Italiano, Davide, and Chris Cummins. "Finding missed code size optimizations in compilers using llms." arXiv preprint arXiv:2501.0065
https://doi.org/10.48550/arXiv.2501.00655
Introduction
컴파일러를 Testing하거나, Fuzzing하는 연구는 그 간 꾸준히 진행되어왔다. 일반적인 방법은 random program을 생성하여 컴파일러에 입력하고, differential testing 기법을 이용하여 생성된 바이너리 코드를 검증하는 것이다.
그러나, random program을 만드는 것은 별도의 생성기를 개발해야하며, 새로운 기능의 추가, 유지 및 보수 등 복잡한 소프트웨어 작업이다. 또한, random program으로 만들어진 테스트 케이스는 매우 크고 복잡하여 readability가 떨어지고, 개발자에게 보고하기 위해서는 프로그램 축소가 필요하다. 예를 들어, C에서는 C-Reduce(Regehr et al., 2012) 같은 추가적인 도구가 필요하다.
대안으로, mutation testing은 seed 코드 하나를 입력받아, 코드의 일부를 수정하는 방식이다. 예를 들어, 특정 입력에서 실행되지 않는 코드 부분을 변이시키는 방식이다(Le et al., 2014). 그러나, 이 역시 대상 언어에 대한 깊은 이해와 분석 능력을 필요로 한다.
이에 따라 연구자들은 'code size optimization'에 대한 컴파일러 테스트 케이스를 LLM을 통해 자동적으로 생성하는 연구를 진행하였다.
코드의 크기를 최적화 하는 전략은 임베디드, 모바일, 펌웨어 및 소프트웨어 등에 필수적이며 최근에도 활발하게 연구되는 분야이다(Hoag et al., 2024; Lee et al., 2024, 2022).
즉, 해당 연구는 다음과 같은 기여를 한다.
- LLM을 사용해 seed code를 반복적으로 수정하는 새로운 테스트 방법론 제안
- 코드 크기 최적화에 실패하는 사례를 찾기 위한 네 가지 테스트 전략 개발
- 150줄 이하의 간단한 코드 구현만으로 가능한 테스트 도구 제작
- 해당 도구를 오픈 소스로 공개
Approach
Methodology

Figure 1은 연구자들이 제안하는 접근법의 간단한 예시이다.
먼저, LLM에게 미리 정해둔 instruction들 중 하나를 무작위로 선택하여 프로그램을 점진적으로 변이(mutate)시킨다. 그리고, 각 변이 단계마다 differential testing을 이용하여 놓친 최적화(missed optimization)이 있는지 탐지한다.
Figure 1의 예시에서는 1분의 연산 시간 동안 코드 크기가 36% 증가한 회귀(regression)를 발견하였다.
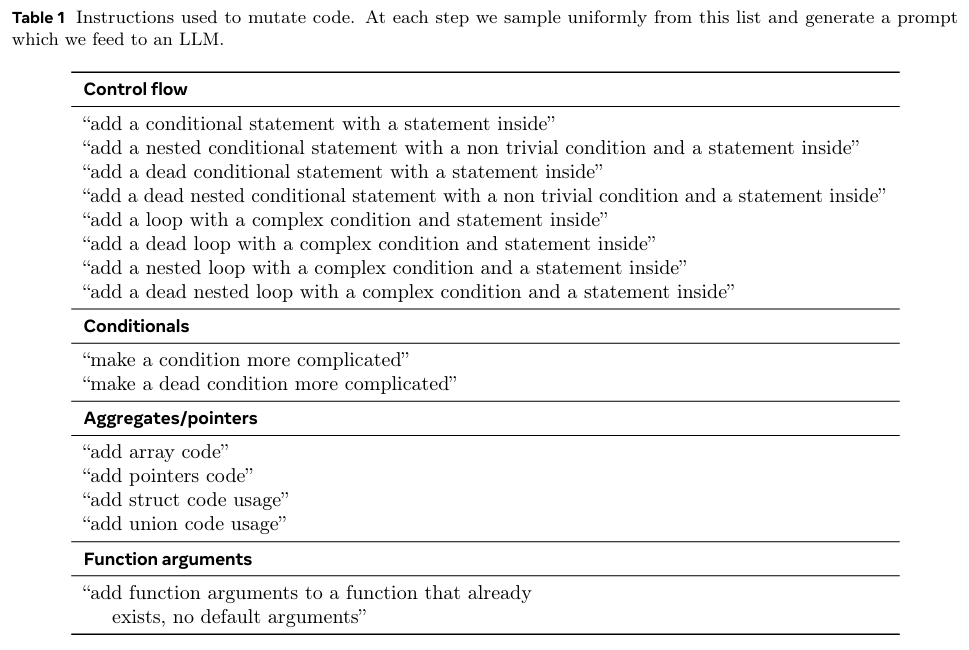
Table 1은 mutation을 위한 instruction 목록을 보여준다. Figure 1의 각 단계에서 이 목록에서 균등하게 샘플링하여 LLM에 전달할 프롬프트(prompt)를 생성한다. 이러한 명령어(프롬프트)는 필요에 따라 특정 도메인에 맞게 추가적인 조정이 가능하다.
