Sui, Yuan, et al. "Table meets llm: Can large language models understand structured table data? a benchmark and empirical study." Proceedings of the 17th ACM International Conference on Web Search and Data Mining. 2024.
https://dl.acm.org/doi/10.1145/3616855.3635752
Abstract
LLM이 과연 table과 같은 구조화된 데이터를 잘 이해하는지는 여전히 미지수로 남아있다. 표 데이터를 serialize하여 LLM의 input으로써 사용할 수는 있지만, 과연 LLM이 이러한 데이터를 잘 이해할 수 있는지 포괄적으로 조사한 연구는 부족한 실정이다.
이에 따라 해당 논문에서는 구조적 이해 능력(SUC, Structural Understanding Capabilities)를 평가하기 위한 벤치마크를 설계하고, LLM의 테이블 이해 능력을 규명하고자 한다. 벤치마크는 cell lookup, row retrieval, size detection 등 다양한 테스크를 포함한 7개의 과제로 구성되어있다.
실험은 GPT-3.5와 GPT-4를 대상으로 수행되었으며, 이 성능은 프롬프트의 형식과 내용, 역할 부여 등 프롬프팅 기법에 따라 변화하였다. 이러한 통찰을 바탕으로 연구자들은 구조적 프롬프트를 효과적으로 생성하기 위한 자기 증강(self-augmentation) 기법을 제안한다. 자기 증강이란 LLM의 내부 지식을 활용해 중요 값과 범위를 식별하는 방식을 의미한다. 이러한 방법이 여러 테이블 기반 과제에서 LLM의 성능을 유의미하게 향상시킬 수 있음을 보였다.
Ⅰ. Instruction
그동안의 선행 연구들은 LLM이 실제로 테이블 데이터를 이해할 수 있는지에 대한 조사가 충분히 이루어지지 않았다. Table Serialize, context/QA가 매우 유동적이였는데, 이는 Table data를 위한 LLM의 prompt 설계에 보편적 합의가 없음을 시사한다. 특히 복잡한 탬플릿과 프롬프트 설계는 연구자와 개발자 모두에게 어려움을 주어 해당 논문은 'LLM이 테이블을 이해하도록 만드는 가장 효과적인 입력 설계는 무엇인가?'에 대해 논의한다.
규명하고자 하는 범위는 1)LLM이 테이블 데이터를 이해하는지, 2) 어느 수준까지 구조적 데이터에 대한 이해가 가능한지 이다. 이를 위해 SUC 벤치마크를 제시하고, format explanation, role prompting, partition mark등 여러 prompt 변형을 실험하였다. 또한, LLM을 더 잘 활용하기 위한 실용적 가이드라인을 제공하며, 특히 self-augmentaed prompting이라는 model-agnostic한 방법론을 제안한다.
즉 논문의 주요 기여와 결론을 요약하면 다음과 같다.
- LLM은 기본적인 구조 이해 능력은 갖추었으나, 단순 과제에서도 아직 완벽과 거리가 멀다.
- 적절한 프롬프트 설계의 조합이 데이터 이해 능력을 크게 향상시킨다.
- self-augmented prompting이 LLM의 내부 지식을 끌어내어 구조 이해 능력을 향상시켰다.
Ⅱ. PreLiminaries
2.1 Table Structure
- 표 데이터는 관계형, 계층형 등 다양한 형태를 가지며 본 논문은 주로 평면 관계형 테이블을 다룬다.
- 텍스트, 숫자 등 다양한 형식의 값이 존재하며, 이러한 유연성은 LLM이 구조를 이해하는 데 어려움을 준다.
2.2 Table Serialization & Splitting
- 테이블 직렬화는 데이터를 LLM이 처리할 수 있도록 선형 텍스트로 변환하는 과정이다.
- 긴 입력으로 인한 성능 저하를 막기 위해 샘플링과 1‑샷 예시 삽입 등의 전략을 사용하며, 다양한 직렬화 방식을 비교 실험한다.
