Han, Sungwon, et al. "Large Language Models Can Automatically Engineer Features for Few-Shot Tabular Learning."arXiv preprint arXiv:2404.09491 (2024).
https://arxiv.org/abs/2404.09491
Ⅰ. Abstract
LLM은 여러 도전적인 새로운 추론 문제들에 대해 놀라운 능력을 보이며, 이는 실제 응용 가능한 분야에서 중요한 Tabular Data에 대한 학습에 큰 잠재력을 가지고 있습니다.
이 연구에서는 LLM을 feature engineer로써 활용하여 Tabular data를 예측하는데 최적화된 데이터 셋을 생성하는 새로운 in-context learning 프레임워크, FeatLLM을 제안합니다. 피쳐를 생성하여 간단한 머신러닝 모델(ex. LogReg)를 사용해 높은 성능의 few-shot learning을 수행합니다.
기존의 LLM 기반 예측 모델들과는 달리, 추론 시 각 샘플에 대해 LLM에 쿼리를 보낼 필요가 없습니다. 따라서 API 수준의 접근만 필요하며, 프롬프트 크기 제한의 문제 또한 극복하였습니다.
결과적으로 다양한 Tabular data set에서 FeatLLM이 TabLLM, STUNT와 같은 기존 대안들 대비 평균적으로 10% 이상의 성능 향상을 보여주었습니다.
Ⅱ. Introduction
최근 몇 년간 LLM은 특정 작업에 대해 fine-tuning 없이도 작업에 적합한 응답을 생성하는데 있어 놀라운 성능을 보였습니다. 방대한 데이터로 학습된 LLM은 많은 분야에서 전문가 수준의 사전 지식을 보유하고 있습니다. 특히, 작업의 예시를 통해 맥락을 파악하고, 중요한 특성과 예시에 대해 집중할 수 있습니다. 이는 피쳐 엔지니어로서의 LLM의 잠재력을 보여줍니다.
LLM의 사전 지식과 추론 능력은 Tabular data의 학습으로 확장되고 있습니다. 최근 연구들은 자연어로 작업과 특징의 설명을 정의하고, 데이터를 직렬화하여 LLM에 입력하였습니다(이는 in-context learning, parameter-efficient fine-tuning으로 이어지기도 합니다). LLM의 사전 지식 덕분에, 특히 low-shot 환경에서 기존의 Table 학습보다 높은 성능을 내는 성과를 냈습니다.
하지만 이러한 LLM 기반 테이블 학습은 몇 가지 한계가 있습니다. 첫 번째로 end-to-end prediction으로 인해 샘플 당 최소한 한 번의 추론이 필요하기에 계산 비용이 높으며, 두 번째로는 높은 정확도를 위한 fine-tuning이 거의 필수적이고, 마지막으로 피쳐의 개수가 증가하면 프롬프트의 길이가 길어져 모델의 성능이 저하되고 접근이 비현실적으로 변합니다.
따라서 이 연구에서는 LLM을 단순한 end-to-end 방식으로 활용하는 것이 아닌 feature engineering 역할을 부여하여 사전 지식을 더 효율적으로 활용할 방법을 제시합니다.
구체적으로, featLLM이라는 새로운 in-context learning 프레임워크를 도입하여 LLM이 예측하는 기준(criteria)를 이해하고자합니다. 예를 들어, 특정 질병을 예측하는 작업에서 LLM이 특정 조건을 결정하는 규칙을 추론하고 생성할 수 있습니다. 이러한 접근은 LLM의 능력을 feature generating으로 전환시켜 보다 단순한 후속 모델의 사용을 가능하게 하며, 따라서 보다 나은 추론 속도(inference latency)를 제공합니다. 또한, 앙상블 기법 중 feature bagging 기법을 사용하여 과도한 프롬프트 크기의 문제를 완화합니다.
Ⅲ. Related Work
일반적으로 Tabular data는 특성이 이질적이기에 보편적으로 적용 가능한 데이터 증강 기법을 찾는 것이 매우 어려우며 따라서 few-shot learning에서는 전통적인 머신러닝 방법이 크게 효과적이지 않았습니다.
Tabular data를 통한 예측모델 대해 LLM을 적용한 주로 살펴볼만한 최신 연구들은 아래와 같습니다.
- 다양한 연구자(Zhang et al., 2023; Levin et al., 2022; Zhu et al., 2023)에 의해 목표 작업과 관계 없는 다양한 Tabular data set에서 모델을 학습시키고, 이를 목표 작업에 전이 학습(transfer learning)시키는 방식이 제안되었습니다. 예를 들어, TransTab(Wang & Sun, 2022)는 열 이름을 기반으로 열 간의 의미적 관계를 학습시키는 transformer 기반의 모델을 학습시켜, 단순한 테이블 값이 아닌 열의 이름까지 학습에 활용합니다. 따라서 새로운 tabular 작업에 대해서도 zero-shot과 few-shot 추론이 가능해졌습니다.
- TabPFN(Hollmann et al., 2023)은 다양한 분포 유형을 혼합하여 사전 학습용 데이터를 생성하여 베이지안 신경망(Bayesian Neural Network)를 사전 학습 시킵니다. TabPFN은 이를 통해 few-shot 상황에서 전통적 트리 기반 접근법을 능가함을 이미 입증한 바 있습니다.
- LLM의 풍부한 사전 지식을 학습과 예측에 직접 적용한 사례도 있습니다. 이러한 연구들은 일반적으로 tabular data를 직렬화하여 LLM 프롬프트에 직접적으로 제공하는 방법을 제안합니다.
- 이후 해당 분야의 연구는 LoRA와 같은 파라미터 튜닝 기법을 활용해 모델을 특화하여 학습하거나, 학습 없이 소수의 예제만을 프롬프트에 추가하는 in-context learning을 채택하는 방향으로 발전했습니다.
이러한 방법들은 모두 few-shot learning에서 기존의 방법들을 개선하는데 효과적이지만, 항상 LLM을 통해 추론을 진행해야함은 실제 도메인에서 한계를 가져옵니다.
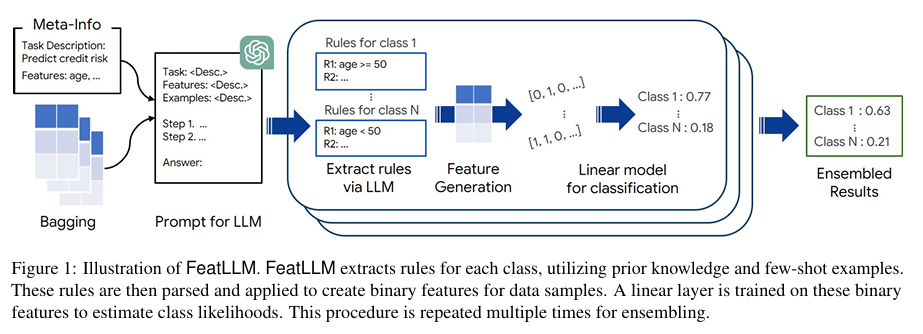
따라서 FeatLLM은 LLM을 end-to-end로 활용하는 기존의 블랙박스 접근법을 벗어나 LLM이 각 클래스와 규칙을 추론하는데 초점을 맞춥니다. FeatLLM은 생성한 규칙을 프로그래밍 코드로 변환하여 새로운 특징을 생성하기에 LLM을 거치지 않고 예측을 수행할 수 있습니다. 모델은 각 클래스에 대한 규칙을 추출해 binary feature를 생성합니다. 이를 linear layer에 학습시켜 클래스를 추정하고, 이 과정을 여러 번 반복하는 앙상블 기법을 활용합니다.
figure.1을 통해 이러한 FeatLLM의 아키텍처를 확인할 수 있습니다.
Ⅳ. Method
*problem formulation

