# 1. requests & BeautifulSoup 다루기
##requests 라이브러리
접근할 웹 페이지의 데이터를 요청/응답받기 위한 라이브러리
import requests as req
# 1. 수집할 웹 페이지의 주소 정의
url = 'https://www.naver.com'
# 2. 라이브러리를 이용해서 웹 페이지 요청
# HTTP상태코드
# -200 : 성공
# -400 : 클라이언트 오류
# -500 : 서버오류
res = req.get(url)
res
# 3. 웹페이지 확인하기
res.text
##BeautifulSOUP 라이브러리
웹페이지에서 원하는 데이터를 추출하기 쉽게 Phython객체로 변환해주는 라이브러리
from bs4 import BeautifulSoup as bs
# 4. 문자열로 된 웹 페이지 데이터를 객체로 변환
# bs(변환할 데이터, 변환방식)
# -변환할 데이터 : 응답받은 웹 페이지 데이터
# -변환방식 : Python 객체로 변환 lxml > html.parse > html5lib
html = bs(res.text,'lxml'
html
type(res.text)
type(bs(res.text,'lxml'))
# 원하는 데이터 추출하기
html.select_one('title')
# select_one(CSS선택자) : 선택자에 해당하는 하나의 요소를 반환하는 함수
# -접근한 요소의 내용만 접근
html.select_one('title').text
# select(CSS선택자) : 선택자에 해당하는 모든 요소를 반환하는 함수
# -요소의 내용 접근 시 인덱스를 통해 하나씩 접근해야한다.
html.select('title')[0].text
##네이버 날씨 온도 가져오기
search_url = 'https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query=%EA%B4%91%EC%A3%BC+%EB%82%A0%EC%94%A8'
res = req.get(search_url)
res
html = bs(res.text,'lxml')
html
html.select_one('div.temperature_text>strong').text
## 뉴스 제목 가져오기 실습
html = bs(res.text,'lxml')
html
news_list = html.select('a.news_tit')
for(news in news_list:
print(nes.text)
## 뉴스의 제목과 내용 가져오기 실습
nes_url = 'https://n.news.naver.com/mnews/article/081/0003401339?sid=105'
# 1. 웹 페이지 요청
res = req.get(news_url)
# 2. 문자열 데이터 ㅡ> Python 객체로 변환
html = bs(res.text,'lxml')
res
html
title = html.select_one('#title_area>span')
print(title.text)
contents = html.select_one('#dic_area')
print(contents.text.strip().replace('\n',''))
## 네이버 뉴스 헤드라인 URL 가져오기
naver_news_url = 'https://news.naver.com/main/main.naver?mode=LSD&mid=shm&sid1=105'
res = req.get(naver_news_url)
# RemoteDisconnected 오류 해결방법
# -브라우저로 요청을 보냈다라는것을 서버에서 인식할 수 있도록
# user-agent 값을 구성하고 보내줘야한다!
header_option ={
'user-agent' : 'Mozilla/5.0(Windows NT 10.0;Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36'}
res = req.get(naver_new_url, headers = header_option)
res
html = bs(res.text, 'lxml')
html
headline_list = html.select('a.sh_text_headline')
# 요소의 속성값 가져오기
# 요소객체[속성명]
headline_list[0]['href']
# 각 헤드라인 기사의 url을 수집한 후 h_url_list에 추가하기
h_url_list = []
#for a in headline_list:
# h_url_list.append(a['href'])
for i in range(len(headline_list)):
h_url_list.append(healine_list[i]['href'])
print(h_url_list)
## 수집된 헤드라인 url을 활용하여 뉴스제목, 내용 가져오기
for url in h_rul_list :
res = req.get(url, headers = header_option)
html = bs(res.text,'lxml')
title = html.select_one('#title_area>span')
