
소트 튜닝
소트 연산의 이해
- 소트는 기본적으로 PGA에 할당한 Sort Area에서 이루어진다.
- 메모리 공간인 Sort Area가 다 차면, 디스크 Temp 테이블스페이스를 활용한다
- 메모리 소트: 전체 데이터의 정렬 작업을 메모리 내에서 완료하는 것 (Internal Sort)
- 디스크 소트: 할당받은 Sort Area 내에서 정렬을 완료하지 못해 디스크 공간까지 사용하는 경우 (External Sort)
소트 과정
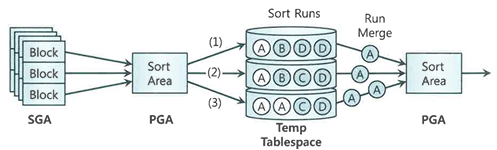
- 소트할 대상 집합을 SGA 버퍼 캐시를 통해 읽어들이고, 일차적으로 Sort Area에서 정렬 시도
- Sort Area 내에서 데이터 정렬을 마무리하는 것이 최적이지만, 양이 많을 때는 정렬된 중간집합을 Temp 테이블 스페이스에 임시 세그먼트를 만들어 저장. 이를 'Sort Run'이라고 부른다.
- 정렬된 최종 결과집합을 얻으려면 이를 다시 Merge해야 한다. 각 Sort Run 내에서는 이미 정렬된 상태이므로 Merge과정은 어렵지 않다.
- PGA로 각각 읽어 들이다가 PGA가 찰 때마다 쿼리 수행 다음 단계로 전달 or 클라이언트에게 전송
소트 연산 특징
- 소트 연산은 메모리 집약적일 뿐만 아니라 CPU 집약적이다.
- 처리할 데이터량이 많을 때는 디스트 I/O까지 발생하므로 쿼리 성능을 좌우하는 매우 중요한 요소
- 디스크 소트가 발생하는 순간 SQL 수행 성능은 나빠질 수밖에 없다.
- 또한 소트 연산은 부분범위 처리를 불가능하게 함으로써 OLTP 환경에서 애플리케이션 성능을 저하시키는 주요인
소트 오퍼레이션
- 소트를 발생시키는 오퍼레이션
Sort Aggregate
- 전체 로우를 대상으로 집계를 수행할 때 발생
- 실제로 데이터를 정렬하지는 않지만, Sort Area를 사용함
- SUM, MAX, MIN, AVG 등
- 절차 예시
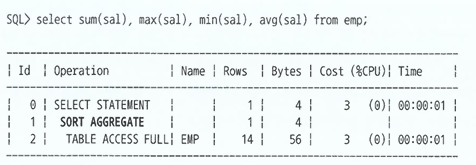
① Sort Area에 SUM, MAX, MIN, COUNT 값을 위한 변수를 하나씩 할당
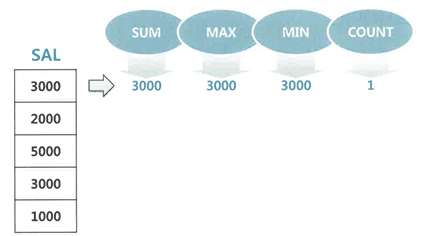
② EMP테이블 첫번째 레코드에서 읽은 SAL 값을 SUM, MAX, MIN 변수에 저장하고, COUNT 변수에는 1을 저장

