이전에 AWS S3를 이용해 이미지 업로드 기능을 구현했었는데, 개선해야 할 일이 생겨 이참에 흐름과 개념을 조금이나마 정리해보려고 한다.
S3란?
AWS에서 제공하는 S3는 Simple Storage Service의 약어로 다양한 객체를 저장할 수 있는 서비스다.
다양한 객체라 하면, 텍스트 파일부터 로그, DB 스냅샷, PDF, 멀티미디어 파일 등을 말한다.
전에 CI/CD를 구성하는 데에도 S3를 사용했는데, 이때 S3에 저장한 객체는 Jar 파일이었다. 이처럼 이미지에 국한되지 않고 정말 다양한 파일들을 S3에 저장할 수 있다.
여기서는 이미지 업로드에 대해 다루므로, 단순히 JPG나 PNG 등 이미지 파일을 클라우드 스토리지에 저장할 수 있는 서비스라고 생각하면 된다.
아키텍처 구성
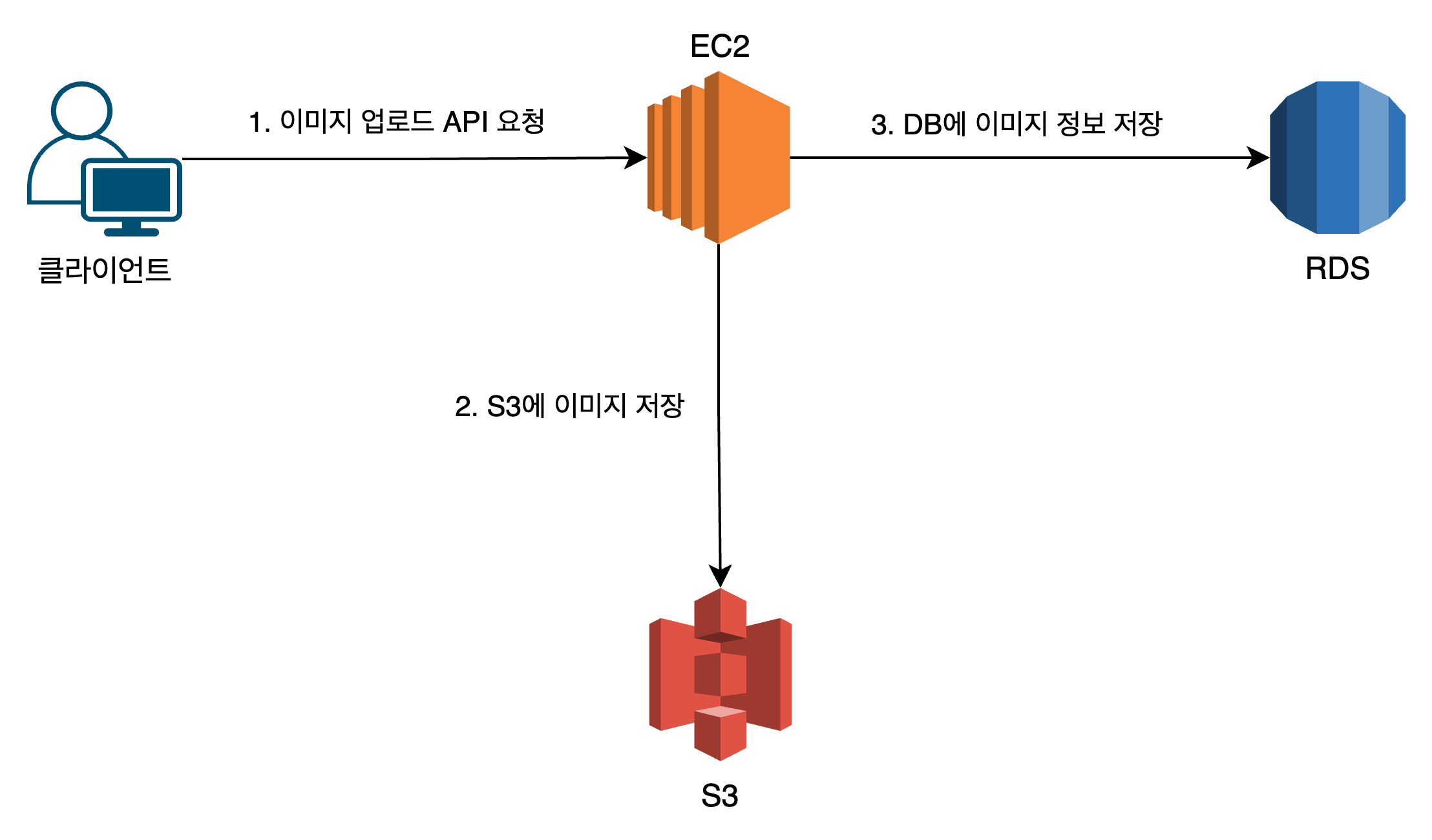
S3를 사용하여 이미지 업로드 기능을 구현했을 때 서비스의 아키텍처 구성은 대략 다음과 같다.
