
📖 학습 주제
- Kafka 소개
- Kafka 아키텍처
- Kafka 기타 기능
- Kafka 설치
✏️ 주요 메모 사항 소개
Kafaka 소개

Kafka는 실시간 데이터를 처리하기 위해 설계된 오픈소스 분산 스트리밍 플랫폼이다. Scalability와 Falut Tolerance를 제공하는 Publish-Subscription 메시징 시스템을 사용한다. (Producer - Consumer)
Kafka는 다음과 같은 특징이 있다.
- High Throughput과 Low Latency 특징으로 실시간 데이터 처리에 맞게 구현됨
- 분산 아키텍처를 따르기 때문에 Scale Out이란 형태로 스케일 가능
- 서버 추가를 통해 Scalability 달성 (서버 = Broker)
- 정해진 보유기간 (retention period) 동안 메시지를 저장
- 메시지 생산과 소비를 분리
- 생산자와 소비자가 각자의 속도에 맞춰 독립적으로 작업이 가능하도록 함 (시스템 안정성 UP)
- 한 파티션 내에서는 메시지 순서를 보장해줌
- 다수의 파티션에 걸쳐서는 "Eventually Consistent"
- 토픽을 생성할 때 지정 가능 (Eventual Consistency vs Strong Consistency)
Kafka 아키텍처
데이터 이벤트 스트림
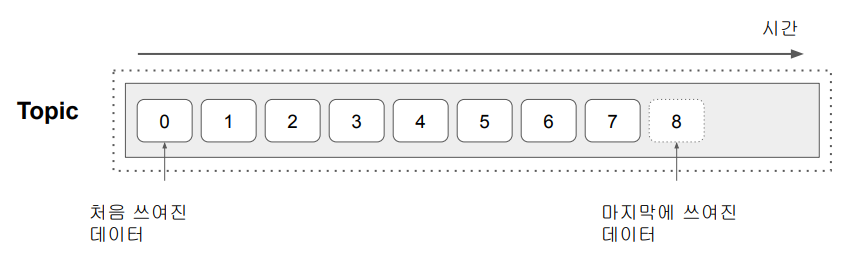
Kafka에서의 데이터 이벤트 스트림은 Topic이라고 한다. Producer는 Topic을 만들고, Consumer는 Topic에서 데이터를 읽어들이는 구조로 이루어 지고, 다수의 Consumer가 같은 Topic을 기반으로 읽어들이는 것이 가능하다. 즉, 하나의 Producer가 만들어낸 이벤트들이 일련번호 순으로 저장이 된 것이 Topic이다.
Message(Event) 구조
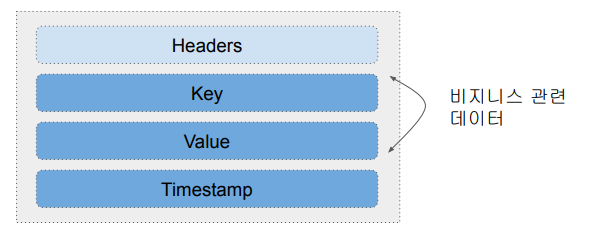
- 최대 1MB
- Timestamp는 보통 데이터가 Topic에 추가된 시점
- Key 자체도 복잡한 구조를 가질 수 있음
- Keu가 나중에 Topic 데이터를 나눠서 저장할 때 사용됨 (Partitioning)
- Header는 선택적 구성요소로 경량 메타 데이터 정보 (key-value pairs)
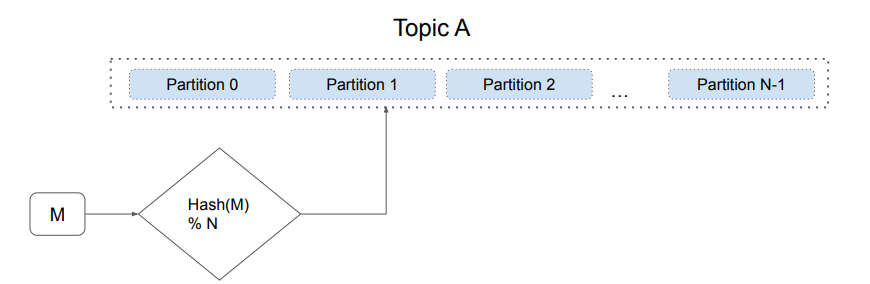
Topic & Partition
- 하나의 Topic은 확장성을 위해 다수의 Partition으로 나뉘어 저장됨
- 메세지가 어느 Partition에 속하는지 결정하는 방식은 키의 유무에 따라 달라짐
- 키가 있다면 Hashing 값을 Partition의 수로 나눈 나머지로 결정
- 키가 없다면 라운들 로빈으로 결정 (비추)
하나의 Partition은 Fail-over를 위해 Replication Partition을 가지고, 각 Partiton 별로 Leader와 Follower가 존재한다.
