버퍼를 파일에 기록한다.
- 그래서 '적어도 커밋시점'에는 Redo 로그버퍼 내욜을 로그파일에 기록한다. 이를 Log Force at Commit이라 부른다.
- 서버 프로세스가 변경한 버퍼블록들을 디스크에 기록하지 않았더라도 커밋 시점에 Redo 로그를 디스크에 기록했다면, 기 순간부터 트랜잭션의 영속성은 보장된다.
One SQL
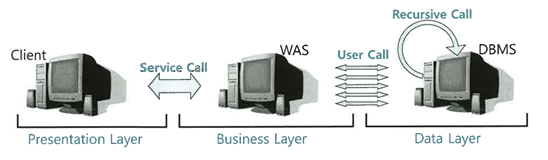
- SQL을 실행할 때마다 Parse, Execute, Fetch Call 단계를 거치기 때문에 데이터베이스 Call이 많으면 성능이 느릴 수 밖에 없다.
- 특히 네트워크를 경유하는 User Call이 성능에 미치는 영향은 매우 크다.
- 따라서 가급적 One SQL로 구현하려고 노력해야 한다.
- One SQL로 구현할 때 Insert Into Select, 수정가능 조인 뷰, Merge 문을 주로 사용한다.
- 만약 One SQL로 구현하기 힘들다면 Array Processing을 활용하면 좋다.
Insert Into Select
- 데이터를 조회한 후 애플리케이션으로 가져오고 다시 데이터베이스에 삽입하는 대신, 데이터베이스 내부에서 처리 -> 네트워크 감소
Array Processing
- 배열을 사용하여 DML 작업을 한번에 처리하는 방식
- Call 횟수를 획기적으로 줄일 수 있다.
수정가능 조인 뷰
- ?
Merge문 활용
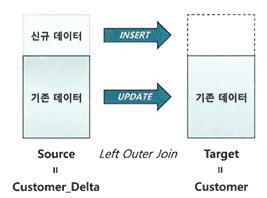
- Merge문은 Source 테이블 기준으로 Target 테이블과 Left Outer 방식으로 조인해서 조인에 성공하면 Update, 실패하면 Insert 한다.
- 아래와 같이 Update와 Insert를 선택적으로 처리할 수도 있다.

- 또한 이미 저장된 데이터를 조건에 따라 지우는 기능도 제공한다. 이때 조인에 성공한 데이터만 삭제가 가능하다. 즉, source 테이블과 target 테이블에 모두 존재하는 필드만 삭제가 가능하다.
- select + (insert or update) 이렇게 2번 수행할 SQL을 Merge를 통해 SQL 1번만에 수행 가능하다.
Direct Path I/O
- 온라인 트랜잭션은 기준성 데이터, 특정 고객, 특정 상품, 최근 거래 등을 반복적으로 읽기 때문에 버퍼캐시가 성능 향상에 도움을 준다.
- 하지만 정보계 시스템(DW/OLAP)이나 배치 프로그램에서 사용하는 SQL은 주로 대량 데이터를 처리하기 때문에 버퍼캐시를 경유하는 I/O가 오히려 성능을 떨어뜨릴 수 있다.
- 대량의 데이터를 읽고 쓸 때는 버퍼캐시에서 블록을 찾을 가능성이 거의 없기 때문에 오히려 성능이 안좋을 수 있다. 또한 대량 블록을 건건이 디스크로부터 버퍼캐시에 적재하고서 읽어야하는 부담도 크다.
- 따라서 버퍼캐시를 경유하지 않고 곧바로 데이터 블록을 읽고 쓸 수 있도록 하는 기능이 Direct Path I/O이다.
- 오라클에서 Direct Path I/O 기능이 작동하는 경우
- 병렬 쿼리로 Full Scan을 수행할 때
- 병렬 DML을 수행할 때
- Direct Path Insert를 수행할 때
- Temp 세그먼트 블록들을 읽고 쓸 때
- direct 옵션을 지정하고 export를 수행할 때
- nocache 옵션을 지정한 LOB 컬럼을 읽을 때
- 이 중 1-3이 가장 중요하고 활용도가 높다.
병렬 쿼리
- 병렬쿼리는
parallel또는parallel_index힌트로 사용할 수 있다.