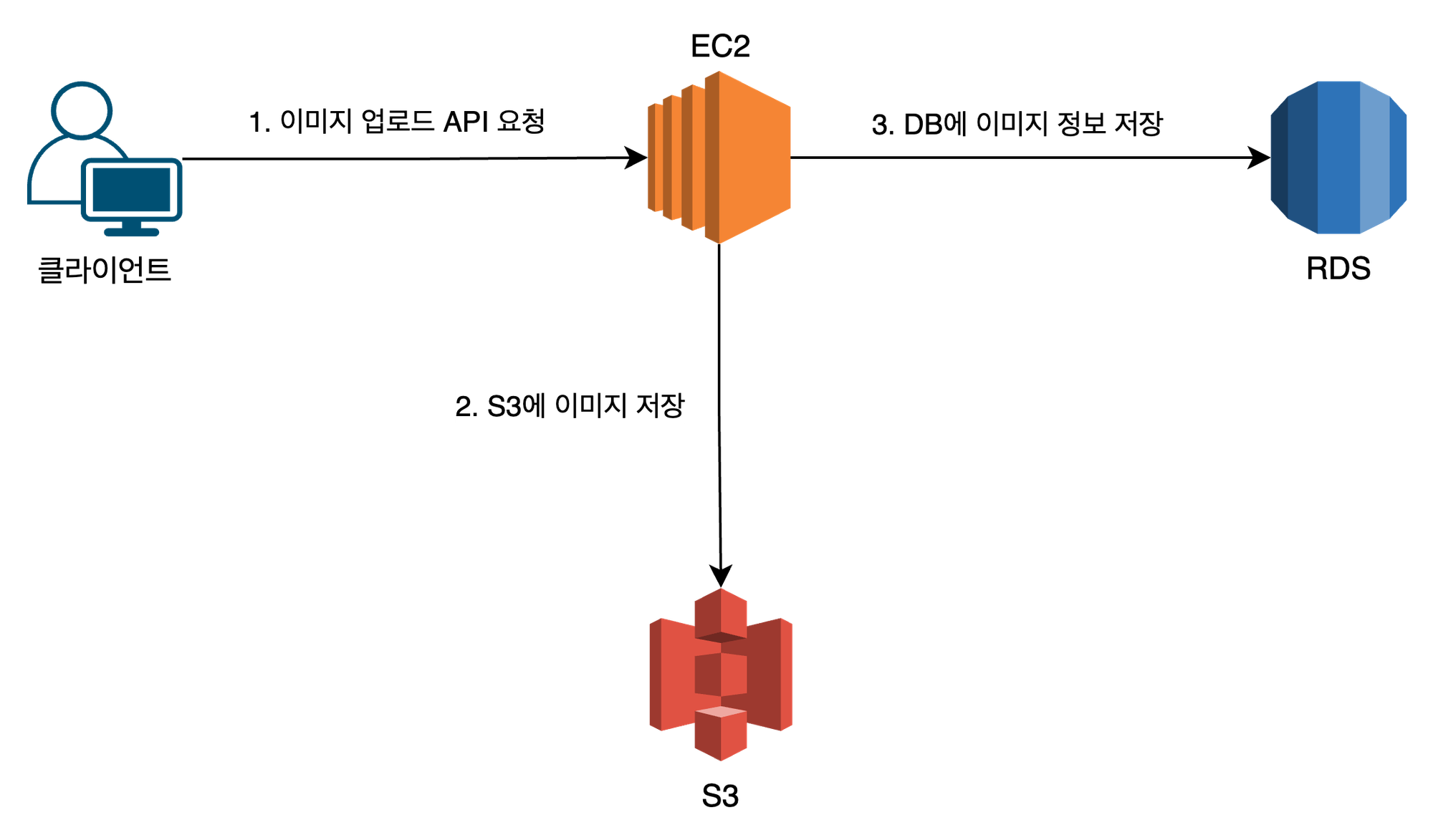
클라이언트에서 이미지 업로드 API를 요청하면, 이미지 파일을 S3에 저장함과 동시에 DB에는 해당 이미지의 메타 데이터(크기, 경로 등)를 저장한다.
DB에 이미지 파일을 바로 저장하면 되지 않나?
물론 BLOB이라는 데이터 타입을 이용해 이미지 파일을 이진 데이터 형태로 DB에 저장할 수 있다. (다른 여러 방식도 존재함)
하지만 이미지의 이진 데이터는 생각보다 DB의 용량을 많이 잡아 먹으며, 성능에도 많은 영향을 끼친다. 이는 곧 처리 비용이 증가하는 문제로 이어진다.
따라서 이미지 파일 자체는 S3에 저장하고, DB에는 이미지의 메타 데이터만 저장하여 안정성을 취하는 것이다.
AWS S3 버킷 생성
S3에서는 여러 저장소를 만들 수 있는데, 각각의 저장소를 버킷(Bucket)이라고 부른다.
버킷은 AWS S3에서 쉽게 생성할 수 있다.
우선 버킷 이름은 원하는대로 지정하고, 나머지는 기본 선택된 내용 그대로 두면 된다.
보안을 위해 모든 퍼블릭 액세스는 차단하는 것이 좋지만, 실제 운영하는 서비스가 아니라면 당장은 넘어가도 괜찮을 듯 싶다. (나중에 다시 차단할 수 있으니 걱정 안해도 될 것 같다)
태그와 기본 암호화도 기본 설정 그대로 두자.
IAM 사용자 생성
외부에서 AWS 리소스에 접근하기 위해서는 액세스 키가 필요하며, 이는 IAM에서 발급 받을 수 있다.
우선 액세스 키를 발급 받을 사용자를 생성해보자.

IAM의 사용자 탭에서 사용자를 생성할 수 있으며, 아래 과정을 따라가면 쉽게 생성할 수 있다.
