Transformer from scratch (Attention is all you need)
1. RNN의 문제점
RNN(Recurrent Neural Network) 계열의 모델들(e.g: RNN, LSTM, GRU)은 시퀸스 데이터를 처리하는데 있어서 훌륭한 성능을 보여줬지만 다음과 같은 문제점을 가지고 있다.
- 장기 의존성
RNN은 이론적으로 시퀸스 내의 모든 요소들의 종속성에 대해 학습할 수 있지만, 실제로는 순전파 과정에서 시퀸스의 시작 부분에서 발생한 정보를 많이 잃어버린다. 또한 시간을 거슬러 역전파하는 과정에서 그래디언트(Gradient)가 매 단계마다 곱해지기 때문에 기울기 소멸(Gradient Vanishing) 또는 기울기 폭발(Gradient Exploding) 현상이 발생해 장기적인 의존성(Long-Term Dependency)을 제대로 학습하지 못하게 된다.
이러한 문제는 LSTM이나 GRU와 같은 구조를 이용하여 어느정도 개선할 수 있으나, 여전히 장기 의존성을 완벽하게 학습하는 것은 어렵다.
- 병렬처리 불가능
RNN은 이전 시간 단계(time step)의 출력이 다음 시간 단계의 입력으로 사용되기 때문에, 각 시간 단계를 독립적으로 처리할 수 없다. 각 시간 단계의 연산을 위해서는 현재의 입력과 이전 단계의 hidden state가 필요하다. 즉, 특정 시간 단계에서의 출력은 그 이전 시간 단계의 계산에 의존적이다. 이로 인해, RNN은 시퀀스의 각 요소를 독립적으로 처리할 수 없으며, 병렬적인 계산이 불가능하게 된다. 또한, 이러한 특징으로 인해 학습 시간이 길어지게 된다.
2. Transformer가 RNN의 문제를 해결하는 방법
Transformer는 새로운 모델 아키텍쳐를 통해 앞서 언급한 문제들을 해결했다. 어떤 방식으로 문제를 해결했는지 간략하게 살펴보자.
- Self-attentiom Mechanism
Transformer는 시퀸스 내의 요소 간의 관계에 대해 학습하기 위해서 Self-attention이라는 메커니즘을 사용한다. Self-attention은 Query, Key, Value를 통해서 각 단어가 다른 단어와 가지는 상관관계를 파악하고, 각 단어가 다른 단어의 정보에 대한 얼마나 필요한지 계산한다. 이러한 구조를 통해 시퀸스 내의 각 단어는 시퀸스의 길이와 상관없이 시퀸스의 어떤 부분에서든 직접 유용한 정보를 가져올 수 있게 되며, 이를 통해 장기 의존성 문제를 해결한다.
- 병렬 처리
Transformer 구조는 RNN과 달리 앞서 설명한 Self-attention 메커니즘을 사용해 입력 시퀸스 내의 모든 단어의 관계를 순차적으로 파악하지 않고 한 번에 파악할 수 있다.
3. 전체 모델 구조
Transformer의 모델 구조는 다음 그림과 같다. 크게 인코더와 디코더로 나눌 수 있다. 인코더와 디코더는 층으로 쌓을 수 있다. 인코더와 디코더의 구조는 비슷하지만 디코더는 인코더의 출력을 추가적으로 활용한다는 점에서 차이가 있다. 디코더의 출력은 행렬 연산을 통해 vocabulary size의 벡터로 변환되며, Softmax 함수를 적용해 각 단어에 대한 확률값으로 최종 반환된다.
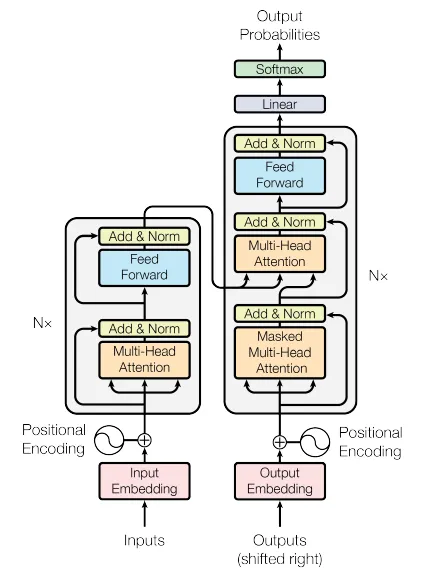
이제 본격적으로 각 구조에 대해서 자세히 알아보도록 하자.
