Lu, Weizheng, et al. "Large language model for table processing: A survey." Frontiers of Computer Science 19.2 (2025): 192350.
https://doi.org/10.1007/s11704-024-40763-6
Ⅳ. Table training
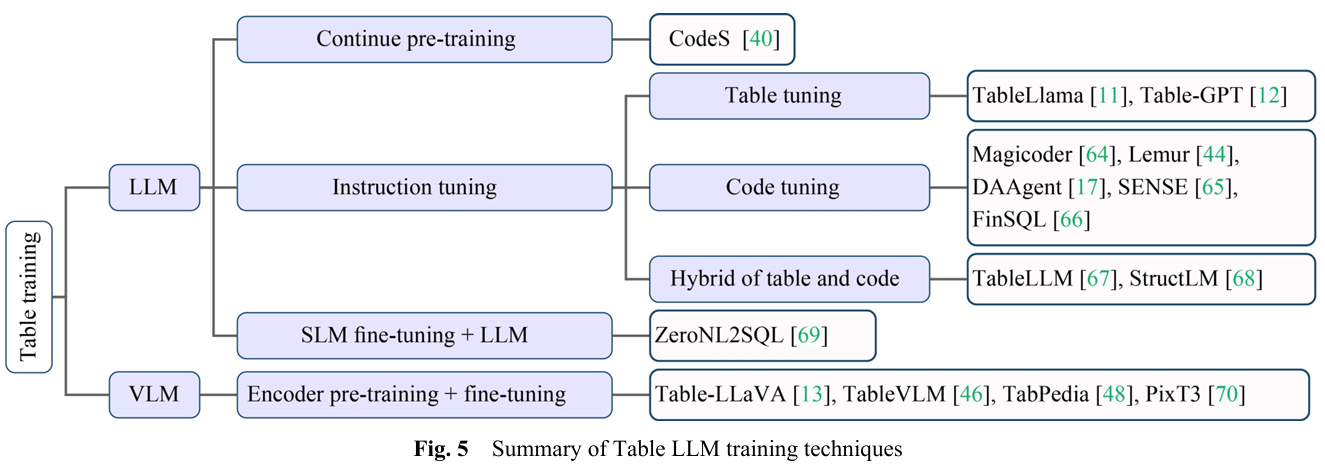
Table LLM Training
LLM이 등장하기 이전에도 테이블 관련 작업에 LM을 사용하는 연구는 매우 많았다(TaPas, TaBERT, TURL, TABBIE, TaPEx, RESDSQL, LayoutLM etc...). 하지만 이러한 방법론들은 모두 소형 언어 모델에 기반하고 있었으며, 다운스트림 작업에 적용이 어렵거나, fine-tuning시 annotaion이 많이 필요하였다.
그러나 LLM이 등장한 이후, instruction tuning과 continued pre-training이 활발히 사용되어왔다.
instruction tuning의 경우 prompt 내부에 지시문(instruction)을 삽입하여 모델의 동작 방식을 유도하였는데, 테이블 타입에서는 다음의 3가지 instruction tuning이 사용된다.
- Table Tuning : 테이블 작업(QA, Table-to-Text, Entity linking)을 처리할 수 있도록 LLM을 튜닝.(TableLlama, Table-GPT)
- Code Tuning: 테이블 데이터를 처리하기 위한 SQL이나 Python 코드 생성을 목표로 튜닝.(Magicoder, Lemur, DAAgent, SENSE, FinSQL)
- Hybrid of table and code : 코드에 기반한 instruction dataset을 통해 LLM을 튜닝.(TableLLM, StructLM)
이외에도 SLM이 보조 역할을 하여 LLM이 원하는 출력을 내도록 유도하는 SLM fine-tuning + LLM 방식이 존재한다.(ZeroNL2SQL)
Table tuning

Table tuning은 table instruction tuning의 약자이다. 즉, 여러 테이블 데이터셋을 활용하여 instruction tuning용 데이터셋을 구축하는 방법을 의미한다.
예를 들어 Fig.6은 TableLlama에서 사용한 instruction tuning용 데이터셋인 TableInstruct의 예시이다.
Instruction은 수행해야될 작업을, Table은 테이블의 내용이나 메타데이터를, Question은 자연어 질의를, Output은 자연어 기반의 출력(QA의 정답, Table-to-Text의 결과, 테이블 조작 결과 등)을 의미한다.
