📖 학습 주제
- Airflow 운영 설정
- DBT
✏️ 주요 메모 사항 소개
Airflow 운영 설정
여태까지 배운 Airflow 사용법 만으로 프로덕션 환경에서 사용하기에는 다소 무리가 있다. 실제 환경에서 구동하려면 어떠한 것들을 바꿔줘야 하는지 알아보자.
1. airflow.cfg
airflow.cfg 파일은 굉장히 중요한 옵션들이 많이 들어가 있고, 이 파일의 내용이 바뀌면 airflow-webserver나 airflow-scheduler를 재실행할 때 변경사항이 모두 반영되기 때문에 잘 관리를 해야한다. 중요한 섹션이 많이 있지만 그 중 몇개만 적어보면
- [core] 섹션의 dags_foler
- 해당 값이 DAG들이 있는 디렉토리 path가 되어야한다. (
/var/lib/airflow/dags)
- 해당 값이 DAG들이 있는 디렉토리 path가 되어야한다. (
- dag_dir_list_interval
- dags_folder를 Airflow가 얼마나 자주 스캔하는지 명시 (초 단위)
또한 airflowignore 파일을 잘 설정해서 Airflow가 읽으면 안되는 파일들을 설정해주어서 오류가 나지 않게 하는 것도 중요하다.
2. Airflow Database upgrade
디폴트로 Sqlite가 지정이 되어있지만, 이는 테스트용으로도 적합하지 않다. docker-compose를 이용해서 설치한다면 Postgres를 사용하게 세팅이 되어있을 것이다. MySQL을 사용해도 좋고, 더욱 중요한 것은 이 DB를 주기적으로 백업해 두어야 한다.
- DB를 바꾸는 경우
airflow.cfg파일의sql_alchemy_conn을 바꿔줘야 한다.
3.Executor 설정
디폴트가 Sqlite로 지정되어 있기 때문에 airflow.cfg의 Executor 설정이 SequentialExecutor일텐데, 이를 사용환경에 맞게 바꿔주는 게 좋다.
- 싱글 서버 :
LocalExecutororCeleryExecutor - 클러스터 :
CeleryExecutororKubernetesExecutor
4. Authentication
민감한 정보들이 들어있을 수 있기 때문에 Web UI가 외부에 노출이 되면 보안 사고로 이어질 수 있다. 따라서 Authentication 기능을 키고 (Airflow 2.0 버전 이상에서는 자동으로 켜짐) 강력한 비밀번호를 사용하도록 하자. 특히 EC2와 같은 외부 네트워크에서 연결해서 사용하는 경우 꼭 설정을 체크해주자.
- 가장 좋은 방법은 VPN 뒤에 위치시켜서 액세스 자체를 못하게 설정하는 것!
5. Log & Local Data 관리
dag가 많아지고 실행기록이 많아지면 log와 local data도 그만큼 많아지기 때문에 한계에 다다를시 Airflow가 기능하지 않을 수 있다. 따라서 주기적으로 log폴더를 클린업을 하던지, S3와 같은 곳에 백업을 하던지 해서 관리를 해주어야 한다. 가능다면 고용량의 disk volume을 사용하는 것도 좋다.
- Logs ->
/dev/airflow/logs(airflow.cfg 파일 안에 Core 섹션)- base_log_forder
- child_process_log_directory
- Local data ->
/dev/airflow/data
로그 파일을 삭제하려먼 log폴더의 내용을 삭제하던가, 주기적으로 내용을 클린업 하도록 새로운 DAG를 만들어서 처리할 수도 있다. docker compose로 실행된 경우 logs 폴더가 host volume의 형태로 유지
예시 코드 : https://github.com/learndataeng/learn-airflow/blob/main/dags/Cleanup_Log.py
6. Scale Up to Scale Out
처음에는 Scale Up으로 확장을 하다가 더욱 규모가 커지면 클라우드 서비스를 이용해서 Scale Out을 해주도록 하자. 클라우드로 Airflow를 사용하는 옵션으로는 Cloud Composer, MWAA, Data Factory, Docker/K8s와 같은 것들이 있다.
7. Airflow metadata 백업
Variable, Connection과 같은 Airflow metadata들도 주기적으로 백업을 진행해 주어야 한다. db의 내용을 암호화해주는 fernet key와 같은 것들도 이에 포함되어야 한다.
메타데이터의 위치에 따라서 백업 방법이 조금 다를 수 있다.