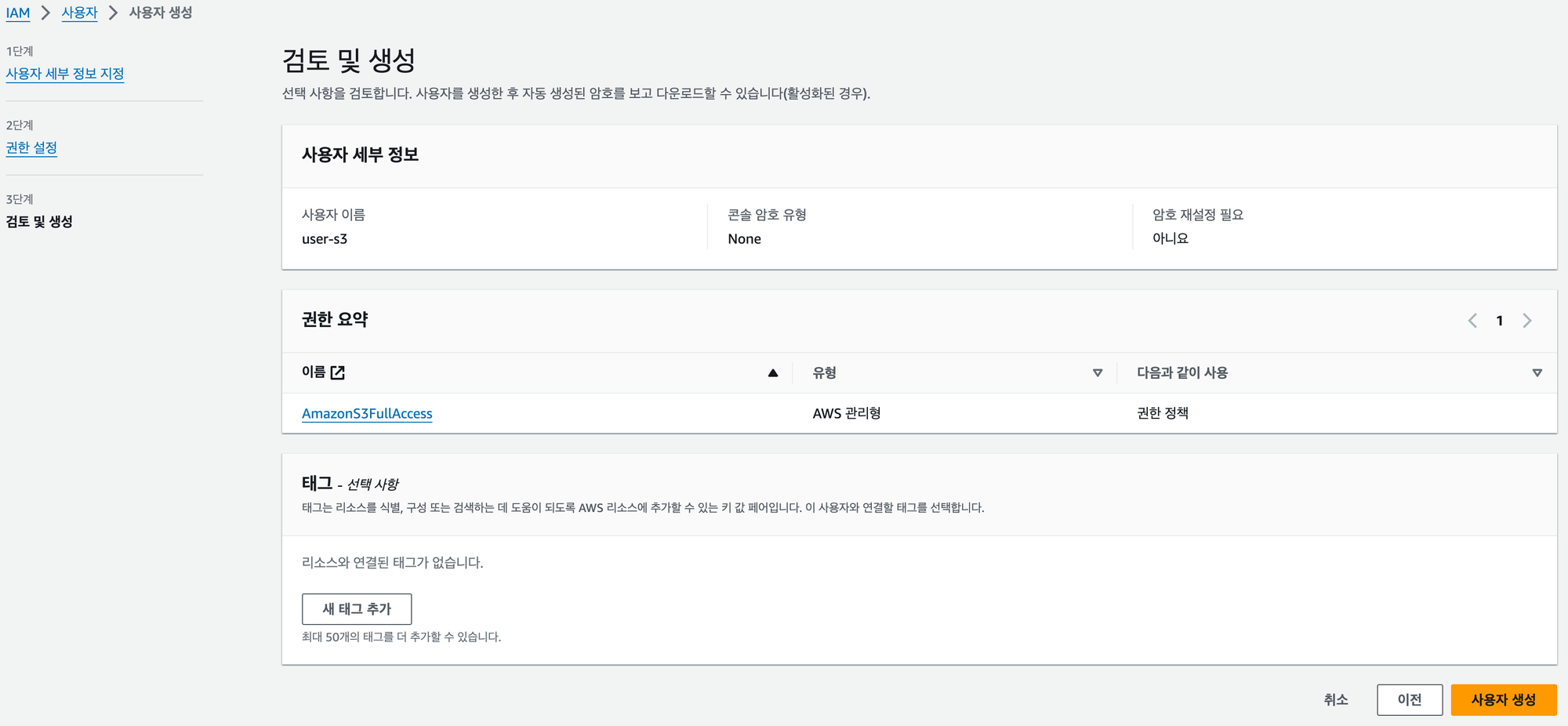
액세스 키 발급
S3에 접근할 사용자를 생성했다면, 이제 해당 사용자를 증명할 수 있는 액세스 키를 생성해야 한다.
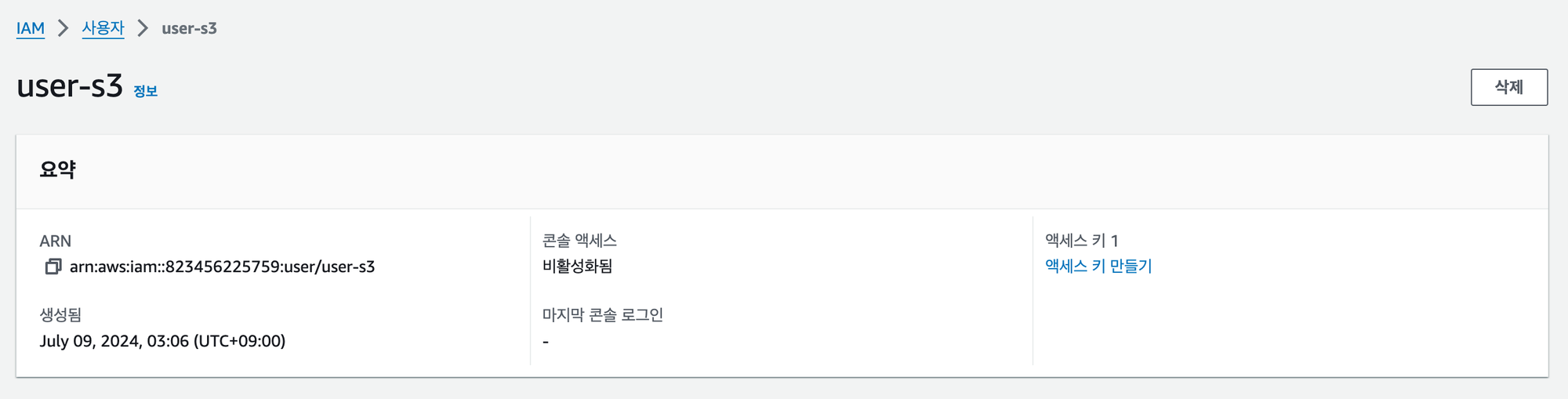
방금 생성한 사용자를 클릭하여 들어오면 사진과 같이 ‘액세스 키 만들기’라는 버튼이 있을텐데, 이를 클릭하여 아래 과정을 따라가면 액세스 키를 발급 받을 수 있다.