이러한 방식에서 여러 가지 데이터 증강 기법들이 사용되는데, 예를 들어 Table-GPT는 아래 3가지 데이터 증강 기법을 사용한다. 이러한 증강 기법들은 모델의 과적합을 막고, unseen task에도 잘 적응하도록 돕는다.
- Instrcution-level : 강력한 LLM을 사용하여 기존의 지시문을 다양한 형태로 변형
- Table-level : 테이블 자체를 변형
- Output-level : 출력 결과를 다양하게 변형
Code Tuning

테이블은 SQL, Python과 같은 언어와 코드를 통해서도 조작이 가능하므로 Code instruction tuning은 코드 생성에 특화되도록 LLM을 학습하는 기법이다. 즉, Code LLM은 먼저 코드를 생성한 뒤, 그것을 Interpreter나 DB Engine에서 실행하여 결과를 얻는다. 이는 특히 NL2SQL, 데이터 분석 등에서 강점을 보인다.
Hybrid of table and code
Zhuang, Alex, et al. "Structlm: Towards building generalist models for structured knowledge grounding." arXiv preprint arXiv:2402.16671 (2024).
https://arxiv.org/abs/2402.16671
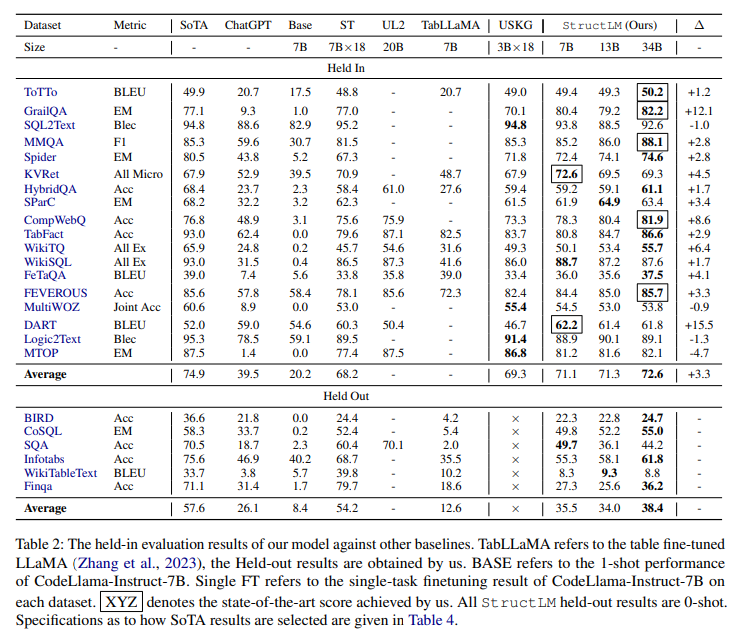
Code LLM, general LLM, Math LLM 등을 대상으로 Tabular data에 대해 fine-tuning하여 성능 비교를 한 결과, code LLM을 base model로 사용하는 것이 Table 작업에서 가장 좋은 성능을 보였다.(StructLM, 2024)
Continue pre-training

Li, Haoyang, et al. "Codes: Towards building open-source language models for text-to-sql." Proceedings of the ACM on Management of Data 2.3 (2024): 1-28.
https://dl.acm.org/doi/abs/10.1145/3654930
sLLM은 비용이 적고 경량화되어있지만, 코드 생성이나 추론 능력은 부족합니다. 이를 보완하기 위해 StarCoder 모델에 대해 SQL 관련 자연어와 코드 데이터를 추가로 학습시켜 성능을 향상시킨 바 있다.(CodeS, 2024)
SLM + LLM

Fan, Ju, et al. "Combining small language models and large language models for zero-shot NL2SQL." Proceedings of the VLDB Endowment 17.11 (2024): 2750-2763.
https://dl.acm.org/doi/abs/10.14778/3681954.3681960
SLM은 Table schema를 이해하는데 강점을 보이고, LLM은 추론 능력이 강하지만 hallucination 현상이 발생할 수 있다. 이를 해결하기 위해 Encoder-Decoder 기반의 SLM이 SQL에 대한 스케치 후보를 생성하고, LLM은 그 스케치의 빈칸을 채우고 오류를 수정하여 최종 SQL 쿼리를 생성하는 연구가 수행된 바 있다.(ZeroNL2SQL, 2024)
Table VLM training
테이블 작업에 사용되는 VLM에 대한 연구는 주로 다음의 3가지 방식으로 수행된다.
