Spring @Async 트랜잭션 이슈 해결 (feat. @TransactionalEventListener)

문제 상황
비동기 처리
PICK-O 서비스의 톡픽(게시글) 생성 API는 아래 두 가지 주요 작업을 수행합니다.
- 사용자가 업로드한 이미지 파일을 톡픽 엔티티와 연결하는 작업
- 톡픽의 제목, 내용을 토대로 AI 기반 요약을 수행하는 작업
두 작업 모두 네트워크 비용이 크기 때문에 톡픽 생성 응답 속도가 현저히 느렸고, @Async 어노테이션으로 비동기 처리하여 성능을 개선했습니다. (자세한 내용은 제 발표 영상을 참고해 주세요)
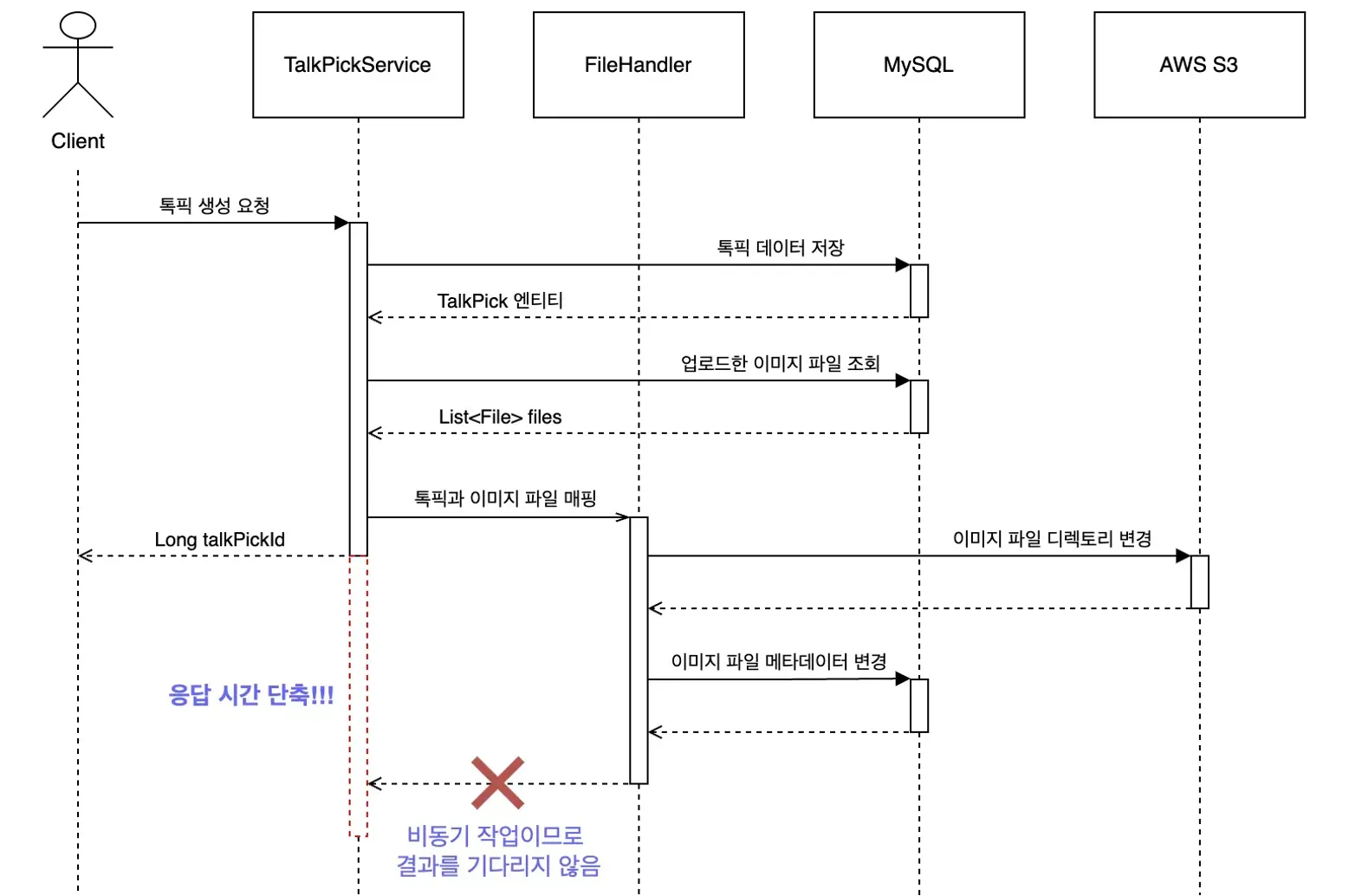
응답 속도는 약 1초에서 80ms로 확실히 개선되었지만, 여러 개의 동시 요청을 가정한 부하 테스트를 진행하는 과정에서 예상치 못한 문제가 발생했습니다.