Ⅲ. SUC BENCHMARK
SUC 벤치마크는 1) 프롬프트 설계, 2) LLM의 구조적 이해 능력에 초점을 맞추며 다양한 프롬프트 기법 간의 trade-off 관계 또한 분석한다.
3.1 Structural Understanding Capabilities
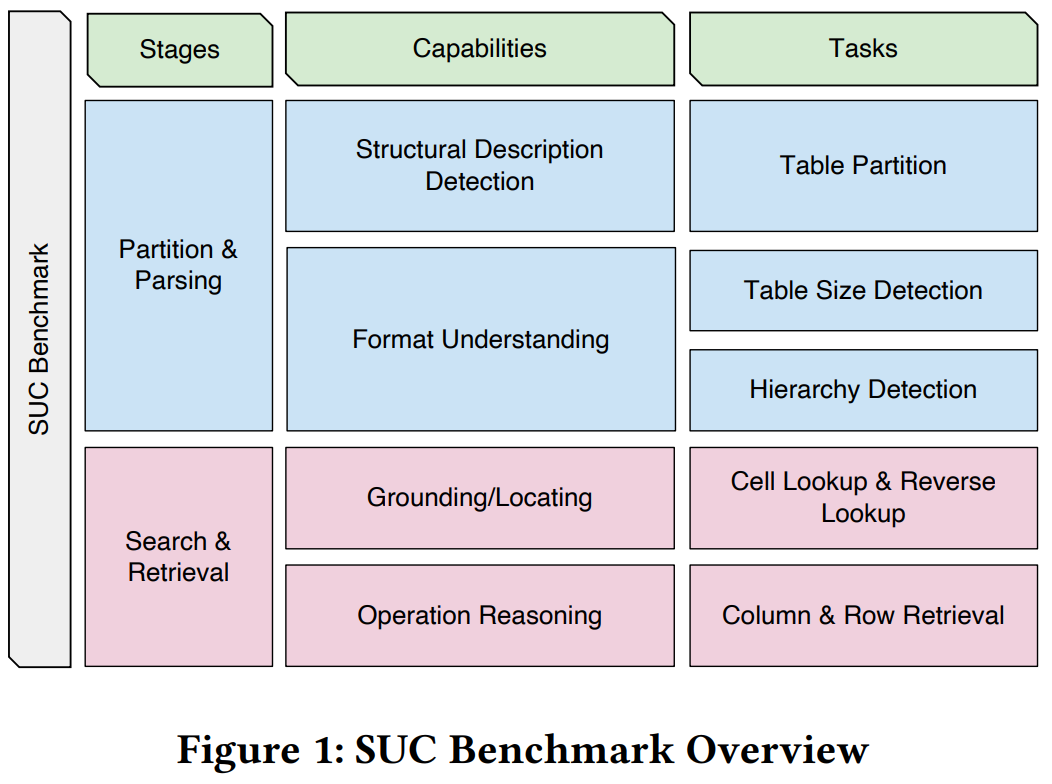
LLM은 다양한 table task를 수행하기 이전에 표의 경계를 파악하고 레이아웃을 이해하며, 구조를 분석하는 능력이 선행되어야한다. 또한, CSV, JSON, XML 등 다양한 형식의 테이블이 존재하며 이들은 정보 압축의 정도와 구조가 다르기에 이러한 형식을 이해하고 파싱하는 능력(Partition & Parsing)이 필요하다.
현재까지는 이러한 형식에 대한 영향성을 깊게 다룬 연구가 없었으며, 본 연구에서는 어떤 입력 형식이 LLM에 적합한지 분석한다.
또한, LLM이 정확한 위치에서 정보를 검색하고, 추출하는 능력(Search & Retrieval) 또한 필요하다. 이는 Table-QA, column type classification 등에서 매우 핵심적인 역할을 수행한다.