- 패턴 인식 : 테이블의 detection과 extraction 작업에 초점을 맞춤.(TableVLM)
- End-to-End model: 테이블 이미지에서 QA, Text Generation 등 다양한 작업을 End-to-End model로 처리한다.(Table-LLaVA)
- Hybrid : 1,2 방식을 모두 갖춘 모델(TabPedia)
LLM은 대부분 decoder only 구조이지만, VLM은 일반적으로 Encoder-Decoder 구조를 사용한다. 따라서 Table VLM의 학습은 vision encoder를 pre-training한 후(이때 디코더인 LLM의 파라미터는 freeze), encoder와 decoder를 함께 fine-tuning한다. 이 때 많은 양의 고품질 멀티모달 데이터가 필요하고, 시각 정보와 언어 정보의 Alignment가 중요하다.(PixT3)
Ⅴ. Table prompting
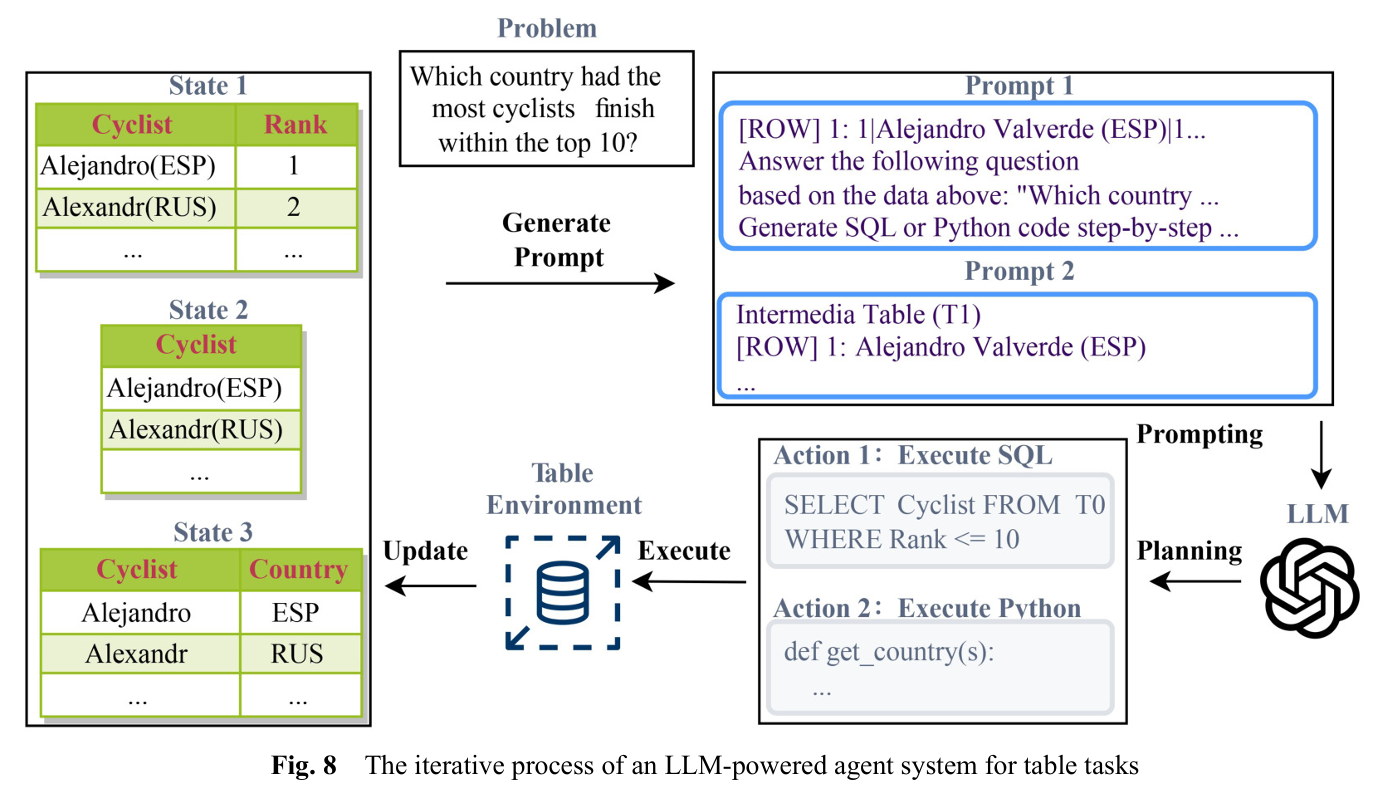
LLM agents workflow
CoT, ReAct와 같은 방법론은 LLM이 복잡한 문제를 여러 단계로 나누어 생각하도록 유도한다. agent 시스템도 이러한 구조를 따르는데, 주로 memory, planning, Action 3가지의 모듈로 구성된다.