데이터 조회 실패
아래는 당시 부하 테스트를 수행할 때 찍힌 로그입니다.
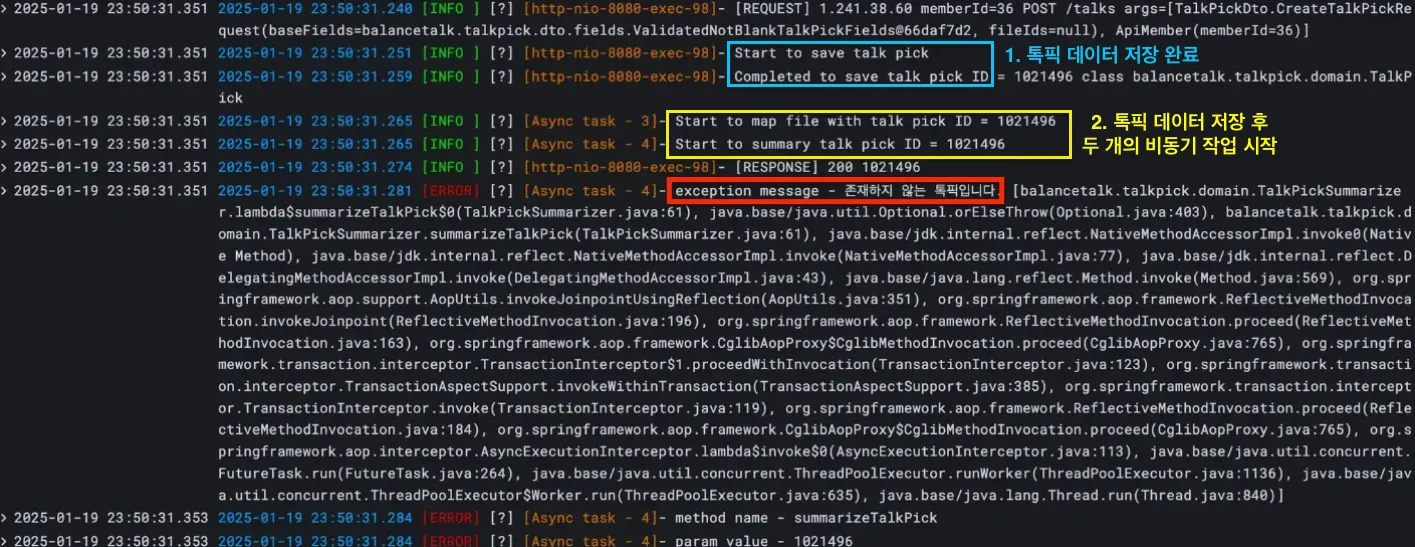
톡픽 데이터 저장은 완료되었는데, 곧바로 실행되는 두 작업에서 해당 톡픽을 찾을 수 없다는 에러가 발생했는데요.
더 큰 문제는 이러한 에러가 10% 확률로 발생했다는 것입니다.
즉, 100번의 API 요청이 왔을 때 90개의 요청은 성공했지만, 나머지 10개 정도의 요청이 위와 같은 이유로 실패했습니다.
Spring @Async와 트랜잭션 생명주기
이 문제를 해결하기 위해, Spring @Async 사용 시 트랜잭션의 생명주기에 대해 다시 돌아봤습니다.
