📖 학습 주제
- Spark 파일 포맷
- Spark 내부 동작
- Bucketing과 Partitioning
✏️ 주요 메모 사항 소개
Spark 파일 포맷
데이터는 디스크에 파일로 저장되고, 일에 맞게 최적화가 필요하다.

Spark에서 사용하는 주요 파일 타입은 다음과 같다. (PARQUET을 많이 사용)
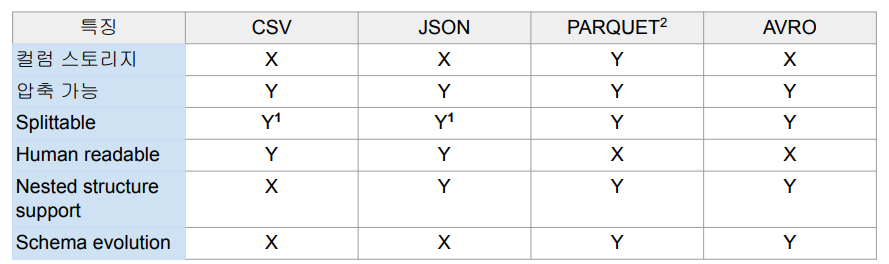
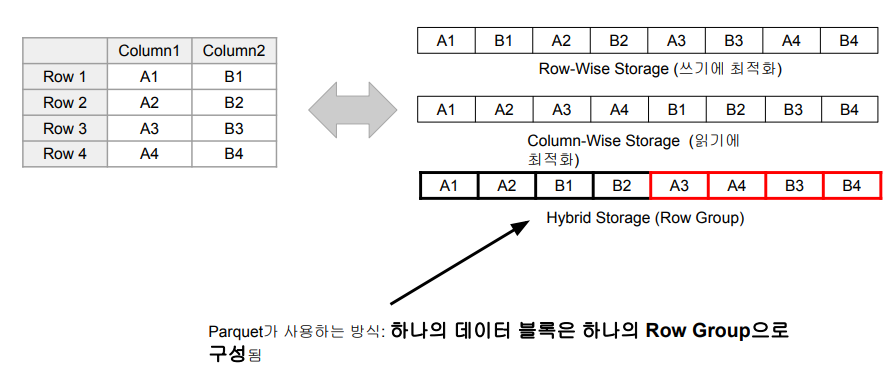
PARQUET
Spark의 기본 파일 포맷
Spark 내부 동작
Spark는 개발자가 만든 코드를 어떻게 변환하여 실행하는지 알아보기 위해 Spark의 Execution Plan을 알아보자.
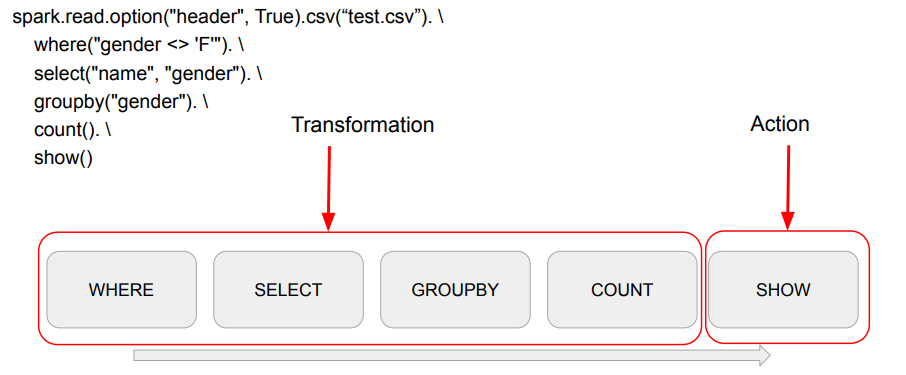
Transformations and Actions
- Transformations
- Narrow Dependencies: 독립적인 Partition level 작업
- select, filter, map 등등
- Wide Dependencies: Shuffling이 필요한 작업
- groupby, reduceby, partitionby, repartition 등등
- Narrow Dependencies: 독립적인 Partition level 작업
- Actions
- Read, Write, Show, Collect -> Job을 실행시킴 (실제 코드가 실행됨)
- Lazy Execution (실행을 최대한 미룸)
- 더 많은 오퍼레이션을 볼 수 있기에 최적화를 더 잘할 수 있음. 그래서 SQL이 더 선호
Job, Stage, Tasks
Action은 Job을 하나 만들어내고 실제 코드가 실행된다.
