Eo, M., Lee, K., Cho, H.-S., Kim, D., Sim, Y. S., & Lim, W. (2025). Representation Space Augmentation for Effective Self-Supervised Learning on Tabular Data. Proceedings of the AAAI Conference on Artificial Intelligence, 39(11), 11625-11633.
https://doi.org/10.1609/aaai.v39i11.33265
Introduction
테이블 데이터는 그간 딥러닝 분야에서 제한적인 관심만을 받아왔다. 자기 지도 학습(Self-Supervised Learning, SSL)은 분명 유망한 방법론이지만, SSL을 위한 효과적인 데이터 증강(Data Augmentation) 기법은 여전히 부족한 실정이다.
특히, 기존의 데이터 증강 기법은 모두 Input Space에서 작동한다. 그러나, 테이블 데이터의 구조적 모호성은 이러한 증강 기법을 비효율적이거나, 성능에 악영향을 미치도록 만든다.
따라서 연구자들은 Input Space가 아닌 Representation Space에서 데이터를 증강시키는 효과적인 테이블 데이터 증강 기법 RaTab(Representation space Augmentation for Tabular Data)를 제안한다.
RaTab 기법은 SSL의 성능을 높이는 데이터 증강 기법으로, 데이터의 핵심 패턴을 보존하기 위해 Truncated SVD를 활용하였으며, 다양한 View에서 데이터를 증강하기 위해 Dropout을 활용한다.
Approach
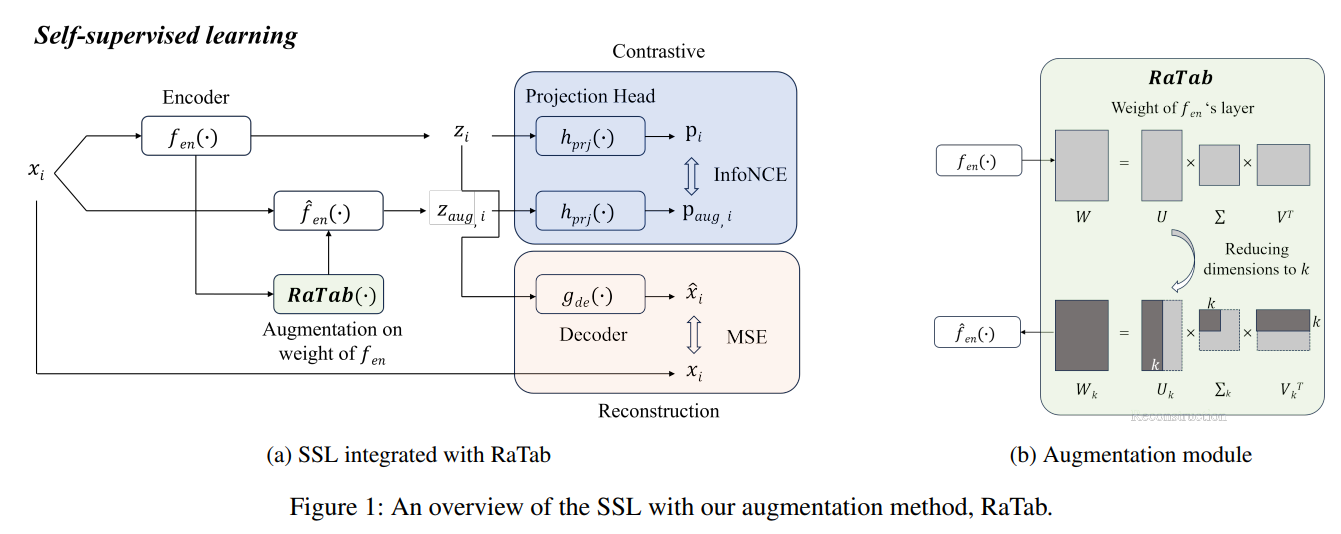
RaTab의 개념 자체는 매우 심플하다. 그림 b를 우선 보면, RaTab은 Encoder의 맨 마지막 레이어를 가져와 새로운 인코더를 만드는 것이 목적임을 알 수 있다. 이 때 RaTab은 SVD를 변형한 기법인 Truncated SVD를 사용한다.