- 외부 DB 이용 (AWS RDS, ... )
- 거기에 바로 지속적으로 백업
- Airflow와 같은 서버에 메타 데이터 DB가 있다면 (예를 들어 PostgreSQL)
- 그러면 DAG등을 이용해 주기 백업 실행 (S3로 저장)
- 예시 코드 : https://github.com/learndataeng/learn-airflow/blob/main/dags/Backup_Airflow_Data_to_S3.py
8. health-check monitoring
https://airflow.apache.org/docs/apache-airflow/stable/logging-monitoring/check-health.html
서비스가 잘 돌아가고 있는지 확인해주어야 하기 때문에 health-check 모니터링이 필요하다. 주로 web-server, scheduler, metadata database를 중점으로 모니터링을 행한다.
API를 먼저 활성화하고 Health Check Endpoint API를 모니터링 툴과 연동해서 사용하자. 어느 정도 규모가 된다면 DevOps팀과 협업하여 DataDog, Grafana와 같은 것을 사용하는 것이 일반적이다.
DBT (Data Build Tool)

ETL을 하는 이유는 결국 ELT를 하기 위함이며, 이 때 데이터 품질 검증이 매우 중요하다. DBT, Data Build Tool이란 데이터 변환 및 모델링을 위한 오픈 소스 도구로, SQL과 Jinja 템플릿을 이용해서 데이터 변환 작업을 정의하고, 이를 코드로 관리한다.
dbt는 다음과 같은 요구조건을 달성해야할 경우 좋은 옵션이 될 수 있다.
- 데이터 변경 사항을 이해하기 쉽고 필요하다면 롤백 가능
- 데이터간 리니지 확인 가능
- 데이터 품질 테스트 및 에러 보고
- Fact 테이블의 증분 로드 (Incremental Update)
- Dimension 테이블 변경 추적 (히스토리 테이블)
- 용이한 문서 작성
여태까지 우리가 사용했던 Redshift, Airflow와 연동해서 다음과 같은 구성으로 사용할 수 있다.
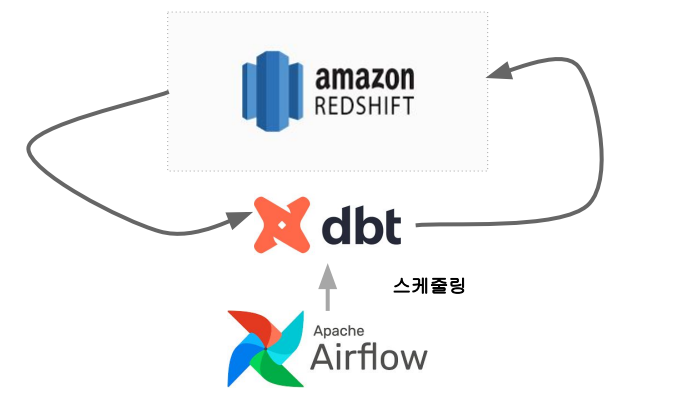
구성 컴포넌트
- 데이터 모델 (models)
- 테이블들을 몇개의 티어로 관리
- 일종의 CTAS (SELECT 문들), Lineage 트래킹
- Table, View, CTE 등등
- 데이터 품질 검증
- 스냅샷 (snapshots)
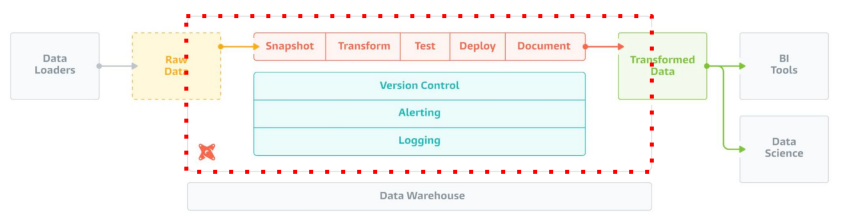
DBT 실습
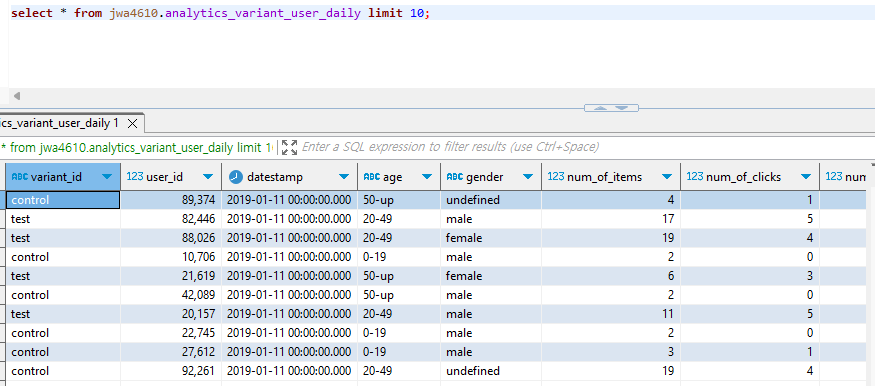
DBT를 이용하여 AB 테스트 분석을 쉽게 하기 위한 ELT 테이블을 만들어보자