-
Control flow (제어 흐름)
: 조건문 추가, 중첩 조건문 추가, 죽은(dead) 조건문 추가, 반복문 추가 등 -
Conditionals (조건식)
: 조건을 더 복잡하게 만들기, 죽은 조건을 더 복잡하게 만들기 -
Aggregates/pointers (집합/포인터)
: 배열, 포인터, 구조체, 유니언 사용 코드 추가 -
Function arguments (함수 인자)
: 이미 존재하는 함수에 기본값 없는 인자 추가
이러한 코드 변형은 dead code(사용하지 않는 코드)와 live code(실행되는 코드)로 나뉜다.
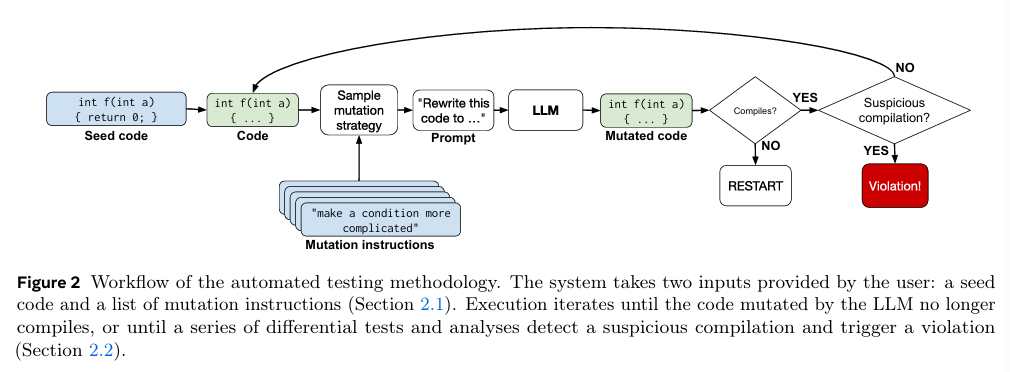
Figure 2는 제안 기법의 워크플로우를 나타낸다. 간단히 요약해보면,
1. Seed code와 mutation instruction들을 입력.
2. LLM이 seed code를 바탕으로 mutated code를 생성
3. compile 및 differential test 수행
4. 위반 사항(violation) 발생 시 종료
와 같은 과정을 거친다.

Listing 1은 Seed program의 예시를 나타낸다. 이는 LLM 기반 코드 변이 테스트의 출발점으로써 활요되는데, 각 언어별로 하나의 비어있는 함수(function)만 있는 매우 단순한 코드이다. LLM은 이를 시작으로 점진적인 변이를 수행한다.

Listing 2는 각 단계에서 LLM이 어떤 변이를 수행할지 지시하는 프롬프트의 템플릿 예시를 나타낸다. 각 단계마다 프롬프트를 만들어 LLM에 전달하고, LLM은 이 프롬프트를 통해 코드를 변형한 결과를 반환한다.
