
조인 튜닝
NL 조인
-
인덱스를 이용한 조인 방식
-
ex) NL 조인 예시

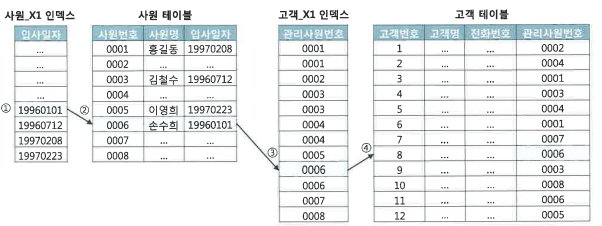
① 사원_X1 인덱스에서 입사일자>='19960101'인 첫번째 레코드를 찾아간다.
② 인덱스를 읽어 ROWID로 사원 테이블 레코드를 찾아간다.
③ 사원 테이블에서 읽은 사원번호 '0006'으로 고객_X1 인덱스를 탐색한다.
④ 고객_X1 인덱스에서 읽은 ROWID로 고객 테이블 레코드를 찾아간다.
NL 조인 특징
-
랜덤 액세스 위주의 조인 방식
-> 레코드 하나를 읽기 위해 블록을 통째로 읽음
-> 대량 데이터를 조인할 때 불리함 -
한 레코드씩 순차적으로 진행
-> 부분범위 처리를 활용하면 큰 테이블을 조인하더라도 응답속도 빠름 -
인덱스 구성 전략이 특히 중요
-> 조인 컬럼에 대한 인덱스가 있느냐 없느냐, 있다면 어떻게 구성되었느냐에 따라 조인 효율이 크게 달라진다.
종합: NL 조인은 소량 데이터를 주로 처리하거나, 부분범위 처리가 가능한 OLTP 시스템에 적합한 조인 방식이다.
NL 조인 수행 과정 분석
-
NL 조인을 제어할 때는
use_nl힌트를 사용한다.

-
이때
ordered힌트는 FROM절에 기술한 순서대로 조인하라는 지시이다.
따라서 위 쿼리에서는 e (e.입사일자 >='19960101') -> c (c.관리사원번호 = e.사원번호) 순서로 조건절을 비교할 것이다.
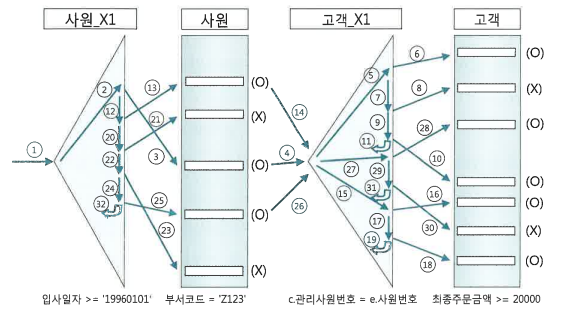
- NL 조인은 한 레코드씩 순차적으로 진행한다. 위 그림에 NL 조인 수행 순서를 숫자로 표시한 예이다.
NL 조인 튜닝 포인트
- OLTP 시스템에서 튜닝할 때 일차적으로 NL 조인부터 고려한다.
- 만약 성능이 느리다면, 각 단계의 수행 일량을 분석하여 과도한 랜덤 액세스가 발생하는 지점을 파악한다.
- 조인 순서를 변경하여 랜덤 액세스 발생량을 줄일 수 있는지, 더 효과적인 다른 인덱스가 있는지 등을 검토
- 필요하다면 인덱스 추가 또는 구성 변경 고려
- 위 방법들로 성능 개선이 어렵다고 판단될 때, 소트 머지 조인이나 해시 조인을 검토
NL 조인 확장 메커니즘
- 오라클은 NL 조인 성능을 높이기 위해 테이블 Prefetch, 배치 I/O 기능을 도입
테이블 Prefetch
- 인덱스를 이용해 테이블을 액세스하다가 디스크 I/O가 필요해지면, 이어서 곧 읽게 될 블록까지 미리 읽어서 버퍼캐시에 적재하는 기능
배치 I/O
- 디스크 I/O Call을 미뤘다가 읽을 블록이 일정량 쌓이면 한번에 처리하는 기능
- 결과집합의 정렬 순서를 보장하지 않기 때문에 주의해야 한다.
