Han, Sungwon, et al. "Large Language Models Can Automatically Engineer Features for Few-Shot Tabular Learning."arXiv preprint arXiv:2404.09491 (2024).
https://arxiv.org/abs/2404.09491
ⅴ. Experiments
Datasets
실험에 사용한 데이터셋은 총 13개로, 이진/다중 분류문제를 모두 포함합니다. 이를 표로 간단하게 정리하면 다음과 같습니다.
| Data | Purpose | Target | Source |
|---|---|---|---|
| Adult | 개인이 연간 $50,000 이상을 버는지 예측 | 연간 수입 (>$50,000 또는 <=$50,000) | Asuncion & Newman, 2007 |
| Bank | 고객이 정기 예금에 가입할지 예측 | 정기 예금 가입 여부 | Moro et al., 2014 |
| Blood | 헌혈자가 추가 헌혈을 할지 예측 | 추가 헌혈 여부 | Yeh et al., 2009 |
| Car | 자동차의 품질 예측 | 자동차 품질 | Kadra et al., 2021 |
| Communities | 특정 지역의 범죄율 예측 | 범죄율 | Redmond, 2009 |
| Credit-g | 개인의 신용 위험 여부 예측 | 신용 위험 (좋음/나쁨) | Kadra et al., 2021 |
| Diabetes3 | 개인의 당뇨병 존재 여부 예측 | 당뇨병 여부 | https://www.kaggle.com/datasets/uciml/pima-indians-diabetes-database |
| Heart4 | 개인의 관상동맥질환 발생 여부 예측 | 관상동맥질환 여부 | https://www.kaggle.com/datasets/fedesoriano/heart-failure-prediction |
| Myocardial | 개인의 만성 심부전 여부 예측 | 만성 심부전 여부 | Golovenkin & Voino-Yasenetsky, 2020 |
| Cultivars | 대두 품종의 곡물 수확량 예측 | 곡물 수확량 | https://archive.ics.uci.edu/dataset/913/forty+soybean+cultivars+from+subsequent+harvests |
| NHANES | 기록 기반으로 연령대를 예측 | 연령대 | https://archive.ics.uci.edu/dataset/887/national+health+and+nutrition+health+survey+2013-2014+(nhanes)+age+prediction+subset |
| Sequence-type | 주어진 시퀀스를 4가지 유형(산술, 기하, 피보나치, 콜라츠) 중 하나로 분류 | 시퀀스 유형 | UCI Machine Learning Repository |
| Solution-mix | 혼합물의 네 가지 용액 중 농도 비율이 0.5를 초과하는지 예측 | 농도 비율 초과 여부 | UCI Machine Learning Repository |
! Sequence-type과 Solution-mix는 UCI Machine Learning Repository에 2023년 9월에 기부된 최신 데이터셋으로 언급되어있으나, 현재 데이터의 원본을 찾아볼 수가 없었습니다.
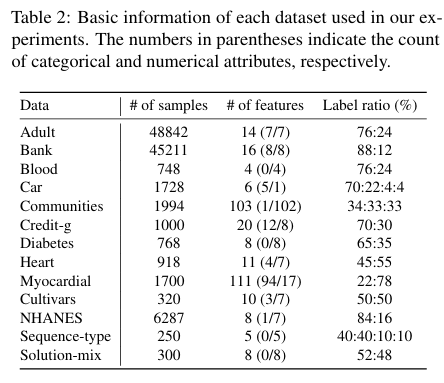 Reprinetd Table.2
Reprinetd Table.2
각 데이터셋의 자세한 특성은 위와 같습니다. 왼쪽부터 차례대로 샘플의 개수, 피쳐의 개수(괄호 안의 비율은 각각 categorical/numerical 피쳐의 개수이다), 레이블의 비율입니다.