- 위처럼 병렬도를 4로 지정하면 성능이 4배 빨라지는게 아니라 수십 배 빨라진다.
- 이는 버퍼캐시를 탐색하지 않고, 디스크로부터 버퍼캐시에 적재하는 부담이 없기 때문이다.
Direct Path Insert
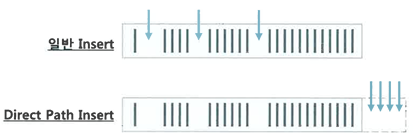
- 일반적인 Insert 매커니즘
- 데이터를 입력할 수 있는 블록을 Freelist에서 찾기
- Freelist에서 할당받은 블록을 버퍼캐시에서 찾기
- 버퍼캐시에 없으면, 데이터파일에서 읽어 버퍼캐시에 적재한다.
- Insert 내용을 Undo 세그먼트에 기록
- Insert 내용을 Redo 로그에 기록
-
Data Path Insert 매커니즘
- Freelist를 참조하지 않고 HMW 바깥 영역에 데이터를 순차적으로 입력
- 블록을 버퍼캐시에서 탐색하지 않음
- 버퍼캐시에 적재하지 않고, 데이터파일에 직접 기록
- Undo 로깅 안함
- Redo 로깅을 안하게 할 수 있음
- 참고로 Direct Path Insert가 아닌 일반 Insert문을 로깅하지 않게 하는 방법은 없다. Redo 로깅은 영속성을 위한 필수 기능이다.
-
Array Processing도 Direct Path Insert 방식으로 처리할 수 있다.
-
Direct Path Insert 주의사항
- Exclusive 모드 TM Lock이 걸린다. 따라서 커밋하기 전까지 다른 트랜잭션은 해당 테이블에 DML을 수행하지 못한다. 트랜잭션이 빈번한 주간에 이 옵션을 사용하는 것은 절대 금물
- Freelist를 조회하지 않고 HWM 바깥 여역에 입력하므로 테이블에 여유 공간이 있어도 재활용하지 않는다. 따라서 Range 파티션 테이블이면 파티션 Drop, 비파티션 테이블이면 주기적으로 Reorg 작업을 수행해 줘야 한다.
Freelist: 테이블 HWM(High-Water Mark) 아래쪽에 있는 블록 중 데이터 입력이 가능한 블록 목록
병렬 DML
- Insert는 append 힌트를 이용해 Direct Path Write 방식으로 유도할 수 있지만, Update, Delete는 기본적으로 Direct Path Write가 불가능하다.
- 유일한 방법은 병렬 DML로 처리하는 것
- 오라클은 병렬 DML에 항상 Direct Path Write 방식을 사용한다.
- DML을 병렬로 처리하려면, 병렬 DML을 반드시 활성화해야 한다.

- 그리고 나서 각 DML문에 아래와 같이 힌트를 사용하면, 대상 레코드를 찾는 작업(Insert:select 쿼리, Update/Delete: 조건절 검색)은 물론 데이터 추가/변경/삭제도 병렬로 진행한다.

- 만약 힌트만 기술하고 병렬 DML을 활성화하지 않는다면 대상 레코드를 찾는 작업은 병렬로 진행하지만, 추가/변경/삭제는 QC가 혼자 담당하므로 병목이 발생한다.
파티션을 활용한 DML 튜닝
테이블 파티션
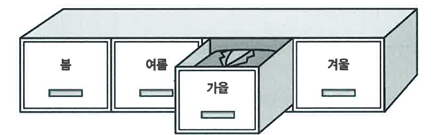
- 파티셔닝은 테이블 또는 인덱스 데이터를 특정 컬럼(파티션 키) 값에 따라 별도 세그먼트에 나눠서 저장하는 것을 말한다.
- 파티션이 필요한 이유
* 관리적 측면: 파티션 다뉘 백업, 추가, 삭제, 변경 -> 가용성 향상- 성능적 측면: 파티션 단위 조회 및 DML, 경합 또는 부하 분산
- 파티션에는 Range, 해시, 리스트 세 종류가 있다.
Range 파티션