- 입력 테이블 :
user_event,user_variant,user_metadata
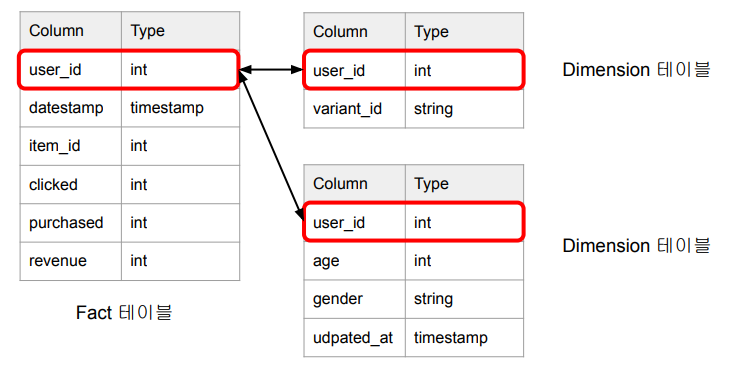
- 생성 테이블 : Variant별 사용자별 일별 요약 테이블을 만들어 보자
variant_id,user_id,datestamp,age,gender,총 impression,총 click,총 purchase,총 revenue- 최종적으로 생성된 데이터를 SELECT로 표현하면 아래와 같다
SELECT
variant_id,
ue.user_id,
datestamp,
age,
gender,
COUNT(DISTINCT item_id) num_of_items, -- 총 impression
COUNT(DISTINCT CASE WHEN clicked THEN item_id END) num_of_clicks, -- 총 click
SUM(purchased) num_of_purchases, -- 총 purchase
SUM(paidamount) revenue -- 총 revenue
FROM raw_data.user_event ue
JOIN raw_data.user_variant uv ON ue.user_id = uv.user_id
JOIN raw_data.user_metadata um ON uv.user_id = um.user_id
GROUP by 1, 2, 3, 4, 5;dbt 설치와 환경설정
공식 문서 : https://docs.getdbt.com/docs/get-started/getting-started/overview
dbt cloud를 이용해도 좋지만, 이번 실습에서는 직접 설치를 해보도록 하자. 보통 git을 사용해서 설치를 하게 되고, 그 후 dbt Connector를 설정해야 한다. Connector는 바탕이 되는 데이터 시스템을 말하고, 우리는 AWS Redshift를 이용할 것이다.
먼저 터미널에서 pip3 install dbt-redshift 명령어를 사용해서 dbt를 설치해 주자. 간혹 psycopg2 관련 오류가 날 수 있는데, Postgres 개발 패키지를 설치해주면 해결 된다. sudo apt-get install libpq-dev
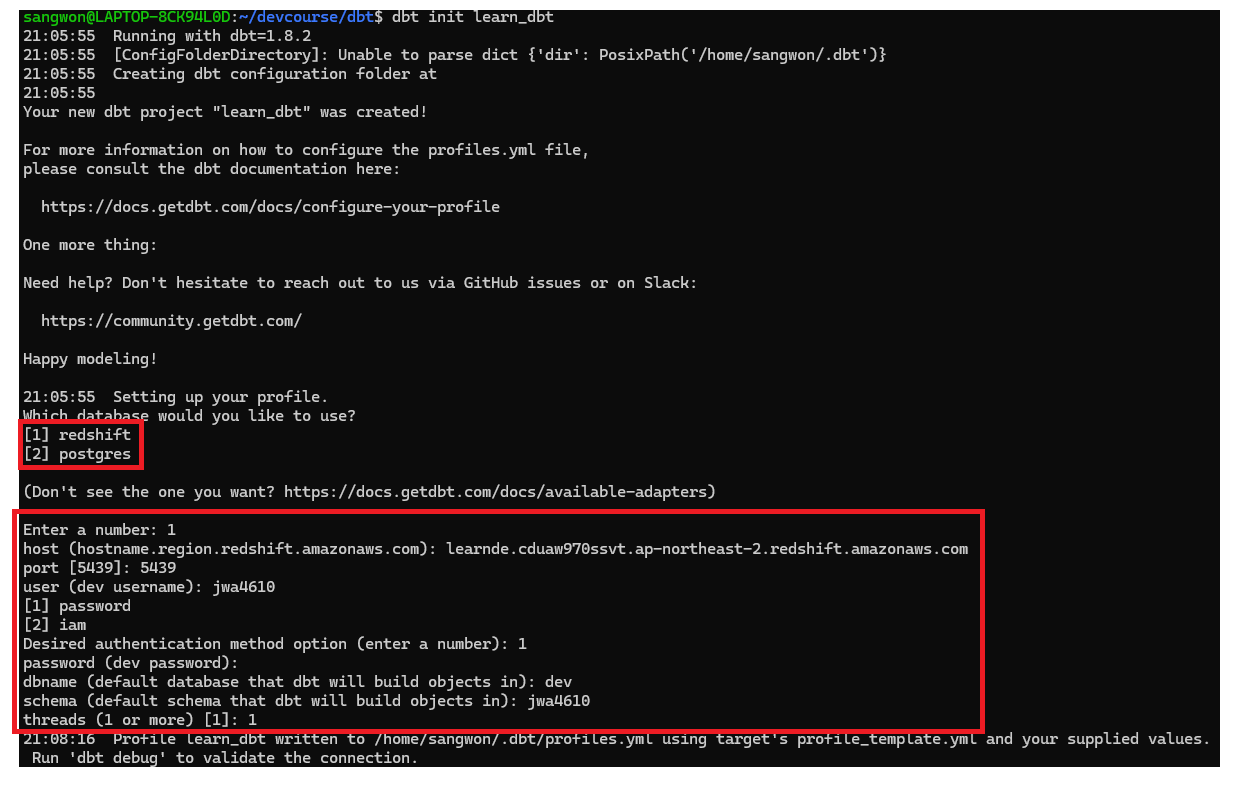
다음으로 적당한 디렉토리에서 dbt init 프로젝트명 명령어를 이용해서 프로젝트를 실행해주자. init을 하면서 redshift 관련 정보들을 입력해야 하기 때문에 미리 준비하도록 하자.
완료되면 learn_dbt라는 디렉토리가 생성되었을 것이다.
dbt Models : Input