NL 조인 자가 진단
위 쿼리와 인덱스를 보고 어떻게 재구성하면 좋을지 스스로 진단해보자.
힌트는 아래와 같다.



- 우선 위 인덱스대로라면
order by에 의해 한번 더 정렬이 발생한다. 이를 방지하기 위해서는STC_DT의 순서를 2번째로 재구성해야할 것 같다. (PRA_HST_STC_N1 : SALE_ORG_ID + STC_DT + STRD_GRP_ID + STRD_ID) - NL 조인할 때는 a에 대한 테이블 액세스가 무조건 발생한다. 따라서
PRA_HST_STC_N1인덱스에 모든 컬럼이 존재할 필요는 없다. 그러므로 필수 조건인SALE_ORG_ID와 정렬을 위한STC_DT를 제외한STRD_GRP_ID와STRD_ID컬럼은 인덱스에서 제외되어도 성능에 영향을 미치지 않는다. 오히려 테이블 b에STRD_GRP_ID + STRD_ID인덱스를 추가하는 것이 좋아보인다. - 최종적으로
PRA_HST_STC_N1 : SALE_ORG_ID + STC_DT로 기존 인덱스를 재구성하고,
STRD_GRP_ID + STRD_ID로 구성된 새로운 인덱스를 b 테이블에 추가하는 것이 좋아보인다.
소트 머지 조인
SGA VS PGA
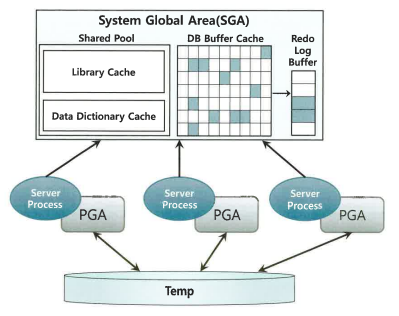
SGA
- 공유 메모리 영역인 SGA에 캐시된 데이터는 여러 프로세스가 공유할 수 있다.
- 여러 프로세스가 공유할 수 있지만, 동시에 액세스할 수는 없다.
- 동시에 액세스하려는 프로세스간 액세스를 직렬화하기 위한 Lock 메커니즘인 래치(Latch)가 존재한다.
- SGA의 구성요소인 DB버퍼캐시에서 블록을 읽기 위해서는 버퍼 Lock을 얻어야 한다.
PGA
- 각 오라클 서버 프로세스에 할당된 메모리 영역
- 프로세스에 종속적인 고유 데이터를 저장하는 용도
- 할당받은 PGA 공간이 작아 데이터를 모두 저장할 수 없을 때는 Temp 테이블스페이스 이용
- 다른 프로세스와 공유하지 않는 독립적인 메모리 공간이므로 래치 메커니즘이 불필요 -> SGA 버퍼캐시에서 읽을 때보다 빠름
소트 머지 조인 메커니즘
-
소트 머지 조인은 소트 단계, 머지 단계로 나누어 진행한다.
-
소트 단계: 양쪽 집합을 조인 컬럼을 기준으로 정렬
-
머지 단계: 정렬한 양쪽 집합을 서로 머지(Merge)
-
ex) 소트 머지 조인 예시

① 조건에 해당하는 사원 데이터를 읽어 조인컬럼인 사원번호 순으로 정렬. 정렬한 결과집합은 PGA 영역에 할당된 Sort Area에 저장
② 조건에 해당하는 고객 데이터를 읽어 조인컬럼인 관리사원번호 순으로 정렬. 정렬한 결과집합은 PGA 영역에 할당된 Sort Area에 저장
③ PGA에 저장한 사원 데이터를 스캔하면서 PGA에 저장한 고객 데이터와 조인①, ②는 소트 단계, ③은 머지단계이다. 머지 단계의 프로세싱은 NL 조인과 다르지 않다.
소트 머지 조인 특징
-
Sort Area에 저장한 데이터 자체가 인덱스 역할을 하므로 인덱스가 없어도 사용할 수 있는 조인 방식이다.