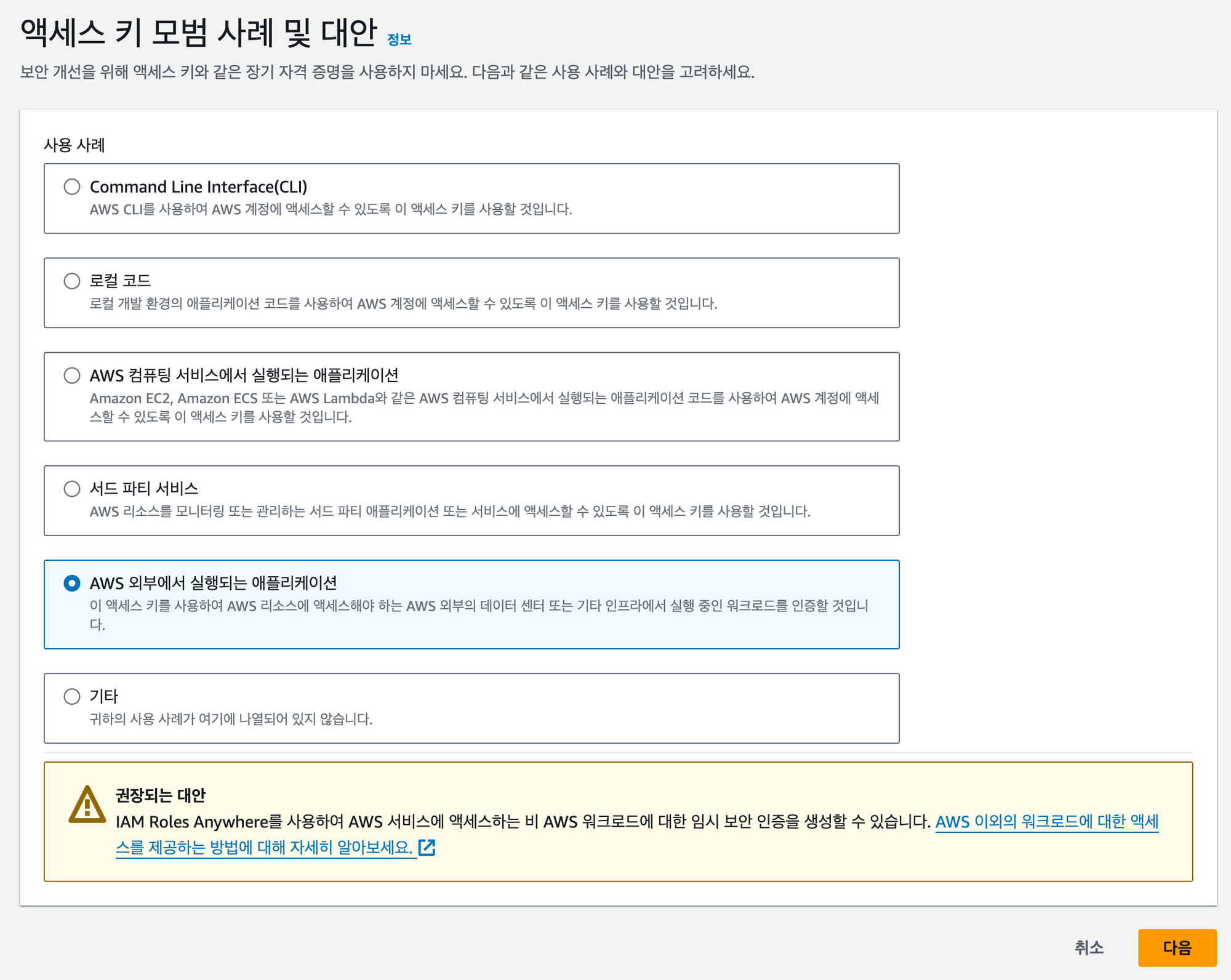

(태그는 비워놔도 상관 없다)
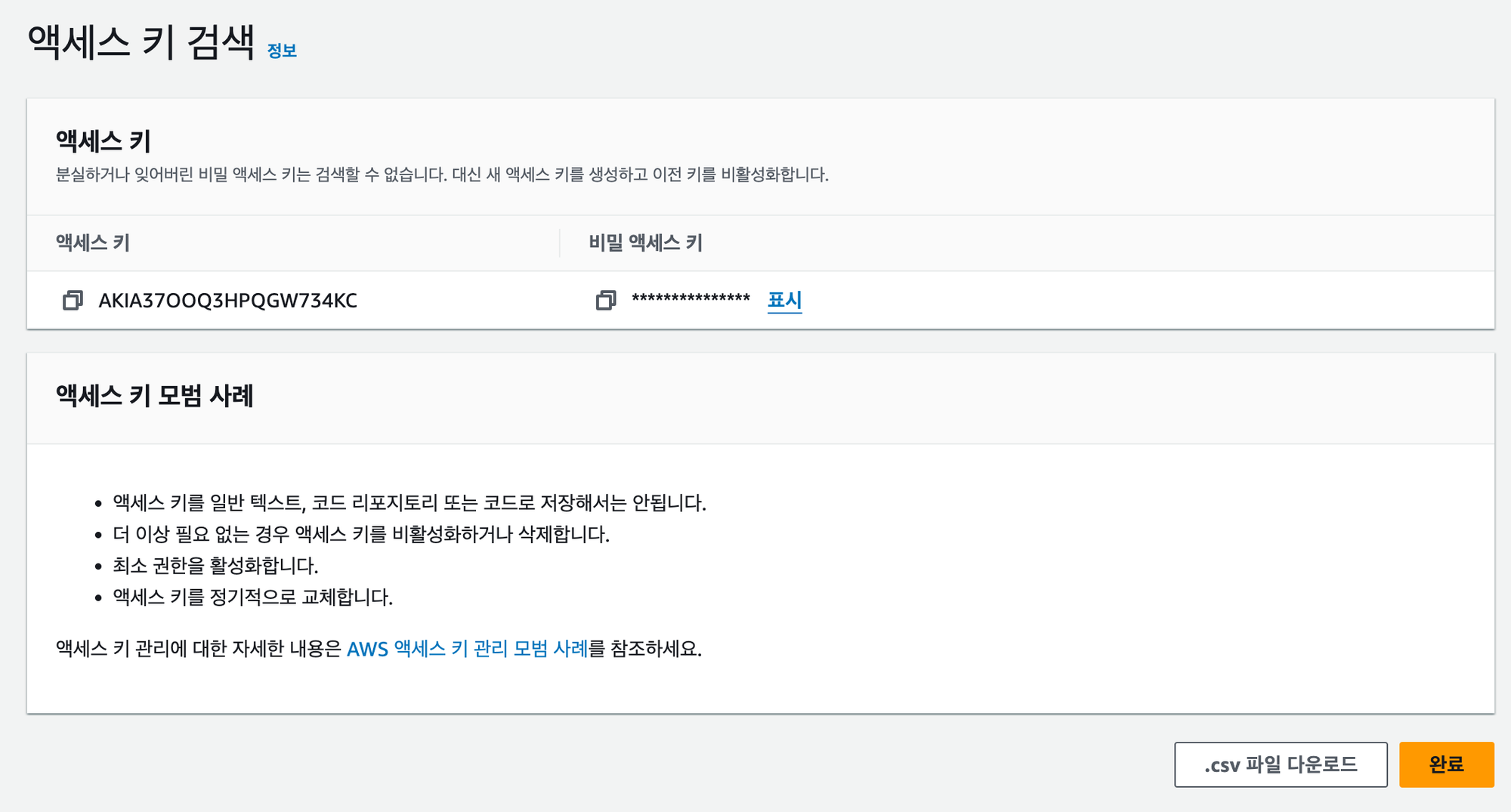
‘액세스 키 만들기’ 버튼까지 클릭하면 다음과 같이 액세스 키와 비밀 액세스 키가 나오는데, 비밀 액세스 키의 경우 지금 아니면 다시는 볼 수 없으니 어딘가에 잘 보관해놔야 한다.