설정이 모두 끝났다면 데이터 모델링(tier)을 진행하면 된다. Raw Data -> Staging -> Core 순으로 진행이 되고 그 후 테스트 코드를 작성한 뒤, 필요하다면 Snapshot 설정을 추가하면 전체적인 dbt 사용절차가 완료된다. 먼저 dbt Model을 사용해 입력 데이터들을 transform 해보자.
먼저 Model이란, ELT 테이블을 만듬에 있어 기본이 되는 빌딩 블록을 말한다. 테이블이나 뷰, CTE등의 형태로 존재하고, 입력, 중간, 최종 테이블을 정의하는 곳이다.
- Model의 티어
raw: ETL을 통해서 만들어진 데이터 웨어하우스 내의 테이블 (원본)staging: raw 데이터를 읽어와서 클린 업한 테이블, View로 만듬 (/models/src/*)core: staging을 가공해서 만든 최종 테이블 (/models/dim/*,/models/fact/*)
- Model 구성요소
- Input
- 입력(raw)과 중간(staging, src) 데이터 정의
- raw는 CTE로 정의
- staging은 View로 정의
- Output
- 최종(core) 데이터 정의
- core는 Table로 정의
- 이 모두는 models 폴더 밑에 sql 파일로 존재
- 기본적으로는 SELECT + Jinja 템플릿과 매크로
- 다른 테이블들을 사용 가능(reference), 이를 통해 리니지 파악
- Input

실습으로 돌아와서 일단 models 폴더 안에 src 폴더를 만들어주고 그 안에 staging 데이터를 정의할 sql 파일을 생성하자

각각 파일의 내용은 다음과 같다
src_user_event.sql
WITH src_user_event AS (
SELECT * FROM raw_data.user_event
)
SELECT
user_id,
datestamp,
item_id,
clicked,
purchased,
paidamount
FROM
src_user_eventsrc_user_metadata.sql
WITH src_user_metadata AS (
SELECT * FROM raw_data.user_metadata
)
SELECT
user_id,
age,
gender,
updated_at
FROM
src_user_metadatasrc_user_variant.sql
WITH src_user_variant AS (
SELECT * FROM raw_data.user_variant
)
SELECT
user_id,
variant_id
FROM
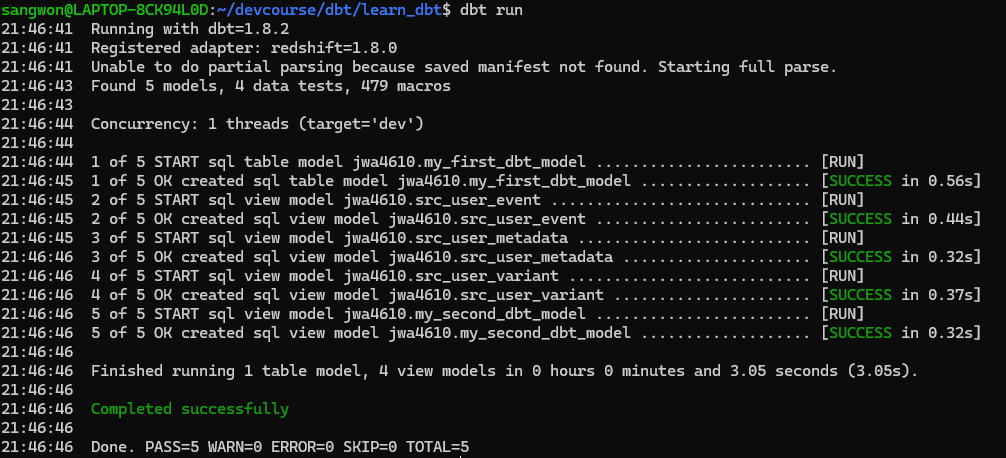
src_user_variant다 작성했다면 dbt run 명령어를 사용해서 model을 빌드해주자.