-
소트 머지 조인은 양쪽 테이블로부터 조인 대상 집합을 일괄적으로 읽어 PGA에 저장한 후 조인한다.
-
PGA는 프로세스만을 위한 독립적인 메모리 공간이므로 데이터를 읽을 때 래치 획득 과정이 없다.
-
또한 양쪽 집합이 모두 정렬되어 있기 때문에 테이블을 Full Scan하지 않아도 된다.
-
따라서 소트 머지 조인은 대량 데이터 조인에 유리하다.
-
하지만 소트 머지 조인도 조인 대상 집합을 읽을 때는 DB 버퍼 캐시를 경유한다. 이때는 인덱스를 이용하기도 한다. 이 과정에서 발생하는 버퍼 캐시 탐색 비용과 랜덤 액세스 부하는 피할 수 없다.
소트 머지 조인 활용
- 조인 조건식이 등치(=) 조건이 아닌 대량 데이터 조인 (해시 조인을 사용할 수 없음)
- 조인 조건식이 아예 없는 조인(Cross Join, 카테시안 곱)
해시 조인
-
NL 조인은 인덱스 구성에 따른 성능 차이가 심하다. 또한 랜덤 I/O 때문에 대량 데이터 처리에 불리하고, 버퍼캐시 히트율에 따라 불규칙한 성능을 보인다.
-
반면 해시 조인은 조인 과정에 인덱스를 이용하지 않기 때문에 대량 데이터 조인에 유리하고, 일정한 성능을 보인다.
해시 조인 메커니즘
-
해시 조인은 Build, Probe 단계로 나뉘어 진행된다.
-
Build 단계: 작은 쪽 테이블(Build Input)을 읽어 해시 테이블(해시 맵)을 생성
-
Probe 단계: 큰 쪽 테이블(Probe Input)을 읽어 해시 테이블을 탐색하면서 조인
-
해시 테이블은 PGA 영역에 할당된 Hash Area에 저장한다. 만약 해시 테이블이 너무 커 PGA에 담을 수 없으면 Temp 테이블 스페이스에 저장한다.
-
ex) 해시 조인 예시

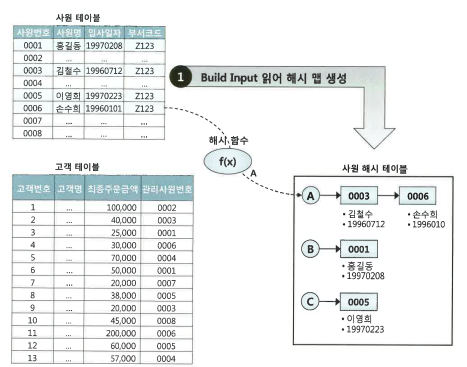
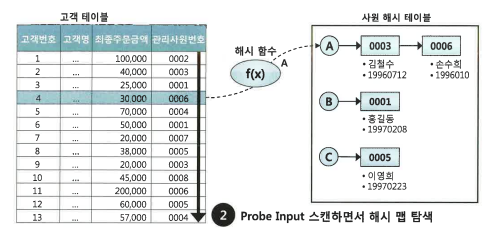
① Build 단계, 조건에 해당하는 사원 데이터를 읽어 해시 테이블을 생성한다. 이때 조인 컬럼인 사원번호를 해시 테이블 키 값으로 사용한다. 즉, 사원번호를 해시 함수에 입력해서 반환된 값으로 해시 체인을 찾고, 그 해시 체인에 데이터를 연결한다.
② Probe 단계, 조건에 해당하는 고객 데이터를 하나씩 읽어 Build 단계에서 생성한 해시 테이블을 탐색한다. 즉, 관리사원번호를 해시 함수에 입력해서 반환된 값으로 해시 체인을 찾고, 그 해시 체인에서 스캔하여 값이 같은 사원번호를 찾는다.②번 Probe 단계의 프로세싱은 NL 조인과 다르지 않다.
해시 조인에서 대용량 Build Input 처리 방법
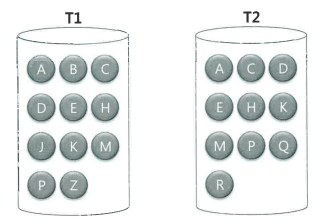
그림처럼 두 테이블 모두 대용량 테이블이어서 인메모리 해시 조인이 불가능한 상황도 존재한다. 이럴 때는 파티션 단계, 조인 단계로 나누어 작업을 처리한다. 쉽게 말해 분할정복 방식이다.