memory 모듈은 계획과 실행에 대한 기록을 저장하며, 일관된 행동이 가능하도록 돕는다.
Planning
Planning 모듈은 LLM에게 1) 복잡한 문제를 sub-problem으로 쪼개는 것과, 2) 이전 결정에 대해 성찰하고 수정하는 것을 요청한다.
계획을 공식화할 때는 ReAct방식처럼 feedback을 통해 학습한다.
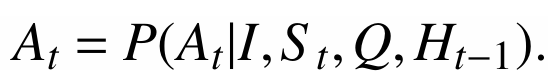
At는 지시문 I, 테이블 state인 St, 하위 문제인 Qt, 이전 기록인 Ht-1을 통해 출력되는 Action이다. 이후 Qt를 갱신하고, Ht를 갱신한다.
또한, CoT, least-to-most와 같은 prompting 기법에 영감을 받아 복잡한 작업을 간단한 sub-task로 나누기도 한다. DIN-SQL은 NL2SQL을 하위 query로 분해하였고, DEA-SQL과 TabSQLify는 불필요한 정보를 제거하고 단순화하였으며, Dater는 거대한 테이블을 작은 sub-table로 나누었다.
이외에도 self-consistency와 voting을 통해 여러 번 추론하여 일관된 답을 선택하거나(계산 비용은 커진다), 이전 행동에 대해 보완하는 Revising을 수행하기도 한다.
Action
테이블 작업에서 LLM의 Action은 LLM과 외부 도구 사이의 중간 다리 역할을 하게된다.
- Table QA & NL2SQL : LLM이 SQL이나 Python code를 생성하고 실행한다. 필요한 정보가 없다면 Python으로 중간 테이블을 생성하여 Revising한다.(ReAcTable)
- Spreadsheet manipulation and data analysis : 사용자의 요구가 다양하고, API의 범위가 넓다. (SheetCopilot, SheetAgent, Data-copilot)
- 이외에도 여러 테이블 작업을 하나의 프레임워크 내부에서 처리하는 연구들 또한 존재한다.(StructGPT, UniDM, TAP4LLM, ChatPipe)