dbt Models : Output
이제 최종 출력 데이터를 만드는 과정을 진행할 것이다. dbt 에서는 Materialization이라는 것을 사용해서 이 작업을 수행하는데 먼저 이 Materialization이 무엇인지 부터 알아보자.
Materialization: 입력 데이터(테이블)들을 연결해서 새로운 데이터(테이블)를 생성하는 것, 보통 여기서 추가 transformation이나 데이터 클린업을 수행한다. dbt에서는 4가지의 내장 materialization이 제공되고, 파일이나 프로젝트 레벨에서 사용이 가능하다. 사용 방법은 dbt run을 기타 파라미터를 가지고 실행하면 된다.
- Materialization 종류
- View : 데이터를 자주 사용하지 않는 경우
- Table : 데이터를 반복해서 자주 사용하는 경우
- Incremental (Table Appends) : 과거 레코드를 수정할 필요가 없는 경우
- Fact 테이블
- Ephemeral (CTE) : 한 SELECT 에서 자주 사용되는 데이터를 모듈화하는데 사용
먼저 models 밑에 core 테이블들을 위한 폴더를 생성하고 sql 파일을 만들어 주자. 보통 이 sql문에서
- dim 폴더 :
dim_user_variant.sql,dim_user_metadata.sql - fact 폴더 :
fact_user_event.sql
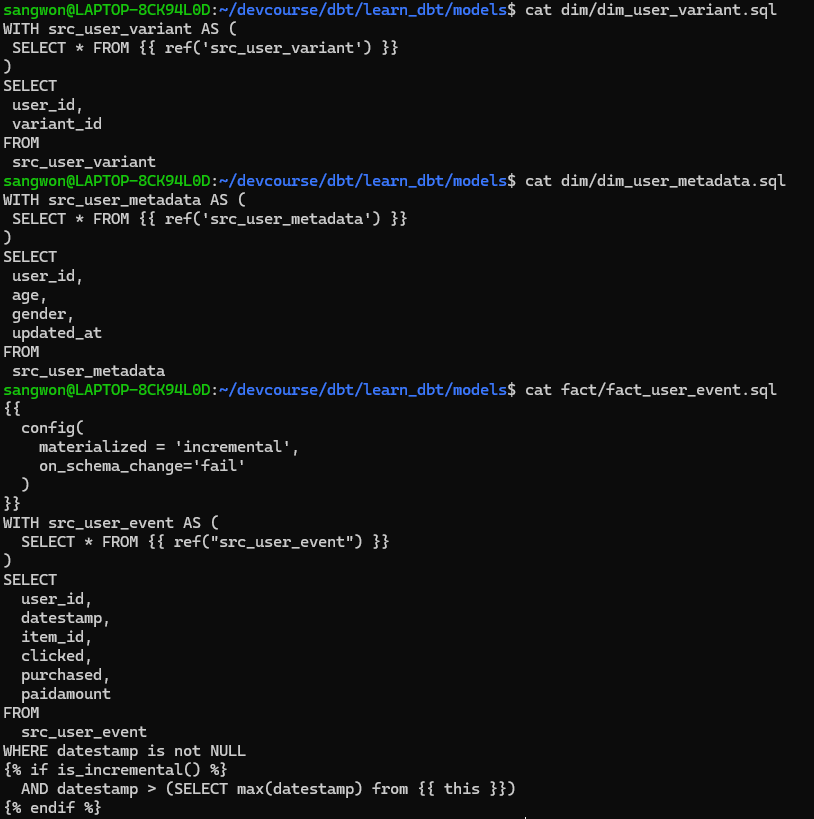
다음으로 materialized format을 결정해주자. 최종 Core 테이블들은 view가 아닌 table로 빌드하는 것이 좋기 때문에 dbt_project.yml 파일을 편집하자.