S3에 접근하기 위한 라이브러리
이제 우리 애플리케이션이 발급받은 액세스 키를 통해 S3 버킷에 접근할 수 있도록 라이브러리를 추가해야 한다.
이러한 라이브러리는 (내가 알아본 바로는) 2개가 존재하는데, AWS SDK for Java와 Spring Cloud AWS다.
AWS SDK for Java
AWS SDK for Java는 AWS에서 제공하는 라이브러리로, Java 기반 애플리케이션에서 S3를 비롯한 여러 AWS 서비스를 쉽게 사용할 수 있도록 API를 지원한다.
다른 라이브러리나 프레임워크와 독립적으로 사용할 수 있으며, 비동기 호출, 스트리밍 처리 등 풍부한 기능을 제공하여 좀 더 세밀한 제어가 가능하다. (물론 나는 이러한 고급 기능을 다루지는 않아 잘 모르겠다)
Spring Cloud AWS
Spring Cloud AWS는 Spring 애플리케이션에서 AWS 서비스를 쉽게 사용할 수 있도록 해주는 라이브러리다.
AWS SDK for Java와는 달리, Spring Cloud AWS는 Spring Boot와 통합되어 필요한 설정으로 자동으로 구성해준다고 한다.
또한 Spring의 다양한 기능(Spring Data, Sequrity 등)과 AWS 서비스를 쉽게 통합할 수 있다는 장점이 존재한다.
자세한 내용은 공식 문서를 참고하자.
지금까지는 정말 이론적인 비교였고, 실제 체감은 Spring Cloud까지 사용해봐야 느낄 수 있을 것 같다.
좀 더 명확한 비교를 위해 추후 Spring Cloud AWS로도 구현해볼 예정이다.
AWS SDK for Java 의존성 추가
이미지 업로드 기능을 구현할 당시 AWS SDK for Java를 사용했기 때문에 여기서는 AWS SDK for Java에 대한 사용법만 설명합니다.
AWS SDK for Java 버전 선택
AWS SDK for Java는 1.x 버전과 2.x 버전이 존재한다. AWS 문서에 따르면, 2.x는 Java 8을 기반으로 기존 1.x의 코드를 대대적으로 개선한 것이라고 한다.
(두 버전의 차이에 대한 자세한 내용은 여기를 참고하자.)
Java 17을 사용하는 나로서는 굳이 1.x를 사용할 이유가 전혀 없다고 느껴져 2.x를 사용했다.
더 코드가 어떻게 변경되었는지는 여기를 통해 자세히 알 수 있다.
Gradle Dependency 추가
AWS SDK for Java에서 제공하는 API를 사용하기 위해 의존성을 추가한다.
implementation 'software.amazon.awssdk:aws-sdk-java:2.24.8'2.x 중에서도 여러 버전이 있는데, 당시 가장 최근 버전이었던 2.24.8 버전을 사용했다.
만약 가장 최신 버전을 사용하고 싶다면 Maven Repository를 확인해보자.
S3 설정 클래스
가장 먼저 애플리케이션이 어떤 국가에 있는 어떤 버킷에 접근할건지, 그리고 어떤 액세스 키로 접근할건지 설정하기 위한 Config 파일을 작성해야 한다.
환경 변수 관리
이때 코드에 액세스 키를 직접 작성하는 것은 보안에 있어 노출 위험이 있기 때문에, application.yml 파일에 환경 변수로 지정하여 주입 받았다.
aws:
s3:
bucket: 버킷 이름
credentials:
access-key: 액세스 키
secret-key: 비밀 액세스 키aws.s3.bucket: 생성한 버킷 이름aws.credentials: IAM 사용자를 생성하면서 발급 받은 액세스 키와 비밀 액세스 키
S3Config 클래스
이제 Spring Boot가 S3 관련 설정을 자동으로 구성할 수 있도록 S3Config 클래스를 작성한다.
@Configuration
public class S3Config {
@Value("${aws.credentials.access-key}")
private String accessKey;
@Value("${aws.credentials.secret-key}")
private String secretKey;
@Bean
public S3Client amazonS3Client() {
return S3Client.builder()
.region(Region.AP_NORTHEAST_2)
.credentialsProvider(StaticCredentialsProvider.create(awsBasicCredentials()))
.build();
}
private AwsBasicCredentials awsBasicCredentials() {
return AwsBasicCredentials.create(accessKey, secretKey);
}
}accessKey와 secretKey 변수에 환경 변수로 지정한 액세스 키와 비밀 액세스 키를 주입하기 위해 @Value를 사용했다.
S3Client
작성한 S3Config 클래스를 보면 S3Client를 빈으로 등록하는데, S3Client는 S3에 접근하기 위해 사용되는 인터페이스라고 보면 된다.
S3Client를 생성할 때 다음과 같이 S3에 접근할 수 있는 자격을 증명할 수 있는 정보를 주입하며, 이 정보는 우리가 생성한 버킷의 리전과 액세스 키를 의미한다.