4. Encoder
4.1 Input Embedding과 Positional Encoding
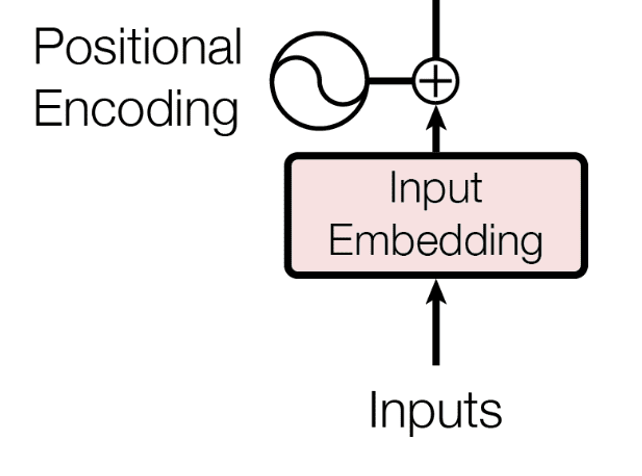
Transformer의 Input Embedding은 토큰(token)의 인덱스로 표현된 단어를 벡터로 변환하기 위한 레이어이다. Input Embedding은 모델의 학습과정에서 지속적으로 업데이트 되며, 각 단어의 의미를 잘 반영하도록 학습된다. 사실상 각 단어와 각 단어에 해당하는 벡터를 서로 연결시켜 놓은 look-up table과 같다.
Positional Encoding은 단어의 입력 순서에 대한 정보를 보존하기 위한 조치이다. 대부분의 자연어 처리 과정에서 문장 내의 단어의 순서에 대한 정보는 매우 중요한 정보다. 따라서 순서에 대한 정보를 제공할 수 있다면 언어 모델이 문장을 보다 쉽게 이해하고 처리할 수 있을 것이다.
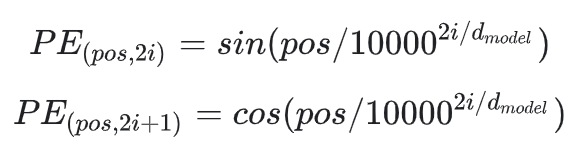
Transformer는 단어의 위치 정보를 보존하기 위해 사인 함수와 코사인 함수를 사용한다. 수식에서 는 단어의 위치를 의미하며 는 임베딩 벡터 내의 차원의 인덱스를 의미한다. 마지막으로 은 임베딩 벡터의 차원수를 의미한다. 이를 pytorch로 구현하면 다음과 같다.
class PositionalEncoding(nn.Module):
def __init__(self, seq_len, emb_size) -> None:
super().__init__()
# p: [seq_len, 1]
p = torch.arange(0, seq_len, dtype=torch.float32).unsqueeze(1)
# i: [1, emb_size/2]
i = torch.arange(0, emb_size, 2, dtype=torch.float32).unsqueeze(0)
# divisor: [seq_len, emb_size/2] by broadcasting
divisor = p / 10000 ** (i / emb_size)
# positional encoding: [seq_len, emb_size]
pe = torch.zeros(seq_len, emb_size)
# sin for even, cos for odd
pe[:, 0::2] = torch.sin(divisor)
pe[:, 1::2] = torch.cos(divisor)
pe = pe.unsqueeze(0)
# state_dict에 pe를 저장하지만 훈련시키지는 않기 위해 buffer에 등록
self.register_buffer('pe', pe)
def forward(self, x):
# x는 input embedding
return x + self.pe
Positional Encoding을 시각화하면 다음 그림과 같다.