- 쓰기는 Leader를 통해 이뤄지고 읽기는 Leader/Follower들을 통해 이뤄짐
- Partition 별로 Consistency Level을 설정 가능 (in-sync replica - "ack")

Broker
Broker란 실제 데이터를 저장하는 서버를 말한다. Kafka Server나 Kafka Node라고 부르기도 한다.
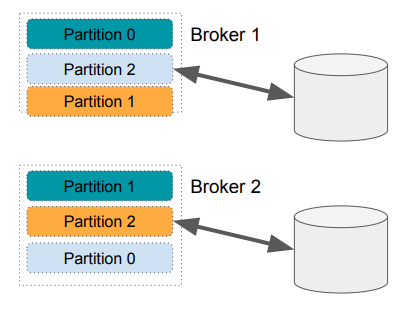
- Kafka 클러스터는 기본적으로 다수의 Broker로 구성됨
- 여기에 원활한 관리와 부가 기능을 위한 다른 서비스들이 추가됨 (Zookeeper가 대표적)
- 한 클러스터는 최대 20만개까지 partition을 관리 가능
- Broker들이 실제로 Producer/Consumer들과 통신 수행
- 앞서 이야기한 Topic의 Partition들을 실제로 관리해주는 것이 Broker
- 한 Broker는 최대 4000개의 partition을 처리 가능
- Broker는 물리서버 혹은 VM 위에서 동작
- 해당 서버의 디스크에 Partition 데이터들을 기록함
- Broker의 수를 늘림으로써 클러스터 용량을 늘림 (Scale Out)
- 앞서 20만개, 4천개 제약은 Zookeeper를 사용하는 경우임
- 이 문제 해결을 위해서 Zookeeper를 대체하는 모드도 존재 (KRaft)
Kafka 기타 기능
Kafka Connect
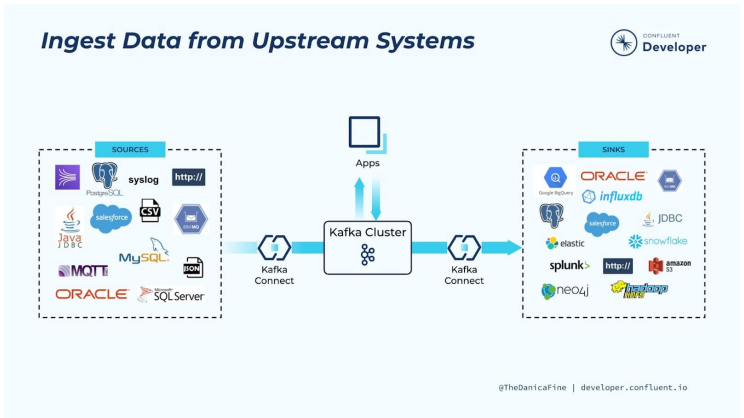
- Kafka Connect는 Kafka 위에 만들어진 중앙집중 데이터 허브
- 별도의 서버들이 필요하며 Kafka Connect는 별도의 오픈소스 프로젝트임
- 데이터 버스 혹은 메세지 버스라고 볼 수 있음
- 두 가지 모드가 존재
- Standalone 모드: 개발과 테스트
- Distributed 모드
- 데이터 시스템들 간의 데이터를 주고 받는 용도로 Kafka를 사용하는 것