그림 a를 보면 RaTab의 적용 방법을 알 수 있다. 먼저, 입력 데이터 x_i가 인코더 f 을 통해 표현(Representation) z_i로 매핑된다. 그리고, RaTab을 적용하여 얻어낸 새로운 인코더 hat f를 통해 증강된 새로운 양성 뷰(positive view) z_aug,i를 얻는다.
이렇게 얻은 두 표현 z_i와 z_aug,i를 통해 동시에 두 개의 loss(contrastive loss, reconstruction loss)를 계산할 수 있으며, 이를 통해 인코더, 프로젝션 헤드, 디코더의 파라미터를 모두 업데이트한다.
Truncated SVD
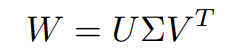
먼저, SVD(Full SVD)란 행렬을 저차원으로 분해하는 기법으로, 인코더의 마지막 가중치 행렬 W를 저차원 행렬 U와 Sigma, V^T의 곱으로 분해한다.
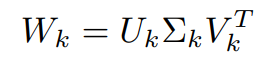
이 때, Truncated SVD는 높은 랭크(rank)에 존재하는 가중치의 주성분을 보존하기 위해 각 행렬에서 k개의 특이값(large singular value)만을 선택하여 곱한 후, 새로운 가중치 Wk를 생성한다.
이러한 연구자들의 접근법은 비용-효율적으로 기존 인코더의 능력을 크게 헤치지 않는 선에서 새로운 View를 통해 데이터를 증강하는 논리의 기반이 된다.
Loss Functions
RaTab의 손실 함수는 크게 두 가지로 정의된다. 하나는원본 표현이 얼마나 입력 표현을 잘 나타내는지(즉, Decodedr를 통해 얼마나 재현가능한지)를 나타내는 Reconstruction Loss, 다른 하나는 두 표현(Z_i, Z_aug,i)의 유사성에 대해 판단하는 Contrastive Loss이다.
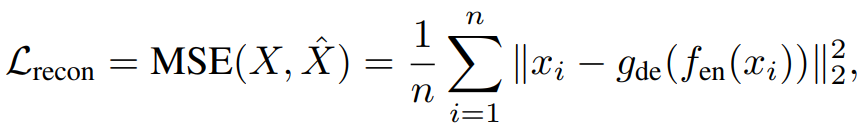
먼저, Reconstruction Loss를 살펴보자. 입력 x_i를 인코더에 넣은 값 f_en(x_i)를 디코더 g_de에 넣은 값이 원본 입력 값 x_i와 얼마나 유사한가를 MSE Loss를 통해 구한 값이다. 즉, Reconstruction Loss는 원본 입력을 보존할 수 있는 표현을 학습하도록 하는 역할을 한다.
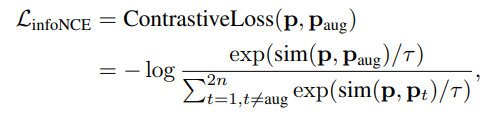
다음으로 Contrastive Loss는 원본 표현 Z_i와 증강된 표현 Z_aug,i를 각각 프로젝션 헤드 h_prj에 통과시킨다. 이렇게 얻은 두 표현 P_i와 P_aug,i는 Positive Pair로 묶어 유사도를 높이고, 나머지 입력들에 대해서는 Negative Pair로 묶어 유사도를 낮춘다. 이를 통해 표현 공간(Representation Space)에서 샘플 간의 구분성을 높이고, Positive Pair의 일관성을 유지할 수 있다.
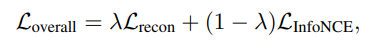
끝으로, 두 Loss를 Lambda를 이용해 적절하게 조합한다. 연구자들은 두 Loss에 각각 동일한 가중치인 0.5를 부여하였다.