- language: 현재 언어 (C/C++, Rust, Swift 등)
- instruction: 변이 지침 (예: 조건문 추가, 배열 코드 추가 등)
- code: 현재 변이된 코드 상태
Diffrential testing strategies
1) Dead code diffrential testing
seed code는 상수 값을 계산하기 때문에, dead code를 추가하더라도 프로그램의 semantic적인 부분은 변하지 않아야 한다. dead code에 대한 테스트를 위해 LLM에게 dead code에 대한 변형만을 지시하고, 나머지 변형은 비활성화한다.
만약 코드를 recompile하고 생성된 코드가 변경되면, 컴파일러가 dead code임을 증명하지 못하였음을 의미하므로 위반으로 판단한다.
2) Optimization pipeline differential testing
최적화 파이프라인이 코드 크기를 최소화 하기 위해 특정 요소를 희생할 수도 있다. 예를 들어, LLVM/GCC에서는 -Oz, Rust에서는 opt-level=z로 코드 크기를 최소화 한다.
따라서 동일한 컴파일러로 다른 최적화 수준(ex. -03)의 코드와 비교하고, 코드 크기가 예상보다 작다면 위반으로 판단한다.
3) Single-compiler differential testing
동일한 컴파일러의 다른 버전 간 생성 코드를 비교한다. 이는 코드 크기의 최적화가 개선되거나, 후퇴한 경우를 찾는데 목적이 있다.
공개된 버전과 최신 개발 버전을 비교하여 코드 크기가 후퇴하면 위반으로 판단한다.
4) Multi-compiler differential testing
가능한 경우, 여러 다른 컴파일러 간의 생성 코드를 비교한다.
코드 크기가 충분히(±10%) 다르다면 더 큰 크기의 컴파일러를 위반으로 판단한다.
Detecting false positives
LLM이 생성한 코드에 오류가 있을 가능성이 존재하므로, 이를 최소화하기 위해 연구자들은 아래 3가지 전략을 사용한다.
-
Dead code detection:
LLM이 실제로 dead code만 생성했는지 확인한다. 함수의 시그니처(f())를 제어하고, main에서 호출하여 실행 한 뒤, counter의 값을 비교한다. -
Sanitization:
메모리 위반이나 정의되지 않은 동작(UB)을 감지하기 위해 sanitizers 사용한다. 실험 결과, 후보 중 10% 미만만 거부가 발생하였다. -
Monotonically increasing size:
반복 변형 테스트에서 undefined behavior가 있는 경우, 컴파일러는 코드를 제거하는 경향이 있으므로, 코드 크기를 복잡성의 지표로 사용한다.
Detecting duplicates
테스트 케이스 생성 시, 동일한 버그를 가진 여러 테스트 케이스가 존재할 수 있다. 이를 줄이기 위해 연구자들은 아래 2가지 전략을 사용하였다.
-
Release screening:
공개된 컴파일러 버전으로 컴파일 후, 버그가 나타나는 버전의 집합을 비교한다. 버그가 나타나는 버전의 집합 간의 겹침은 허용하되, 완전히 동일하지 않다면 서로 다른 두 버그로 간주한다. -
Commit screening/bisection:
회귀의 경우 오류가 발생하지 않는 “known working version of the compiler”이 존재할 수 있다. 이를 이용하여 이분 탐색을 수행하고, 위반을 최초로 발생시킨 커밋을 찾아낸다.
만약 새로운 동작을 유발하는 커밋이 두 다른 프로그램에서 다르다면, 이는 높은 확률로 서로 다른 버그임을 암시한다.
Experiments
Finding bugs in C/C++ compilers
C/C++ 컴파일러에서 제안 기법(Itertative Mutation Testing) 기법의 효과를 평가하였다. LLM Backbone은 Llama 3.1(70B, 405B)이며, 각각 8시간씩 실행하였다.