Other Techniques
이외에도 prompt에 소수 예제를 추가하는 Few-shot examples selection과 LLM에 특정 역할을 부여하는 Role-play와 같은 테크닉이 사용되기도 한다.
Ⅵ. Resources
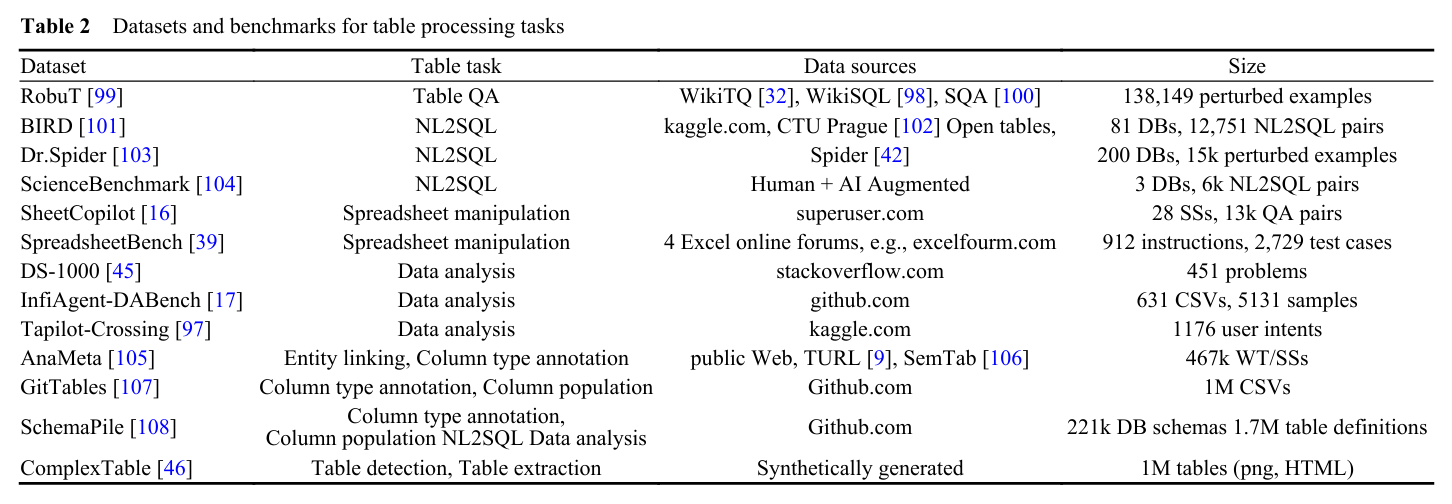
기존 벤치마크인 WikiTQ, WikiSQL, Spider는 이미 널리 사용하고 있으며, 연구되고 있다. 논문은 이들에 대해서는 자세히 다루지 않고, 새롭게 제안된 벤치마크들에 중점을 둔다. Table.2에 최근 제안된 데이터셋과 task, source, size가 제시되어있다. 이러한 벤치마크들은 특성에 따라 아래와 같이 분류할 수 있다.
- Robustness : 테이블 변형에 대한 성능 저하 분석(Dr.Spider, RobuT)
- Human involved labeling : 데이터 분석 작업을 위한 대규모 annotaion.(DS-1000, InfiAgent-DABench, Tapilot-Crossing)
- Real-world workload : 공개된 온라인 데이터는 대부분 초보자용 수준으로 간단하지만, 실제 시나리오를 반영한 데이터셋 또한 필요하다.(ScienceBenchmark, SpreadsheetBench)
- Larger Scale : 대규모 데이터셋들. AnaMeta는 대규모 테이블 메타이터이고, GitTables는 GitHub에서 수집된 million 단위의 csv 파일들이다. schemaPile은 DB schema와 Table definition을, ComplexTable은 복잡한 구조를 가진 이미지 테이블들을 포함한다.
Ⅶ. Analysis and discussion
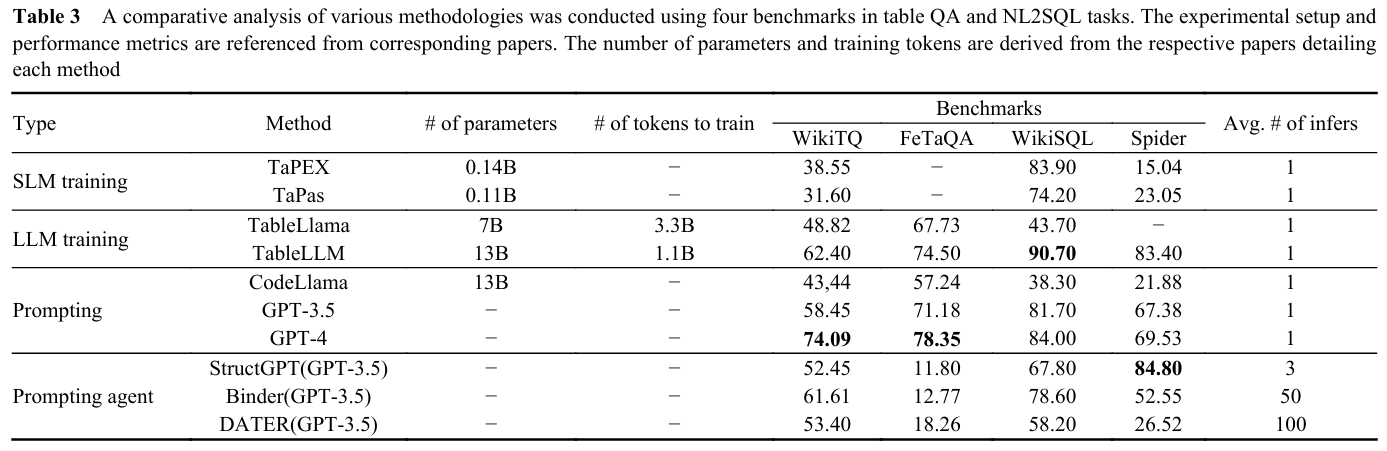
1. Discussion on LLM training
LLM학습에 있어 cost와 accuracy는 주요한 논의점일 것이다.
