Zhou, Qifeng, et al. "Pathm3: A multimodal multi-task multiple instance learning framework for whole slide image classification and captioning." International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer Nature Switzerland, 2024.
https://doi.org/10.1007/978-3-031-72083-3_35
Introduction
PathM3는 WSI(Whole Slide Image)를 분류하고 캡션을 생성하기 위한 프레임워크이다.
WSI는 병리학에서 쓰이는 초고해상도(gigapixel) 이미지를 의미하는데, WSI는 이미지의 크기가 너무 커서 DNN 계열 모델에 직접적으로 넣을 수 없는 문제가 존재한다. 이 때문에 이미지를 패치 단위로 나누게 되는데, 이 과정에서 중복 및 패치 간의 상관관계 정보를 잃는 문제가 생긴다.
또한, WSI 수준의 진단 캡션 데이터가 매우 부족하므로(이는 전문 병리학자의 참여, 개인정보 보호 등에 기인한다) 그동안 멀티모달 학습에 한계가 존재하였다.
PathM3는 Multimodal(WSI + caption), multi-task(classification + captioning), mil(multiple instance learning) 기법을 융합한 프레임워크로써, WSI 이미지와 캡션을 통해 진단의 정확성을 높이고, 의학 분야의 데이터 부족 문제를 해결하는 방법론을 제시하였다.
PathM3의 주요 기여는 다음 3가지이다.
1. WSI 수준의 이미지와 caption이라는 서로 다른 모달리티의 데이터를 융합하였다.
2. 각 패치간의 중복, 상관관계를 종합하여 학습에 사용하였다.
3. 한정된 caption 데이터를 효율적으로 활용하였다.
Approach

전반적인 아키텍처는 Figure 1에 나타나있다. 한 번에 이해하려하면 조금 복잡하니 단계별로 생각해보자.

먼저, WSI 이미지는 일정 단위의 패치로 쪼개져 Image encoder에 들어간다. 이때 인코더는 frozen된 상태이며, 결과적으로 각 패치에 대한 Image Embedding들을 얻게된다.

패치들의 이미지 임베딩들은 먼저 correlation module을 거친다. correlation module은 Layer-nomalization과 Multi-head Self-Attention(MSA)을 수행하는데, 이를 통해 패치 임베딩 간의 상호 작용 및 상관관계에 대한 정보를 적용하여 임베딩을 조정할 수 있다.
WSI 이미지는 크기가 매우 크고(패치를 나누었더라도), 개수가 많으므로 MSA를 수행하는 동안 Transformer에서 Attention 연산량이 매우 커지는 문제가 발생한다.
이를 위해 Nystrom 근사를 사용하는데, Attention 연산을 저차원으로 근사하여 연산량과 사용되는 메모리를 줄인다. 이때 ^+는 Moore-Penrose pseudo-inverse를 의미한다.

준비된 이미지 임베딩과 Query Embedding, caption을 준비하여 Query-Based Transformer에 집어넣어준다.

Query-Based Transformer는 Caption input을 Query로 사용하여 이미지 임베딩과 Alignment를 시킨다. 여기서 이미지와 텍스트 임베딩 간의 Cross Attention을 계산하여 상관관계를 학습한다.

Query-Based Transformer를 거쳐 나온 output 임베딩은 Caption 생성과 Classification에 사용된다.
이후 두 가지의 Loss를 계산하는데, 하나는 분류 결과에 대한 Cross Entropy Loss(L_C), 다른 하나는 LLM이 생성한 Caption의 Generative Loss(L_G)이다. 이를 가중치(alpha) overall loss를 계산하고, Correlation module과 Query-Based Transformer의 파라미터를 업데이트한다.
Experiment
이미지 인코더의 백본으로는 ViT-g/14를, LLM 백본으로는 Flan-T5 XL를 사용하였다.