3.2 Task Design
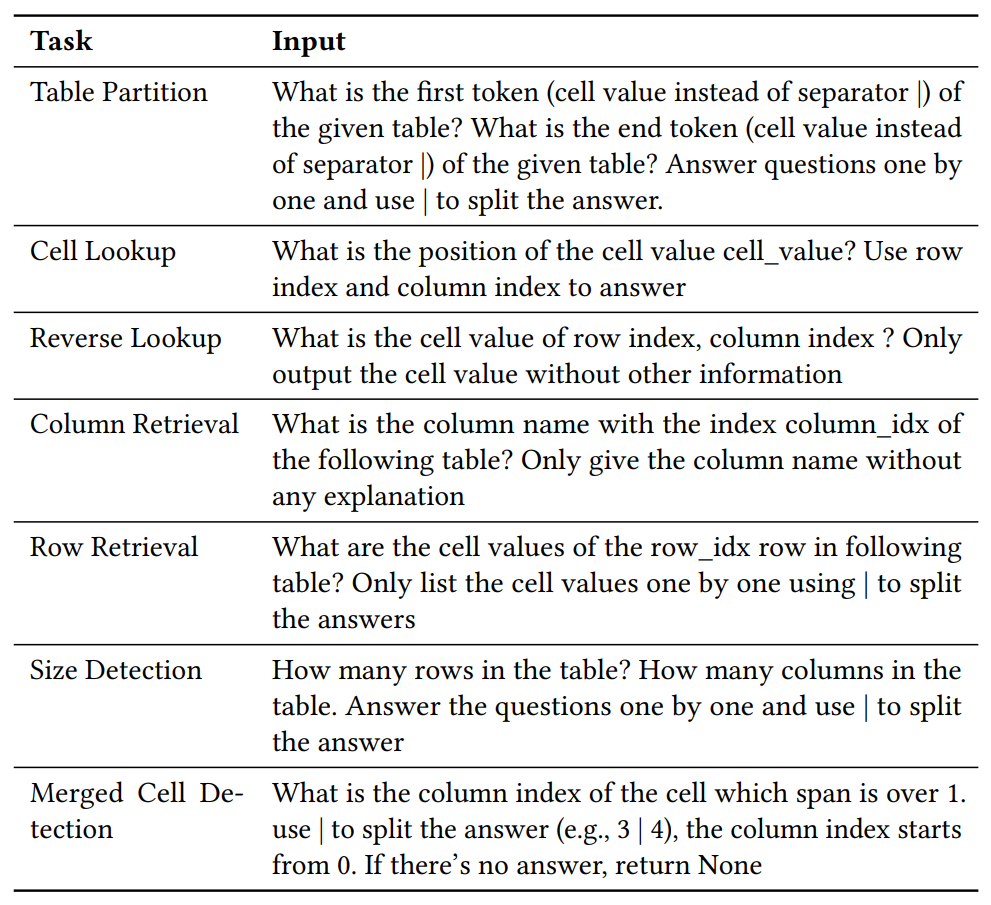
LLM이 테이블을 이해하는 능력을 평가하기 위한 다양한 과제가 존재하며, 이들은 쉬운 것부터 어려운 것까지 난이도별로 배열되어있다.
- Table Partition : 테이블의 구조를 인식하는 능력을 평가. 입력에는 설명, 문맥, 질문 등 여러 정보가 섞여 있으며 LLM은 테이블이 시작하는 위치(bn)와 끝나는 위치(be)를 정확하게 출력해야한다.
- Cell Lookup / Reverse Lookup : 특정 위치의 셀 값을 검색하거나, 반대로 특정 값을 가진 셀의 위치를 찾는 과제이다.
- Column & Row Retrieval : 특정 열과 행의 모든 셀 값을 나열하는 과제이다.
- Table Size Detection : LLM이 정답으로 (m,n)쌍을 출력하게 함으로써 테이블의 행/열 개수를 정확하게 파악 가능한지 측정한다.
- Merged Cell Detection : 테이블에서 두 개 이상의 병합된 셀 위치를 감지하는 과제로 계층 구조에 대한 인식력을 측정한다.
3.3 Data Collection and Reformatting of SUC
Table Data는 다양한 공개 데이터셋(TabFact, FEVEROUS, SQA, HybridQA, ToTTo, etc...)에서 수집하였으며 이들은 모두 Wikipedia로부터 수집된 표를 기반으로 한다.