이번 포스트에서는 쉬운 이해를 위해 톡픽 요약 작업만 다룹니다.
일반적인 트랜잭션 동작
Spring에서는 @Transactional이 선언된 메서드를 실행하면, 해당 메서드가 실행되는 동안 트랜잭션이 유지됩니다.
따라서 다음과 같이 createTalkPick 메서드에서 내부적으로 summary 메서드를 호출하면, 두 메서드는 동일한 트랜잭션에서 실행됩니다.
@Service
public class TalkPickService {
...
@Transactional
public Long createTalkPick(TalkPick talkPick, List<Long> fileIds) {
TalkPick savedTalkPick = talkPickRepository.save(talkPick); // 톡픽 저장
summarizer.summarize(savedTalkPick.getId()); // 톡픽 내용 요약
...
}
}
@Component
public class TalkPickSummarizer
public void summarize(Long talkPickId) {
// 톡픽 조회
TalkPick talkPick = talkPickRepository.findById(talkPickId)
.orElseThrow(() -> new BalanceTalkException(NOT_FOUND_TALK_PICK)); // ID에 해당하는 톡픽이 존재하지 않는다면 NOT_FOUND 예외 발생
// 조회한 톡픽의 내용을 토대로 AI 기반 요약
Summary summary = callPromptForSummary(talkPick); // OpenAI API를 호출하여 요약 텍스트 생성
talkPick.updateSummary(summary); // 톡픽 요약 내용 업데이트
}
}이를 트랜잭션 흐름으로 도식화하면 아래와 같습니다.
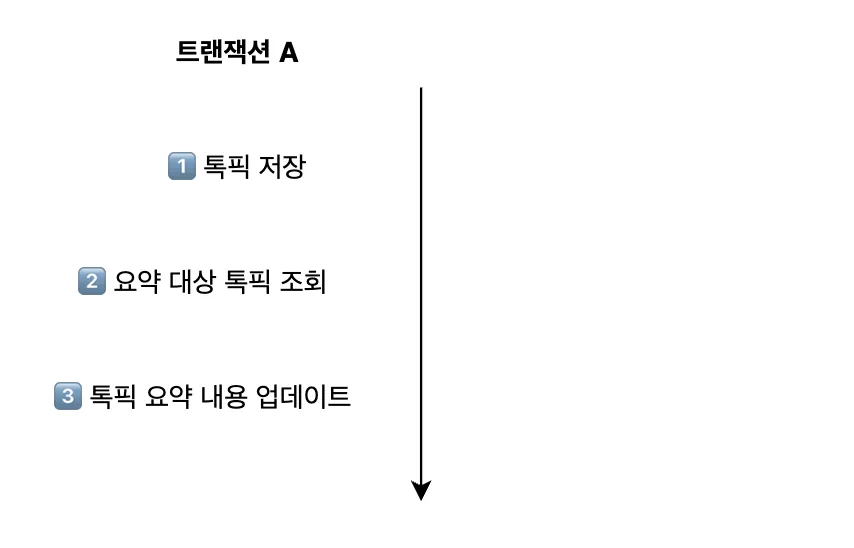
톡픽 생성 API의 응답 속도를 개선하기 전(비동기 처리 전)의 흐름이 바로 이러한 모습이었습니다.
서로 다른 스레드의 트랜잭션 생명주기
Spring은 클라이언트의 각 요청을 별도의 스레드에서 처리합니다. 일반적으로 한 요청을 처리하는 A 메서드가 B 메서드를 내부에서 호출하면, 두 메서드는 같은 스레드에서 실행되며 (위에서 봤듯) 동일한 트랜잭션을 공유합니다.
하지만 B 메서드에 @Async가 붙어 있으면 새로운 스레드에서 실행되기 때문에, A와 B의 트랜잭션 생명주기가 다르게 동작합니다.
이번에는 summarize 메서드에 @Async와 @Transactional을 붙여봤습니다.
@Service
public class TalkPickService {
...
@Transactional
public Long createTalkPick(TalkPick talkPick, List<Long> fileIds) {
TalkPick savedTalkPick = talkPickRepository.save(talkPick); // 톡픽 저장
summarizer.summarize(savedTalkPick.getId()); // 톡픽 내용 요약
...
