
📖 학습 주제
- SparkML
- SparkML Pipeline
- SparkML EMR 론치
✏️ 주요 메모 사항 소개
SparkML
머신러닝 관련 다양한 알고리즘, 유틸리티로 구성된 라이브러리로 데이터의 크기와 상관없이 ML을 할 수 있다는 장점이 있다. RDD 기반과 데이터프레임 기반의 두 버전이 존재한다. 데이터프레임 기반의 spark.ml을 사용하는 것을 권장
import pyspark.ml
SparkML의 장점은 원스톱 ML 프레임워크라는 점이다.
- 데이터프레임과 SparkSQL등을 이용해 전처리
- Spark MLlib를 이용해 모델 빌딩
- ML Pipeline을 통해 모델 빌딩 자동화
- MLflow로 모델 관리하고 서빙
- MLflow : 모델 개발과 테스트와 관리와 서빙까지 제공해주는 End-to-End 프레임워크
SparkML 모델 빌딩 구조
여느 라이브러리를 사용한 모델 빌딩과 크게 다르지 않고 다음과 같은 STEP을 따른다.
- 트레이닝셋 전처리
- 모델 빌딩
- 모델 검증 (confusion matrix)
Scikit-Learn과 비교했을 때 Scikit-Learn은 하나의 컴퓨터에서 돌아가는 모델 빌딩이고, SparkML은 여러 서버 위에서 돌아가는 모델일 빌딩한다는 차이점이 있다. 즉 데이터의 크기가 차이
- 트레이닝 셋의 크기가 크면 전처리와 모델 빌딩에 있어 Spark이 큰 장점을 가짐
- Spark은 ML 파이프라인을 통해 모델 개발의 반복을 쉽게 해줌
SparkML Pipeline
모델 빌딩과 관련해서 다음과 같은 흔한 문제들이 발생할 수 있다.
- 트레이닝 셋의 관리가 안됨
- 모델 훈련 방법이 기록이 안됨
- 어떤 트레이닝 셋을 사용했는지?
- 어떤 피쳐들을 사용했는지?
- 하이퍼 파라미터는 무엇을 사용했는지?
- 모델 훈련에 많은 시간 소요
- 모델 훈련이 자동화가 안된 경우 매번 각 스텝들을 노트북 등에서 일일히 수행
- 에러가 발생할 여지가 많음 (특정 스텝을 까먹거나 조금 다른 방식을 적용하거나)
ML Pipeline의 등장으로 2번과 3번의 문제를 해결 가능. 자동화를 통해 에러 소지를 줄이고 반복(모델개발 & 테스트)을 빠르게 가능하게 해줌. 또한 머신러닝 알고리즘에 관계없이 일관된 형태의 API를 사용하여 모델링이 가능하다.
ML Pipeline은 다음 4가지 요소로 구성된다.
- 데이터프레임
- Transformer
- Estimator
- Parameter
- 정리하면 ML Pipeline란 하나 이상의 Transformer와 Estimator가 연결된 모델링 워크플로우
- 입력은 데이터프레임
- 출력은 머신러닝 모델
- ML Pipeline 그자체도 Estimator
- 따라서 ML Pipeline의 실행은 fit 함수의 호출로 시작
- 저장했다가 나중에 다시 로딩하는 것이 가능 (Persistence)
- 한번 파이프라인을 만들면 반복 모델빌딩이 쉬워짐
Spark EMR 론치
AWS에서 Spark을 실행하려면 EMR (Elastic MapReduce) 위에서 실행하는 것이 일반적이다. EC2 서버들을 worker node로 사용하고 S3를 HDFS로 사용하고 AWS 내의 다른 서비스들과 연동이 쉽다는 장점이 있다.
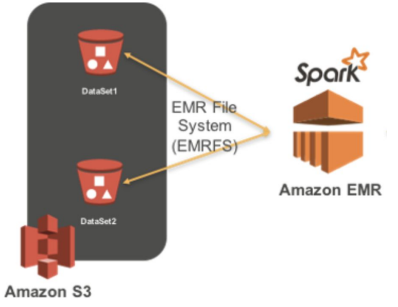
[실행 과정]
- AWS의 EMR (Elastic MapReduce - 하둡) 클러스터 생성
- EMR 생성시 Spark을 실행 (옵션으로 선택)
- S3를 기본 파일 시스템으로 사용
- EMR의 마스터 노드를 드라이버 노드로 사용
- 마스터 노드를 SSH로 로그인
- spark-submit를 사용
- Spark의 Cluster 모드에 해당
- 마스터 노드를 SSH로 로그인