return S3Client.builder()
.region(Region.AP_NORTHEAST_2)
.credentialsProvider(StaticCredentialsProvider.create(awsBasicCredentials()))
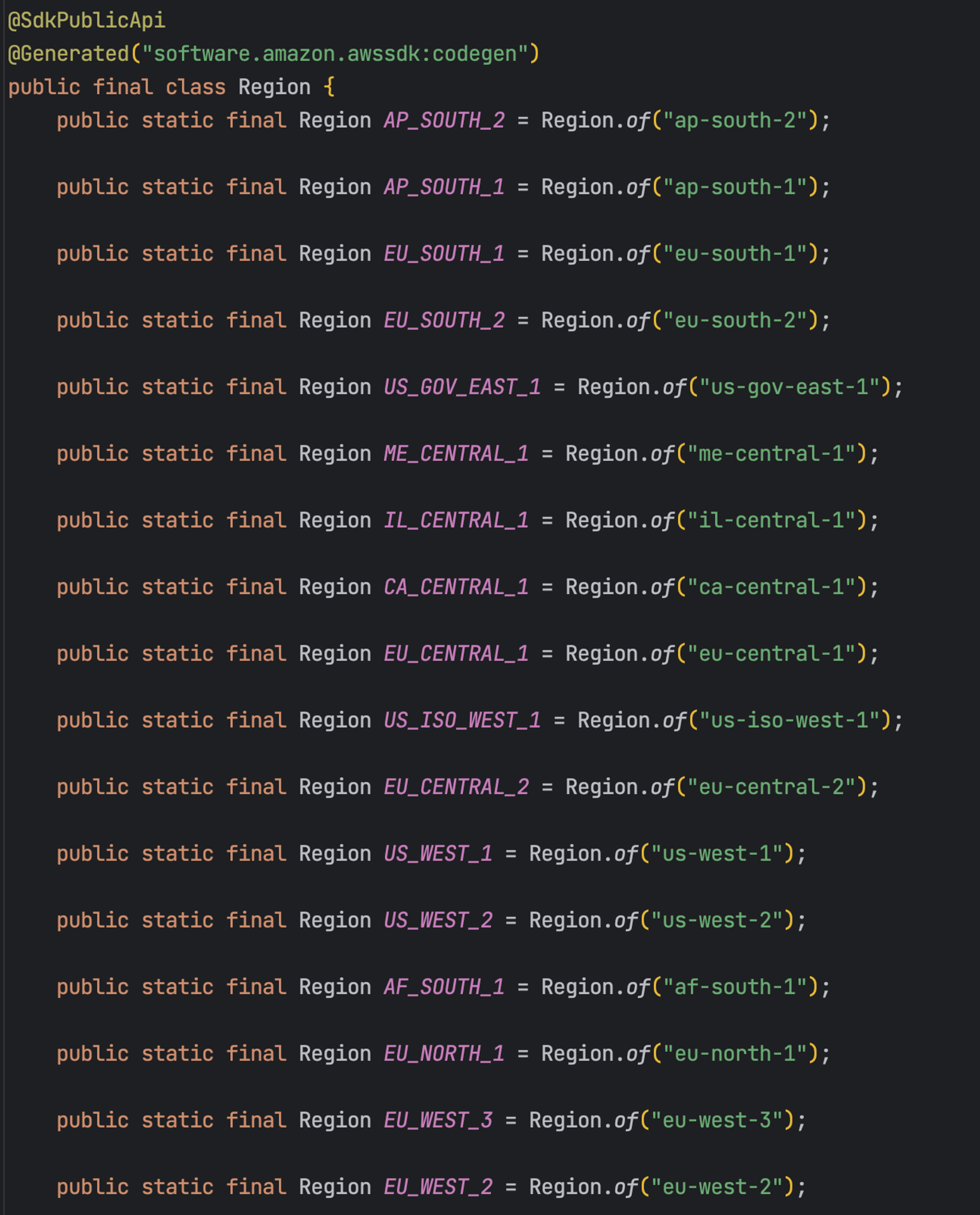
.build();region의 매개변수로는 우리가 생성한 버킷의 리전인 서울(AP_NORTHEAST_2)을 전달한다.
AWS SDK에서는 다양한 리전을 상수로 정의하고 있다.
credentialsProvider의 매개변수로는 아까 발급 받은 액세스 키와 비밀 액세스 키를 전달하는데, 몇 가지 방법이 존재한다.
AwsBasicCredentials
 위에서 사용한 방법으로, yml 파일에 환경변수로 지정한 액세스 키와 비밀 액세스 키를
위에서 사용한 방법으로, yml 파일에 환경변수로 지정한 액세스 키와 비밀 액세스 키를 AwsBasicCredentials생성자에 주입하여 자격 증명을 생성한다.
-
EnvironmentVariableCredentialsProvider