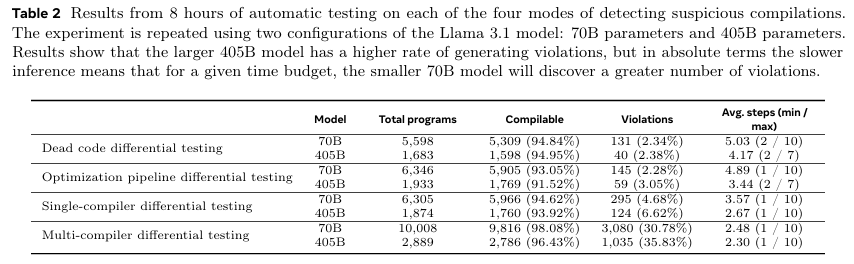

Total programs는 생성된 전체 프로그램의 개수, Compilable은 컴파일 오류 없이 성공한 프로그램의 수, Violations는 differential testing에 잡힌 위반의 수, Avg. steps는 한 에피소드(seed code ~ violation 발견)에서의 평균 변이 횟수를 의미한다.
Table 2를 보면 우선, 70B 모델의 응답 생성 속도가 훨씬 빠르기에(Table 3 참조) 405B 모델보다 훨씬 많은 프로그램 변이를 생성하였다는 점을 알 수 있다. Violation rate는 405B가, number는 70B가 많은 점 또한 이에 기인한다.
결과적으로는 Multi-compiler differential testing이 오류 탐지에 가장 강력하였다.
참고로, 연구자들은 8B 모델도 실험하였으나 Syntax/Semantic 오류가 매우 많아 폐기하였다고 언급하였다.
Conclusion for C/C++
ⅰ) Dead code differential testing을 통해 찾은 버그
 Listing 3: GCC bug 116753
Listing 3: GCC bug 116753
특정 dead condition이 추가되면 GCC의 -Os 최적화 파이프라인이 루프가 상수로 평가되는 사실을 더 이상 잡아내지 못하였다. 과거 GCC (12.4.0)에서는 잘 동작했는데, 최근 value-range analysis 인프라 개편 후 최적화에 실패하였다.
 Listing 4: LLVMbug 112080
Listing 4: LLVMbug 112080
ConstraintElimination pass가 내부 루프가 죽은 루프(dead loop)임을 발견하지 못하였다. 저자들이 이를 LLVM 개발자에게 보고하여 패치하였다.
ⅱ) Optimization pipeline differential testing을 통해 찾은 버그
 Listing 5: LLVM bug 111571
Listing 5: LLVM bug 111571
-O3버전에서는 루프가 unroll되었으며, dead store elimination으로 상수 최적화에 성공하였지만, -Oz버전에서는 루프 unroll을 하지 않았기에 코드 크기가 증가하였다.
 Listing 6: GCC bug 117033
Listing 6: GCC bug 117033
-Oz 버전에서 -Os보다 더 큰 크기의 코드를 생성하였다. 특히, -O3에서는 constant folding에 성공하였지만, -Os에서는 루프가 남았다. 이는 파이프라인의 일관성 문제를 의미한다.
ⅲ) Single-compiler differential testing을 통해 찾은 버그
 Listing 7: GCC bug 117123
Listing 7: GCC bug 117123
GCC 13.3과 GCC trunk를 비교하였을 때 -Os 코드의 크기에서 regression이 발생하였다. 이는 GCC 14에서 추가된 sccopy pass가 PHI 노드 값의 번호를 매길 때 동등성(equivalence)를 놓쳤기 때문이다.
 Listing 8: GCC bug 117128
Listing 8: GCC bug 117128
GCC trunk와 GCC 14를 비교하였을 때, -Os 코드 크기에 regression이 발생하였다. 이는 register allocation shrink-wrapping이 -Os에서 불필요하게 적용되어 코드의 크기가 증가한 것에 기인한다.
ⅳ) Multi-compiler differential testing을 통해 찾은 버그
 Listing 9: GCC bug 116868함수가 상수 백터임을 증명하지 못하여 최적화에 실패하였다. 이는 GCC는 operator new 호출이 전역 메모리에 side-effect가 없는지 증명하지 못하는 것에 기인한다. Clang은 최적화에 성공하였으며, GCC는 이후 이 지원을 추가하여 버그를 수정하였다.
