2025 Samsung Collegiate Programming Challenge : AI 챌린지(2025.06.19 ~ 2025.07.28)
public score : 0.76601(47th)
private score : 0.7708(15th)
대회 개요
[주제]
사용자의 일상 사진을 이해하는 멀티모달 AI 모델 개발
[문제 설명]
참가자는 어떤 사용자의 스마트폰 갤러리에 저장된 다양한 일상 사진들에 대해 선다형 질문이 주어지면 정답을 선택하는 AI 모델을 개발
[주최 / 주관]
주최: 삼성전자
주관: 삼성리서치
운영: 데이콘
[진행 기간]
2025.06.19 ~ 2025.07.28
[주요 제약 사항]
1)사전 학습 모델 사용 가능 범위
2024년 전(~2023.12.31)에 공식적으로 가중치가 공개되었으며, 최소한 비상업적 이용이 허용된 오픈소스 라이선스(MIT, Apache 2.0 등)로 배포된 사전 학습 모델만 사용할 수 있습니다. 해당 조건을 충족하지 않는 모델은 사용이 불가능합니다.
2) 외부 데이터 사용 가능
2025년 6월 11일 전(~2025.06.10)에 공식적으로 공개되었으며, 최소한 비상업적 이용이 허용된 라이선스(CC BY-NC, CC0 등)로 배포된 외부 데이터만 사용할 수 있습니다. 해당 조건을 충족하지 않는 외부 데이터는 사용이 불가능합니다.
3) 추론 모델 가중치의 총합은 '3B' 미만
리더보드에 제출하는 예측 결과는 아래 조건을 반드시 충족해야 합니다.
- 추론에 사용되는 모든 모델의 총 파라미터 수는 반드시 3B(30억 개) 미만이어야 합니다.
- 이 기준은 추론 코드에서 실제로 로드(Load)되는 모든 모델의 가중치(parameter)의 수 합계를 기준으로 판단합니다.
사용한 데이터는 삼성 AI 리서치에서 제공하였으며, 이미지와 질문을 입력으로 받아 주어진 선택지(A~D) 중 정답을 고르는 멀티모달 객관식 질문응답(Multiple-choice Visual Question Answering)이 주요 과제였습니다.
데이터 개요
- Data Type : 이미지와 텍스트(Question + Options)로 - 이루어진 멀티모달 데이터
- 데이터 분할 :
- Train Data : 60개
- Test Data : 852개
- 문제 유형 : 멀티모달 QA
- 평가 지표 : 가중 정확도 (Weighted Accuracy)
방법론
Initial Approach
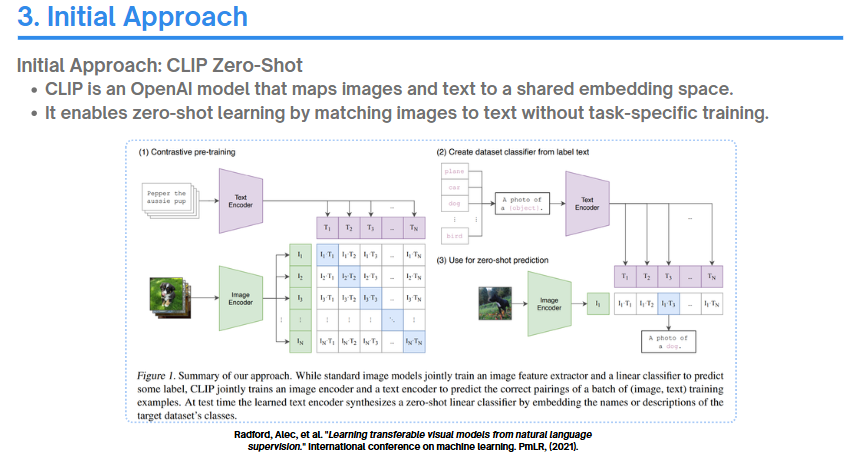
가장 먼저 시도했던건 CLIP 모델을 활용한 Zero-shot 추론이였습니다. LLM이나 VLM을 사용한 방법을 생각을 안했던 것은 아니지만, 두 가지 이유 때문에 초기에는 사용을 하지 않았습니다.
- 2024년 이전 모델, 3B 이하 모델만 사용 가능하기 때문에, 고성능의 멀티모달 모델은 활용하기 어려울 가능성이 높다.