우선, LLM을 pre-training하거나 fine-tuning 하는 데에는 막대한 cost가 든다. 일례로 7B 모델을 fine-tuning한다면 80GB GPU 8개가 필요하며, Token 수가 시간에 크게 영향을 준다. Table.3에서는 SLM/LLM의 training 방식에 따른 파라미터 수와 훈련 토큰 수를 제시하여 training에 대한 비용을 파악할 수 있도록 하였다.
또한, Table.3에서 볼 수 있듯이 4개의 벤치마크에 대해서 LLM을 훈련하는 접근법은 단 1개에서만 뛰어난 성능을 보였고, 나머지는 강력한 LLM(GPT-4)를 prompting하는 방식이 우수하였다.
훈련 데이터에 대한 라벨링 비용 또한 문제이다. 합성(Synthetic) 데이터는 비용은 낮으나 데이터 품질에서 문제가 있는데, 이에 대한 대안으로 GPT를 teacher model로 활용하여 data distillation 하는 방식이 보편적으로 적용되고 있다.
2. Discussionn on LLM prompting
LLM에 기반한 agent는 LLM의 성능과 외부 도구들을 결합하는 방식이며, 많은 테이블 작업에서 강력한 LLM인 GPT-4를 프롬프팅하는 방식이 가장 뛰어난 성능을 보인다.
하지만 이는 대부분 하드코딩된 template에 의존하기에 전이성(transferability)에서 문제점이 있다. 또한, Table.3의 Avg. # of infers에서 보이듯이 agent는 사용자 경험을 충족시키기 위해 여러 번의 inference를 수행해야하며, 이는 비용과 시간의 문제로 귀결된다.
이외에도 개인정보 이슈나, fine-tuning되지 않은 기본 모델이 table의 구조를 이해하지 못하는 등에 대해 문제점이 존재한다.
Ⅷ. Challenges and future directions
앞으로의 연구를 위한 도전과제 및 고려사항들은 아래와 같다.
1. Diverse user input when serving
현실 세계에서 사용자의 질의가 모호한 경우(ambiguous), 사용자가 테이블에 익숙하지 않은 경우(unfamiliar) 질의를 구성하는데 어려움을 겪기도 한다.
또한, 실제로 테이블의 구조나 내용이 매우 다양하고 비공개되어있는 경우 또한 존재한다. 기존의 데이터셋들은 지나치게 구조가 단순하거나, 강력한 LLM에 의해 합성된 데이터셋을 사용하는 경우가 많으므로 현실 세계의 비즈니스 시나리오를 충분히 반영하는 것이 큰 도전 과제가 된다.
2. Slow and deep thinking
CoT는 이미 LLM의 성능을 대폭 향상시킬 수 있음을 증명하였고, 모델의 학습과 프롬프팅에 모두 도움을 줄 수 있을 것이다.
그러나 training 과정에서 사용자의 instruction과 최종적인 정답 사이에는 논리적인 간극이 존재한다. CoT는 instruction -> answer로 도달하는 과정을 내부적으로 설명해줄 수 있지만, 명확한 Chain-of-Thought를 얻는 것은 어렵다. 따라서 정확하고 저비용으로 CoT를 보장하는 방법을 탐구하는 것 또한 유의미한 연구 영역이다.
또한, 테이블 작업에서 prompt는 하드코딩된 template에 크게 의존하고, 전이성이 약하다. 다만, OpenAI의 o1 모델은 자체적인 CoT 능력을 보유한 만큼, 프롬프팅과 에이전트 방식들도 워크플로우를 다시 구축할 필요가 있다. 해당 과정에서 CoT는 시간과 비용을 증가시키므로, 향후 테이블 프롬프팅 방법은 정확성과 추론 시간의 균형을 맞추는 것이 주요 과제이다.
Ⅸ. Conclusion
LLM과 Table 처리 작업에 대해 종합적으로 조사한 최초의 review paper로서
1) 테이블 작업을 학계/유저의 관점에서 분류 및 요약하였으며, 2) 테이블 처리를 위한 핵심 기술들을 탐색하고, 3) 데이터셋과 벤치마크, 소프트웨어 등 resource를 수집하고 논의하였으며, 4) 기존 연구를 정리하는 것을 넘어 향후 연구를 위한 과제와 방향성을 제시하였다.