RaTab의 주요 단계를 정리하자면,
- Encoder를 통해 input X로부터 표현 z를 얻는다.
- Encoder의 마지막 레이어로부터 가중치 W를 얻는다.
2-1. 2에서 얻은 가중치 W를 Full-SVD를 이용해 U, S, V로 분해한다.
2-2. 행렬 U, S, V에서 k rank에 해당하는 값만 추출해 곱하여 새로운 가중치 행렬 W_k를 얻는다.
2-3. 기존 Encoder의 마지막 가중치를 W_k로 업데이트하고, 증강된 표현 z_aug를 얻는다. - 표현 z를 Decoder에 넣어 복원한 값 X_hat과 기존 Input 값인 X를 통해 MSE Loss를 계산한다.
- 두 표현(Z_i, Z_aug)를 projection head에 넣어 동일한 차원으로 매핑한 후, Contrastive Loss를 구한다.
- 두 Loss를 이용해 Total Loss를 구하고, 이를 통해 Encoder, Decoder, Projection Head를 업데이트한다.
Experiment
실험은 13개의 OpenML Dataset에서 수행되었으며, 이진 분류(Binary Classification), 다중 분류(Multiclass Classification), 회귀(Regression) 문제를 모두 포함한다. 평가 지표로써 분류(Classification) 문제에는 Accuracy를, 회귀(Regression) 문제에는 MSE를 사용하였다.
Encoder는 3-Layer MLP, FT-Transformer, T2G-Former를 실험에 사용하였고, Decoder 또한 Encoder와 동일한 아키텍처를 사용하였다. Projector는 Single-layer Perceptron을 사용하였다.
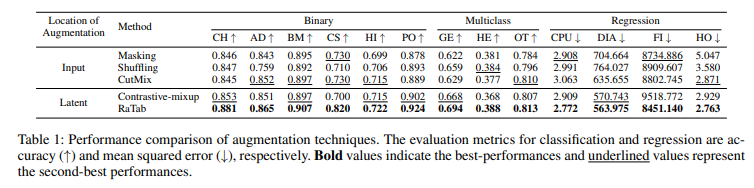
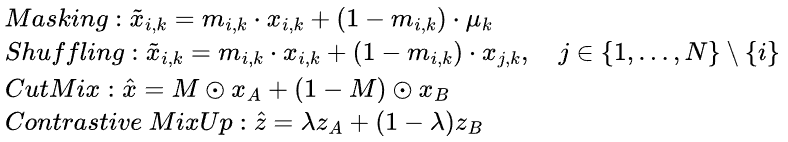
먼저, 기존의 데이터 증강 기법과 RaTab의 성능을 비교분석한 결과이다. Input Space에서 작동하는 데이터 증강 기법은 Masking, Shuffling, CutMix가 있으며 Latent Space(=Representation Space)에서 작동하는 기법은 Contrastive-mixup과 제안 기법인 RaTab이 있다.
RaTab은 다른 데이터 증강 기법들에 비해 모든 Task, 모든 Dataset에서 우수한 성능을 보였다. 또한, 전반적으로 Latent-Space에서 데이터를 증강하는 기법이 Input-Space에서 데이터를 증강하는 것보다 더 우수한 성능을 보였다.
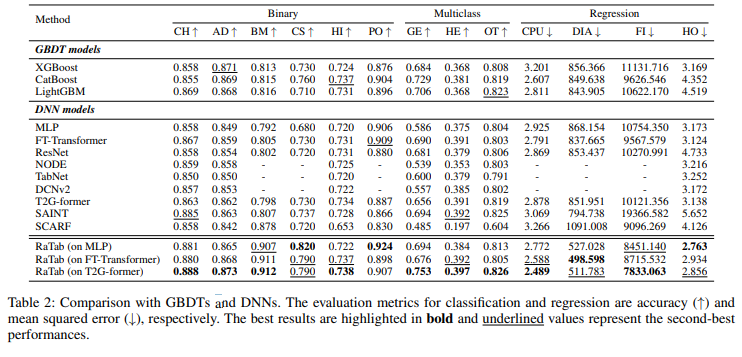
또한, 여러 MLP 모델에 RaTab을 적용하는 것 만으로도 기존의 기법들(GBDT models, DNN models)을 능가하는 성능을 보였다. 이는 모든 Dataset, 모든 Task에서 동일하게 나타난 결과이기에 충분히 놀랄만 하다.