- Job
- 하나 혹은 그 이상의 Stage로 구성됨
- Stage는 Shuffling이 발생하는 경우 새로 생김
- Stage
- DAG의 형태로 구성된 Task들 존재
- 여기 Task들은 병렬 실행이 가능
- Task
- 가장 작은 실행 유닛으로 Executor에 의해 실행됨
Bucketing & Partitioning
둘다 Hive 메타스토어의 사용이 필요 (saveAsTable), 데이터 저장을 이후 반복처리에 최적화된 방법으로 하는 것
- Bucketing
- Shuffling을 최소화하는 것이 목적
- 먼저 Aggregation이나 Window 함수나 JOIN에서 많이 사용되는 컬럼이 있는지?
- 있다면 데이터를 이 특정 컬럼(들)을 기준으로 테이블로 저장
- 이 때의 버킷의 수도 지정
- File System Partitioning
- 원래 Hive에서 많이 사용
- 데이터의 특정 컬럼(들)을 기준으로 폴더 구조를 만들어 데이터 저장 최적화
- 위의 컬럼들을 Partition Key라고 부름
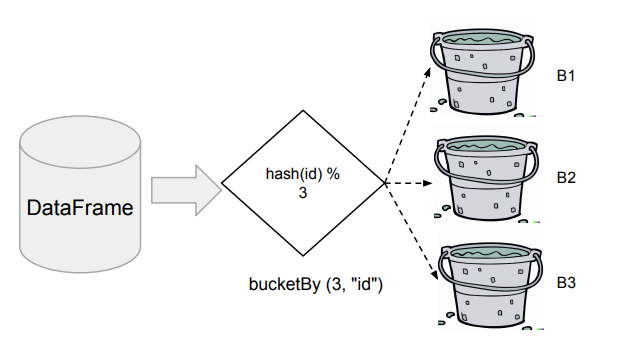
Bucketing
Bucketing이란 DataFrame을 특정 ID를 기준으로 나눠서 테이블로 저장하는 것을 말한다. 다음부터는 이를 로딩하여 사용함으로써 반복 처리시 시간을 단축할 수 있다.
- DataFrameWriter의 bucketBy 함수 사용
- Bucket의 수와 기준 ID를 지정
- 데이터의 특성을 잘 알고 있는 경우 사용이 가능
Partitioning
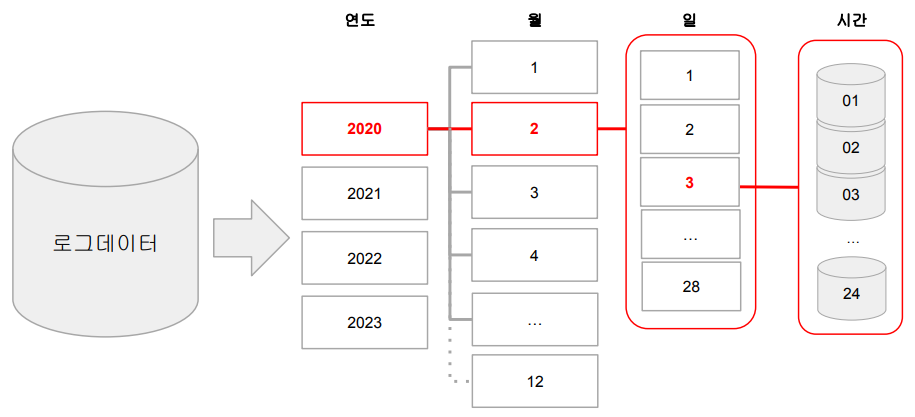
Partitioning이란 데이터를 Partition Key 기반 폴더 ("Partition") 구조로 물리적으로 나눠서 저장하는 방식을 말한다. Partitioning의 예와 장점으로는 다음과 같은 것이 있다.
- 굉장히 큰 로그 파일을 데이터 생성시간 기반으로 데이터 읽기를 많이 한다면?
- 데이터 자체를 연도-월-일의 폴더 구조로 저장
- 보통 위의 구조로 이미 저장되어 있는 경우가 많음
-
이를 통해 데이터 읽기 과정을 최적화 (스캐닝 과정이 줄어들거나 없어짐)
-
데이터 관리도 쉬워짐 (Retention Policy 적용 시)
DataFrameWriter의 partitionBy 함수를 사용한다. 주의할 점은 Partition Key를 잘못 선택하면 엄청나게 많은 파일들이 생성된다. 따라서 Partition Key는 카디널리티가 가장 낮은 값을 선택하는 것이 좋다.