지난번에는 톡픽 생성 시 수행되는 파일 매핑(사용자가 업로드한 이미지 파일을 톡픽과 매핑)과 요약 작업을 이벤트 기반 비동기 처리로 전환하여, 전체 응답 속도를 개선했습니다.
https://velog.io/@hjm2530/Spring-Async-트랜잭션-이슈-해결-feat.-TransactionalEventListener
이번에는 톡픽 생성 API가 동시에 여러 요청을 받더라도 정상적으로 동작하는지 확인하기 위해, 동시 요청이 최대 30까지 점진적으로 늘어나는 시나리오로 3분간 부하 테스트를 진행했습니다.
동시 요청으로 비동기 작업 처리 시간 급증
부하 테스트 결과
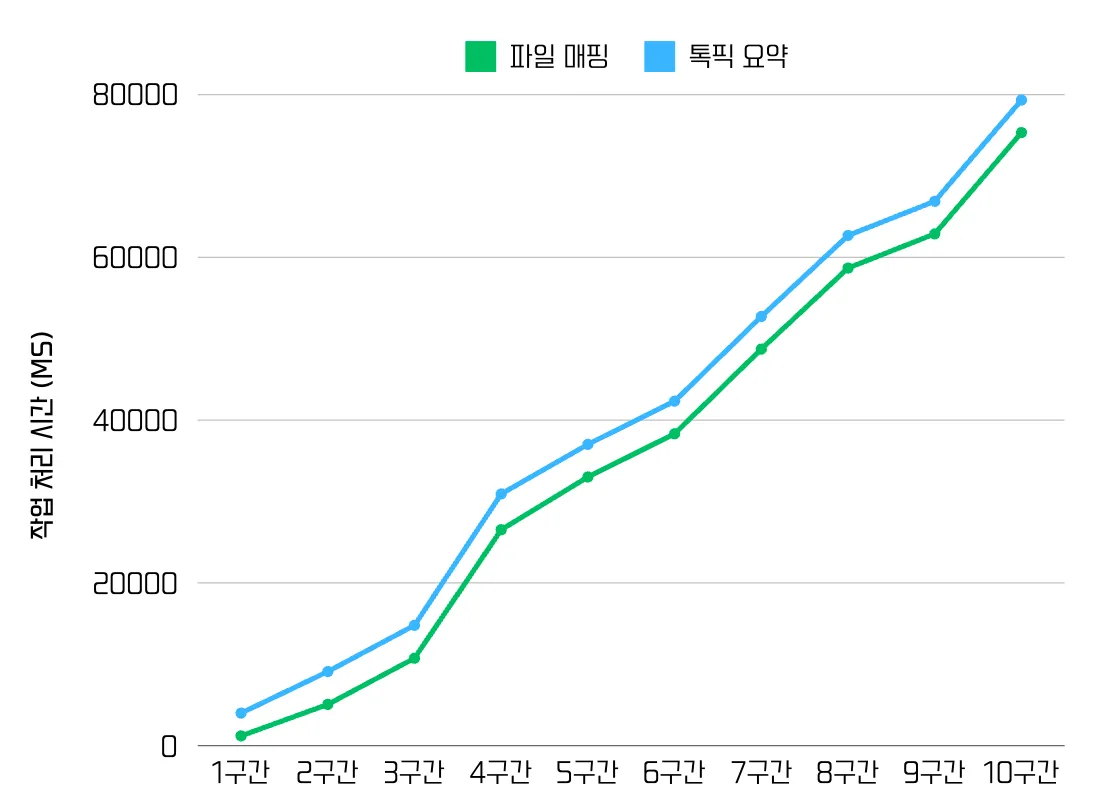
테스트 결과, 톡픽 생성 API의 응답 시간은 약 80ms로 일정하게 유지되었지만, 다음과 같이 하지만 후속 비동기 작업인 파일 매핑과 톡픽 요약 처리 시간에서 문제가 발생했습니다.
톡픽 생성 API 자체의 응답 시간은 약 80ms로 안정적이었으나, 이후 실행되는 비동기 작업, 즉 파일 매핑과 톡픽 요약의 처리 시간은 요청이 누적됨에 따라 점진적으로 증가했습니다.
성능 개선의 필요성
파일 매핑 작업은 사용자가 시스템과 직접 상호작용하는 핵심 기능으로, 빠른 피드백이 필수입니다. 톡픽 작성 과정에서 업로드한 파일이 정상적으로 반영되었는지 즉시 확인할 수 있어야 하기 때문이에요.
예를 들어, 톡픽을 성공적으로 작성했는데 업로드했던 이미지가 표시되지 않는다면, 사용자는 이미지가 반영되지 않았다고 판단하고, 다시 업로드를 시도하거나 오류로 인식할 수 있습니다. 이런 경험이 반복되면 서비스의 신뢰도가 굉장히 낮아질거에요😢
이처럼 파일 매핑 작업의 속도는 단순한 처리 시간이 아니라, 전체적인 사용자 경험과 직결되는 요소입니다. 따라서, 요청이 많아졌을 때 지연이 발생하는 원인과 해결 방안을 고민했습니다.