}
}
@Component
public class TalkPickSummarizer
@Async // 비동기 선언
@Transactional // 새로운 스레드에서 실행되므로 트랜잭션 선언 필수
public void summarize(Long talkPickId) {
// 톡픽 조회
TalkPick talkPick = talkPickRepository.findById(talkPickId)
.orElseThrow(() -> new BalanceTalkException(NOT_FOUND_TALK_PICK)); // ID에 해당하는 톡픽이 존재하지 않는다면 NOT_FOUND 예외 발생
// 조회한 톡픽의 내용을 토대로 AI 기반 요약
Summary summary = callPromptForSummary(talkPick); // OpenAI API를 호출하여 요약 텍스트 생성
talkPick.updateSummary(summary); // 톡픽 요약 내용 업데이트
}
}Spring은 클라이언트의 톡픽 생성 요청을 처리하기 위해 새로운 스레드 A를 할당합니다. 스레드 A가 createTalkPick 메서드를 실행하면서 트랜잭션 A가 시작됩니다.
톡픽을 DB에 저장한 후 summarize 메서드를 만나면, Spring이 해당 메서드를 실행하기 위한 스레드 B를 새롭게 할당합니다. 그리고 스레드 B가 메서드를 실행하면서 새로운 트랜잭션 B가 시작됩니다.
이를 그림으로 간단하게 나타내면 다음과 같습니다.
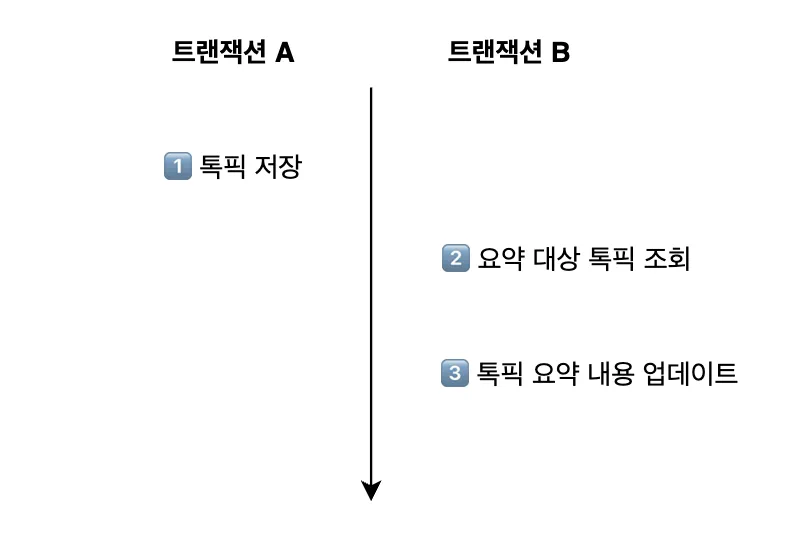
그래서 뭐가 문젠데?
지금까지 본 트랜잭션 흐름에서는 commit에 대한 내용이 없었는데요. 좀 더 자세히 보겠습니다.