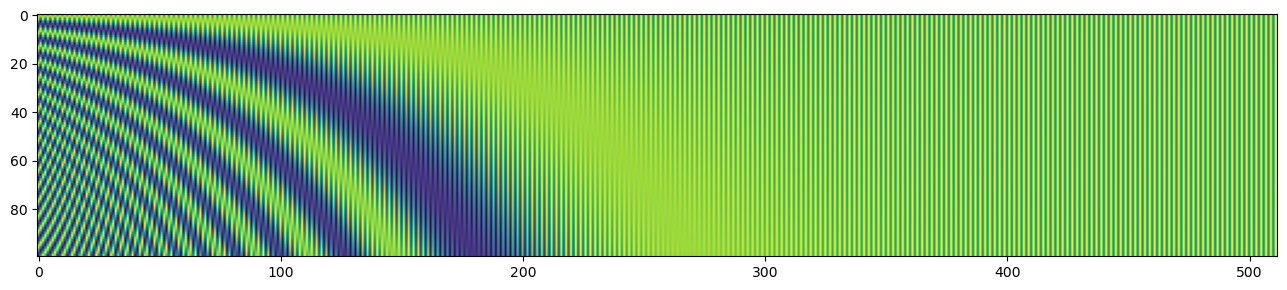
최종적으로 Input Embedding과 Positional Embedding이 서로 더해져서 Encoder에 들어갈 Input이 된다.
4.2 Multi-head Attention
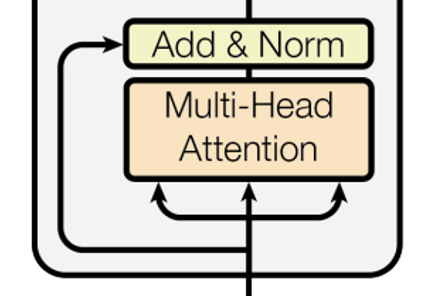
multi-head attention은 시퀸스 내에 존재하는 각 단어와 다른 단어 간의 연관성에 대해 구하는 과정이다. 연관성을 구하기 위해 Query, Key, Value라는 개념을 사용하는데. encoder에서의 multi-head attention은 self attention이기 때문에 Query, Key, Value를 생성하기 위해 동일한 문장의 시퀸스가 사용된다. 즉, 문장의 시퀸스 내에 있는 단어들 간의 상호작용을 파악하기 위해 self attention이 적용되는 것이다.
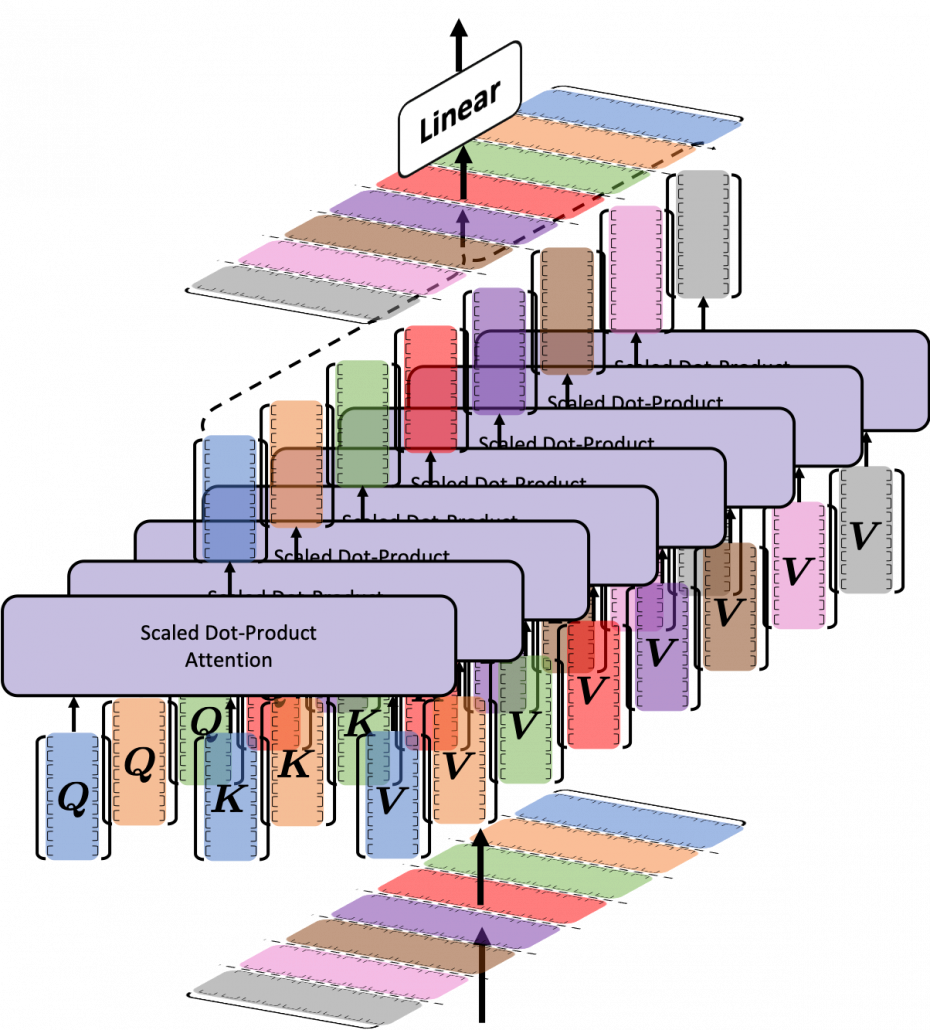
이름에 multi-head가 붙는 이유는 어텐션 매커니즘을 각각의 독립적인 head에서 여러 번 수행하기 때문이다. 논문에서는 각 head에서 독립적으로 어텐션 연산을 하면서 각 head가 서로 다른 부분에 집중해 다양한 정보를 동시에 잡아내는 데 도움이 된다고 주당한다.