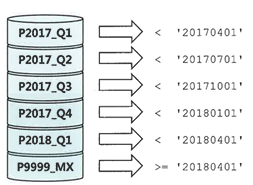
- 검색 조건을 만족하는 파티션만 골라 읽을 수 있어 이력성 데이터를 Full Scan 조회할 때 성능 향상
- 보관주기 정책에 따라 과거 데이터가 저장된 파티션만 백업 및 삭제하는 등 데이터 관리 작업을 효율적으로 빠르게 수행할 수 있다.
- 파티션과 병렬 처리가 만나면 효과는 배가된다.
해시 파티션

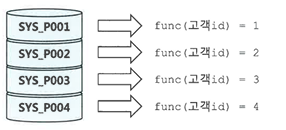
- 파티션 키 값을 해시 함수에 입력해서 반환받은 값이 같은 데이터를 같은 세그먼트에 저장하는 방식
- 파티션 개수만 사용자가 지정하고 데이터를 분산하는 알고리즘은 내부 해시함수가 결정한다.
- 해시 파티션은 ID처럼 변별력이 좋고 데이터 분포가 고른 컬럼을 기준으로 선정해야 효과적이다.
리스트 파티션
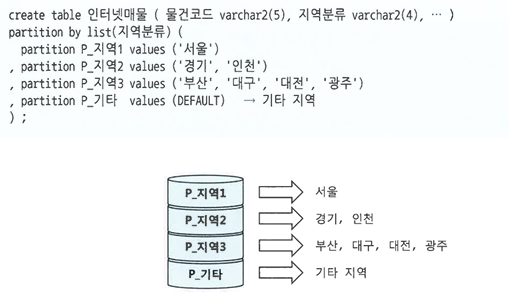
- 사용자가 정의한 그룹핑 기준에 따라 데이터를 분할 저장하는 방식
- Range 파티션에선 값의 순서에 따라 저장할 파티션이 결정되지만, 리스트 파티션에서는 순서와 상관없이 불연속적인 값의 목록에 의해 결정
- 해시 파티션은 오라클이 정한 해시 알고리즘에 따라 임의로 분할하지만, 리스트 파티션은 사용자가 정의한 논리적인 그룹에 따라 분할
인덱스 파티션
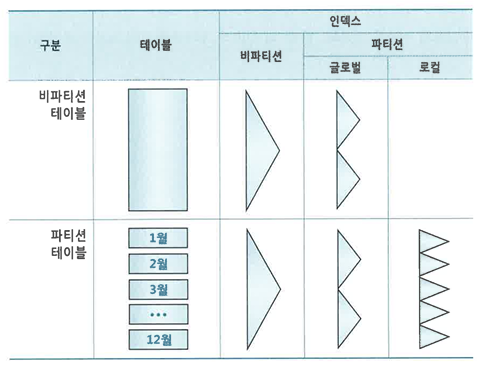
로컬 파티션 인덱스

- 각 인덱스 파티션은 테이블 파티션 속성을 그대로 상속받는다.
- 테이블과 정확히 1:1 대응 관계를 갖도록 자동으로 관리
- 따라서 테이블 파티션 구성을 변경하더라도 인덱스를 재생성할 필요가 없다.
- 변경작업이 빠르게 끄나므로 피크 시간대만 피하면 서비스를 중단하지 않고도 작업할 수 있다.
글로벌 파티션 인덱스

- 파티션을 테이블과 다르게 구성한 인덱스
- ex) 파티션 유형이 다르거나, 파티션 키가 다르거나, 파티션 기준값 정의가 다른 경우
- 인덱션 파티션을 자동으로 관리해주지 않는다.
- 따라서 테이블 파티션 구성을 변경하는 순간 Unusable 상태로 바뀌므로 곧바로 인덱스를 재생성해 줘야 한다. 그동안 해당 테이블을 사용하는 서비스를 중단해야 한다.
비파티션 인덱스