문제 원인 분석
Spring @Async와 ThreadPoolTaskExecutor
Spring은 @Async 어노테이션이 붙은 메서드를 별도의 스레드에서 실행하도록 하여 비동기 처리를 지원합니다. 이때 실행할 스레드를 관리하는 여러 Executor를 제공하는데, 그중에서 ThreadPoolTaskExecutor를 설정했습니다.
ThreadPoolTaskExecutor는 스레드 풀 기반의 Executor로, 효율적으로 스레드를 관리할 수 있어 많이 사용됩니다.
ThreadPoolTaskExecutor를 사용할 때는 다음과 같이 스레드풀 관련 값들을 미리 설정해야 하는데요.
@EnableAsync
@Configuration
public class AsyncConfig {
@Bean
public Executor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(2); // 스레드 풀에서 가용한 최소 스레드 수
// executor.setMaxPoolSize(4); // 스레드 풀에서 가용한 최대 스레드 수
// executor.setQueueCapacity(50); // 작업 큐 용량
executor.setThreadNamePrefix("Async-"); // 스레드의 이름 접두사
executor.initialize(); // 설정 값을 이용해 executor 초기화
return executor;
}
}PICK-O는 AWS 프리티어를 사용하기에 서버 자원이 충분하지 않고 부하도 거의 없기 때문에, 불필요한 스레드 생성을 방지하고 요청이 많아도 최대한 큐에서 대기하도록 maxPoolSize와 queueCapacity는 기본값(Integer.MAX_VALUE)을 유지했습니다.
그리고 corePoolSize의 경우, 최소한 하나의 요청에서 2개의 비동기 작업이 대기 없이 실행되도록 하기 위해 2로 설정했습니다.
스레드 병목 발생
이러한 설정으로 초기화된 executor는 동시 다발적인 요청을 처리하기에는 부족했습니다. 그 이유는 스레드 풀 크기가 너무 작아, 여러 비동기 작업이 한정된 스레드를 공유하면서 병목이 발생했기 때문입니다.
아래 그림을 보면 이해가 더 쉽습니다.
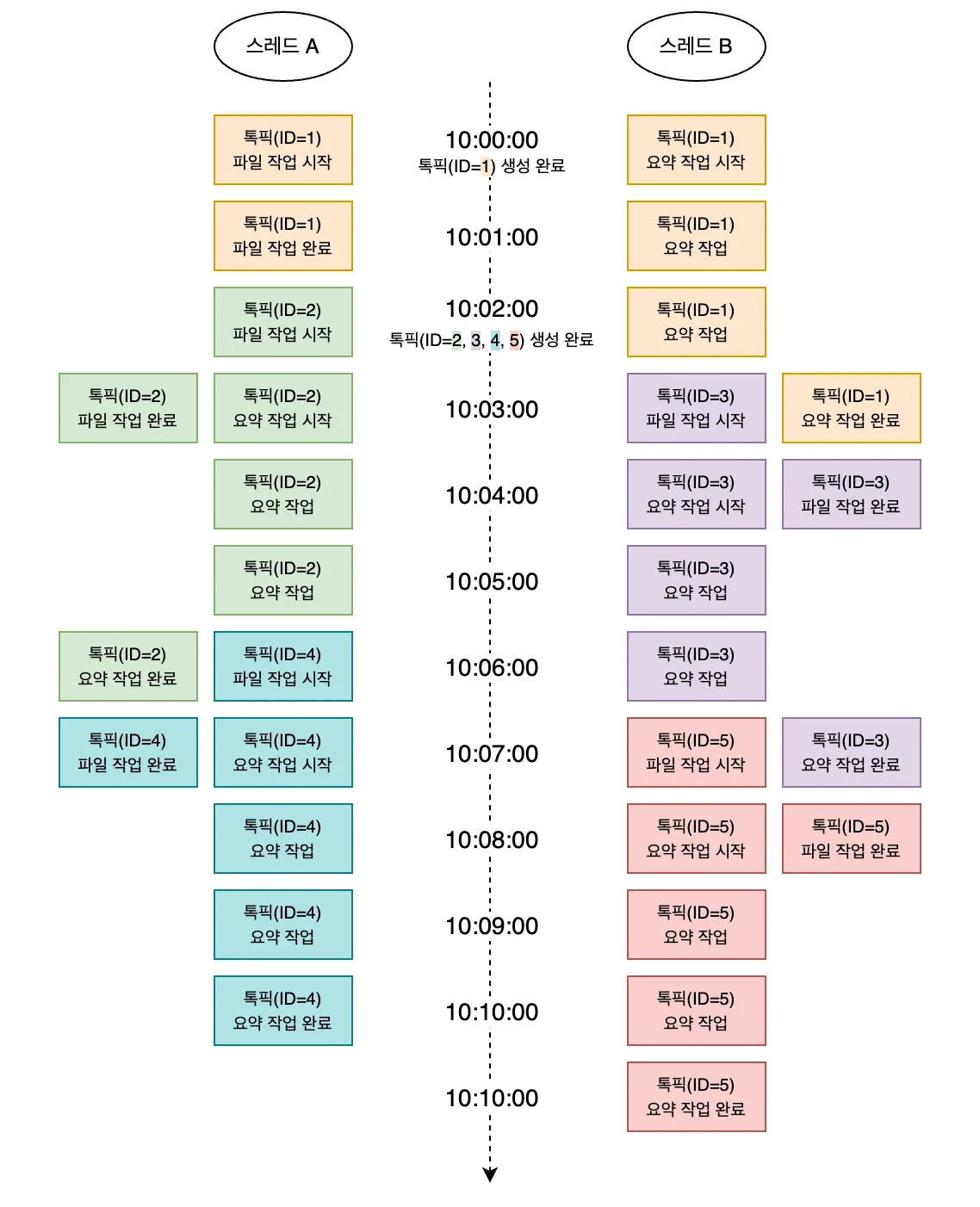
파일 매핑 작업만 봤을 때, ID가 2인 톡픽은 생성 완료 후 1분(10:02:00~10:03:00) 만에 처리되었습니다.