데이터셋은 PatchGastric을 사용하였는데, 이는 991개의 WSI 이미지와 Caption으로 구성된 공개 위선암 병리 데이터셋이다.
데이텃셋에는 9가지 위선암 아형이 포함되어있으나, 연구는 주요 3가지 아형에 집중하였다:
- 고분화 관상샘암(well differentiated tubular adenocarcinoma)
- 중간분화 관상샘암(moderately differentiated tubular adenocarcinoma)
- 저분화 선암(poorly differentiated adenocarcinoma)
또한, WSI이미지가 부족한 실제 환경을 반영해 데이터셋을 훈련(20%), 검증(40%), 테스트(40%)로 분할하였다.
WSI Classification

Table 1은 WSI 이미지의 분류 성능을 비교한 결과이다.
이미지만 사용하는 경우(Image only)는 현실에서 항상 caption이 주어지지 않기 때문에 고려해야하는 조건이다. PathM3는 이미지만을 단독으로 사용했을 때도 평균적으로 71.48%의 정확도를 보였으며 이는 비교 모델 대비 1.32%p - 4.81%p 높은 정확도이다.
이미지와 텍스트를 함께 사용하는 경우(Image & Text) PathM3는 평균적으로 86.40%의 정확도를 기록하였으며, 이는 비교 모델 대비 5.08%p - 5.52%p 높은 결과이다.
이는 Query-Based Transformer가 멀티모달 학습에 효과적임을 시사한다.
Captioning
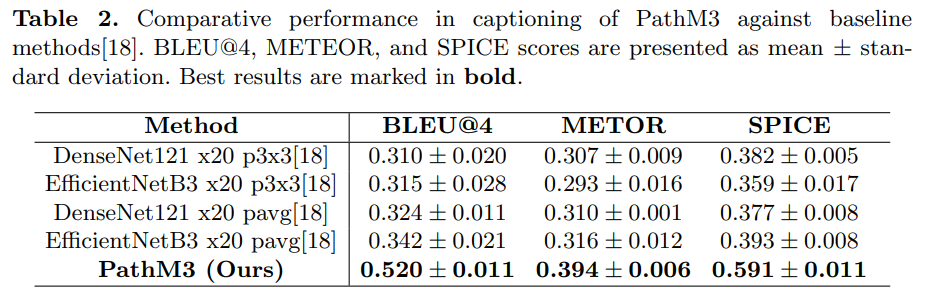
Table 2는 PathM3의 Captioning 성능을 비교한 결과이다. 최고 베이스라인 대비 성능이 모든 지표에서 일관되게 향상되었다. 이는 PathM3가 일관되고, 문맥상 정확한 캡션을 생성하였다는 것을 의미한다.
※평가 지표(Evaluation Metric)