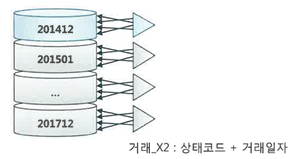
- 파티셔닝하지 않은 인덱스
- 인덱션 파티션을 자동으로 관리해주지 않는다.
- 따라서 테이블 파티션 구성을 변경하는 순간 Unusable 상태로 바뀌므로 곧바로 인덱스를 재생성해 줘야 한다. 그동안 해당 테이블을 사용하는 서비스를 중단해야 한다.
인덱스 파티션 제약
Unique 인덱스를 파티셔닝하려면, 파티션 키가 모두 인덱스 구성 컬럼이어야 한다.
파티션을 활용한 대량 Update 튜닝
-
인덱스가 DML 성능에 큰 영향을 미치므로 대량 데이터를 입력/수정/삭제할 때는 인덱스를 Drop하거나 Unusable 상태로 변경하고서 작업하는 방법을 많이 활용한다.
-
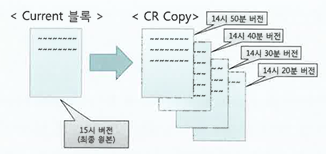
이때 손익분기점은 5% 정도로 본다. 즉, 입력/수정/삭제하는 데이터 비중이 5%를 넘는다면, 인덱스 없이 작업한 후 재생성하는 것이 더 빠르다.
-
ex) 테이블이 파티션닝돼 있고 인덱스도 로컬 파티션
- 임시 테이블 생성. 가능하다면 nologging 모드로 생성