Baselines
| Baseline | Description | Source |
|---|---|---|
| Logistic Regression (LogReg) | 전통적인 표 형식 데이터 학습 방법 중 하나로 선형 회귀 모델의 확률적 해석을 기반으로 함 | - |
| XGBoost | Gradient Boosting 알고리즘의 효율적인 구현으로, 표 형식 데이터 학습에서 높은 성능을 보여줌 | Chen & Guestrin, 2016 |
| Random Forest | 결정 트리들의 앙상블 모델. 과적합을 줄이고 예측 정확도를 높임 | Ho, 1995 |
| SCARF | 비표지 데이터셋을 활용하며, 표 형식 데이터에서의 비지도 학습 접근법 | Bahri et al., 2022 |
| STUNT | 비표지 데이터셋을 사용하며, 비지도 학습을 위한 새로운 접근법 | Nam et al., 2023b |
| TabPFN | 다양한 분포를 가진 합성 데이터셋을 생성하여 모델을 사전 학습하는 방식 | Hollmann et al., 2023 |
| In-context Learning | 소수의 학습 샘플을 입력 프롬프트에 직접 포함하여 미세 조정 없이 학습 수행 | Wei et al., 2022a |
| TABLET | 외부 분류기와 규칙 집합, 프로토타입을 통해 추가 힌트를 프롬프트에 포함하여 추론 품질을 향상시킴 | Slack & Singh, 2023 |
| TabLLM | IA3와 같은 매개변수 효율적 튜닝 기법을 사용하여 LLM을 소수의 샘플로 학습 | Hegselmann et al., 2023 |
Details
FeatLLM은 GPT-3.5를 backbone으로 사용하였지만, 이에 독립적으로 설계되어있습니다(예를 들어, APPENDIX.H에서는 PaLM을 사용한 결과가 수록되어있습니다).
LLM 추론을 위한 temperature는 0.5, top-p값은 API의 기본값인 1로 설정됩니다. 앙상블되는 모델의 수는 20, 추출하는 규칙의 수는 10으로 설정됩니다. 이러한 하이퍼파라미터의 변화는 이후 분석할 것이며, APPENDIX.B에 더욱 자세히 기술되어있습니다.