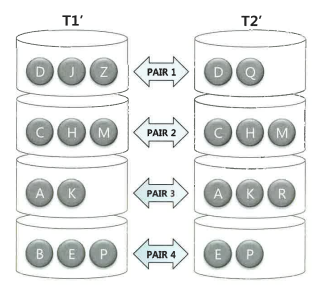
① 파티션 단계
- 독립적으로 처리할 수 있는 여러 개의 작은 서브 집합으로 분할함으로써 파티션 짝(pair)을 생성하는 단계
- 조인하는 양쪽 집합(조인 이외 조건절을 만족하는 레코드)의 조인 컬럼에 해시 함수를 적용하고, 반환된 해시 값에 따라 동적으로 파티셔닝한다.
- 이때 디스크인 Temp 테이블 스페이스에 저장(T1', T2')하기 때문에 인메모리 해시 조인보다 성능이 많이 떨어진다.
② 조인 단계
- 파티션 단계를 완료하면 각 파티션 짝(pair)에 대해 하나씩 조인을 수행한다. 이때 각각에 대한 Build Input과 Probe Input은 독립적으로 결정된다. 즉, 파티션된 짝별로 작은 쪽을 Build Input으로 선택하여 해시 테이블을 생성한다.
- 해시 테이블을 생성하고 나면 반대쪽 파티션 로우를 하나씩 읽으면서 해시 테이블을 탐색한다.
- 모든 파티션 짝에 대한 처리를 마칠 때까지 이 과정을 반복한다.
해시 조인이 빠른 이유
-
해시 테이블은 PGA영역의 Hash Area에 할당되기 때문에 래치 획득 과정 없이 빠르게 데이터를 탐색, 조인할 수 있다.
-
해시 조인도 Build Input과 Probe Input 각 테이블을 읽을 때는 DB 버퍼 캐시를 경유한다. 이때는 인덱스를 이용하기도 한다. 이 과정에서 발생하는 버퍼 캐시 탐색 비용과 랜덤 액세스 부하는 피할 수 없다.
-
똑같이 PGA 영역을 사용하는 소트 머지 조인은 양쪽 테이블을 모두 정렬하여야 한다. 그렇기 때문에 PGA가 부족해 Temp 테이블 스페이스(디스크)에 쓰는 작업을 보통 수반한다. 반면 해시 조인은 작은 쪽 테이블을 해시 맵으로 만들기 때문에 Temp 테이블 스페이스에 쓰는 작업이 보통 일어나지 않는다.
-
설령 Build Input이 Hash Area 크기를 초과하여 Temp 테이블 스페이스를 사용하더라도 대량 데이터 조인 시에는 일반적으로 해시 조인이 가장 빠르다.
조인 메서드 선택 기준
일반적인 메서드 선택 기준
- 소량 데이터 조인 -> NL 조인
- 대량 데이터 조인 -> 해시 조인
- 대량 데이터 조인인데 해시 조인으로 처리할 수 없을 때, 즉 조인 조건식이 동치 조건이 아닐 때 -> 소트 머지 조인
여기서 소량과 대량은 단순히 데이터량의 많고 적음이 아닌 랜덤 액세스가 많음을 의미함.
수행빈도가 높은 쿼리에 대한 메서드 선택 기준
- (최적화된)NL 조인과 해시 조인 성능이 같을 때 -> NL 조인
- 해시 조인이 약간 더 빠를 때 -> NL 조인
- NL 조인보다 해시 조인이 매우 빠를 때 -> 해시 조인
해시 조인이 빠름에도 NL 조인을 항상 최우선으로 사용하는 이유는 해시 테이블은 단 하나의 쿠리를 위해 생성되고 조인이 끝나면 곧바로 소멸하는 자료구조이기 때문이다. 반면 NL 조인이 사용하는 인덱스는 영구적으로 유지되면서 다양한 쿼리를 위해 공유 및 재사용되는 자료구조이다.