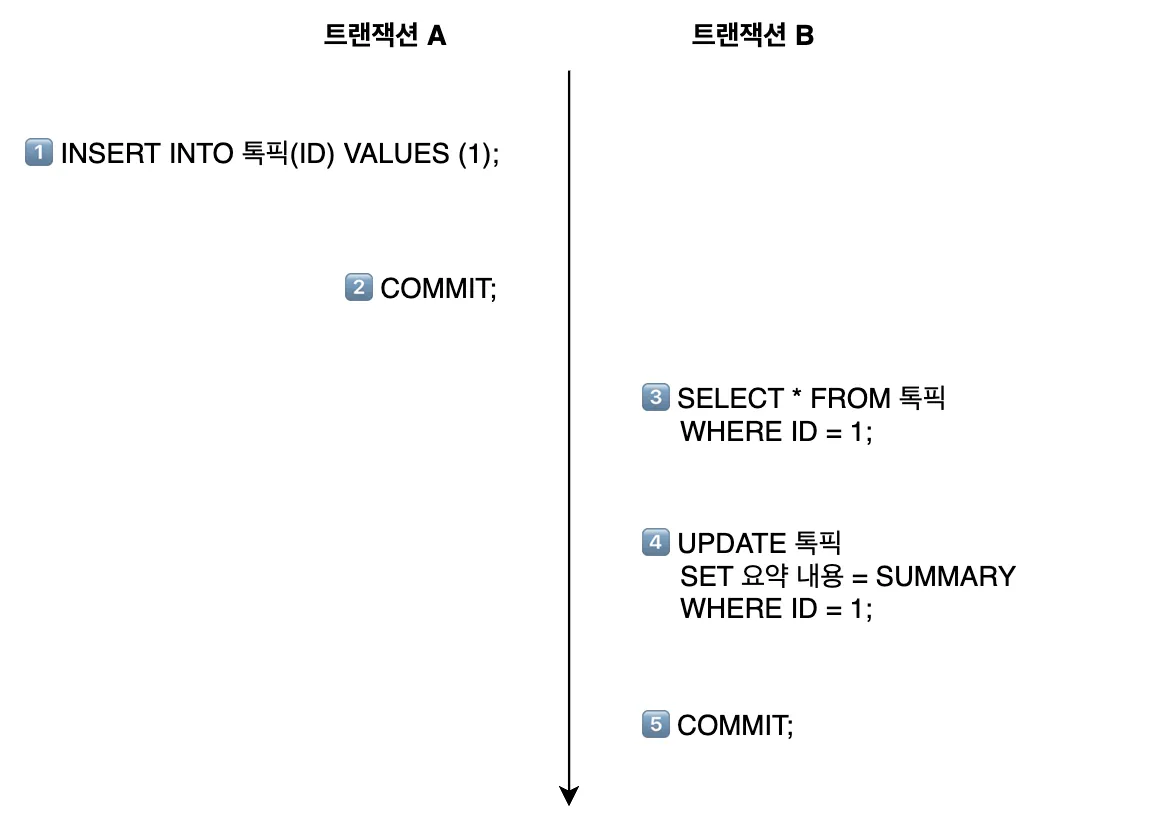
기본적으로 트랜잭션은 DML을 실행한 후 COMMIT까지 해야 데이터가 DB에 영구적으로 저장됩니다.
실행 순서가 바뀐다면?
위에서는 트랜잭션 A의 커밋 시점이 트랜잭션 B의 톡픽 조회 시점보다 빠른데, 과연 모든 요청이 이 순서대로 처리될까요?
사실 트랜잭션이 변경 내용을 commit하는 시점은 항상 일정하지 않습니다.
많은 요청으로 인해 DB에 부하가 생겨 트랜잭션 처리 속도가 느려지거나, DB와의 연결 자체가 지연되는 등 여러가지 상황이 발생할 수 있기 때문입니다.
따라서, 다음과 같이 아직 커밋되지 않은 데이터를 다른 트랜잭션이 조회하려고 하는 상황이 발생할 수 있습니다.