2. 거래 데이터를 읽어 임시 테이블에 입력하면서 데이터 수정

- 임시 테이블에 원본 테이블과 같은 구조로 인덱스 생성. 가능하다면 nologging 모드로 생성

- 원본 파티션과 임시 테이블 Exchange
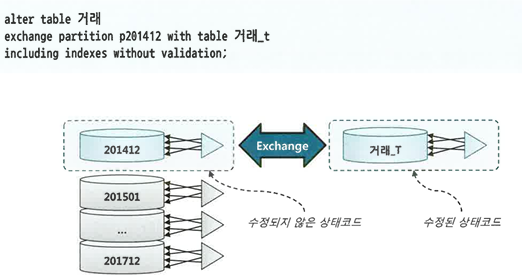
- 임시 테이블 Drop

- (nologging 모드로 작업했다면) 파티션을 logging 모드로 전환

- 임시 테이블 생성. 가능하다면 nologging 모드로 생성
파티션을 활용한 대량 Delete 튜닝
- Update는 변경 대상 컬럼을 포함하는 인덱스만 재생성하면 되지만, Delete는 모든 인덱스를 재생성해야 한다.
- 서비스 중단 없이 파티션을 Drop 또는 Truncate하려면 아래 조건을 모두 만족해야 한다.
- 파티션 키와 커팅 기준 컬럼이 일치해야 함
- 파티션 단위와 커팅 주기가 일치해야 함
- 모든 인덱스가 로컬 파티션 인덱스이어야 함
- 방법1) 파티션 Drop을 이용한 대량 데이터 삭제
- 테이블이 삭제 조건절 컬럼 기준으로 파티셔닝돼 있고, 인덱스도 로컬 파티션일 때 사용
- 방법2) Truncate를 이용한 대량 데이터 삭제
- 조건에 해당하는 데이터를 일괄 삭제하지 않고 또 다른 삭제 조건이 있는 경우, 해당 조건을 만족하는 데이터가 대다수이면, 남길 데이터만 백업했다가 재입력하는 방식이 빠르다.- 임시 테이블 생성 및 남길 데이터 복제
- 삭제할 대상 테이블 파티션 Truncate
- 임시 테이블에 복제해 둔 데이터를 원본 테이블에 입력
- 임시 테이블 Drop
파티션을 활용한 대량 Insert 튜닝
비파티션 테이블일 때
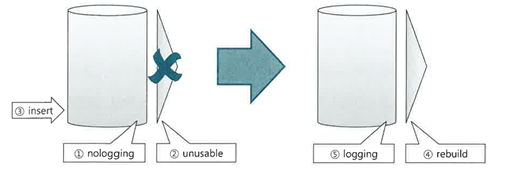
- 비파티션 테이블에 손익분기점을 넘는 대량 데이터를 Insert 하려면 인덱스를 Unusable했다가 재생성하는 방식이 빠를 수 있다.
- (가능하다면) 테이블을 nologging 모드로 전환
- 인덱스를 Unusable 상태로 전환
- (가능하다면 Direct Path Insert 방식으로) 대량 데이터 입력
- (가능하다면 nologging 모드로) 인덱스 재생성
- (nologging 모드로 작업했다면) logging 모드로 전환
파티션 테이블일 때
- 초대용량 인덱스를 재생성하는 부담이 크기 때문에 실무에서는 웬만하면 인덱스를 그대로 둔(Unusable로 전환하지 않은) 상태로 Insert 한다. 하지만 테이블이 파티셔닝돼 있고, 인덱스가 로컬 파티션이라면 파티션 단위로 인덱스를 재생성할 수 있다.
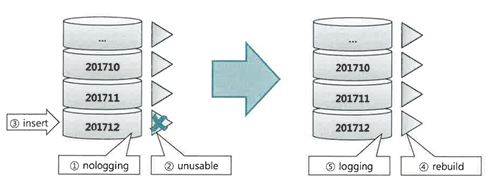
- (가능하다면) 작업 대상 테이블 파티션을 nologging 모드로 전환
- 작업 대상 테이블 파티션과 매칭되는 인덱스 파티션을 Unusable 상태로 전환
- (가능하다면 Direct Path Insert 방식으로) 대량 데이터 입력
- (가능하다면 nologging 모드로) 인덱스 재생성
- (nologging 모드로 작업했다면) logging 모드로 전환
Lock과 트랜잭션 동시성 제어
DML 로우 Lock
-
두 개의 동시 트랜잭션이 같은 로우를 변경하는 것을 방지
-
DML 로우 Lock은 배타적 모드
-
Insert에 대한 로우 Lock 경합은 Unique 인덱스가 있을 때만 발생. 즉, Unique 인덱스가 있는 상황에서 두 트랜잭션이 같은 값을 입력하려고 하면 블로킹 발생
-
MVCC 모델을 사용하는 오라클은 Select 문에 로우 Lock을 사용하지 않는다.
- 다른 트랜잭션이 변경한 로우를 읽을 때 복사본 블록을 만들어서 쿼리가 '시작한 시점'으로 되돌려서 읽음