- 출력이 A, B, C, D 중 하나여야만 하기에, Language Model이 부정확한 답변을 생성한다면 점수가 크게 낮아질 것이다. 즉, 답안이 항상 결정론적이여야 한다.
또한, 파인튜닝을 시도해보았지만 60개라는 극단적으로 적은 수의 train data로 인해 모델의 기본 성능이 크게 떨어졌습니다. 따라서 이후에는 시도하지 않았습니다.
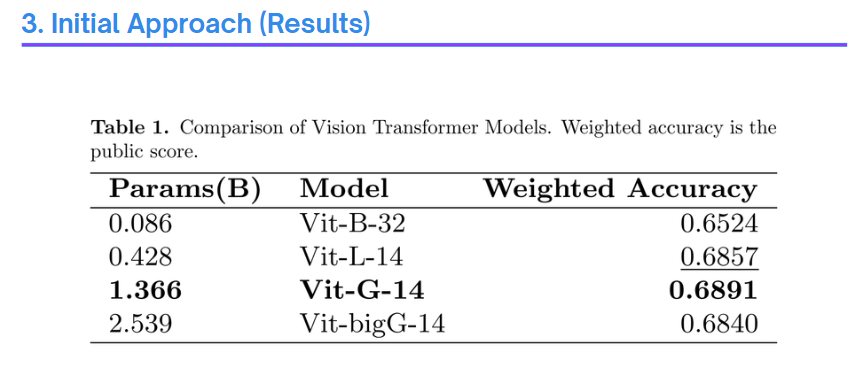
따라서 대회 초기에는 CLIP을 사용해서 이미지와 텍스트(Question + 선지) 간의 유사도를 비교하는 방식으로는 진행했습니다. 모델을 여러 가지 사용해봤는데, 단일 모델만 사용해봤을 때는 0.689 수준의 성능이 나왔습니다.
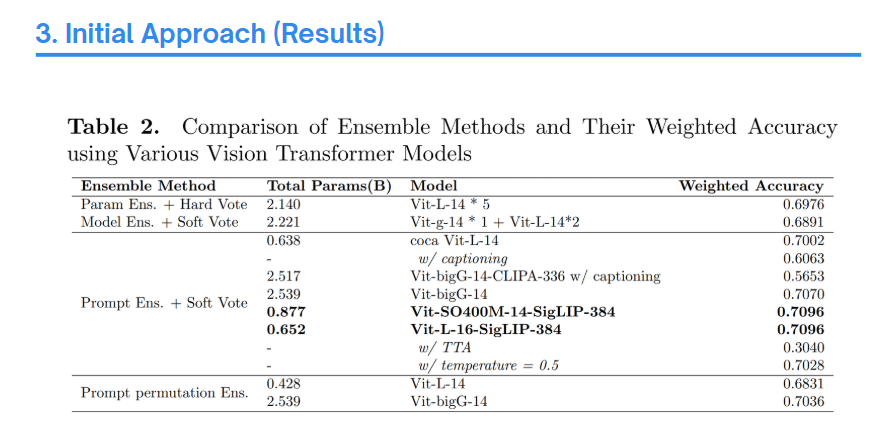
이후, 여러 앙상블 기법을 활용하여 public score를 기준으로 약 0.709 수준까지는 성능을 올릴 수 있었습니다. 하지만 여기서 한계에 도달했고 더이상 유의미한 결과를 얻지 못하였습니다.
Intermidiate Approach

돌파구를 찾았던 것은 Kosmos-2 모델을 사용한 결과를 보았을 때입니다. Kosmos-2는 기본적으로 이미지와 text를 통해 Image Gounding을 하는 모델입니다.
Kosmos-2 모델은 이미지와 Question만 넣어줬을 때(선지는 미포함), 이미지로부터 Question과 관련된 Description을 세세하게 작성해줍니다. 이 결과를 보고 '사람에게 이정도 설명과 선지만 줘도 문제를 맞추겠는데?' 라는 생각이 들기 시작했습니다.