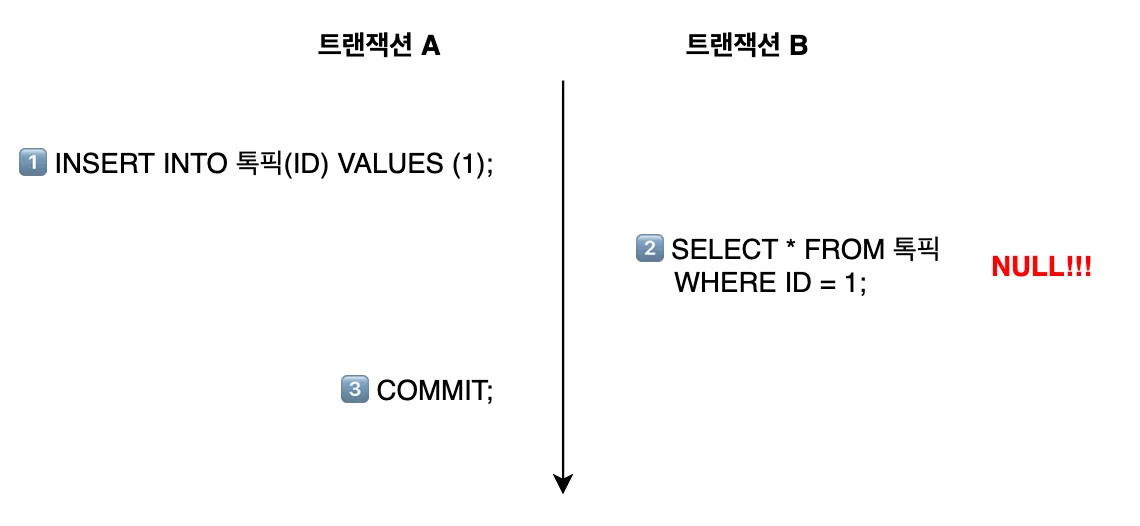
이처럼 톡픽 데이터는 저장되었지만 commit이 안 된 시점에서, 다른 트랜잭션이 요약 내용을 업데이트하기 위해 해당 톡픽을 읽어오려 시도해 발생한 문제였습니다.
트랜잭션 격리 수준 변경
이 방식은 적절한 해결책이 아니라서 결국 적용하지 않았습니다. 해결 방법만 빠르게 보고싶은 분들은 패스해 주세요 🙃
문제를 해결하기 위해 가장 먼저 떠오른 방법은 트랜잭션의 격리 수준을 변경하여 충돌 가능성을 제거하는 것이었습니다.
MySQL InnoDB의 기본 격리 수준은 Repeatable Read로, 트랜잭션이 시작된 시점에 commit된 데이터만 볼 수 있으며, 그 이후 다른 트랜잭션에서 commit된 변경 사항은 조회할 수 없습니다. 이로 인해 트랜잭션 B가 톡픽 조회 시 NULL을 반환하는 것입니다.
만약 격리 수준을 Read Uncommitted로 변경한다면, 톡픽 데이터를 저장하는 트랜잭션이 commit되지 않아도 요약 내용을 업데이트하는 트랜잭션은 해당 톡픽을 조회할 수 있게 됩니다.
@Async
@Transactional(isolation = Isolation.READ_UNCOMMITTED) // 트랜잭션 격리 수준을 Read Uncommitted로 변경
public void summarizeTalkPick(Long talkPickId) {
TalkPick talkPick = talkPickRepository.findById(talkPickId)
.orElseThrow(() -> new BalanceTalkException(NOT_FOUND_TALK_PICK));
...
}Dirty Read로 인한 데이터 불일치 문제 발생 가능
이를 이용하면 톡픽 생성 요청에서 발생하는 문제는 해결할 수 있지만, 톡픽 수정 요청에서는 Dirty Read로 인해 데이터 불일치 문제가 발생할 수 있습니다.
예를 들어, 아래 흐름을 살펴보겠습니다.