Optimizer의 경우 Adam을 사용하고, learning rate는 0.01, epoch는 200을 줍니다. 최적 epoch를 선택하기 위해 k-fold 교차 검증을 수행합니다. 또한, LogReg, XGBoost, RandomForest에 대해서도 k-fold를 통해(k=2, 또는 4) 하이퍼파라미터를 설정하였습니다.
실험은 3번씩 반복수행되어 AUC값의 평균과 표준편차를 제공하였습니다.
Evaluation Results
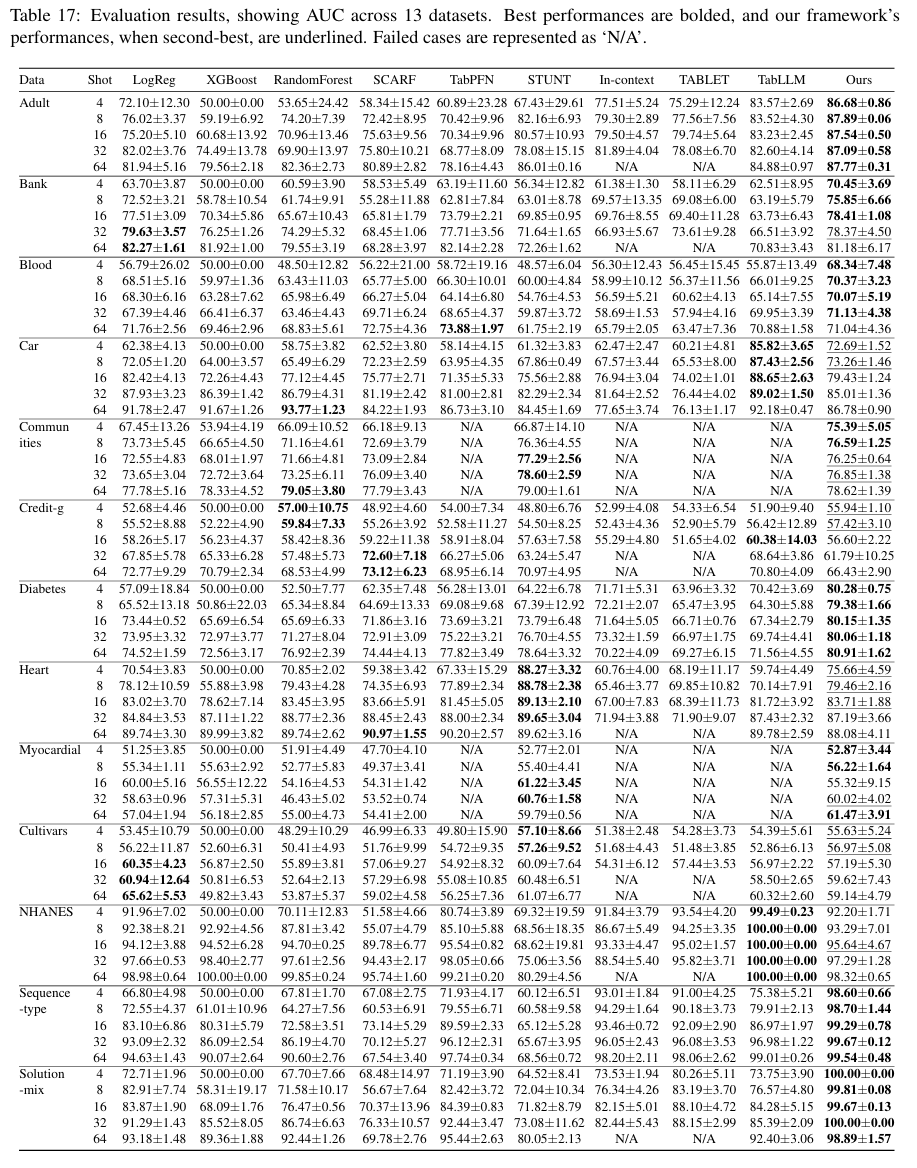 Reprinted Table.17(APPENDIX.K)
Reprinted Table.17(APPENDIX.K)
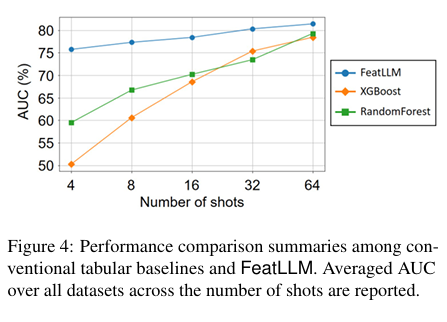 Reprinted Figure.4
Reprinted Figure.4
FeatLLM은 다른 베이스라인 모델들과 비교했을 때, 대부분의 경우에서 가장 좋거나 혹은 2번재로 좋은 성능을 달성하였습니다. 특히, 4개의 shot만으로도 32개의 shot으로 학습한 전통적인 머신러닝 모델과 비슷한 성능을 달성합니다.(figure.4 참조)
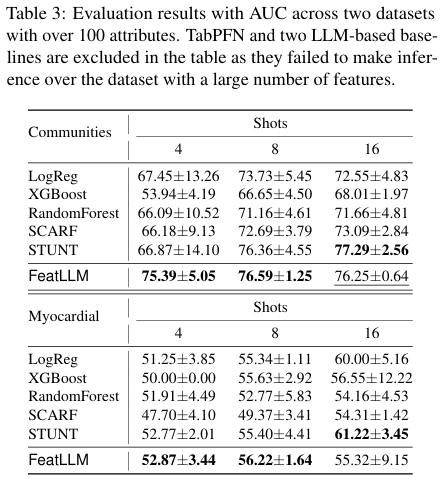 Reprinted Table.3
Reprinted Table.3
in-context learning, TABLET, TabLLM과 같은 LLM을 사용하는 모델은 피쳐의 개수가 많은 데이터셋(Communities, Myocardial. Table.3 참조)에서 성능이 낮게 나왔습니다.
반면 FeatLLM은 배깅과 앙상블을 결합하여, 특성이 많은 데이터셋에서도 효과적으로 작동하며 좋은 성능을 보였습니다. 중요한 점은 이 방식이 기존의 LLM 기반 모델에도 적용될 수 있다는 점입니다. 다만, 이러한 방식은 샘플 당 추론 횟수를 두 배로 늘리므로 cost가 증가할 수 있습니다.