원본 데이터셋에서 table, rows, headers 등 structural portion만 고려하고, ID, Answers, Question등 다른 메타데이터는 제외하였다.
또한, SUC는 one-shot in-context learning을 기반으로 설계되었다. 다만, 비교 실험을 위해 zero-shot 실험도 함께 수행되었다.
3.4 Evaluation
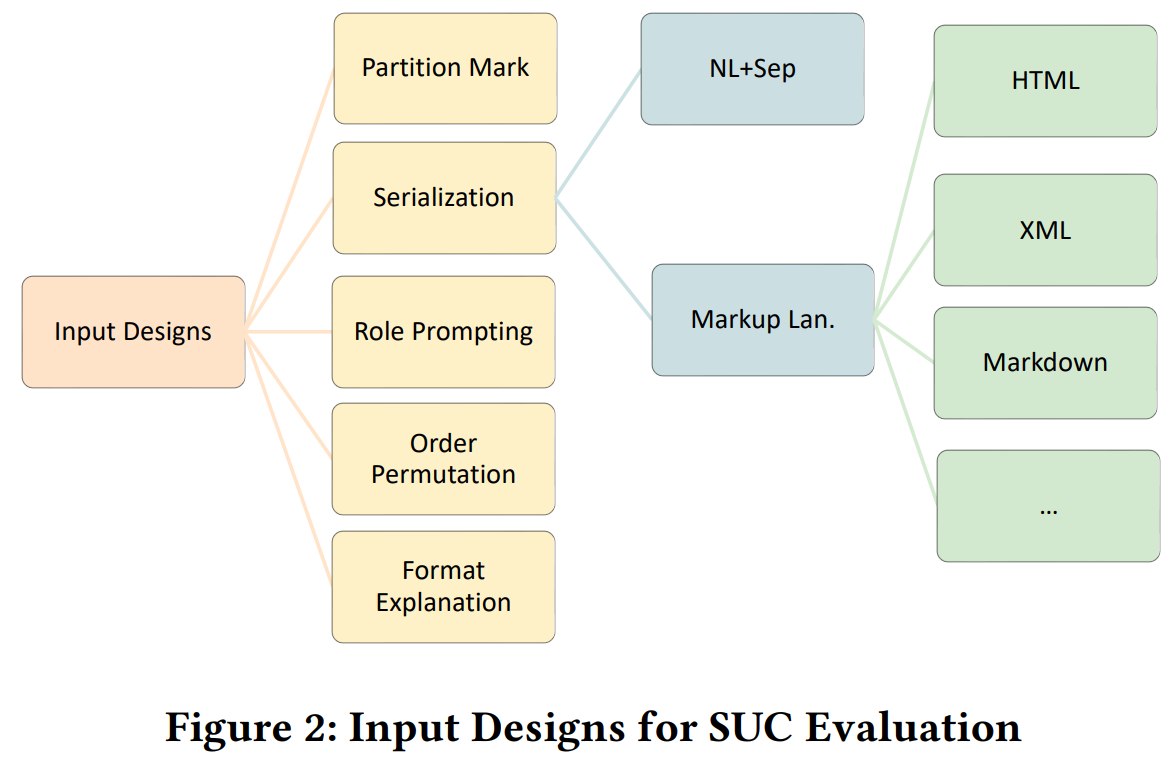
실험을 위해 일반적으로 사용되는 input design들을 활용하였으며, CSV, JSON, XML 등 다양한 테이블 형식을 고려하였다.
기본적인 베이스라인으로는 '|'와 같은 구분자를 활용해 이어 붙이는 일반적인 방식 또한 사용하였다. 이러한 형식별 비교 결과는 Table.2에 제시되어있다.
평가 지표로써 Accuracy를 사용했고, 정확한 평가를 위해 다음과 같은 출력 형식에 대한 제약 조건을 추가하였다.
"Answer questions one by one and use ’|’ to split the answer."
실험 결과 전체 중 90% 이상이 이러한 instruction을 잘 따랐으며, 나머지 10%는 REㄹ를 이용한 semantic parsing을 통해 평가히였다.