③ EMP 테이블에서 레코드를 하나씩 읽어가며 각 변수를 업데이트
④ EMP 레코드를 다 읽고나면 변수에 담긴 값을 출력, AVG는 SUM / COUNT로 계산
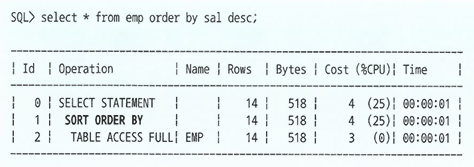
Sort Order By
- 데이터를 정렬할 때 발생
Sort Group By
- 소팅 알고리즘을 사용해 그룹별 집계를 수행할 때 발생
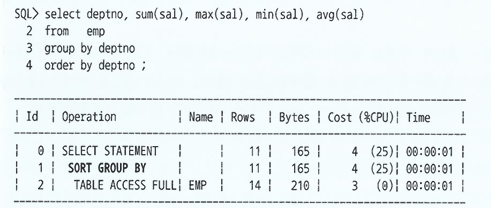
- 그룹별 집계이기 때문에 Sort Area에 그룹별로 1개의 변수만 필요하다.
- 따라서 그룹 개수가 많지 않다면, 집계할 대상 레코드가 아무리 많아도 Temp 테이블스페이스가 필요하지 않다.
- 또한
Group By절 뒤에Order By절을 명시하지 않는다면 대부분Hash Group By방식으로 처리됨
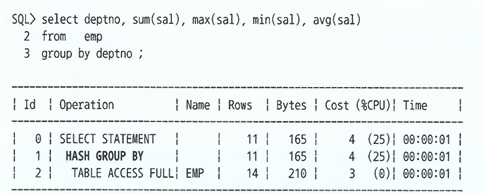
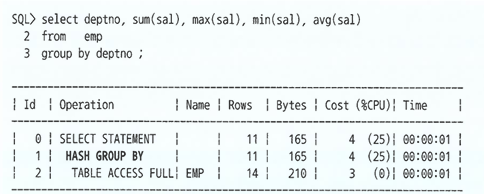
- Hash 알고리즘을 사용할 경우, 정렬 순서를 보장하지 않기 때문에, 정렬 순서를 보장하기 위해서는 반드시
Order By절을 명시해야 한다. Order By절을 명시할 경우, 논리적인 정렬 순서에 따라 연결 리스트 방식으로 그룹 집합이 배치되기 때문에 정렬 순서가 보장된다.
Sort Unique
- '서브쿼리 Unnesting'에서 메인쿼리와 조인하기 전에 중복 레코드를 제거할 때 Sort Unique 오퍼레이션 발생
- Union, Minus, Intersect 같은 집합 연산자를 사용할 때도 발생
- Distinct 연산에서도 발생
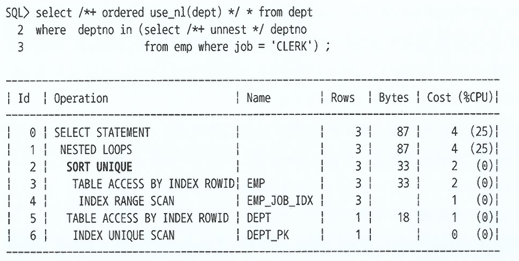
- 만약 이때 PK/Unique 제약 또는 Unique 인덱스를 통해 Unnesting된 서브쿼리의 유일성이 보장된다면 Sort Unique 오퍼레이션을 생략할 수 있다.
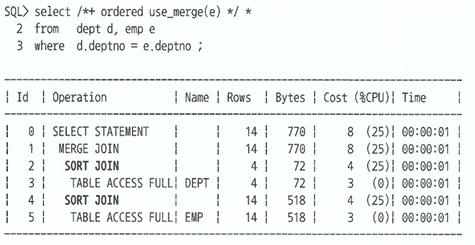
Sort Join
- 소트 머지 조인을 수행할 때 발생
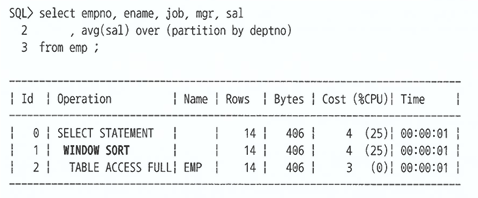
Window Sort
- 윈도우 함수를 수행할 때 발생
소트가 발생하지 않도록 SQL 작성
- 소트가 발생하지 않도록 SQL을 작성할 때부터 주의해야 한다.
Union VS Union All
- Union을 사용 시 옵티마이저는 상단과 하단 두 집단 간 중복을 제거하기 위해 소트 작업 수행
- Union All은 중복을 확인하지 않고 두 집합을 단순히 결합
- 따라서 Union 대신 Union All로 변경할 때 결과 집합이 달라지지 않는다면 변경하는 것이 좋다.
- ex) Union 대신 Union All 사용 가능
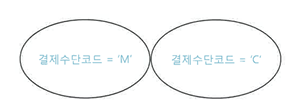
- ex) 단순히 Union 대신 Union All 사용 시 데이터 중복
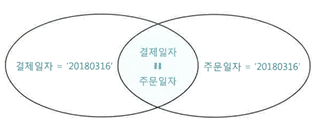
이럴 경우, 조건절에서 데이터 중복 방지하여야 Union All을 사용할 수 있다.