N개의 데이터셋 D에서 d개의 피쳐가 존재한다고 정의해보겠습니다. Dataset D는 N^2 차원의 x,y 좌표를 가지고 있으며 자연어로 구성된 피쳐 이름 f를 가집니다.
분류에 있어 레이블 y가 존재하며, 이 때 k-shot learning은 N보다 작은 k개의 레이블링된 샘플을 랜덤하게 추출하여 사용합니다.
prompt design

주황색으로 색칠된 텍스트는 주어진 문제를 해결하기 위한 필수적이고 기본적인 내용이 들어갑니다. 주어진 문제(task)와 피쳐들에 대한 묘사(Features), 예제에 대한 데모(Examples)가 포함됩니다.
작업에 대한 설명은 질문 형식으로 작성됩니다. 예를 들어, "Does this patient’s myocardial infarction complications data indicate chronic heart failure? Yes or no?" 과 같은 방식입니다. 각 데이터셋에 대한 Task description은 Appendix A.1에 자세하게 서술되어있습니다.

피쳐에 대한 설명은 해당 피쳐의 타입 유형을 작성하며, 피쳐의 정의를 포함하기도 합니다. categorical column의 경우 가능한 카테고리의 예시를 제공할 수도 있습니다.
예제는 몇 가지 학습 샘플을 직렬화시켜 실제 레이블과 함께 제공합니다. 직렬화는 이전 연구(Dinh et al., 2022; Hegselmann et al., 2023)에서 사용된 아래의 방식을 사용합니다.
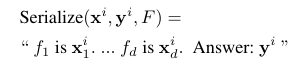
파란색 텍스트는 추론 과정에 대한 문장입니다.
Chain-of-thought(Wei et al., 2022b)와 유사한 도입 문장으로 시작하며, 이후 두 단계의 추론 과정을 거칩니다.
step 1에서는 LLM이 특징의 인과 관계와 경향성을 추론하도록 합니다. 이 과정에서는 예제를 참고하지 않고 일반적인 지식/상식을 활용하여 사전 지식을 추출합니다.
이후 step 2에서는 첫 번째 단계의 정보와 예제를 활용하여 각 클래스에 대한 규칙을 도출합니다.
이 2 step의 추론 과정이 모델이 레이블과 관련 없는 열에서 잘못된 상관관계를 식별하지 않도록 방지합니다. 또한, 더 중요한 특성에 집중 할 수 있도록 돕습니다.
추가적으로, 너무 적거나 너무 많은 규칙을 추출하게되면 과소적합/과적합의 문제가 발생할 수 있기에 각 클래스 당 고정된 규칙 수를 설정해주었습니다.(예시에서는 10개)
마지막 노란색 텍스트는 응답의 형태를 지시합니다. 응답의 형식과 규칙의 형식에 대한 가이드라인을 포함합니다. 또한, 추가적인 지침 없이도 AND, 또는 OR 연산자를 활용해 여러 규칙을 결합할 수도 있습니다(APPENDIX A.3).
실제 프롬프팅에 대한 예시는 Appendix A.2에 자세하게 나와있습니다.