- 데이터 시스템의 예: 데이터베이스, 파일 시스템, 키-값 저장소, 검색 인덱스 등등
- 데이터 소스와 데이터 싱크
- Broker들 중 일부나 별개 서버들로 Kafka Connect를 구성
- 그 안에 Task들을 Worker들이 수행. 여기서 Task들은 Producer/Consumer 역할
- Source Task, Sink Task
- 외부 데이터(Data Source)를 이벤트 스트림으로 읽어오는 것이 가능
- 내부 데이터를 외부(Data Sink)로 내보내어 Kafka를 기존 시스템과 지속적으로 통합 가능
- 예: S3 버킷으로 쉽게 저장
- 그 안에 Task들을 Worker들이 수행. 여기서 Task들은 Producer/Consumer 역할
Kafka Schema Registry
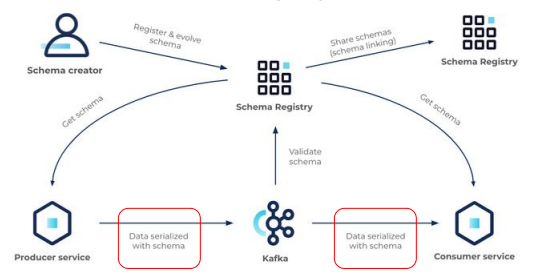
- Schema Registry는 Topic 메시지 데이터에 대한 스키마를 관리 및 검증하는데 사용
- Producer와 Consumer는 Schema Registry를 사용하여 스키마 변경을 처리
- Schema ID(와 버전)를 사용해서 다양한 포맷 변천(Schema Evolution)을 지원
- 보통 AVRO를 데이터 포맷으로 사용 (Protobuf, JSON)
- 포맷 변경을 처리하는 방법
- Forward Compatibility: Producer부터 변경하고 Consumer를 점진적으로 변경
- Backward Compatibility: Consumer부터 변경하고 Producer를 점진적으로 변경
- Full Compatibility: 둘다 변경

<참고 : Serialization vs Deserialization>
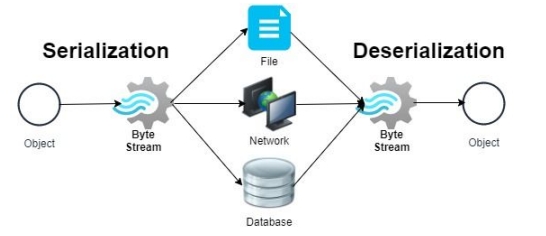
- Serialization (직렬화)
- 객체의 상태를 저장하거나 전송할 수 있는 형태로 변환하는 프로세스