multi-head attention을 구하는 과정은 다음과 같다.
- Linear Transformation
입력으로 들어온 인풋 시퀸스에 대해 세 개의 다른 선형 변환을 적용해 Quey, Key, Value 텐서를 생성한다. - Split Head
변환된 Query, Key, Value 텐서가 다수의 독립적인 head를 가질 수 있도록 텐서를 변환한다. 쉽게 말해서 (batch_size, sequence_length, embedding_size)의 텐서가 (batch_size, num_heads, sequence_length, embedding_size/num_head)의 형태로 변환된다. - Scale-Dot Product Attention
Query 텐서와 Key 텐서를 내적해(dot product) 각 head에서 Query와 Key 간의 유사도 점수(score)를 구한다. 그리고 유사도 점수를 임베딩 차원의 제곱근만큼 나눠준다. 이는 softmax 함수 출력값을 안정적으로 만들기 위한 조치이다. 내적 연산을 할 때 임베딩 차원이 커질 수록 결과값도 비례해서 커지기 때문이다. 이후 softmax 함수를 적용해 attention weight로 변환한다. 이후 attention weight와 Value를 곱한다. 이 과정을 통해 모델이 Query와 가장 유사한 Key들에 연결된 정보(Value)에 더 많이 초점을 맞출 수 있다고 한다. - Merge and Linear Transformation
나눠진 head를 통합해 하나로 만들고 새로운 선형 변환을 적용한다.
Multi-head Attention을 Pytorch로 구현하면 다음과 같다.
class MultiHeadAttention(nn.Module):
def __init__(self, emb_size: int = 512, num_heads: int = 8) -> None:
super().__init__()
assert emb_size % num_heads == 0, "emb_size must be a multiple of num_heads"
self.emb_size = emb_size
self.num_heads = num_heads
self.head_size = emb_size // self.num_heads
# query, key, value 그리고 output을 위한 선형변환
self.w_q = nn.Linear(emb_size, emb_size)
self.w_k = nn.Linear(emb_size, emb_size)
self.w_v = nn.Linear(emb_size, emb_size)
self.w_o = nn.Linear(emb_size, emb_size)
def forward(self, q, k, v, mask=None):
# query, key, value: [batch_size, seq_len, emb_size]
bs, seq_len, emb_size = q.shape
# query, key, value 선형변환
q = self.w_q(q)
k = self.w_k(k)
v = self.w_v(v)
# 변환된 query, key, value를 여러 개의 독립적인 head로 나누기
# query, key, value: [batch_size, num_heads, seq_len, head_size]
q = q.view(bs, seq_len, self.num_heads, self.head_size).transpose(1, 2)
k = k.view(bs, seq_len, self.num_heads, self.head_size).transpose(1, 2)
v = v.view(bs, seq_len, self.num_heads, self.head_size).transpose(1, 2)
# scaled dot-product attention 적용
# scores: [batch_size, num_heads, seq_len, seq_len]
scores = torch.matmul(q, k.transpose(-2, -1)) / (self.head_size ** 0.5)
# 패딩 토큰은 마스킹처리 (패딩 토큰에 대해 어텐션을 구하면 안되니까)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# attention: [batch_size, num_heads, seq_len, seq_len]
attention = F.softmax(scores, dim=-1)
# out: [batch_size, num_heads, seq_len, head_size]
out = torch.matmul(attention, v)
# head 합치기
# out: [batch_size, seq_len, emb_size]
out = out.transpose(1, 2).contiguous().view(bs, seq_len, emb_size)
# 최종출력 선형변환
out = self.w_o(out)
return out4.3 Feed Forward Network
feed forward network는 단순히 선형변환과 활성화 함수의 조합이다.