Exists 활용
Distinct는 조건에 해당하는 데이터를 모두 읽어 중복을 제거한다.- 따라서
Distinct연산자로 중복 제거 시 부분 처리가 불가하고, 모든 데이터를 읽는 과정에서 많은 I/O가 발생한다. - 반면
Exists서브쿼리는 데이터 존재 여부만 확인하기 때문에 조건절을 만족하는 데이터를 모두 읽지 않는다.
조인 방식 변경
- 인덱스는 정렬된 상태를 유지하기 때문에 소트 연산을 생략할 수 있다.
- 인덱스를 사용하는 NL 조인에서 소트 연산을 생략할 수 있는 경우가 있다.
인덱스를 이용한 소트 연산 생략
- 인덱스는 항상 키 컬럼 순으로 정렬된 상태를 유지한다.
- 이를 통해
Order By또는Group By절이 있어도 소트 연산을 생략할 수 있다. - 여기에
Top N쿼리 특성을 결합하면 OLTP에서 대량 데이터를 조회할 때 매우 빠른 응답속도를 낼 수 있다. - 또한 특정 조건을 만족하는 최소값, 최대값도 빨리 찾을 수 있어 이력 조회에서도 유용하다.
Top N 쿼리
-
전체 결과집합 중 상위 N개 레코드만 선택하는 쿼리
-
Top N 쿼리를 통해 3-Tier 아키텍처에서도 부분범위 처리를 활용할 수 있다.
-
ex)

- [종목코드 + 거래일시] 로 구성된 인덱스를 이용하면, 옵티마이저는 소트 연산을 생략하고, 인덱스를 스캔하다가 10개 레코드를 읽는 즉시 스캔을 멈춘다.

- [종목코드 + 거래일시] 로 구성된 인덱스를 이용하면, 옵티마이저는 소트 연산을 생략하고, 인덱스를 스캔하다가 10개 레코드를 읽는 즉시 스캔을 멈춘다.
-
이렇게
Sort Order By오퍼레이션 대신Count(STOPKEY)를 통해 지정한 건수 만큼 결과 레코드를 얻으면 바로 멈추는 알고리즘을 Top N Stopkey 알고리즘이라고 한다. -
Top N Stopkey 알고리즘을 통해 페이징 처리가 가능하다.

-
이렇게 인덱스 사용이 가능하도록 조건절을 구사하고, 조인을 NL 조인 위주로 처리하고, Order By절이 있어도 소트 연산을 생략할 수 있도록 인덱스를 구성하면 소트 연산 없이 페이징 처리가 가능하다.
-
Order By 아래 쪽
ROWNUM조건절은 Top N Stopkey 알고리즘의 핵심이므로 이를 제거하면 소트 생략은 가능하지만, Stopkey가 작동하지 않아 전체범위를 처리하게 된다.
최소값/최대값 구하기
-
최소값(MIN), 최대값(MAX)를 구하는 SQL의 실행계획을 보면 Sort Aggregate 오퍼레이션이 나타난다.
-
이때 인덱스를 이용하면 전체 데이터를 읽지 않고도 최소값, 최대값을 찾을 수 있다.
-
인덱스 맨 왼쪽에서 읽는 첫번째 값이 최소값, 맨 오른쪽에서 읽는 첫번째 값이 최대값이다. (First Row StopKey 알고리즘)

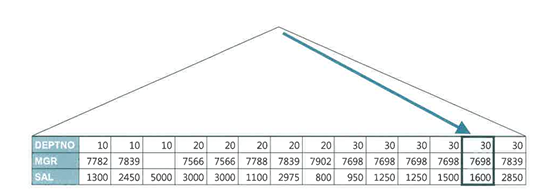
-
이를 위해서는 조건절 컬럼과 MIN/MAX 함수 인자 컬럼이 모두 인덱스에 포함돼 있어야 한다. 즉, 테이블 엑세스가 발생하지 않아야 한다.
-
Top N 쿼리를 통해서도 최소값, 최대값을 구할 수 있다. 아래와 같이 ROWNUM <= 1 조건을 이용하면 된다.
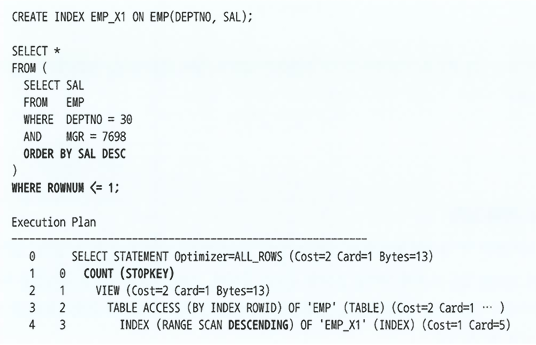
-
Top N 쿼리에 작동하는 'Top N Stopkey 알고리즘'은 모든 컬럼이 인덱스에 포함돼 있지 않아도 잘 동작한다.