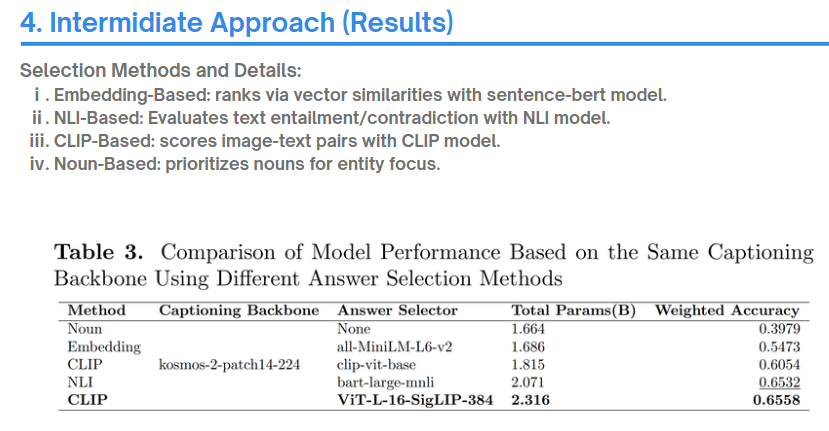
이에 따라 몇 가지 방법을 시도해보았는데, 모두 선지 A, B, C, D 중에 하나로 무조건 응답이 나올 수 있는 방법만 시도를 우선 해봤습니다. 최고 성능이 0.6558로 매우 낮지만 포기하지 않고 계속 방법을 탐색해보았습니다.
Final Approach
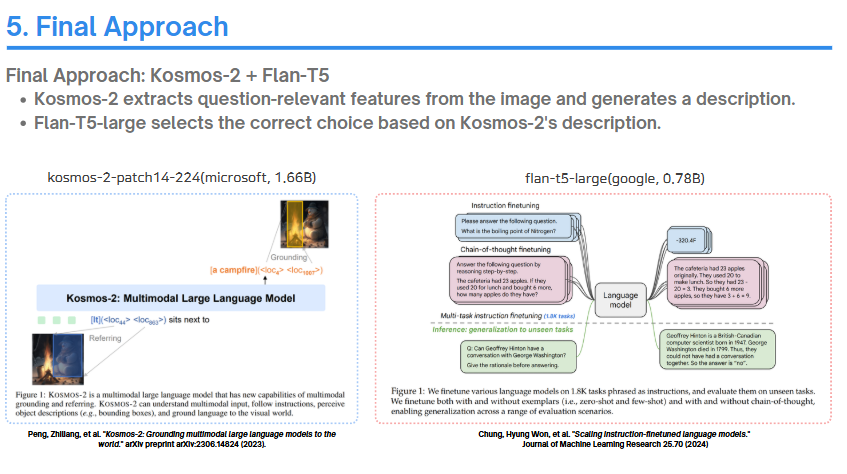
최종적으로는 3B 파라미터 내에서 사용가능한 언어 모델 중 T5라는 모델을 선택했습니다.
T5가 Instruction tuning이 잘 되어있는 모델이기도 하고, Kosmos-2라는 1.6B 수준의 모델을 사용하였을 때 남은 파라미터로 선택 가능한 모델이 거의 없어 선택하게 되었습니다.
Kosmos-2가 이미지와 텍스트(Question)만을 보고 image description을 작성하면, T5가 질문과 선지, Kosmos-2가 생성한 Image description만을 보고(즉, 이미지는 보지 않은 상태로) 답안을 작성하는 방식입니다.

결과적으로 public score 기준 0.7660, private score 기준 0.7708, 최종 등수 15등이라는 결과를 얻었습니다.
본선 진출

코드 검증 이후 본선에 진출하였고, 해당 내용들을 삼성 AI 리서치센터에서 발표 하였으나 아쉽게도 수상을 하지는 못하였습니다.
회고
이번 대회에서 private 기준 15등으로, 수상에 가까웠던 만큼 아쉬움이 많이 남았습니다.
사실 상위권 참가자분들은 모두 발표 준비를 철저히 하셨을 것이라 생각해, 순위가 private score에 따라 결정될 것이라 예상했는데 결과는 전혀 달라 놀라기도 했습니다. 실제로 수상 순서는 private score 순위와는 크게 달랐습니다.
발표 자체는 열심히 준비했기에 후회는 없지만, 아마도 질의응답 과정에서 다른 분들이 더 명확하고 준비된 답변을 하셨던 것 같습니다. 또한 저는 Zero-shot 방식으로만 접근했는데, train 데이터를 적극적으로 활용하고, 여러 데이터를 활용하여 모델을 학습시킨 분들이 분들이 더 좋은 평가를 받으셨을 수도 있겠습니다.
다음 기회가 온다면 발표 준비뿐만 아니라 예상 질의응답까지 꼼꼼히 준비하고, 여러 번 연습하여 더 완성도 있게 도전해보고 싶습니다.