Ⅳ. Structural Prompting
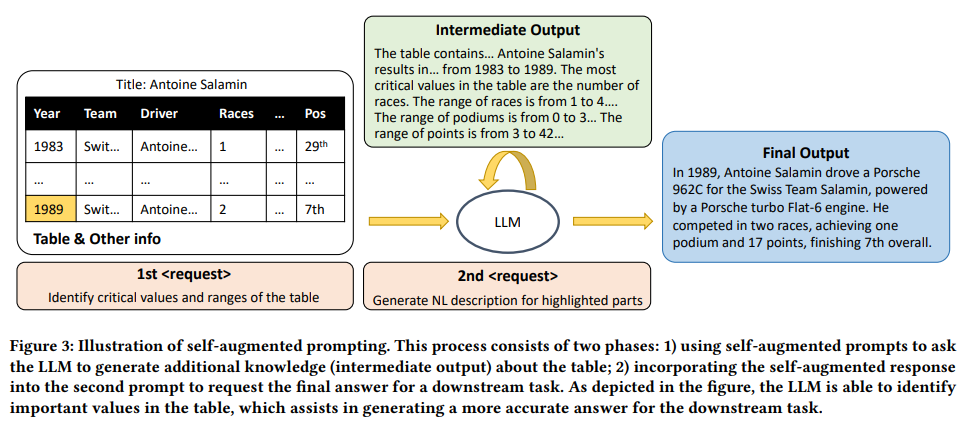
CoT는 LLM이 reasoning step을 제공하면, 그 틀에 따라 unseen task에 대해서 해당 step을 따라 과제를 해결할 수 있음을 보여주었다. 이에 영감을 받아 연구자는 self-augmented prompting이라는 방법론을 고안하였다. 이는 LLM이 내부 지식 베이스를 스스로 'retrieving'하게 하여 intermidiated structural knowledge를 생성하게 하였다. 예를 들어, LLM이 입력 형식을 직접 작성하게 하여 자신이 받아들일 패턴을 명확히 하도록 하였다. 이러한 접근은 CoT나 Zero-shot-CoT와는 달리 구조 정보를 이해하는데 필요한 잠재 능력을 'unlock'하는데 초점을 맞춘다.
이러한 방법론은 model-agnostic하므로 어떤 backbone과도 쉽게 결합되고, 타 프롬프팅 기법과도 쉽게 결합 가능하다.
Self-Augmented Prompting은 두 번의 프롬프트를 이용한다.
1차 프롬프트에서는 "Identify critical values and ranges of the table"과 같이 구조적이고 핵심적인 정보를 찾도록 요청한다. 이는 LLM이 복잡한 구조를 추론하도록 하는 Reasoning step을 이끌어낼 수 있도록 한다.
2차 프롬프트는 LLM이 생성한 intermidiate result를 원래 프롬프트 뒤에 덧붙여 생성된다. 해당 프롬프트가 LLM에 들어가 최종 답변을 생성한다.
Ⅴ. Experiments
Models : 모델은 GPT-3.5와 GPT-4를 사용. 하이퍼파라미터는 temperature=0, top_p=1, n=1로 고정됨.
Downstream Task and Datasets : Task는 SQA, HybridSQA, ToTTo, FEVEROUS, TabFact로 나누어진다.
Results
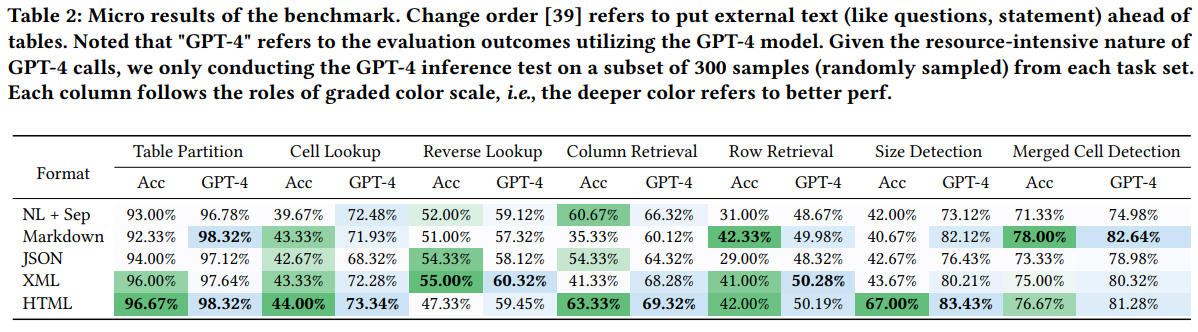
테이블이 구조를 이해하는 능력을 300개의 샘플만을 대상으로 GPT-4를 이용해 추론한 결과이다.