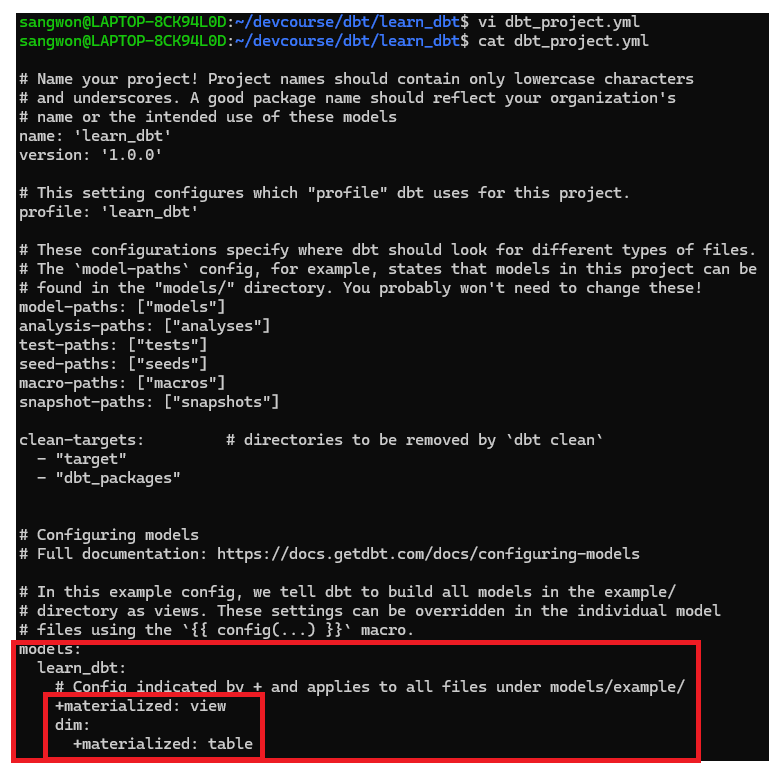
이젠 다시 dbt run 혹은 dbt compile 명령어를 사용해서 빌드해주자. dbt compile 명령어는 빌드는 하되, 실행은 하지 않는 명령어이다.
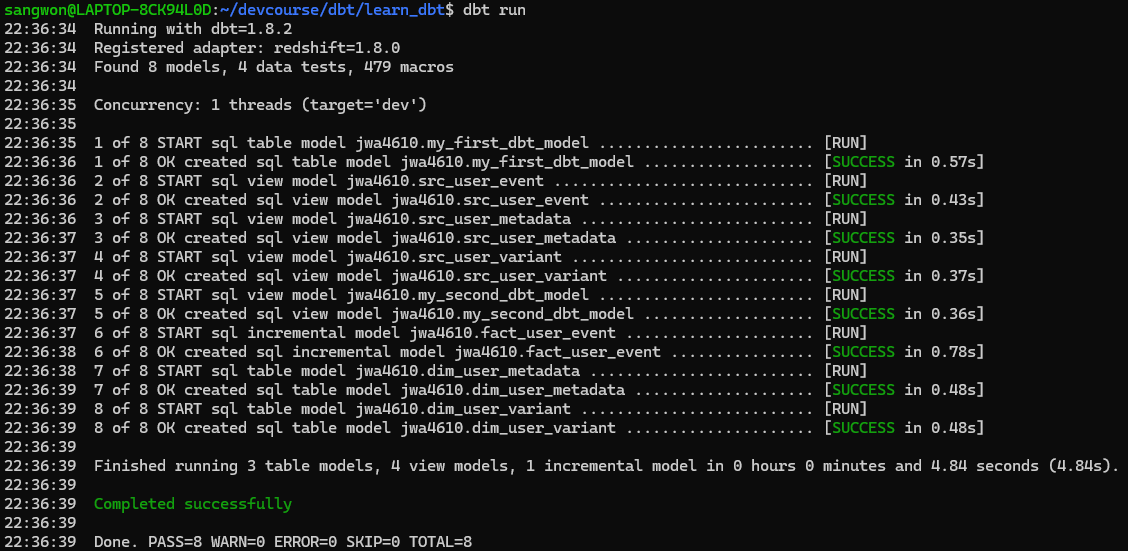
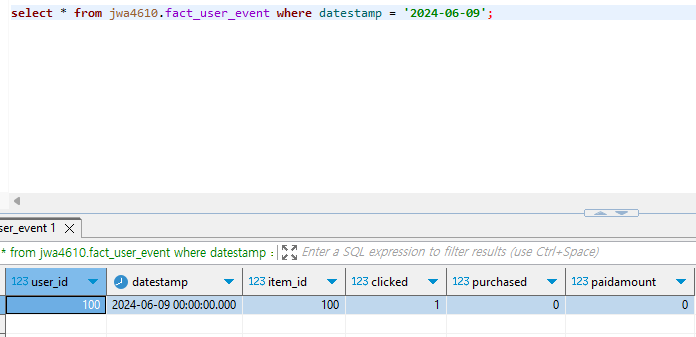
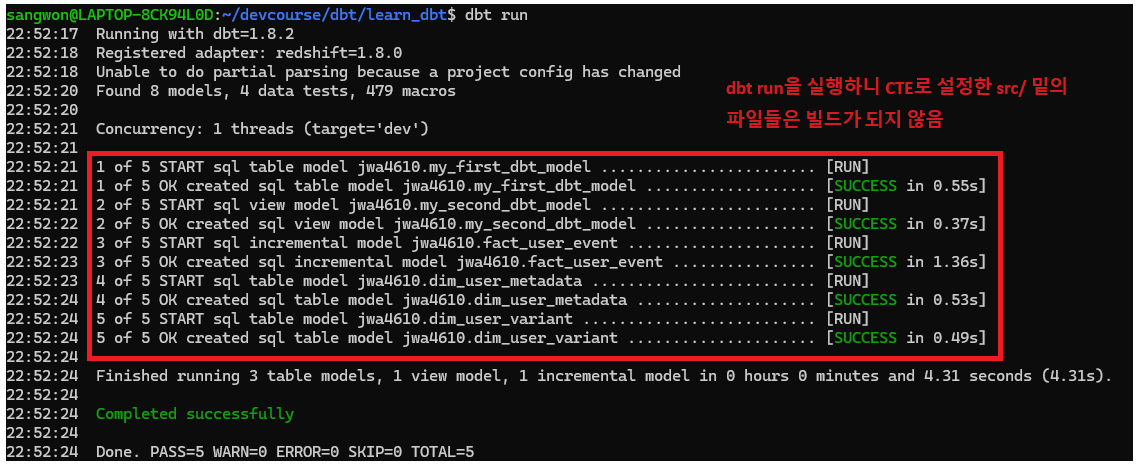