그리고, 단순한 MLP 구조에서도 경쟁력 있는 결과를 보였으며, 특히 T2G-former를 Backbone으로 사용하였을 때 전반적으로 가장 좋은 성능을 보였다.
상세한 결과를 Appendix에 기술하였다는데, 왜 부록 자체가 논문에 없는지 의문이다.
Ablation Study and Analysis
t-SNE visualizations
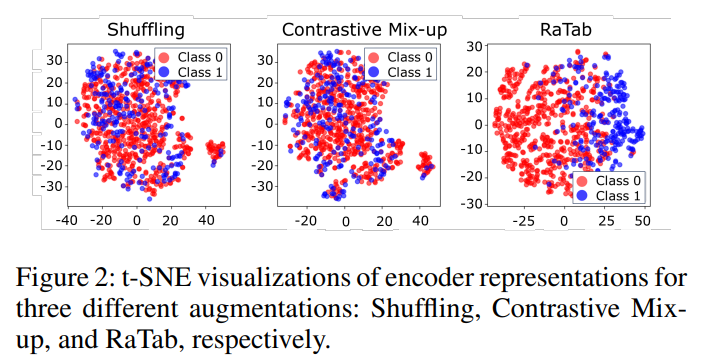
t-SNE로 증강된 데이터들이 얼마나 효과적인지 보여주는 결과이다. 다른 방법(Shuffling, Contrastive Mix-up)에 비해 더 뚜렷한 클래스 분리를 보여주며, 데이터 구조가 효과적으로 보존됨을 알 수 있다.
Alignment-uniformity scores
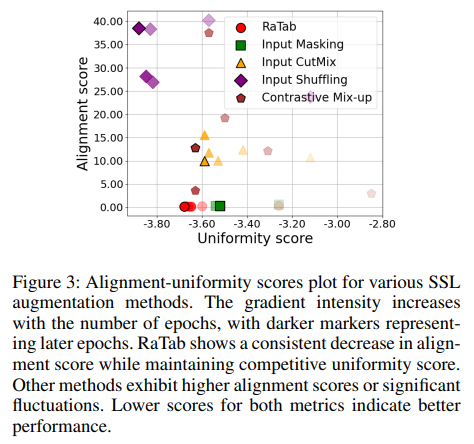
세로 축은 Aligment Score를, 가로 축은 Uniformity Score를 의미하고, 더 짙은 마크(darker makers)는 epoch의 증가를 의미한다.
- Aligment Score란 같은 샘플로부터 나온 양성 쌍(positive pair)가 얼마나 가깝게 모여있는 지를 측정하는 지표이다.
- Uniformity Score는 전체 데이터가 표현 공간(Representation Space)에서 얼마나 균일하게 분포하는지를 측정하는 지표이다.
RaTab은 타 기법에 비해 Epoch이 증가함에 따라 Uniformity Score를 낮추고 Aligment Score를 유지하여, 임베딩 구조를 보존하면서 클래스의 구별성과 다양성을 균형 있게 유지하였다.
Robustness to uninformative features
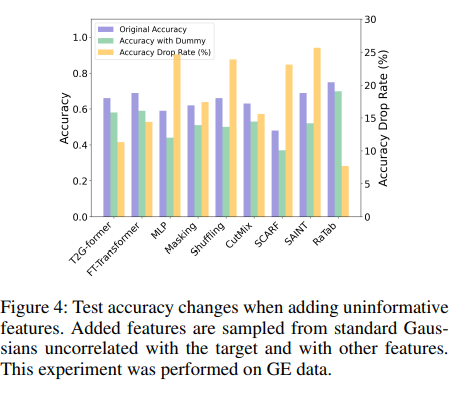
보라색은 기존의 Accuracy를, 초록색은 Dummy feature를 추가하였을 때의 Accuracy를, 노란 색은 두 Accuracy간의 손실을 %로 나타낸 값이다.