BLEU@4: n-gram 기반 정밀도 측정, 단어 중복을 통한 평가
METOR: Alignment 기반 단어 매칭, 동의어 등 언어적 변형을 고려한 평가
SPICE: 의미론적 명제(Semantic Propositional Content) 기반 다양성 평가
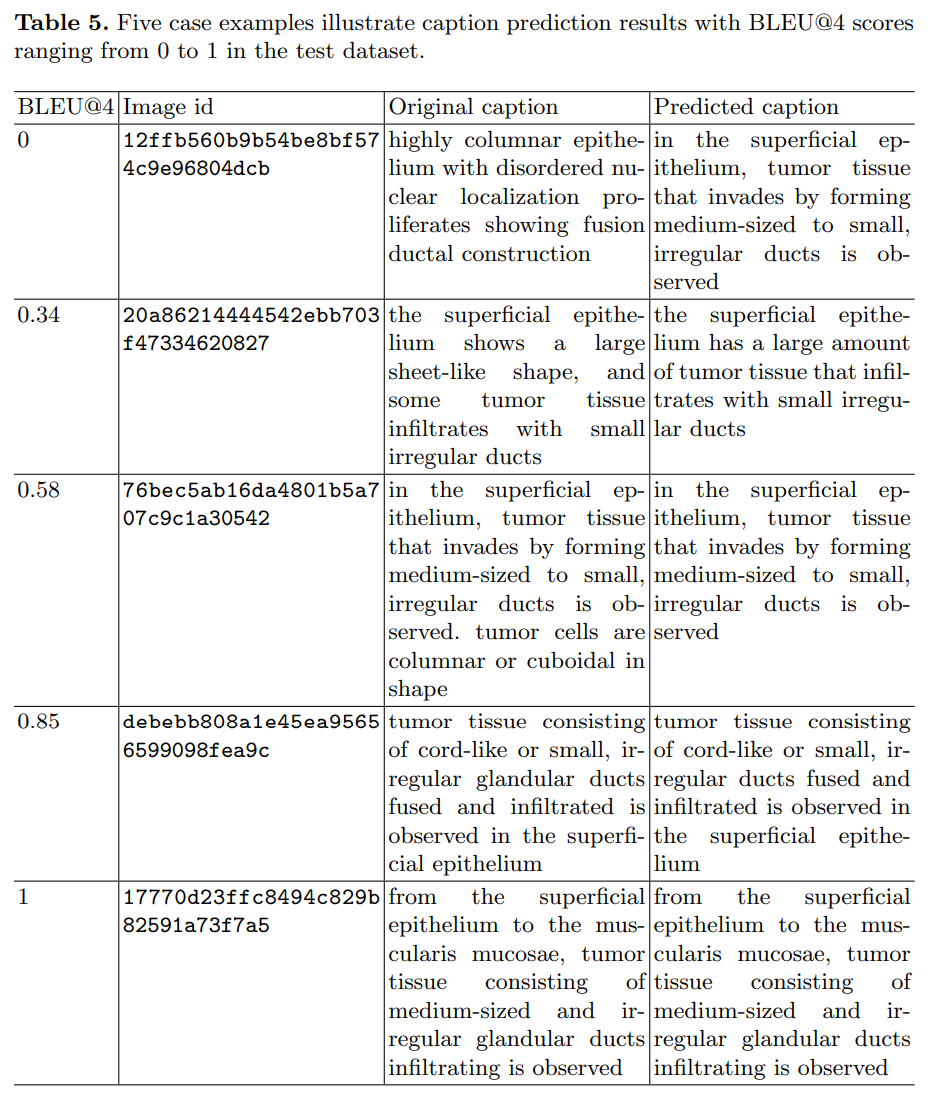
Table 5는 PathM3가 생성한 captioning의 질적 분석이다. BLEU가 늘어날 수록 원문 캡션과 거의 동일한 캡션을 생성하는데, n-gram 기반이다보니 의미론적인 부분을 평가하지는 못하고있다. 따라서 해당 결과는 참고 용도 정도로만 보면 될 듯 하다.
Ablation Study


Table 3, 4는 모두 Correlation Module과 Multi-task 에 대한 요소 제거 실험의 결과이다.
결과적으로 두 실험 모두 Correlation module을 추가하면 성능이 향상되었는데, 이는 이미지 패치 간의 상호 연관성을 학습시키는 것이 학습에 효과적임을 의미한다.
또한, 단일 작업보다 Multi-task 작업을 수행할 때 성능이 향상되는 결과를 통해 다양한 태스크 간의 학습이 상호 간의 성능을 보완해주었다는 것을 알 수 있다.
Conclusion
연구자들은 병리 이미지 분석을 위한 Multimodal, Multi-task, Multi Instance Learning 프레임워크인 PathM3를 제안하였다.
PathM3는 WSI와 진단 캡션 간의 정렬을 달성하였으며, 제한된 caption만을 활용하여 성능을 향상시켰다. 또한, 멀티모달 데이터의 통합을 통해 분류와 캡션 생성의 성능을 향상시켰다.
결과적으로 PathM3는 딥러닝 모델과 전문가의 caption 생성을 통합하는 가능성을 제시하며, 데이터의 효율성과 해석 가능성, 성능적 측면에서 우수한 결과를 제시하였다.