Ⅵ. Analysis and Discussion
Ablation Study
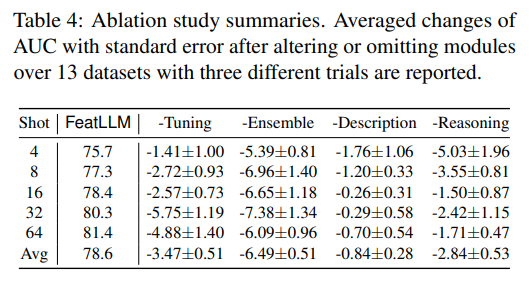 Reprinted Table.4
Reprinted Table.4
먼저, 요소별 기여도를 분석하기 위해 요소 제거 실험(Ablation Study)를 수행하였습니다. 분석의 초점은 다음과 같습니다.
1. -Tuning : 선형 모델에서 가중치를 조절하는 과정을 제거하고, 대신 이진 피쳐를 합산하여 logit을 계산합니다.
2. -Ensemble : 앙상블 과정을 생략합니다.
3. -Description : 피쳐 설명(feature description)을 생략합니다.
4. -Reasoning : 규칙을 생성할 때, 추론 지침에서 1단계를 생략합니다.
해당 결과는 table.4에 기록되어있습니다. 모든 데이터셋에서 수행한 요소 제거 실험의 평균을 비교하면, 어느 요소를 제거하던 성능은 저하되었습니다. 주로 관찰해야될 지점은 다음과 같습니다.
1. Weight tuning : 샘플의 수가 많아질 수록 weight tuning의 효과는 커집니다. 즉, 가중치 조정이 성능에 중요한 역할을 합니다.
2. Feature Description & Reasoning instruction : 샘플 수가 적을 때 더 큰 성능 저하가 발생합니다. 이는 즉, LLM의 사전 지식을 효율적으로 사용함이 성능 개선에 주요하게 작용함을 의미합니다.
3. Ensemble : 제안된 앙상블 기법이 모든 설정에서 일관되게 성능을 향상시켰습니다.
Training & Inference Time
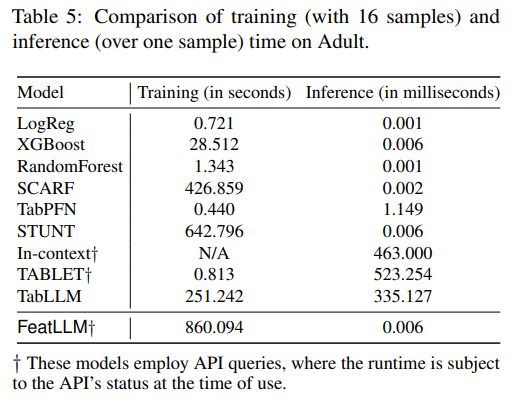 Reprinted Table.5
Reprinted Table.5
이번에는, 다양한 모델간의 학습 시간과 추론 시간을 비교했습니다. 해당 실험은 Adult 데이터셋(16-shot)에서 수행되었습니다.
학습 시간의 경우 FeatLLM은 다른 LLM 기반의 방법과 비교하였을 때 유사한 훈련 시간을 보였습니다. FeatLLM의 경우 30개의 API 쿼리만을 필요로 하기에 예산에 큰 부담을 주지 않으며, 병렬화 또한 가능합니다.
추론 시간의 경우 FeatLLM은 기존 방법들과 마찬가지로 짧은 추론 시간을 보였습니다. LLM 기반 모델들의 경우 높은 추론 시간을 보였는데, 이는 LLM 기반의 방법이 복잡한 계산을 포함하기 때문입니다.
Quality of features generated by FeatLLM
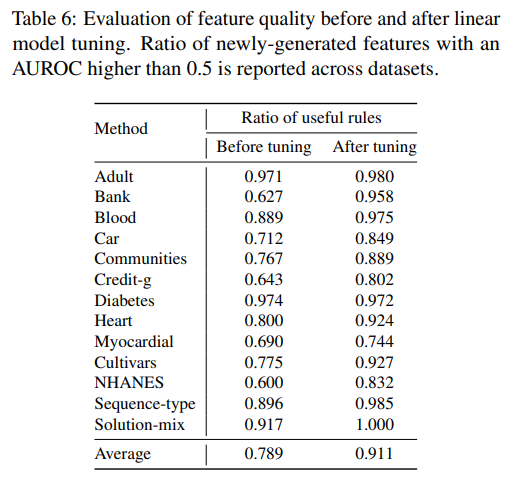 Reprinted Table.6
Reprinted Table.6
FeatLLM이 생성한 피쳐가 실제로 얼마나 영향을 미쳤는지에 대한 분석입니다. 실험은 새로 생성된 피쳐와 타겟 레이블 간의 평균 AUROC를 측정하여 0.5가 넘는 유용한 피쳐들의 비율을 계산하여 진행되었습니다.