또한 해시 조인은 CPU와 메모리 사용률이 높고, 해시 맵을 만드는 과정에서 여러 가지 래치 경합이 발생할 수 있다.
따라서 해시 조인은 수행 빈도가 낮고, 쿼리 수행 시간이 오래걸리는 대량 데이터 조인할 때 사용하는 것이 적절하다.
서브쿼리 조인
서브쿼리
-
서브쿼리: 하나의 SQL문 안에 괄호로 묶은 별도의 쿼리 블록, 쿼리에 내장된 또 다른 쿼리
-
오라클은 서브쿼리를 스칼라 서브쿼리, 인라인 뷰, 중첩된 서브쿼리로 분류한다.
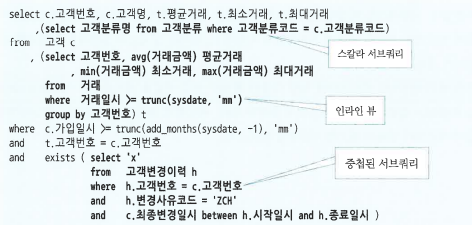
-
스칼라 서브쿼리(Scalar Subquery): 한 레코드당 정확히 하나의 값을 반환하는 서브쿼리
-
인라인 뷰(Inline View): FROM절에 사용한 서브쿼리
-
중첩된 서브쿼리(Nested Subquery): 결과집합을 한정하기 위해 WHERE절에 사용한 서브쿼리
-
옵티마이저는 쿼리 블록 단위로 최적화를 수행한다. 따라서 서브쿼리를 사용하면 메인 쿼리와 서브 쿼리를 각각 따로 최적화한다.
-
서브쿼리별로 최적화한 쿼리는 전체적으로 최적화됐다고 말할수 없다. 따라서 SQL을 최적화 할때는 먼저 서브쿼리를 푸는 작업이 필요하다.
중첩된 서브쿼리와 조인
- 중첩된 서브쿼리를 처리하는 방법에는 필터 오퍼레이션과 서브쿼리 Unnesting이 있다.
필터 오퍼레이션
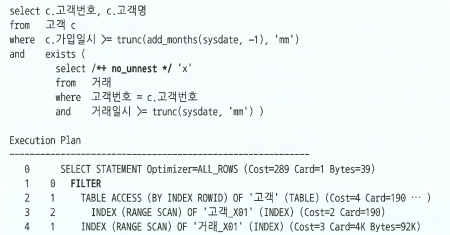
- 서브쿼리를 필터 방식으로 처리하는 방법
- 필터 방식이란 마치 NL 조인처럼 동작하도록 하는 방식이다.
- 두 개의 쿼리를 각각 최적화하는게 아니라 NL 조인처럼 하나의 쿼리로 판단하여 최적화
- 위 실행계획에서
FILTER를NESTED LOOP라고 생각하면 된다. - NL 조인과 차이점
- 서브쿼리 조건절에 해당하는 값이 존재하면 조건절이 참이 true가 되었으므로 바로 break
- 서브쿼리 조건절의 결과를 캐싱한다. 캐시는 쿼리를 시작할 때 PGA 메모리 공간에 할당하고, 쿼리를 마치면 반환한다.
- 항상 메인쿼리가 Outer, 서브쿼리가 Inner
서브쿼리 Unnesting
- 메인과 서브쿼리 간의 계층구조를 없애고, 서로 같은 레벨로 쿼리를 처리하는 방식
- 필터 오퍼레이션 VS 서브쿼리 Unnesting
Filter 방식 Unnesting 방식 힌트 no_unnest unnest Outer와 Inner 쿼리 항상 서브 쿼리가 Inner 힌트를 이용해 선택 가능 조인 방식 NL 조인 방식 NL조인, 해시 조인 등 다양하게 가능 - Unnesting 방식은 다양한 최적화 기법을 사용할 수 있어 필터 방식보다 더 좋은 실행 결로를 찾을 수 있다.