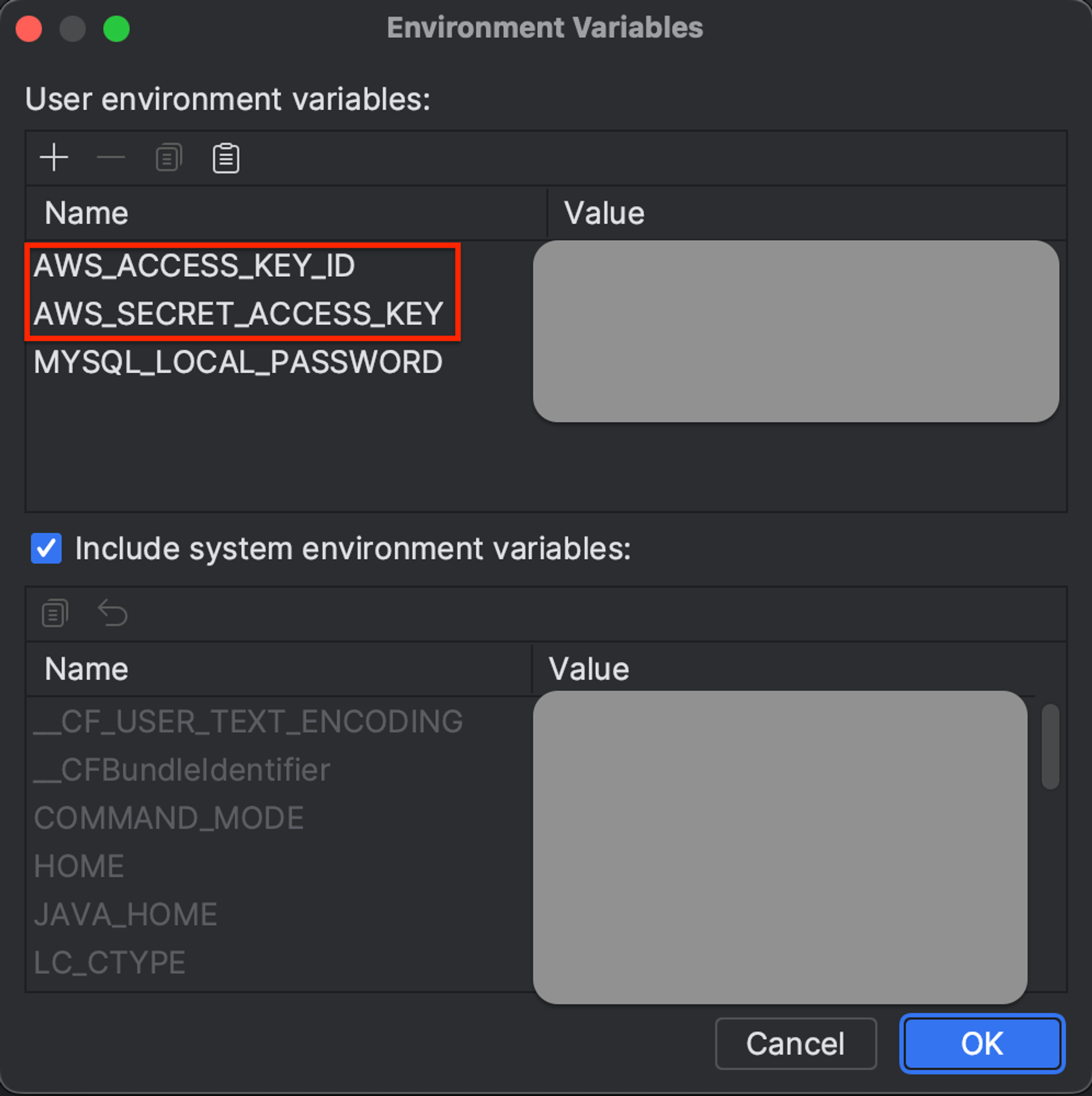
액세스 키와 비밀 액세스 키를 설정 파일에 따로 명시하지 않고, IDE 환경 변수로 등록하여 자격 증명을 생성하는 방식이다.
이때 환경변수 이름은 반드시 위 사진에 나와 있는대로 작성해야 한다.
코드를 확인하기 전에…
앞에서 이미지 파일은 S3에 저장하고, DB에는 이미지 정보만 저장한다고 했다.
여기서 이미지 정보는 다음과 같은 메타 데이터를 의미한다.
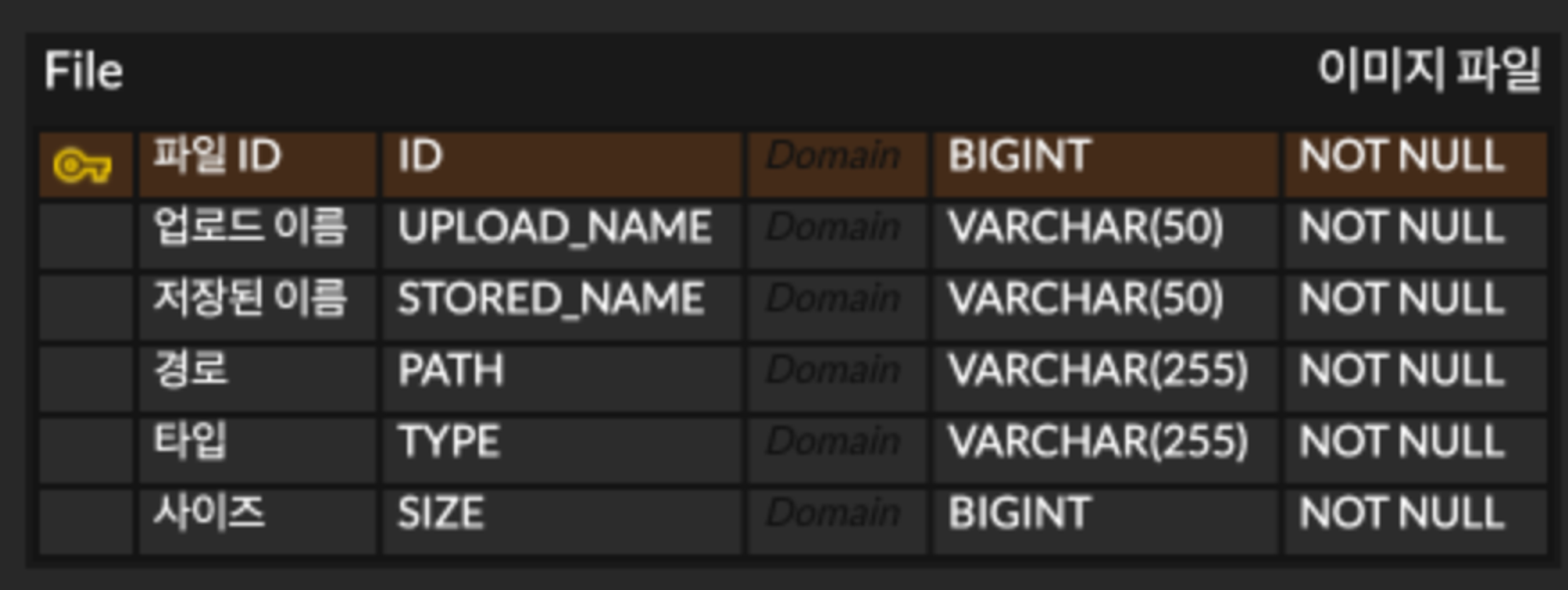
UPLOAD_NAME은 사용자가 업로드할 때의 이미지 이름이고, STORED_NAME은 이미지가 업로드된 이후 부여된 고유 이름이다.
이렇게 이름을 굳이 2개로 구분한 이유는 여러 사용자들이 같은 이름의 이미지를 사용할 수 있음을 고려했기 때문이다. 만약 파일 이름이 중복된다면 관리에 어려움이 생길 뿐만 아니라, 데이터 손실 문제도 발생할 수 있다.
또 다른 정보로는 파일의 경로와 타입, 그리고 파일 크기가 있다.
이미지 업로드 기능 플로우
본격적으로 코드를 확인하기에 앞서 내가 구현한 이미지 업로드 기능의 흐름을 대강 살펴보자.