-
모든 컬럼이 인덱스에 포함되지 않는 경우, Top N 쿼리는 인라인 뷰를 사용하므로 쿼리가 약간 더 복잡하지만, 성능 측면에서는 MIN/MAX 쿼리보다 낫다.
이력 조회
- 테이블의 값이 어떻게 변경돼 왔는지 과거 이력을 조력할 필요가 있다면 이력테이블을 따로 관리해야 한다.
- 이력 데이터를 조회할 때
First Row Stopkey또는Top N Stopkey알고리즘이 작동할 수 있게 인덱스를 설계해야 한다.
- ex) 단순한 이력조회

- 그림은 장비구분코드가 'A001'인 장비 목록을 조회하는 쿼리이다.
- 상태코드가 현재값으로 변경된 날짜는 상태변경이력에서 조회한다.
- 인덱스가 [장비번호 + 변경일자 + 변경 순번] 순으로 구성되어 있기 때문에, 이력 조회하는 스칼라 서브쿼리 부분에
First Row StopKey알고리즘이 작동하고 있다.
Sort Group By 생략
-
그룹핑 연산에도 인덱스를 활용할 수 있다.
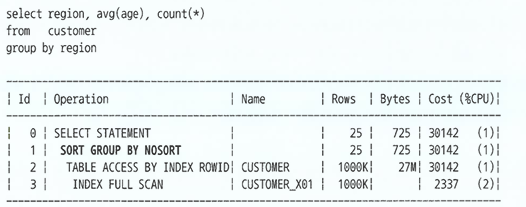
-
Group By절에 선두컬럼인 인덱스를 이용하면
Sort Group By Nosort라고 표시된다. -
동작 메커니즘(Array size = 3)
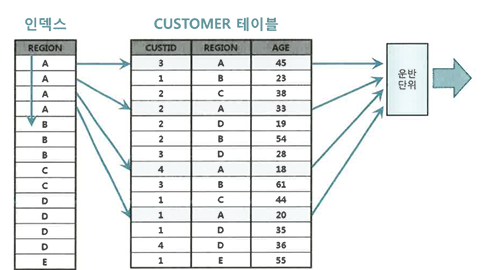
1. 인덱스에서 A 구간을 스캔하면서 테이블을 액세스하다 B를 만나는 순간, 그때까지 집계한 값을 운반 단위에 저장한다.
2. 계속해서 B구간을 스캔하다가 C를 만나는 순간, 그때까지 집계한 값을 운반 단위에 저장한다.
3. 계속해서 C구간을 스캔하다가 D를 만나는 순간, 그때까지 집계한 값을 운반 단위에 저장한다. Array size가 3이므로 지금까지 읽은 A,B,C에 대한 집계 결과를 클라이언트에게 전송하고 다음 Fetch Call일 올 때까지 기다린다.
4. 클라이언트로부터 다음 Fetch Call이 오면 1~3 과정을 반복한다. 물론 두번째 Fetch Call에서는 D구간부터 읽기 시작한다 -
이처럼 인덱스를 이용하 Nosort 방식으로 Group By를 처리하면 부분범위 처리가 가능해진다.
Sort Area를 적게 사용하도록 SQL 작성
-
소트 연산이 불가피하다면 메모리 내에서 처리를 완료할 수 있도록 노력해야 한다.
-
테이블을 Full Scan하더라도 가공, 출력에 따라 소트하는 데이터량이 다르다.
-
인덱스 소트 연산을 생략할 수 없더라도
Top N쿼리를 사용하여 Sort Area 사용량과 소트 연산 횟수를 줄일 수 있다. -
(SORT ORDER BY STOPKEY)

-
왜냐하면 전체 레코드를 다 정렬하지 않고 N개의 레코드만 정렬 상태를 유지해도 결과를 구할 수 있기 때문이다.

-
윈도우 함수 중
RANK나ROW_NUMBER함수는 TOP N 소트 알고리즘을 사용하기 때문에MAX함수보다 소트 부하가 적다.