- 변경이 진행중인(아직 커밋되지 않은) 로우를 읽을 때도 Lock이 풀릴 때까지 기다리지 않고 복사본을 만들어서 읽음
- 따라서 Select문에 Lock을 사용할 필요가 없음
-
DML 로우 Lock에 의한 성능 저하를 방지하려면 Lock이 필요 이상으로 오래 유지되지 않도록 관련 SQL을 모두 튜닝해야한다. 즉, SQL 튜닝이 곧 Lock 튜닝인 셈
DML 테이블 Lock
-
오라클은 DML 로우 Lock을 설정하기에 앞서 테이블 Lock을 먼저 설정한다.
-
현재 트랜잭션이 갱신 중인 테이블 구조를 다른 트래잭션이 변경하지 못하게 막기 위함
-
테이블 Lock을 TM Lock이라고 부르기도 한다.
-
로우 Lock은 항상 배타적 모드이지만, 테이블 Lock은 여러 Lock 모두 사용
-
Lock 호환성(O 표시는 두 모드 간에 호환성이 있음을 의미)
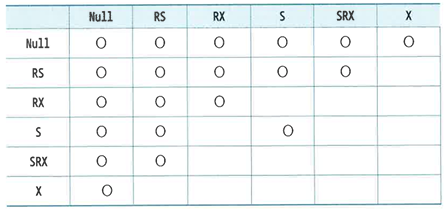
- RS: row share
- RX: Row exclusive
- S: share
- SRX: share row exclusive
- X: exclusive
-
선행 트랜잭션과 호환되지 않는 모드로 테이블 Lock을 설정하려는 후행 트랜잭션은 대기하거나 작업을 포기해야 한다.
-
Insert, Update, Delete, Merge문을 위해 로우 Lock을 설정하려면 해당 테이블에 RX 모드 테이블 Lock을 먼저 설정해야 함
-
Select For Update문을 위해 로우 Lock을 설정하려면 10gR1 이하는 RS, 10gR2 이상은 RX 모드 테이블 Lock을 먼저 설정해야 함
-
테이블 Lock이라고 하면 테이블 전체에 Lock이 걸린다고 생각하기 쉽지만, 테이블 Lock은 해당 테이블에서 현재 수행 중인 작업을 알리는 일종의 푯말이다.
-
그리고 테이블 Lock에는 여러 모드가 있고, 어떤 모드를 사용했는지에 따라 후행 트랜잭션이 수행할 수 있는 작업의 범위가 결정된다.
Lock을 얻고자 하는 리소스가 사용 중일 때, 프로세스는 3가지 방법 중 하나를 택한다.
보통은 내부적으로 진로가 결정돼 있지만, 사용자가 선택할 수 있는 경우도 있다. 사용자가 이 3가지 옵션을 모두 선택할 수 있는 문장이 바로SELECT FOR UPDATE문이다.
1. Lock이 해제될 때까지 기다린다.
2. 일정 시간만 기다리다 포기한다.
3. 기다리지 않고 작업을 포기한다.
트랜잭션 동시성 제어
비관적 동시성 제어
- 사용자들이 같은 데이터를 동시에 수정할 것으로 가정
- 사용자가 데이터를 읽는 시점에 Lock을 걸고 조회 또는 갱신처리가 완료될 때까지 이를 유지
낙관적 동시성 제어
- 사용자들이 같은 데이터를 동시에 수정하지 않을 것으로 가정
- 데이터를 읽을 때 Lock을 설정하느 않음
- 데이터를 수정하고자 하는 시점에 앞서 읽은 데이터가 다른 사용자에 의해 변경되었는지 검사
채번 방식에 따른 Insert 성능 비교
- 신규 데이터를 입력하려면 PK 중복을 방지하기 위한 채번이 선행되어야 한다.
- 가장 많이 사용하는 3가지 채번 방식의 성능과 장단점을 비교해보자
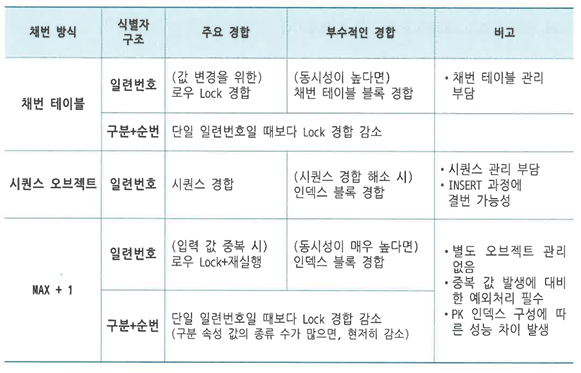
채번 테이블
-
각 테이블 식별자의 단일 컬럼 일련번호 또는 구분 속성별 순번을 채번하기 위해 별도 테이블을 관리하는 방식
-
채번 레코드를 읽어 1을 더한 값으로 변경하고, 그 값을 새로운 레코드를 입력하는데 사용
-
장점
-
높은 범용성
-
Insert 과정에 결번 방지 (vs 시퀀스)
-
PK가 복합컬럽일 때도 사용 가능 (vs 시퀀스)
-