RaTab은 정보량이 없는 피처가 추가되었을 때도 정확도 하락이 거의 없어, 불필요한 피처에 대해 강한 견고성을 보여줌을 알 수 있다.
Ablation Study on Loss Functions
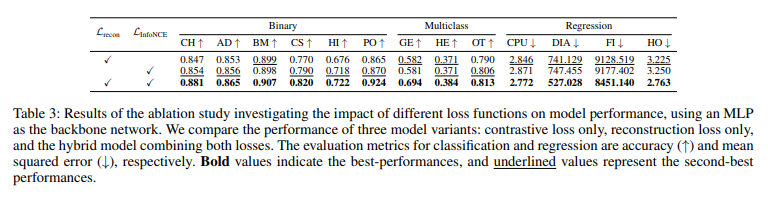
Loss Function을 왜 Contrastive Loss와 Reconstruction Loss를 함께 사용하였는가에 대한 Ablation Study이다.
테이블을 보면 모델 성능을 1) 대조 손실(contrastive loss)만 사용, 2) 재구성 손실(reconstruction loss)만 사용, 3) 두 손실을 결합한 하이브리드 모델로 비교하였다.
결과적으로 하이브리드 모델이 모든 평가에서 가장 우수한 성능을 나타냈다.
Sensitivity Analysis on Lambda(λ)
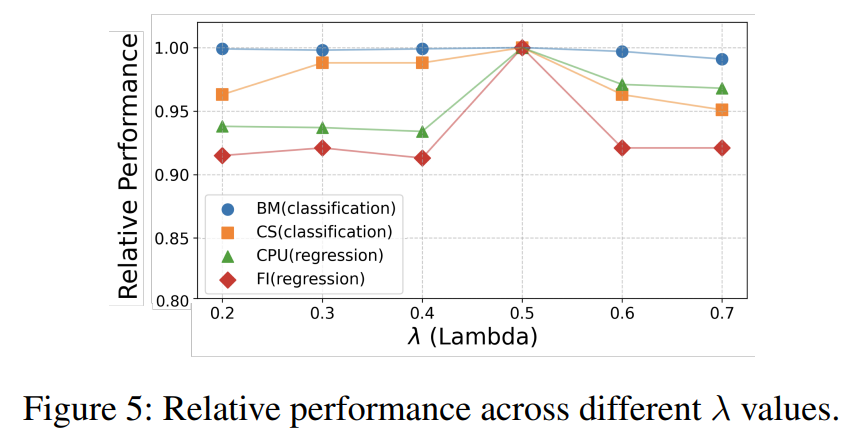
λ 값을 변경했을 때 성능에 미치는 영향은 거의 없었으며, 모델은 λ 조정에 대해 강한 견고성을 보였다.
분류(classification) 모델은 λ가 증가함에 따라 성능이 약간 하락했지만, 회귀(regression) 모델은 λ = 0.5에서 최적의 성능을 달성하였다.
Sensitivity Analysis on P-value(k)
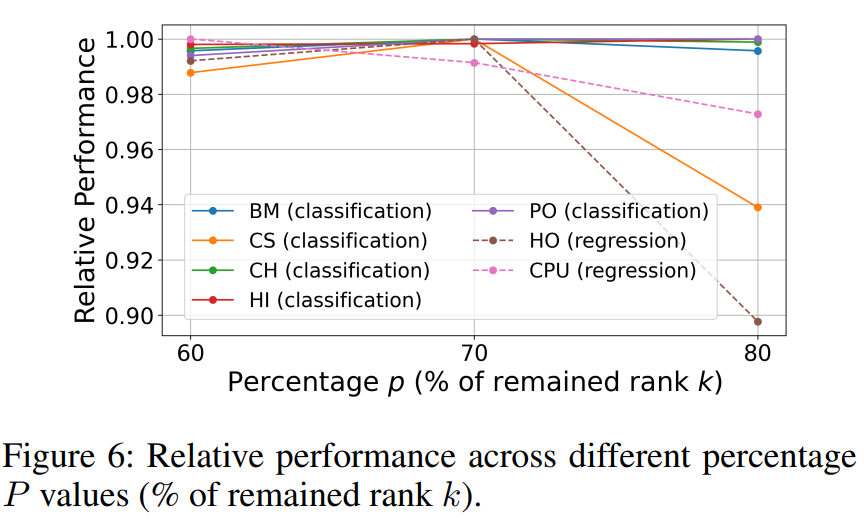
p(k)의 비율이 변해도 성능 변동은 거의 없었으며, 최적 성능은 70%에서 나타났다.