Inferring Class Likelihood

이전 단계에서 생성한 규칙을 통해 새로운 이진 특성(binary feature)을 생성합니다. 이는 해당 클래스에 대한 샘플이 해당 규칙을 만족하는지의 여부를 0/1로 표현한 피쳐입니다.
클래스의 확률을 예측하기에 앞서, 생성된 규칙에 대해 파싱을 수행해야합니다. 왜냐하면 LLM에서 생성한 규칙은 자연어에 기반하기 때문에 자동화된 특징 생성을 위해서는 구문 분석이 필수적입니다.
이전 단계의 노란 텍스트 부분에서 이미 출력에 대한 형식을 제한하였음에도 불구하고, LLM의 출력에는 문법적 변형(noisy syntatic changes)이 발생할 수 있습니다(Kovaˇc et al., 2023). 예를 들어, "<"와 같은 표현을 LLM은 "greater than"과 같은 구문으로 바꿀 수 있습니다. 이러한 불규칙적이고, 노이즈가 낀 문법적 변형은 구문 분석을 어렵게 만드는 요인입니다.
따라서 간단하게 파싱을 수행하기 위해 다시 LLM을 활용합니다. LLM은 문법적 변형에도 불구하고 의미를 이해할 수 있으며, 간단한 코드를 생성할 수 있는 능력이 있습니다.
따라서 함수 이름, 입/출력에 대한 설명, 도출된 규칙을 프롬프트에 추가시켜 LLM에 입력시키고, 생성된 코드를 python의 exec()함수로 실행하여 데이터를 성공적으로 변환할 수 있었습니다.
이제 클래스의 확률을 추론합니다. 기존의 머신러닝 모델을 활용하여 학습을 진행하는데, 아래와 같은 편향(bias)이 없는 선형 모델을 고려해볼 수 있습니다.
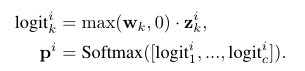
각 샘플 x에 대해 클래스 k에 대한 생성된 이진 특성을 z라고 해봅시다. 0보다 큰 가중치를 z에 곱해주어 logit 벡터값을 구해주고, 이를 softmax에 넣어주어 클래스 별 확률을 구합니다. 이 때 W는 선형 모델이 학습 가능한 가중치로, 각 피쳐의 중요도를 나타냅니다. 이를 양의 공간으로 투영하기 때문에, LLM이 생성한 피쳐가 학습 과정에서 클래스에 속할 확률을 감소시키지 않을 수 있습니다. W를 학습하는데 이용되는 Loss function으로는 Cross-Entropy loss를 사용하였습니다.
마지막으로, 전체 과정을 여러 번 반복하여 여러 개의 추론 모델을 생성하여 앙상블 메서드를 사용해 최종 예측을 수행합니다. T번의 실험으로부터 수집된 가중치 집합 {w[t]}에서 각 w[t]에 대해 계산된 클래스 확률 pi의 평균을 구하는 방식으로 예측을 수행합니다.
LLM 추론에 대해서는 temperature를 충분히 높게 설정해주는데, 이는 모델의 출력을 분산시켜 다양성을 보존하고 더 많은 창의적인 결과를 얻을 수 있도록 돕습니다. 또한, 몇 가지 shot의 순서를 바꾸어 LLM의 질의 결과에 긍정적인 영향을 끼칠 수 있도록 합니다(Lu et al., 2022). 더 강력한 예측을 위해서는 Bagging을 활용할 수도 있습니다.
제안된 앙상블 메서드는 두 가지 주요 쟁점을 제공합니다. 첫 째는, LLM이 일부 실험에서 잘못된 규칙을 생성하더라도, 다른 실험에서 생성한 올바른 규칙이 이를 보완하여 모델 전체의 강건성(Robust)를 유지합니다. 이는 자기 일관성(self-consistency)와 관련 있으며, 여러 실험이 공통적으로 도출한 규칙은 더 정확할 가능성이 높습니다(Wang et al., 2022).
둘 째는 LLM의 프롬프트 크기 제한을 해결하는 점입니다. 배깅은 tabular data의 크기를 줄여 모델의 강건성을 보장합니다.
단일 규칙 집합은 모든 특징간 상관관계를 포착할 수는 없지만, 여러 실험에서 생성된 약한 학습기(weak learners)들의 앙상블이 개별 실험이 가지는 불완전한 커버리지의 문제를 해결할 수 있습니다.
실험과 분석은 2편