Insert 과정에 중복 레코드 발생에 대비한 예외처리 없이 채번 함수만 정의하면 사용 가능 (vs MAX+1)
-
단점
-
채번 레코드 변경을 위한 로우 Lock 경합 때문에 다른 채번 방식에 비해 성능이 좋지 못함
-
따라서 동시 Insert가 많은 테이블에서 사용하기 어려움
시퀀스 오브젝트
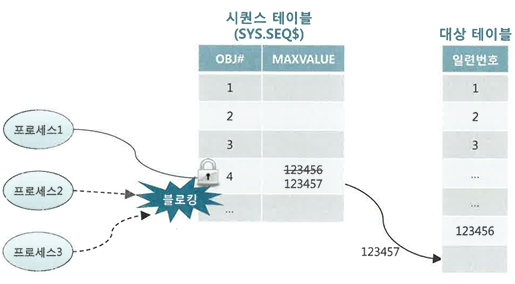
- 장점
- Insert 과정에 중복 레코드 발생에 대비한 예외처리 없이 채번 함수만 정의하면 사용 가능 (vs MAX+1)
- 단점
- 시퀀스 오브젝트도 테이블이기 때문에 값을 읽고 변경하는 과정에서 Lock 메커니즘 작동 -> 캐시 사이즈를 적절히 설정하면 가장 빠른 성능 제공
- 기본적으로 PK가 단일 컬럼일 때만 사용 가능
- 신규 데이터를 입력하는 과정에 결번 발생 가능
- 시퀀스 채번 이후 트랜잭션을 롤백하거나, 시퀀스가 캐시에서 밀려나는 경우
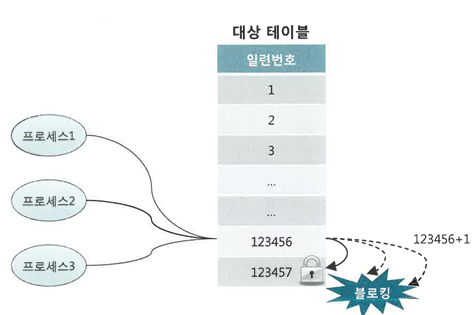
MAX + 1 조회
-
대상 테이블의 최종 일련번호를 조회하고, 거기에 1을 더해 Insert하는 방식
-
장점
-
시퀀스 또는 별도의 채번 테이블을 관리하는 부담이 없음
-
동시 트랜잭션에 의한 충돌이 많지 않으면 성능이 매우 빠름
-
PK가 복합컬럼인 경우에도 사용 가능
- 채번 테이블은 구분 속성 값의 수가 적을 때만 사용할 수 있지만, MAX+1은 값의 수가 아무리 많아도 사용 가능
-
단점
-
레코드 중복에 대비한 세밀한 예외처리 필요
-
레코드 중복에 의한 로우 Lock 경합 때문에 다중 트랜잭션에 의한 동시 채번이 심하면 성능 저하
채번 방식 선택 기준
- 다중 트랜잭션에 의한 동시 채번이 많지 않다면, 어느 것을 사용해도 상관 없다. 다만, 테이블 관리 부담을 고려하면 MAX+1 방식 선택
- 다중 트랜잭션에 의한 동시 채번이 많고 PK가 단일컬럼 일련번호라면, 시퀀스 방식 선택
- 다중 트랜잭션에 의한 동시 채번이 많고 PK 구분 속성에 값 종류가 많으면 중복에 의한 로우 Lock 경합 및 재실행 가능성 낮음. 따라서 MAX+1 선택
- 다중 트랜잭션에 의한 동시 채번이 많고 PK 구분 속성에 값 종류가 적으면 MAX+1 방식은 성능 저하. 따라서 순환 옵션을 가진 시퀀스 방식 선택
시퀀스보다 좋은 솔루션
- 순번 대신 [구분 속성 + 입력일시]로 PK 구조를 설계하면 채번 또는 Insert 과정에 생기는 Lock 이슈를 거의 해소할 수 있다.
- 대규모 데이터 삽입 작업 혹은 동시성이 높은 환경에서 유리
- 또한 대량 Delete 튜닝에서 설명한 것처럼 서비스 중단없이 파티션 단위로 커팅하려면 기본적으로 PK 인덱스가 로컬 파티션이어야 한고, PK 인덱스를 로컬 파티셔닝하려면 삭제 기준 컬럼이 PK에 포함돼 있어야 한다.
인덱스 블록 경합
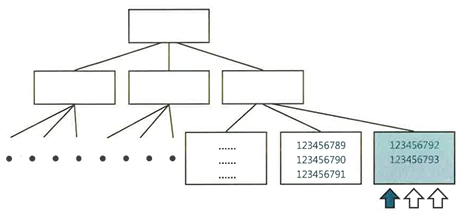
- [구분 속성 + 입력일시]로 PK 구조를 설계해도 인덱스 경합 문제 발생(MAX+1 방식에서도 자주 발생)
- 인덱스는 키순으로 정렬된 상태를 유지하며 값이 입력된다.
- 이때 '일렬번호'나 '입력일시'처럼 순차적으로 값이 증가하는 단일ㅋㄹ럼 인덱스는 항상 맨 우측 블록에만 데이터가 입력된다.(Right Growing 인덱스)
- 이 과정에서 같은 블록을 갱신하려는 프로세스 간 버퍼 Lock 경합 발생 -> 여러 프로세스에 의한 동시 Insert가 많은 경우 트랜잭션 성능 저하
- 구분속성이 앞에 있더라도 동시성이 매우 높으면 인덱스 블록 경합 발생
- 해결법
- 가장 일반적인 해결법은 인덱스를 해시 파티셔닝하는 것
- 해시 함수가 리턴한 값에 따라 서로 다른 파티션에 입력되므로 경합 감소