- 보통 이 과정에서 데이터 압축등을 수행. 가능하다면 보내는 데이터의 스키마 정보 추가
- Deserialization (역직렬화)
- Serialized된 데이터를 다시 사용할 수 있는 형태로 변환하는 Deserialization
- 이 과정에서 데이터 압축을 해제하거나 스키마 정보 등이 있다면 데이터 포맷 검증도 수행
Kafka REST proxy
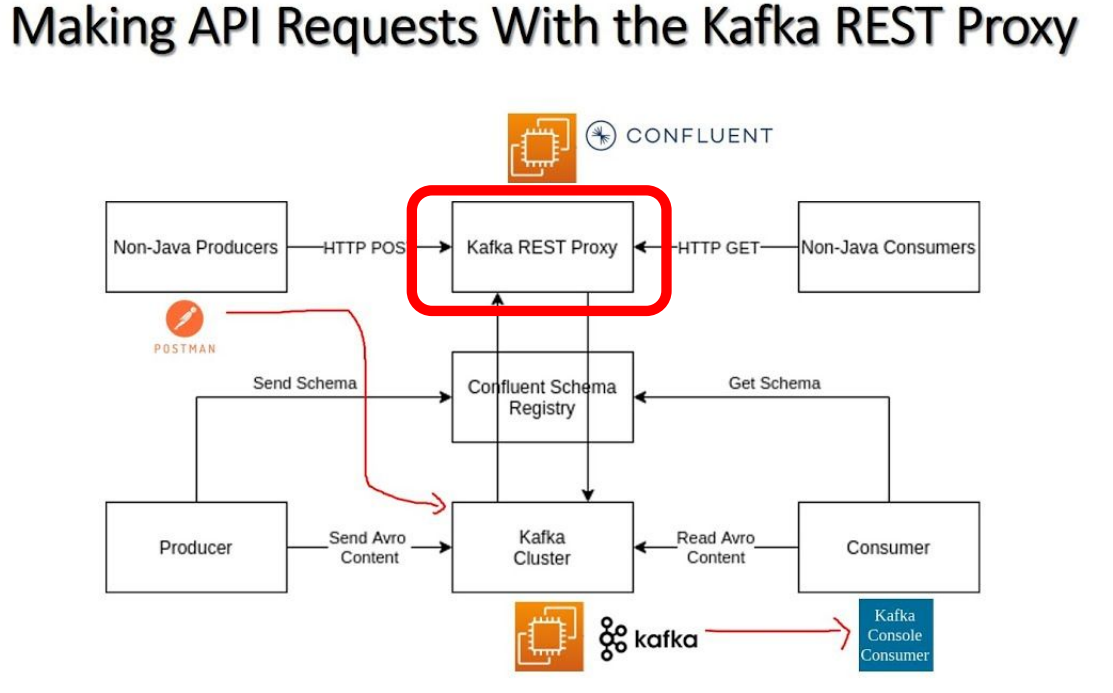
- 클라이언트가 API 호출을 사용하여 Kafka를 사용 가능하게 해줌
- 메시지를 생성 및 소비하고, 토픽을 관리하는 간단하고 표준화된 방법을 제공
- REST Proxy는 메세지 Serialization과 Deserialization을 대신 수행해주고 Load Balancing도수행
- 특히 사내 네트워크 밖에서 Kafka를 접근해야할 필요성이 있는 경우 더 유용
Kafka Streams
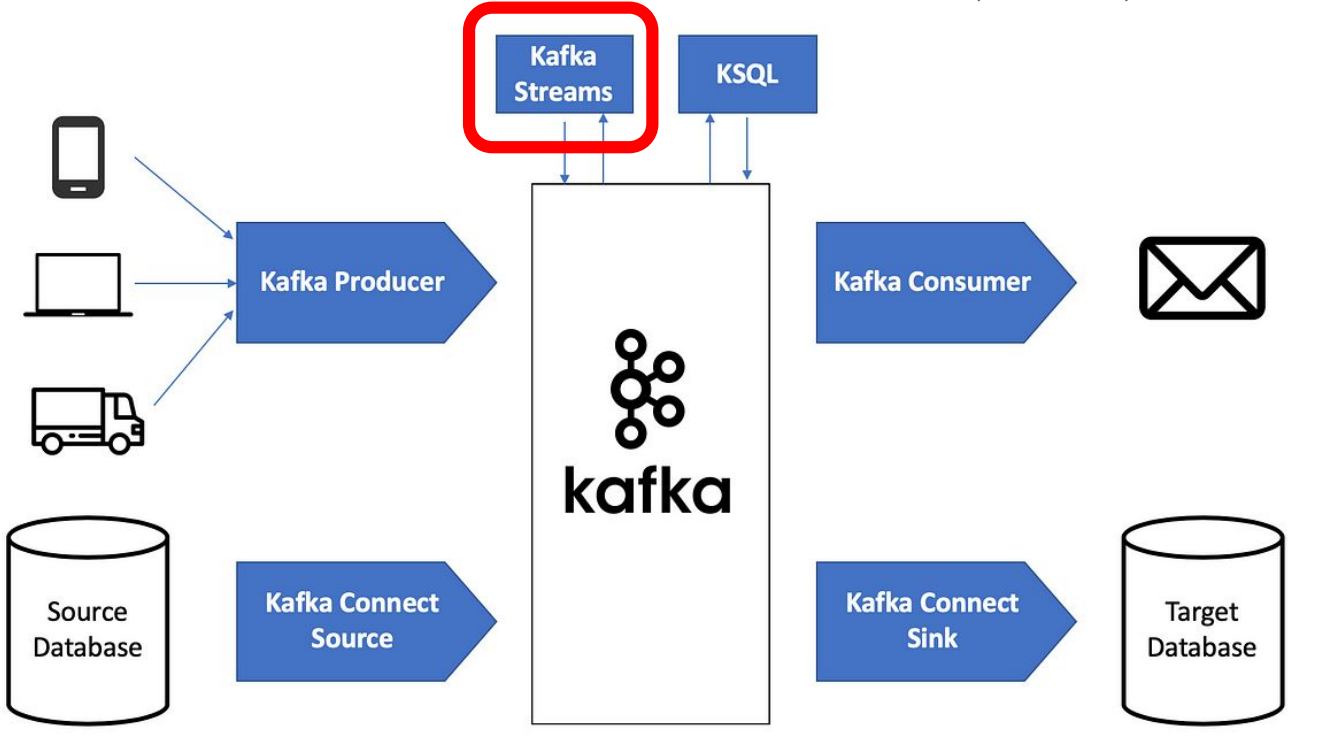
- Kafaka Topic을 소비하고 생성하는 실시간 스트림 처리 라이브러리
- Spark Streaming으로 Kafka Topic을 처리하는 경우는 조금 더 micro batch에 가까움
- Kafka Streams로 Kafka Topic을 처리하는 것은 조금 더 Realtime에 가까움 (레코드 단위 처리)
ksqlDB
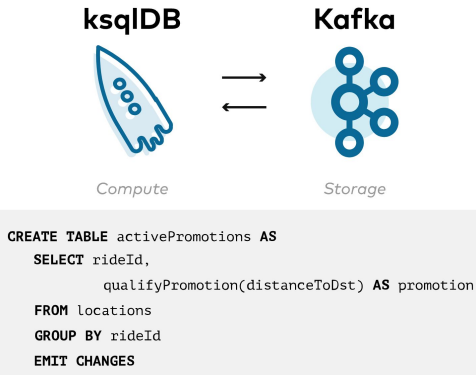
- Kafka Streams로 구현된 스트림 처리 데이터베이스로 KSQL을 대체
- SQL과 유사한 쿼리 언어. 필터링, 집계, 조인, 윈도우잉 등과 같은 SQL 작업 지원
- 연속 쿼리: ksqlDB를 사용하면 데이터가 실시간으로 도착할 때 지속적으로 처리하는 연속 쿼리 생성 가능
- 지속 업데이트되는 뷰 지원: 실시간으로 지속적으로 업데이트되는 집계 및 변환 가능
- Spark에서 보는 것과 비슷한 추세: SQL이 대세