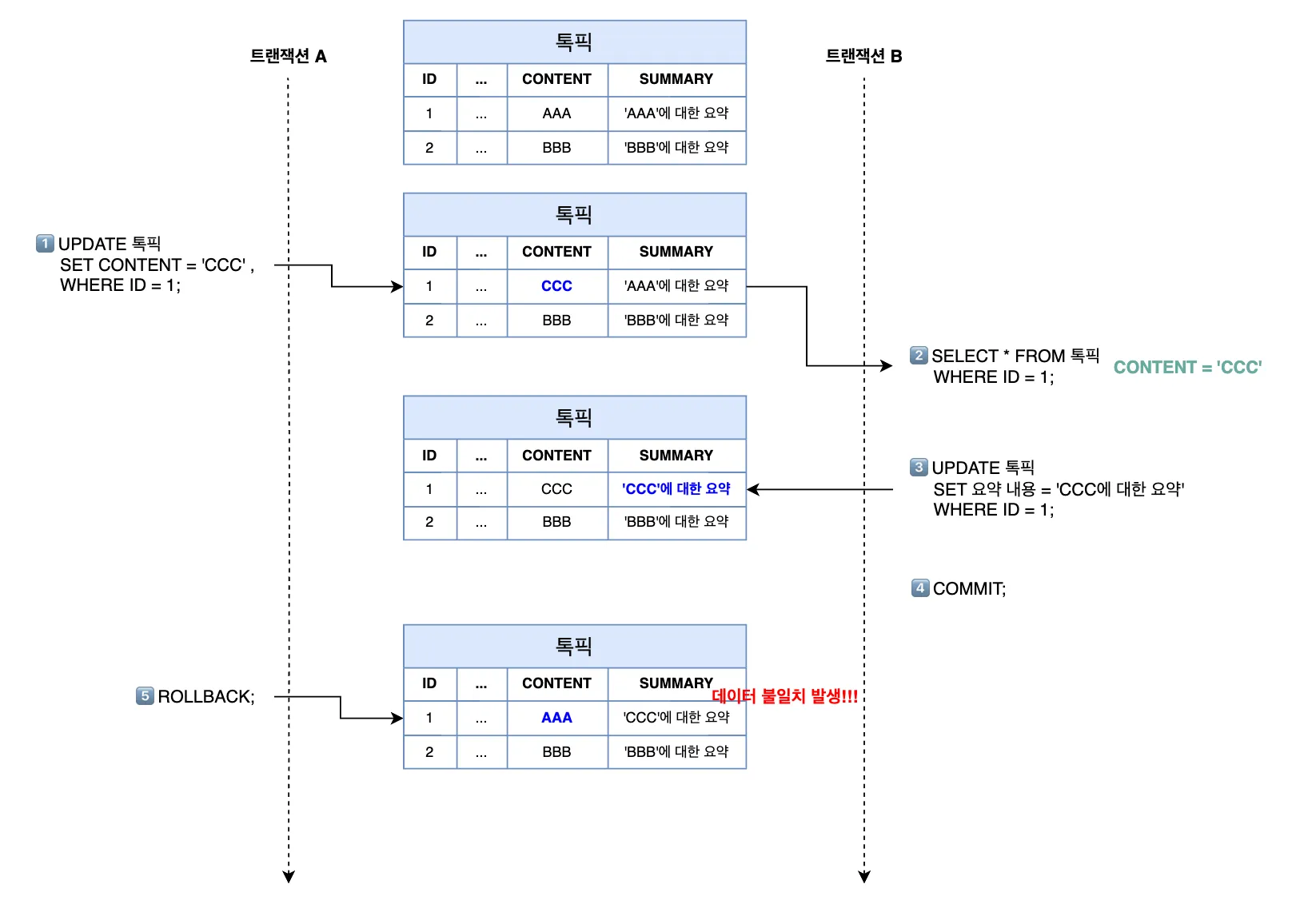
트랜잭션 A(이하 tx A)가 톡픽의 본문 내용을 ‘AAA’에서 ‘CCC’로 수정하고 커밋은 하지 않은 상태에서, 트랜잭션 B(이하 tx B)가 해당 톡픽을 조회합니다.
tx B는 읽어온 톡픽의 본문 내용(’CCC’)을 토대로 요약 내용을 업데이트하고 커밋합니다.
여기서 tx A가 예기치 못한 이슈로 인해 롤백된다면, 해당 톡픽의 본문 내용은 이전 값인 ‘AAA’로 돌아갈텐데, 이때 데이터 불일치 문제가 발생하게 됩니다.
이러한 문제는 요약 내용부터 읽는 톡픽 독자들에게 혼선을 불러일으킬 수 있다고 판단하여, 격리 수준을 변경하는 방식은 제외했습니다.
Spring 이벤트 기능을 활용하자
Spring은 이벤트 기반 프로그래밍을 제공하는데요. 이를 활용하여 비동기 작업의 실행 시점을 메인 트랜잭션 커밋 이후로 조정할 수 있습니다.
이벤트 클래스 정의
먼저, 이벤트를 처리하는 데 필요한 데이터를 가진 클래스를 정의합니다.
