
📖 학습 주제
- dbt seeds
- dbt sources
- snapshots
- dbt tests
- 데이터 카탈로그
✏️ 주요 메모 사항 소개
dbt Seeds
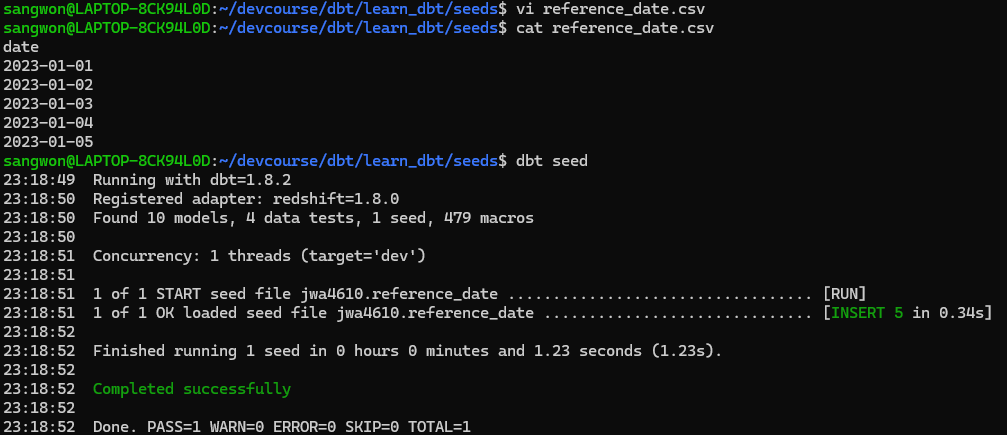
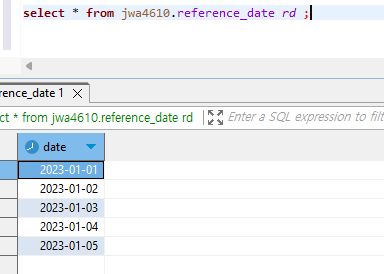
많은 dimension 테이블들은 크기가 작고 많이 변하지 않기 때문에 Seeds라는 기능을 사용하면 이를 파일 형태로 데이터 웨어하우스로 로드할 수 있다. 보통 csv 파일을 사용하고, 사용 방법은 다음과 같다.
-
seeds 폴더 밑에 적당히 .csv 파일을 하나 생성
-
dbt seed명령어 실행
dbt Sources
Staging 테이블을 만들 때 입력 테이블들이 자주 바뀐다면 models 밑의 .sql 파일들을 일일이 찾아 바꿔줘야하는 번거로움이 있다. 이걸 해결하기 위해 사용하는 것이 Sources이다. 입력 테이블에 별칭을 주고, 별칭을 Staging 테이블에서 사용하는 방식이다.
Sources는 기본적으로 처음 입력이 되는 ETL 테이블을 대상으로 한다. 테이블 이름들에 별명(alias)을 주어서 ETL 단의 소스 테이블이 바뀌어도 뒤에 영향을 주지 않는다. 추상화를 통한 변경처리를 용이하게 하는 것. 이 별명은 source 이름과 새 테이블 이름의 두 가지로 구성된다. 추가적으로 Source 테이블들에 새 레코드가 있는지 체크해주는 기능도 제공한다.
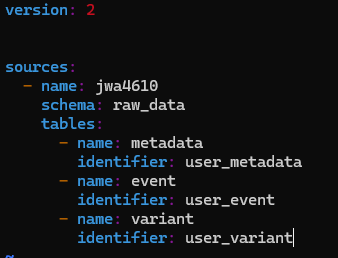
만약 models/sources.yml 파일을 만든 뒤, 다음과 같이 내용을 작성한다면, raw_data.user_metadata는 JINJA에서 source(“jwa4610”, “metadata”)로 지칭된다.
Sources 최신성 (Freshness)
- 특정 데이터가 소스와 비교해서 얼마나 최신성이 떨어지는지 체크하는 기능
- dbt source freshness 명령으로 수행
- 이를 하려면
models/sources.yml의 해당 테이블 밑에 아래 설정을 추가해야 한다.

dbt Snapshots
Dimension 테이블은 성격에 따라 변경이 자주 생길 수 있다. Snapshot이란 dbt가 테이블의 변화를 계속적으로 기록함으로써 과거 어느 시점이건 다시 돌아가서 테이블의 내용을 볼 수 있는 기능을 이야기 한다. 이를 통해 테이블에 문제가 있을 경우 과거 데이터로 롤백이 가능하고, 다양한 데이터 관련 문제 디버깅도 쉬워진다.
Snapshot을 사용하려면 snapshots/ 폴더 안에 .sql파일을 만들어야 한다.
- 예시
{% snapshot scd_user_metadata %}
{{
config(
target_schema='keeyong',
unique_key='user_id',
strategy='timestamp',
updated_at='updated_at',
invalidate_hard_deletes=True
)
}}
SELECT * FROM {{ source('jwa4610', 'metadata') }}
{% endsnapshot %}다음으로 dbt snapshot 명령어를 실행하면 된다.
dbt Tests
데이터 품질을 테스트하는 방법으로 dbt에서는 두 가지가 존재한다.
- 내장 일반 테스트 ("Generic")
- unique, not_null, accepted_values, relationships 등의 테스트 지원
- models 폴더

- 커스텀 테스트 ("Singular")
- 기본적으로 SELECT로 간단하며 결과가 리턴되면 "실패"로 간주
- tests 폴더