튜닝 전에는 생성된 대부분의 규칙들이 타겟과 관련이 높기 때문에 분류 문제를 해결함에 있어 도움이 되는 인사이트를 제공함이 확인되었습니다.
튜닝 이후에는 타겟과 관련성이 적은 규칙들이 자동으로 필터링 되었습니다.
따라서 FeatLLM이 생성한 규칙에 기반한 피쳐가 대부분 유용하며, 선형 모델의 필터링 과정을 통해 불필요한 규칙들을 탈락시킬 수 있음을 보였습니다.
Effect of Adding Spurious Correlations
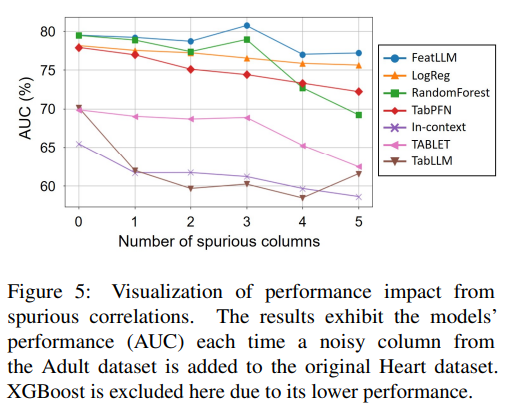 Reprinted Figure.5
Reprinted Figure.5
이 실험은 FeatLLM을 포함한 다양한 모델이 low-shot 환경에서 얼마나 효과적으로 거짓 상관관계(spurious correlations)를 필터링하는지 분석합니다. Heart 데이터셋에 Adult데이터에서 불필요한 컬럼들을 임의로 추가해 관련없는 피쳐와 데이터를 결합합니다. 그 다음, 관련 없는 컬럼의 수를 점진적으로 늘려가며 비교합니다. 이때 공정한 비교를 위해 라벨이 없는 데이터셋은 제외하여 SCARF, STUNT와 같은 모델은 비교했습니다.
실험결과 FeatLLM은 다른 방식에 비해 spurious column으로 인한 성능 저하가 가장 적었습니다. 이는 FeatLLM이 규칙을 추출할 때 사전 지식을 바탕으로 작업과 피쳐간의 관계를 고려하기에 불필요한 컬럼을 기반으로한 규칙 생성을 방지하였기 때문입니다. 노이즈가 포함된 컬럼에 기반한 규칙은 전체에서 1-2%에 불과하기도 하였습니다.
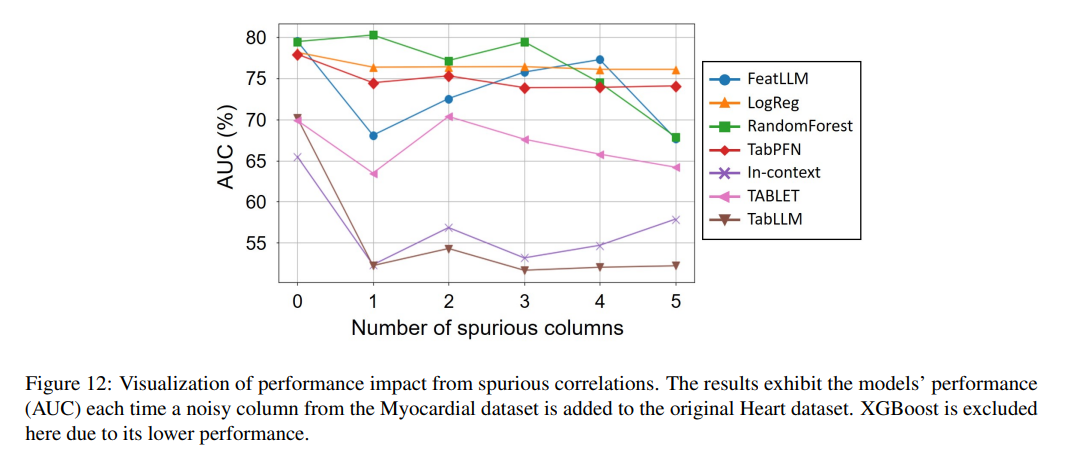 Reprinted Figure.12 (APPENDIX.I)
Reprinted Figure.12 (APPENDIX.I)
하지만 FeatLLM이 관련이 있는 데이터에서 임의로 컬럼을 추가할 경우, 거짓 상관 관계와 인과 관계를 학습할 수 있다는 점 또한 관측되었습니다. Figure.12는 APPENDIX I에 있는 결과로, Heart 데이터셋에 Myocardial 데이터셋의 컬럼을 추가한 실험 결과입니다. 결과적으로 FeatLLM은 노이즈 정보에 대한 규칙을 더 많이 추출하여 과적합되고, 이로인해 노이즈가 포함된 컬럼으로부터 추출된 규칙이 전체의 7-8%를 차지하였습니다. 다른 모델에서도 성능이 유의미하게 감소하는 결과를 확인할 수 있었습니다.