Listing 9: GCC bug 116868함수가 상수 백터임을 증명하지 못하여 최적화에 실패하였다. 이는 GCC는 operator new 호출이 전역 메모리에 side-effect가 없는지 증명하지 못하는 것에 기인한다. Clang은 최적화에 성공하였으며, GCC는 이후 이 지원을 추가하여 버그를 수정하였다.
ⅴ) LLM code mutation 실패 사례

LLM이 syntax는 올바르게 컴파일 가능한 코드이나, 의도하지 않거나 잘못된 semantic을 가진 코드를 생성하는 경우가 있었다.
가장 잦은 경우는 LLM이 "dead code"의 의미를 단순히 "code that does nothing"로 오해하는 것이였다.
이렇게 잘못된 케이스들은 동적 명령어 카운트(dynamic instruction counts, Sec 2.3)를 이용해 걸러냈다.
Extending to other lanuages
제안 기법은 LLM과 automatic validation tool을 사용하기 때문에 다양한 언어로 확장하기가 용이하다. 연구자들은 제안 기법의 확장성을 평가하기 위해, C/C++ 테스트용 150 line의 스크립트를 Rust와 Swift로 포팅하였다.
다른 언어에 adaptation 시키는 것은 컴파일러 호출 부분과, seed program만 변경해주면 되기에 매우 간단한 작업이다.
이때 연구자들이 Rust와 Swift를 대상으로 한 이유는 두 언어가 비교적 신생 언어이고, 무작위 테스트 케이스 생성을 위한 기존 인프라가 부족하기 때문이다.
Conclusion for Rust/Swift
 Listing 11: Rust bug 130421
Listing 11: Rust bug 130421
Rust 컴파일러가 중첩 루프를 완전히 단순화하지 못하였다. 루프를 unroll 시켜야 합이 상수임을 알 수 있는데, 부분 전개만 한 후 vectorization을 적용하여 코드의 크기가 커지고 실행 속도도 느려졌다.
 Listing 12: Swift bug 76535
Listing 12: Swift bug 76535
Swift 컴파일러가 최적화 파이프라인(-Osize, -O)에서 중첩된 while 루프가 dead code임을 판별하지 못하였다.
루프가 실행되지 못함에도 컴파일러는 이를 제거하지 못하였으며, 연구자들은 Swift에 SIL(Swift Intermediate Language) 단계에서 범위 분석(range analysis) 매커니즘을 적용하엿다면 이를 제거할 수 있었을 것이라 언급하였다.
 Listing 13: Rust bug 132888
Listing 13: Rust bug 132888
특정 코드를 Rust nightly로 컴파일하면 Rust 1.81.0보다 더 큰 바이너리가 생성되는데, 이는 컴파일러의 backend가 비효율적인 명령어 시퀀스를 선택함에 기인한다.
 Listing 14: Rust bug 132890
Listing 14: Rust bug 132890
단순한 배열 iteration 코드가 Rust nightly에서 Rust 1.73.0보다 더 큰 바이너리를 만드는 경우가 존재했다. 이 또한, 컴파일러의 backend가 비효율적인 명령어 시퀀스를 선택함에 기인하였다.
Conclusion
연구자들은 LLM을 활용하여 컴파일러가 놓친 code size optimization 케이스를 식별하기 위한 방법론을 제시하였다.
제안 기법은 기존의 LLM과 소프트웨어 검증 도구를 결합함으로써 효과적이고, 매우 단순하였다. 또한, 이를 통해 실제 컴파일러에서 총 24가지의 버그를 발견하였다.
연구자들은 Future works로써 diffrential testing 기법을 확장하여 실행 성능 최적화에서의 누락을 탐지하고,프롬프트 엔지니어링을 통해 효과를 개선하며, 더 큰 시드 코드에 대한 변이를 시도할 계획이다.