@Getter
@NoArgsConstructor
@AllArgsConstructor
public class TalkPickCreatedEvent {
private Long talkPickId;
private List<Long> fileIds;
}톡픽 생성 시 파일 매핑과 요약 작업을 수행해야 하므로, 해당 톡픽의 ID와 매핑할 파일들의 ID list를 담았습니다.
이벤트 발행
다음으로, 기존 서비스 계층에 있던 비동기 메서드를 제거하고, 이벤트 발행 코드를 추가합니다.
@Service
@RequiredArgsConstructor
public class TalkPickService {
private final TalkPickRepository talkPickRepository;
private final ApplicationEventPublisher eventPublisher;
@Transactional
public Long createTalkPick(TalkPick talkPick, List<Long> fileIds) {
// 톡픽 데이터 저장
TalkPick savedTalkPick = talkPickRepository.save(talkPick);
// 이벤트 발행
eventPublisher.publishEvent(new TalkPickCreatedEvent(savedTalkPick.getId(), fileIds));
...
}ApplicationEventPublisher의 publishEvent 메서드에 앞서 정의한 이벤트 클래스를 전달함으로써, 톡픽이 성공적으로 저장되면 이벤트가 발생합니다.
이벤트 리스너에서 비동기 작업 실행
마지막으로, 발생한 이벤트를 처리할 리스너를 구현합니다.
@Component
@RequiredArgsConstructor
public class TalkPickEventHandler {
private final TalkPickSummaryService talkPickSummaryService;
private final TalkPickFileService talkPickFileService;
@TransactionalEventListener
public void handleTalkPickCreatedEvent(TalkPickCreatedEvent event) {
talkPickFileService.handleFilesOnTalkPickCreate(event.getFileIds(), event.getTalkPickId());
talkPickSummaryService.summarizeTalkPick(event.getTalkPickId());
}이때, 저는 @EventListener가 아닌 @TransactionalEventListener를 선언했습니다.
두 어노테이션 모두 이벤트를 수신하여 메서드를 실행하는 역할을 하는데, 한 가지 다른 점은 @TransactionalEventListener가 트랜잭션 관리 기능이 통합되어 있다는 것입니다.
즉, 다음과 같이 트랜잭션 커밋 또는 롤백 상태에 따라 이벤트를 처리할 수 있습니다.
- AFTER_COMMIT (default): 트랜잭션이 commit 되었을 때 이벤트 실행
- AFTER_ROLLBACK: 트랜잭션이 rollback 되었을 때 이벤트 실행
- AFTER_COMPLETION: 트랜잭션이 종료(commit 또는 rollback)되었을 때 이벤트 실행
- BEFORE_COMMIT: 트랜잭션이 commit 되기 전에 이벤트 실행
이 점을 이용하여, 이벤트가 톡픽을 저장하는 트랜잭션 커밋 이후에 처리되도록 했습니다.
이벤트 기반 아키텍처 적용 결과
이벤트 기반 아키텍처로 개선한 후 다시 부하 테스트를 진행한 결과, 모든 요청이 실패 없이 완료되었음을 확인할 수 있었습니다.

느낀점
이번 트러블슈팅 경험을 통해, 적용하려는 기술의 동작 원리와 관련 CS 지식에 대한 깊은 이해가 필수적임을 다시 한번 깨달았습니다.
또한, 문제를 해결하는 과정에서 당장의 이슈를 해결하는 것뿐만 아니라, 새로운 위험 요소를 초래할 가능성은 없는지 신중히 검토하는 것이 중요하다는 점도 배웠습니다.
다음에는 메시지 큐를...
요즘 많은 서비스가 전환중인 MSA 환경에서는 서비스 간의 결합도를 낮추고 독립적인 확장을 가능하게 하기 위해 메시지 브로커(Kafka, RabbitMQ, AWS SQS 등)를 활용한다고 하는데요. 우리 서비스의 규모와 가용 시간 대비 구현 복잡도가 높아 이번 문제 해결 과정에서는 적용하지 못했습니다.
향후 시스템이 더 확장되거나 요구사항이 변경될 경우 메시지 큐를 활용한 접근 방식도 적극적으로 고려해볼 계획입니다.