Hyperparameter Analysis
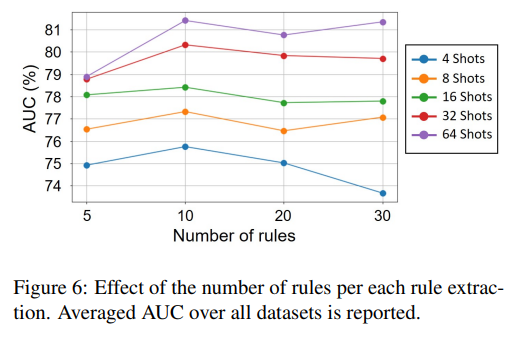 Reprinted Figure.6
Reprinted Figure.6
FeatLLM에는 두 가지 주요 하이퍼파라미터가 있습니다. 하나는 앙상블 수, 다른 하나는 각 클래스에서 추출할 규칙의 수입니다.
실험 결과, 앙상블의 수가 증가함에 따라 성능이 향상되었지만, 일정 수치(20)을 넘으면 성능 향상이 수렴함을 보였습니다. 이는 규칙이 많아지면 입력 차원이 커져, 정보는 증가하지만 low-shot 환경에서는 과적합이 발생할 수 있음을 의미합니다.
Figure.6의 결과는 통계적으로 유의미한 차이는 없지만, 10개의 규칙이 프롬프트 길이와 성능 간의 균형을 고려할 때 가장 적절하다고 연구자는 판단하였습니다.
Ⅶ. Conclusion
결과적으로 본 연구에서는 FeatLLM을 제시하며, LLM기반의 low-shot 학습의 최신 기술을 발전시켰습니다. FeatLLM은 각 샘플에 대한 예측을 수행하는데 LLM을 사용하는 것을 넘어, 피쳐 엔지니어링에 중점을 둡니다. 규칙 생성과 배깅, 앙상블을 통해 FeatLLM은 최소 추론 비용으로 작동하며, 훈련 없이 API만으로도 사용할 수 있고, 데이터 특성 크기의 제약을 극복합니다. 또한, 높은 예측 성능을 달성하며 tabular data에 대한 뛰어난 대안이 됩니다.
FeatLLM은 훈련 샘플이 제한적인 low-shot 환경에서 과적합 문제를 사전 지식을 통해 완화합니다. FeatLLM은 특히 금융, 헬스 케어 산업과 같이 레이블링이 어려운 현실적인 시나리오에서 유용합니다. 이 산업들에서 데이터를 수집하고 레이블링하는 것은 비용이 높거나 어려운 경우가 많기에 LLM의 사전 지식이 매우 가치있게 사용될 것입니다.
FeatLLM은 low-shot 학습에 초점을 맞추어 설계되었습니다. 연구의 미래 목표는 더 많은 샘플을 가진 데이터셋에 대해서 새로운 특징을 생성하는 기능을 확장하고 해석 가능성을 제공하는 것입니다. 또한, 미래의 주요 연구 방향 중 하나는 LLM에 내제된 사회적 편향과 거짓 정보가 예측에 미치는 영향을 분석하는 것입니다. 이는 사전 지식이 예측에 영향을 미치며, 때로는 관측되거나 수집된 레이블보다 더 큰 영향을 미칠 수 있기 때문입니다.