제대로 Incremental하게 업데이트되었는지 확인하기 위해서 Redshift 툴에서 레코드를 추가해주고 다시 dbt run을 수행해보자. 만약 제대로 실행되었다면 fact_user_event 테이블에서 확인할 수 있을 것이다.
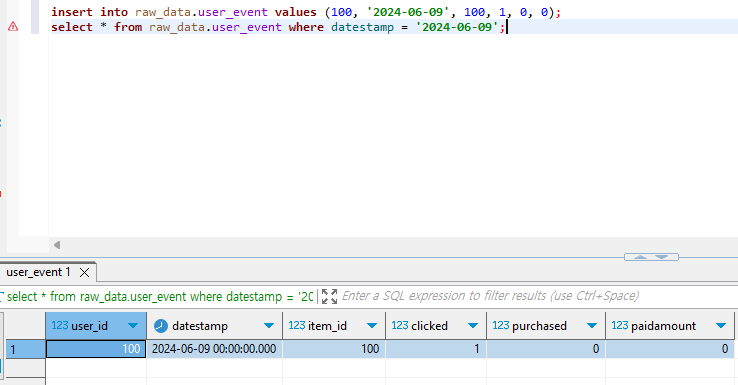
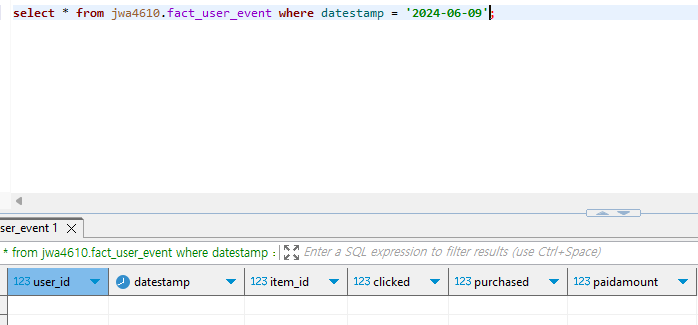
당연히 현재 fact_user_event 테이블에는 해당 레코드가 없을 것이다. dbt run을 실행하고 다시 확인해보자.