모델은 다양한 p 값에서도 안정적이며 적응력이 뛰어남을 보여주었다.
Ablation Study on Layer Application
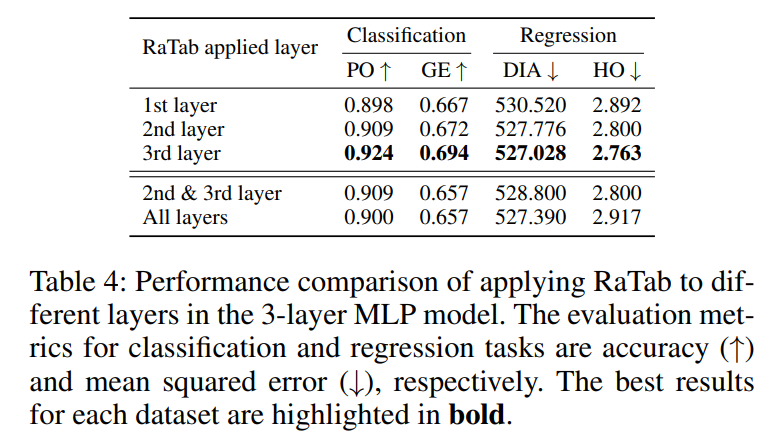
RaTab을 MLP 모델의 세 번째 층에 적용했을 때 모든 데이터셋에서 일관되게 최고의 성능을 나타냈다.
여러 층에 적용했을 때는 더 이상의 성능 향상이 관찰되지 않았는데, 이는 층이 많아질수록 정보 손실이 증가하기 때문으로 보인다.
Addressing Computational Cost in SVD
-
Standard SVD: O(min(mn², nm²))
→ 가중치의 차원이 커질 수록 시간 복잡도가 매우 크게 늘어난다. -
Randomized SVD(Halko, Martinsson, and Tropp 2011): O(mnlog(k) + (m + n)k²)
→ 실험 결과, Randomized SVD는 연산 시간을 크게 줄이면서도 성능을 유지한다.
Conclusion
해당 논문에서 연구자들은 RaTab이라는 새로운 representation-level 데이터 증강 전략을 제안한다.
RaTab은 입력 데이터 자체에 직접 적용하는 대신, 데이터로부터 얻은 표현의 가중치(weight)에 Truncated SVD를 적용한다. 이 접근법은 기저 핵심 구조(core structures)와 복잡한 관계를 효과적으로 포착하여, 테이블 데이터의 이질성으로 인한 문제를 해결한다. 또한, 입력 수준에서 어떤 정보가 필수 구조적 정보인지를 정의하는 어려움도 해결한다
또한, Truncated SVD로 강화된 표현을 대조학습(contrastive learning), 재구성 기법(reconstruction), dropout과 통합함으로써, RaTab은 다양한 데이터셋과 하위 과제(downstream task)에서 기존 테이블 데이터용 알고리즘보다 우수한 성능을 나타낸다.
결과적으로 RaTab은 Table Data에서 딥러닝 모델의 성능을 향상시키는 잠재력을 보여주었으며, 더 견고하고 효과적인 데이터 증강 기법 개발의 가능성을 보여준다.