근데 ACC는 무슨 모델인지 명확히 안적어놨는데.. 아마 GPT-3.5지 않을까 추측된다. 전반적으로 GPT-4가 비교 대비 더 좋은 성능을 보였다.
일반적으로는 Natural Language에 구분자(Sep)을 추가하는 방식을 사용하지만, 실험 결과 HTML을 중심으로 한 Markup 언어 방식이 NL+Sep방식보다 평균적으로 높은 성능을 얻었다. 이는 LLM이 학습을 하는 과정에 code tuning이 포함되어있으며, 학습 데이터셋에 web table data가 상당히 포함되어있기 때문으로 보인다.
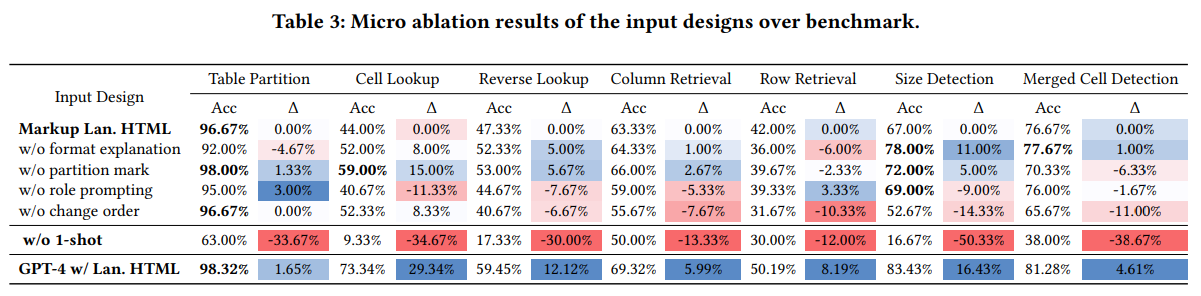
Input Data를 디자인할 때, 가장 효과적인 방식은 HTML Markup으로 테이블 데이터를 표현하고, format explanation과 role prompt를 포함하여 열과 행의 순서를 모두 유지하였을 때 전반적으로 가장 높은 정확도를 달성하였다.
0-shot 환경에서는 HTML 형식을 기준으로 했을 때, 전체 정확도가 평균 30.38%p 하락하였다. 즉, 구조 정보를 포함하기 위해서는 in-context-learning이 필수적임을 보이며 특히 Table size와 merged cell을 탐지하는 파싱 문제와 능력이 직결됨을 알 수 있다.
또한, GPT-4를 Backbone으로 사용하였을 때 모든 작업에서 큰 성능 향상을 보였다.
changing order를 통해 external text를 테이블의 뒤쪽에 놓으면 평균적으로 6.81%p의 성능 하락이 있음을 알 수 있다. 이는 외부 정보를 Table보다 앞에 두면, LLM이 구조적인 맥락을 먼저 파악하여 더 잘 일반화하는 것으로 해석된다.