※ Unnesting: 중첩
서브쿼리 Pushing
- 서브쿼리 필터링을 가능한 한 앞 단계에서 처리하도록 강제하는 기능
- 서브쿼리 필터링을 먼저 처리함으로써 조인 단계로 넘어가는 로우 수를 줄일 수 있을 때 사용
push_subq/no_push_subq힌트로 제어- 서브쿼리 Pushing은 Unnesting되지 않은 서브쿼리에만 작동한다. 따라서
push_subq는 항상no_unnest와 함께 기술 - 반대로, 가능한 한 나중에 처리하게 하려면
no_unnest와no_push_subq를 함께 기술
인라인 뷰 서브쿼리와 조인
-
merge 힌트를 사용하여 뷰를 메인쿼리와 머징하는 방법
-
서브쿼리나 인라인 뷰를 조인 형태로 처리하는 방식
-
이를 통해 불필요한 임시 테이블 생성이나 필터링을 피할 수 있다.
-
ex)

-
위 예시에서 고객 테이블에서 '전월 이후 가입한 고객'을 필터링하는 조건이 인라인 뷰 바깥에 있다.
-
하지만 인라인 뷰 안에서는 당월에 거래한 '모든' 고객의 거래 데이터를 읽어야 한다. 이는 매우 비효율적이다.

-
위와 같이
merge힌트를 이용와 뷰를 메인쿼리와 머징

-
실행계획을 보면 쿼리가 위와 같이 변환되었음을 예측할 수 있다.(조인)
-
전체 데이터를 병합하는 방식으로 동작하므로 부분 범위 처리가 불가능하다
-
조인 조건 Pushdown
- 메인쿼리를 실행하면서 조인 조건절 값을 건건이 뷰 안으로 밀어 넣는 기능

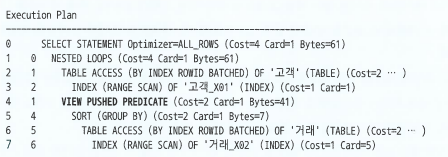
- 전월 가입한 고객을 대상으로 '건건이' 당월 거래 데이터만 읽어서 조인하고
Group By수행 - 즉,
t.고객번호 = c.고객번호조건을 인라인 뷰를 조인하기 전에 미리 처리하도록 변경한다. - 결과적으로 고객번호별로 조인을 수행할 수 있다.
- 이로 인해 부분 범위 처리가 가능하다.
push_pred힌트로 제어하며, 옵티마이저가 뷰를 머징하면 힌트가 작동하지 않으니no_merge와 함께 사용해야 한다.
스칼라 서브쿼리 조인
- 스칼라 서브쿼리는 함수와 비슷해보이지만, 재귀적으로 실행되는 구조가 아니다.
- 함수와 달리 컨텍스트 스위칭 없이 메인쿼리와 서브쿼리를 한번에 실행한다.
- NL 조인 방식으로 실행되지만, 필터 서브쿼리와 같은 캐싱 기능을 가지고 있다.
- 캐시는 쿼리를 시작할 때 PGA 메모리 공간에 할당하고, 쿼리를 마치면 반환한다.
- 캐시는 매우 작은 메모리 공간이기 때문에 입력 값의 종류가 적어 해시 충돌 가능성이 작을 때 효과가 있다
- 캐싱이 쿼리 단위로 이루어지기 때문에 메인 쿼리 집합이 매우 작은 경우에도 캐싱 효과를 기대하기 어렵다.
- 그렇지 않다면 캐시를 매번 확인하는 비용 때문에 오히려 성능이 나빠지고, CPU와 메모리 사용률만 높아진다.
- 스칼라 서브 쿼리는 2개 이상의 항목을 조회할 수 없다. 그럴 경우에는 해당 쿼리를 인라인 뷰로 사용하는 편이 낫다.
- NL 조인 방식으로 조인하므로 캐싱 효과가 크지 않으면 랜덤 I/O 부담이 있기 때문에 대용량 데이터를 다루는 병렬 쿼리는 스칼라 서브쿼리를 사용하지 않는 것이 좋다.
- 이럴 경우를 위해 오라클 12c부터 옵티마이저가 자동으로 쿼리를 변환해주는 Unnesting이 가능해졌다. (최적화된 조인 방식 선택)
- 하지만 이로 인한 문제가 종종 나타나기 때문에
_optimizer_unnest_scalar_sq파라미터를false로 설정하여 기능을 끌 수 있다.