pytorch 구현은 다음과 같다.
class FeedFowardNetwork(nn.Module):
def __init__(self, emb_size: int = 512, ff_size: int = 2048) -> None:
super().__init__()
self.linear1 = nn.Linear(emb_size, ff_size)
self.linear2 = nn.Linear(ff_size, emb_size)
def forward(self, x):
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
return x4.4 Encoder Layer
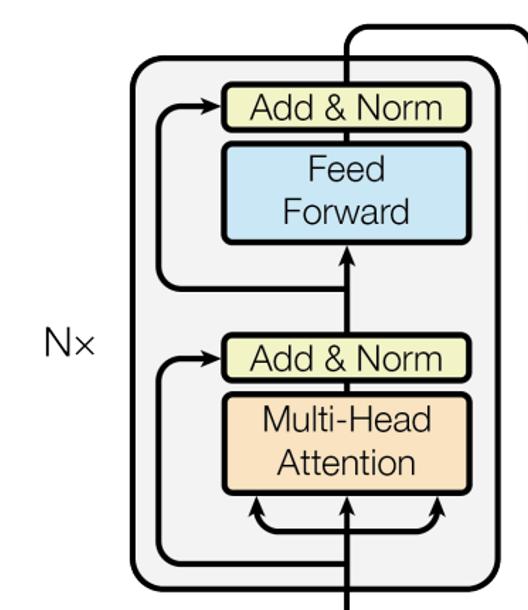
multi-head attention, feed forward network, layer normalization, skip connection을 활용하면 Encoder Layer를 구현할 수 있다.
Layer Normalization은 개별 데이터 포인트 내에서 feature를 정규화한다. 즉, 각 레이어의 출력을 독립적으로 정규화하므로, Batch Normalization과 같이 다른 데이터 포인트에 대한 통계적 특성의 영향을 받지 않는다. 이는 모델이 더욱 안정적인 학습 동작을 보이도록 도와주며, 특히 언어 모델과 같이 모델의 입력 시퀀스 길이가 다양한 경우에 유용하다고 한다.
Skip Connection은 네트워크의 한 층의 출력을 그 다음 층의 출력에 직접 더하는 것이다. 이렇게 하면 네트워크는 일종의 '짧은 경로'를 통해 그래디언트를 전파할 수 있게 된다. 이 '짧은 경로'는 그래디언트가 더 깊은 층을 통해 전파되는 동안 손실되거나 왜곡되는 것을 방지하며, 학습 속도를 향상시키고 모델의 성능을 향상시키는 데 도움이 된다고 한다.
encoder layer의 pytorch 구현은 다음과 같다.
class EncoderLayer(nn.Module):
def __init__(self, emb_size: int = 512, num_heads: int = 8, ff_size: int = 2048, dropout: float = 0.1) -> None:
super().__init__()
self.attention = MultiHeadAttention(emb_size, num_heads)
self.norm1 = nn.LayerNorm(emb_size)
self.dropout1 = nn.Dropout(dropout)
self.ff = FeedFowardNetwork(emb_size, ff_size)
self.norm2 = nn.LayerNorm(emb_size)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x, mask=None):
# x: [batch_size, seq_len, emb_size]
# self-attention 적용
# out: [batch_size, seq_len, emb_size]
out = self.attention(x, x, x, mask)
# skip connection 및 layer normalization
out = self.norm1(x + self.dropout1(out))
# feed forward
# out: [batch_size, seq_len, emb_size]
out = self.ff(out)
# skip connection 및 layer normalization
out = self.norm2(out + self.dropout2(out))
return out4.5 Encoder
encoder layer를 층으로 쌓고 input embedding과 positional encoding을 합쳐주면 Encoder가 완성된다.