그러나 ID가 3인 톡픽은 2분, ID가 4인 톡픽은 5분, ID가 5인 톡픽은 8분이 걸렸습니다.
이처럼 가용한 스레드 수가 요청량에 비해 현저히 적기 때문에, 비동기 작업의 대기 시간이 점진적으로 증가할 수밖에 없었습니다.
해결 과정
이러한 스레드 병목 현상을 해결하기 위해 2가지 단계를 거쳤습니다.
분리된 Task Executor 사용
우선, 작업 특성에 따라 Task Executor를 분리하여 독립적인 스레드 풀로 운영하도록 했습니다.
요약 작업은 사용자가 작성한 톡픽 내용을 요약하기 위해 GPT 같은 대형 언어 모델에게 보내고, 그 결과를 다시 받아오는 과정이 필요합니다. 이러한 모델 추론과 네트워크 통신으로 인해 파일 매핑 작업에 비해 더 긴 지연 시간이 발생합니다.
상대적으로 짧게 걸리며 빠른 피드백이 중요한 파일 매핑 작업이 요약 작업에 밀려 지연되는 것은 치명적인 문제입니다.
따라서, 두 작업이 서로 다른 Task Executor를 사용하도록 분리함으로써, 요약 작업이 오래 걸리더라도 파일 매핑 작업이 독립적으로 빠르게 처리될 수 있도록 개선했습니다.
@EnableAsync
@Configuration
public class AsyncConfig implements AsyncConfigurer {
@Bean
public Executor fileMappingTaskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(1);
executor.setThreadNamePrefix("FileMappingTask - ");
executor.initialize();
return executor;
}
@Bean
public Executor talkPickSummaryTaskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(1);
executor.setThreadNamePrefix("TalkPickSummaryTask - ");
executor.initialize();
return executor;
}
...
}**@Async("fileMappingTaskExecutor")**
@Transactional
public void handleFiles(List<Long> fileIds, Long talkPickId) {
// 파일 매핑 작업
}TaskExecutor를 2개로 분리하여 bean으로 등록하고, @Aysnc 어노테이션에 사용할 executor를 명시했습니다.
그 결과, 요약 작업의 처리 시간이 길어져도 파일 매핑 작업에는 영향을 주지 않게 되었습니다.
스레드 풀 크기 최적화
여기까지 하면 두 비동기 작업이 서로 간섭 없이 독립적으로 처리될 수 있지만, 여전히 스레드 풀의 크기에 따라 병목이 발생할 수 있습니다.
이에 따라 작업 특성과 실행 시간 기반으로 스레드 풀 최적화 작업을 수행했습니다.
먼저, 잘 알려진 적정 스레드 수 = 사용 가능한 코어 개수 * (1 + 대기시간/서비스시간)공식을 사용했습니다.
각 작업에 실제 데이터를 대입해보니, 계산값은 모두 약 2로 나왔고, 작업이 I/O Bound 성격이라는 점을 고려하여 2를 곱한 4를 executor의 corePoolSize로 설정했습니다.
이후 동일한 환경에서 부하 테스트를 수행했고, 파일 매핑 작업은 정상 처리됨을 확인했습니다. 하지만 요약 작업은 여전히 스레드 수가 부족하여 처리 지연이 남아 있었습니다. 따라서 요약 작업의 corePoolSize는 6으로 증가시켰습니다.
결과적으로, 두 작업 모두 실제 처리 시간만큼만 대기하며 동작하게 되었고, 사용자 경험 저하 없이 안정적인 비동기 처리가 가능해졌습니다.
마무리
이번 개선 과정을 통해 느낀 점은, 단순히 @Async로 비동기 처리하는 것만으로는 성능과 안정성 확보가 어렵다는 점입니다.
중요한 것은 작업의 특성과 실행 흐름을 잘 파악하고, 그에 맞는 구조를 설계하고 지속적으로 검증하는 과정임을 배웠습니다.
다음번에는 설정한 스레드풀을 모니터링하고, 실시간으로 지표를 확인할 수 있는 시스템을 구축해보겠습니다!