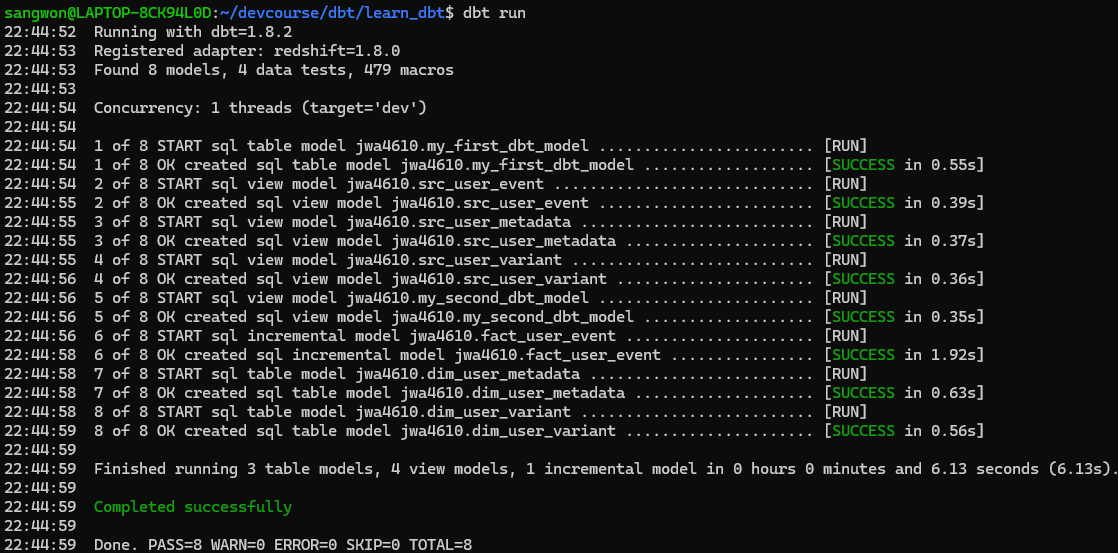
dbt run을 실행하니 fact_user_event 테이블에 우리가 만든 새로운 레코드가 추가된 것을 볼 수 있다.
추가로, src 테이블들을 굳이 빌드할 필요가 있나 싶기에 src 테이블들을 CTE로 변환해보자. 먼저 만들어진 VIEW를 먼저 삭제하고 dbt_project.yml 파일을 수정한 뒤, dbt run을 실행해보자. 이제 SRC 테이블들은 CTE 형태로 임베드되어서 빌드될 것이다.
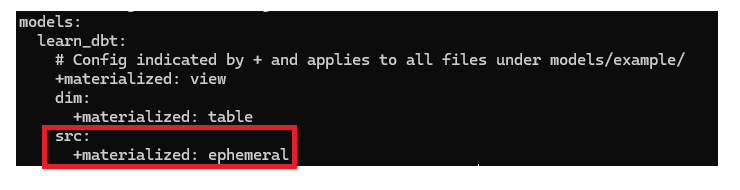
dbt Models : 최종
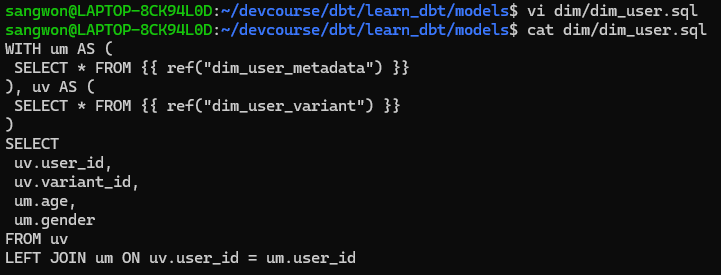
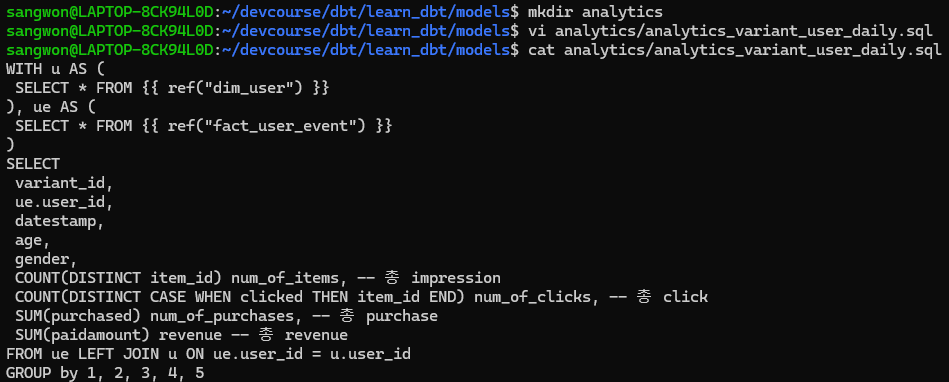
최종적으로 variant와 metadata를 합쳐서
dim_user라는 테이블을 만들고, 이를 user_event 테이블과 결합시켜 새로운analytics_variant_user_daily테이블을 만들어보자.
dim_user.sql만들기
analytics테이블 만들기
dbt run
- 테이블 확인해보기