encoder의 pytorch 구현은 다음과 같다.
class Encoder(nn.Module):
def __init__(self, vocab_size, seq_len, num_encs, emb_size, num_heads, ff_size, dropout) -> None:
super().__init__()
# input embedding
self.input_embedding = nn.Embedding(vocab_size, emb_size)
# positional encoding
self.pos_encoding = PositionalEncoding(seq_len, emb_size)
# encoder 쌓기
self.enc_layers = nn.ModuleList([EncoderLayer(emb_size, num_heads, ff_size, dropout) for _ in range(num_encs)])
def forward(self, x, mask=None):
# x는 원-핫 벡터로 표현된 단어 시퀸스 데이터
# x: [batch_size, seq_len, vocab_size] -> [batch_size, seq_len, emb_size]
x = self.input_embedding(x)
# positional encoding 적용
x = self.pos_encoding(x)
# encoding 과정
for enc_layer in self.enc_layers:
x = enc_layer(x, mask)
# x: [batch_size, seq_len, emb_size]
return x
5. Decoder
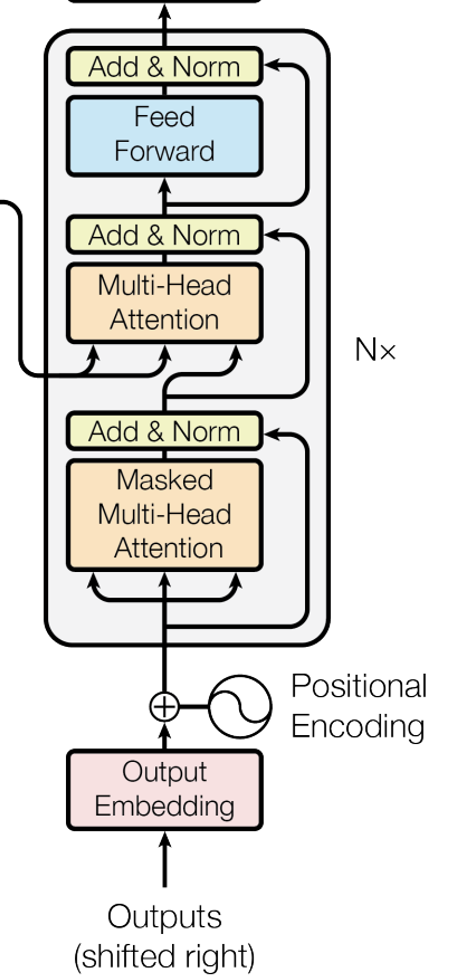
decoder는 encoder의 출력을 해석해 다음 시퀸스를 생성하는 역할을 한다. decoder의 구조는 encoder의 구조와 비슷하다. decoder가 encoder와 다른 점은 크게 두가지이다.
- masked multi-head attention
입력에 대해 self-attention을 구하는 것은 동일하지만, look-ahead 마스크를 self-attention에 적용해 미래 시점의 토큰에 대해 참조할 수 없도록 만든다. 다른 말로 t 시간 단계에 대한 출력은 그 이전 단계에 대한 출력만 참조해야 한다는 의미이다.이는 decoder가 현재 위치보다 미래에 있는 토큰을 보지못하게 함으로써, 학습 단계에서 시퀀스 내의 토큰 간 독립성을 유지하는데 도움을 준다고 한다. 이는 decoder가 각 시간 단계에서 올바른 정보만을 참조하도록 보장하며, 실제 예측 시나리오에서 가능한 행동을 모방한 것이다.

- encoder-decoder attention
encoder-decoder attention의 목적은 decoder가 encoder의 출력에 대한 어텐션을 적용하여 현재 디코딩 위치에 필요한 정보를 encoderd의 출력으로부터 얻는 것이다. 이를 위해 Query는 decoder layer의 출력을 사용하고, Key와 Value는 encoder의 출력을 사용한다.
decoder layer의 구현은 다음과 같다.