- 사용자가 업로드한 이미지 이름과 UUID를 혼합해 고유한 이름 생성
- 클라이언트로부터 전달된 이미지 파일에서 이름, 타입, 크기 등 메타 데이터 추출 후 DB에 저장
- S3 버킷의 특정 경로에 이미지 파일 저장
이미지 업로드 기능 예제 코드
아래 코드는 내가 실제로 작성했던 코드에서 중요한 부분만 가져온 것이다.
@Service
@RequiredArgsConstructor
public class FileService {
private static final String END_POINT = "AWS S3 버킷 내 객체에 대한 접근 경로"; // ex) "https://test-bucket.s3.ap-northeast-2.amazonaws.com/"
private static final String UPLOAD_DIR = "디렉토리 이름"; // ex) "test/"
private final S3Client s3Client;
private final FileRepository fileRepository;
@Value("${aws.s3.bucket}")
private String bucket;
@Transactional
public String uploadImage(MultipartFile multipartFile) {
// 이미지 고유 이름 생성
String originalName = multipartFile.getOriginalFilename();
String storedName = String.format("%s_%s", UUID.randomUUID(), originalName);
// 이미지 파일 메타 데이터 추출
long contentLength = multipartFile.getSize();
FileFormat FileFormat = convertMimeTypeToFileFormat(multipartFile.getContentType());
// S3에 이미지 저장 및 DB에 메타 데이터 저장
try (InputStream inputStream = multipartFile.getInputStream()) {
putObjectToS3(UPLOAD_DIR + storedName, inputStream, contentLength);
fileRepository.save(createFile(originalName, storedName, END_POINT + UPLOAD_DIR, FileFormat, contentLength));
return getUrl(UPLOAD_DIR + storedName);
} catch (IOException e) {
// 예외 처리
}
}
private FileFormat convertMimeTypeToFileFormat(String mimeType) {
// 지원하는 파일 타입인지 체크 후 변환
}
private void putObjectToS3(String key, InputStream inputStream, long contentLength) {
PutObjectRequest putObjectRequest = PutObjectRequest.builder()
.bucket(bucket)
.key(key)
.build();
s3Client.putObject(putObjectRequest, RequestBody.fromInputStream(inputStream, contentLength));
}
private File createFile(String uploadName, String storedName, String path, FileFormat FileFormat, long contentLength) {
return File.builder()
.uploadName(uploadName)
.storedName(storedName)
.path(path)
.fileFormat(FileFormat)
.size(contentLength)
.build();
}
private String getUrl(String key) {
GetUrlRequest request = GetUrlRequest.builder()
.bucket(bucket)
.key(key)
.build();
return s3Client.utilities().getUrl(request).toString();
}
}개선할 부분이 많이 보이지만, 당장 로직을 이해하는 데에는 문제가 없으니 하나씩 살펴보자.
MultipartFile이란?
Spring에서는 파일 업로드 기능을 지원하기 위해 MultipartFile 인터페이스를 제공한다.
MultipartFile 인터페이스는 HTTP 요청의 multipart/form-data로 전송된 파일을 다루는 데 사용되며, 이를 통해 사용자는 파일을 서버에 업로드하고, 서버는 해당 파일을 쉽게 처리할 수 있는 것이다.
MultipartFile이 제공하는 기능이 더 궁금하다면 언제나 그렇듯 공식 문서를 참고하자😅
이미지 고유 이름 생성
String originalName = multipartFile.getOriginalFilename();
String storedName = String.format("%s_%s", UUID.randomUUID(), originalName);클라이언트로부터 전달된 파일에서 원래 이름을 추출하고, 랜덤 UUID를 혼합하여 고유한 이름을 생성한다.
S3에 이미지 파일 저장
private void putObjectToS3(String key, InputStream inputStream, long contentLength) {
PutObjectRequest putObjectRequest = PutObjectRequest.builder()
.bucket(bucket)
.key(key)
.build();
s3Client.putObject(putObjectRequest, RequestBody.fromInputStream(inputStream, contentLength));
}S3Client는 버킷에 객체를 저장하는 putObject 메서드를 제공하며, 매개변수로 PutObjectRequest와 RequestBody를 전달한다. 그리고 각 객체는 다음과 같은 역할을 수행한다.
PutObjectRequest: 객체를 저장하려는 버킷과 경로 및 이름을 담는 객체RequestBody: 파일의InputStream과 크기를 이용해 만든 업로드할 데이터의 본문 객체
이미지 URL 가져오기
private String getUrl(String key) {
GetUrlRequest request = GetUrlRequest.builder()
.bucket(bucket)
.key(key)
.build();
return s3Client.utilities().getUrl(request).toString();
}GetUrlRequest에 담은 버킷과 키를 이용해 객체를 식별하고, 그 객체의 URL을 문자열 형태로 가져온다.
예제 코드의 문제점
사실 위 코드에는 한 가지 문제가 있는데, IOException을 처리하는 try-catch문이다.
try (InputStream inputStream = multipartFile.getInputStream()) {
putObjectToS3(UPLOAD_DIR + storedName, inputStream, contentLength);
fileRepository.save(createFile(originalName, storedName, END_POINT + UPLOAD_DIR, FileFormat, contentLength));
return getUrl(UPLOAD_DIR + storedName);
} catch (IOException e) {
// 예외 처리
}만약 putObjectToS3 메서드가 성공한 후 fileRepository.save(createFile(...)) 메서드에서 문제가 발생해 실패하게 된다면, 트랜잭션 롤백으로 인해 S3에는 파일이 존재하지만 DB에는 존재하지 않게 된다.
즉, S3 버킷과 DB 간 데이터 불일치 문제가 발생할 수 있다.
따라서 DB 저장에 실패했을 때 S3에 업로드된 파일을 삭제하는 로직까지 추가하는 것이 좋다.
끝으로
지금까지 이미지 업로드 기능을 구현하는 과정을 다시 한 번 정리해봤다.
구현할 때 당시에는 코드 대부분을 이해하지 못한 채 넘어갔는데, 지금 다시 정리해보니 각각의 코드가 무엇을 의미하는지 알 수 있게 되었다.
특히 그때는 볼 수 없었던 문제점도 지금은 보이기 시작한다는 것에 “그래도 성장하긴 했구나,,”를 느낀다.