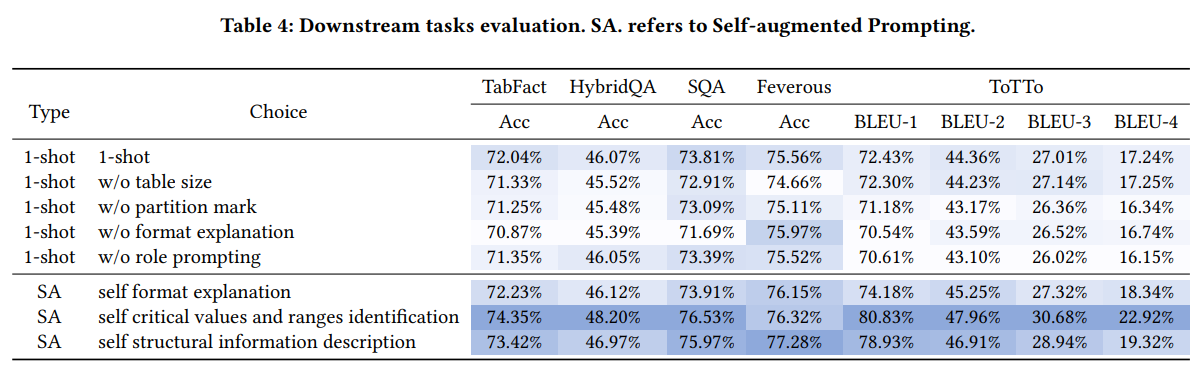
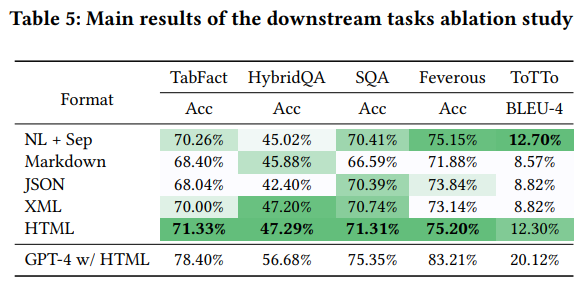
논문에서 주장하는 Self-augmented prompting 기법을 적용하였을 때의 결과이다. 주목할 만한 점은, 모델이 스스로 생성한 정보를 제공하는 SA 방식이 일반적인 1-shot 방식보다 성능이 우수하다는 점이다.
또한, 테이블 크기와 같은 구조적 특징을 명시적으로 프롬프트에 삽입하는 것 또한 모델 성능에 약간의 영향을 미친다.
1-shot w/o format explanation 행과 SA self format explanation 행을 비교하면, format에 대한 설명을 수동으로 부여하는 것이 Feverous와 같은 downstream 과제에서 부정적인 영향을 끼칠 수 있다는 점을 알 수 있다. 이는 Feverous 데이터셋의 테이블 구조가 매우 불규칙적이고, 많은 segment와 subtable을 포함하고 있기 때문이다. 즉, 모델이 스스로 생성한 설명(Self-Augmentation)이 문맥에 더 적합하고 효과적인 단서를 제공할 수 있음을 시사한다.

FEVEROUS에 대한 Format explanation의 예시이다.
Ⅵ. Related Work
최근 연구들은 LLM이 사전 튜닝 없이도 다양한 자연어 과제를 수행할 수 있는 자발적 능력(emergent capability)을 보여준다는 점에 주목하며, 특히 CoT(Chain of Thought)와 같은 중간 단계 프롬프트 기법이 큰 모델에서 추론 성능을 향상시키는 데 효과적임을 밝혔습니다. CoT의 변형인 Zero-shot-CoT는 간단한 문장을 추가해 LLM이 논리적 사고 과정을 유도하고, Self-consistency는 다수결을 통해 더 정확한 응답을 도출하며, Generated knowledge는 응답 전 배경 지식을 생성해 정답률을 높이는 방식으로 활용되고 있습니다.
Ⅶ. Conclusion
해당 논문에서는 LLM이 테이블 데이터의 구조적 정보를 얼마나 잘 이해하는지를 평가하기 위해 여러 input design을 비교하는 벤치마크를 제시하였고, LLM이 테이블 데이터에 대한 기본적인 이해는 가능하지만 그 능력이 완전하지 않음을 확인했다.
또한, LLM이 자기 지식을 활용하여 추가 정보를 생성하는 단순하지만 효과적인 방식인 Self-augmentation prompting 기법을 제안하였다.
이러한 연구가 테이블/구조화 데이터를 연구하는데 도움이 될 것이며, 테이블을 이해하는 보조적인 역할 또한 가능할 것으로 보인다.