class DecoderLayer(nn.Module):
def __init__(self, emb_size: int = 512, num_heads: int = 8, ff_size: int = 2048, dropout: float = 0.1) -> None:
super().__init__()
self.self_attention = MultiHeadAttention(emb_size, num_heads)
self.norm1 = nn.LayerNorm(emb_size)
self.cross_attention = MultiHeadAttention(emb_size, num_heads)
self.norm2 = nn.LayerNorm(emb_size)
self.ff = FeedFowardNetwork(emb_size, ff_size)
self.norm3 = nn.LayerNorm(emb_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_out, enc_mask=None, dec_mask=None) -> None:
# decoder의 self-attention (look-ahead 마스크 적용)
self_attn = self.self_attention(x, x, x, dec_mask)
x = self.norm1(x + self.dropout(self_attn))
# encoder-decoder attention
cross_attn = self.cross_attention(x, enc_out, enc_out, enc_mask)
x = self.norm2(x + self.dropout(cross_attn))
ffo = self.ff(x)
x = self.norm3(x + self.dropout(ffo))
return xdecoder의 구현은 다음과 같다.
class Decoder(nn.Module):
def __init__(self, vocab_size, seq_len, num_decs, emb_size, num_heads, ff_size, dropout):
super().__init__()
self.out_embedding = nn.Embedding(vocab_size, emb_size)
self.pos_encoding = PositionalEncoding(seq_len, emb_size)
self.dropout = nn.Dropout(dropout)
self.dec_layers = nn.ModuleList([DecoderLayer(emb_size, num_heads, ff_size, dropout) for _ in range(num_decs)])
def forward(self, x, enc_out, enc_mask=None, dec_mask=None):
x = self.out_embedding(x)
x = self.pos_encoding(x)
x = self.dropout(x)
for dec in self.dec_layers:
x = dec(x, enc_out, enc_mask, dec_mask)
return x6. Mask
Transformer에 사용되는 마스크의 종류는 총 2개이다. 하나는 패딩 마스크이며 다른 하나는 앞서 언급한 look-ahead 마스크다.
패딩 마스크는 패딩된 시퀸스에 대해 어텐션 스코어를 계산하는 것을 방지하기 위한 장치이다. 패딩은 단순히 시퀸스의 길이를 맞추기 위한 장치이므로 어텐션 스코어를 계산하지 않는게 맞다.
decoder는 출력 시퀀스를 생성하는데 있어서 자기 회귀적(auto-regressive) 방식을 사용한다. 즉, 각 시점에서 생성된 토큰은 이전 시점에서 생성된 모든 토큰에 의존한다. 따라서 현재 시점보다 나중에 등장하는 토큰을 참조하는 것은 다음 토큰을 예측하는 데에 있어 반칙과 같다. 따라서 look-ahead 마스크를 적용해 현재 시점보다 나중에 등장하는 토큰을 참조하는 것을 방지한다.
7. Transformer
앞서 언급한 모든 요소들을 조합해 만든 Transformer의 코드는 다음과 같다.
class Transformer(nn.Module):
def __init__(self,
src_vocab_size: int,
trg_vocab_size: int,
pad_token_idx: int,
seq_len: int,
num_encs: int,
num_decs: int,
emb_size: int,
num_heads: int,
ff_size: int,
dropout: float):
super().__init__()
self.encoder = Encoder(src_vocab_size, seq_len, num_encs, emb_size, num_heads, ff_size, dropout)
self.decoder = Decoder(trg_vocab_size, seq_len, num_decs, emb_size, num_heads, ff_size, dropout)
self.out_linear = nn.Linear(emb_size, trg_vocab_size)
self.pad_token_idx = pad_token_idx
def create_masks(self, src, trg):
batch_size, seq_len = src.shape
# [batch_size, 1, 1, seq_len]
enc_mask = (src != self.pad_token_idx).unsqueeze(1).unsqueeze(2)
# [batch_size, 1, seq_len, 1]
dec_pad_mask = (trg != self.pad_token_idx).unsqueeze(1).unsqueeze(3)
# [seq_len, seq_len]
look_ahead_mask = torch.tril(torch.ones(seq_len, seq_len)).bool()
# [batch_size, 1, seq_len, seq_len]
dec_mask = dec_pad_mask & look_ahead_mask
return enc_mask, dec_mask
def forward(self, enc_input, dec_input):
enc_mask, dec_mask = self.create_masks(enc_input, dec_input)
enc_out = self.encoder(enc_input, enc_mask)
dec_out = self.decoder(dec_input, enc_out, enc_mask, dec_mask)
out = self.out_linear(dec_out)
return out