contents = html.select_one(#dic_area')
print('제목 : ',title.text)
print('내용 : ',contents.text.strip().replace('\n',''))
print()멜론Top 100 음원 데이터 수집
#멜론 Top 100 음원 데이터 수집
- 수집할 정보 : 순위, 노래제목, 아티스트
- 수집 완료 시, DataFrame으로 만든 후 출력
import pandas as pd
import requests as req
from bs4 import BeautifulSoup as bs
header_option = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36'
}이 코드는 Python을 사용하여 웹 스크래핑을 수행하고 데이터를 가공하기 위해 필요한 라이브러리를 가져와 사용하는 예제입니다. 아래는 코드의 각 부분을 한국어로 설명한 것입니다:
-
import pandas as pd: Pandas 라이브러리를 가져와서 'pd'로 별칭(alias)을 지정합니다. Pandas는 데이터 분석 및 조작에 사용되는 라이브러리로, 데이터프레임을 다루는데 유용합니다. -
import requests as req: 'requests' 라이브러리를 가져와서 'req'로 별칭을 지정합니다. 이 라이브러리는 웹에서 데이터를 가져오는 HTTP 요청을 보내는데 사용됩니다. -
from bs4 import BeautifulSoup as bs: 'BeautifulSoup' 클래스를 'bs'라는 이름으로 가져옵니다. 이 클래스는 HTML 문서를 파싱하고 원하는 정보를 추출하는데 사용됩니다. -
header_option: 웹 스크래핑을 할 때 HTTP 요청 헤더를 정의하는 딕셔너리입니다. 이 헤더는 웹 사이트에 요청을 보낼 때 사용자 에이전트(user-agent)와 함께 보내집니다. 이 헤더는 웹 스크래핑을 하는 동안 웹 사이트 관리자에게 사용자 에이전트가 웹 브라우저인 것처럼 보이도록 하는 역할을 합니다. -
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36': HTTP 요청 헤더의 'user-agent' 필드에 할당된 값으로, 이 부분은 사용자 에이전트를 설정하는 부분입니다. 웹 스크래핑 시에 사용자 에이전트를 설정하여 웹 서버로부터 데이터를 가져오는 동안 브라우저처럼 동작하도록 만듭니다.
이 코드는 웹 스크래핑을 위한 기본 설정을 정의하고 필요한 라이브러리를 가져온 후, 나중에 웹 페이지에서 데이터를 가져와 데이터 분석 및 가공에 사용할 수 있게 합니다.
melon_url = 'https://www.melon.com/chart/index.htm'
res = req.get(melon_url, headers = header_option)
html = bs(res.text,'lxml')위 코드는 파이썬을 사용하여 웹 페이지에서 데이터를 스크레이핑하는 작업을 수행하는 것으로 보입니다. 각 줄의 코드를 한국어로 설명하겠습니다:
-
melon_url = 'https://www.melon.com/chart/index.htm':melon_url변수에 Melon 뮤직 차트 웹 페이지의 URL 주소를 저장합니다. 이 주소는 Melon 뮤직 차트의 홈페이지를 가리킵니다. -
res = req.get(melon_url, headers=header_option):req라이브러리를 사용하여melon_url에 정의된 URL 주소로 GET 요청을 보내고, 응답을res변수에 저장합니다. 이때,header_option변수에 정의된 HTTP 헤더 정보를 요청에 포함시킵니다. HTTP 헤더는 요청의 메타데이터와 사용자 에이전트 정보 등을 포함하는데, 이것을 사용하여 웹 페이지에 대한 요청을 커스터마이즈할 수 있습니다. -
html = bs(res.text, 'lxml'):bs함수를 사용하여res객체에서 받아온 웹 페이지의 텍스트를 파싱하고, 파싱된 결과를html변수에 저장합니다. 'lxml'은 파싱을 수행하는 데 사용되는 파서로, HTML 문서를 효율적으로 해석하기 위한 도구입니다. 이렇게 파싱된 데이터를 나중에 사용하여 원하는 정보를 추출할 수 있게 됩니다.
#순위 가져오기
ranks = html.select('td span.rank')이 코드는 HTML 문서에서 특정 요소를 선택하는 작업을 수행하는 것으로 보입니다. 코드의 구체적인 설명은 다음과 같습니다:
-
ranks변수를 선언합니다. 이 변수는 HTML 문서에서 특정 요소들을 선택한 결과를 저장할 것입니다. -
html.select()메서드를 사용하여 HTML 문서에서 원하는 요소를 선택합니다. 이 메서드는 CSS 선택자를 인수로 받아 해당 선택자에 일치하는 요소들을 찾아 반환합니다. -
td span.rank는 CSS 선택자입니다. 이 선택자는 다음과 같이 해석됩니다:td: HTML<td>요소를 선택합니다.span.rank: 선택된<td>요소 내부에서<span>요소 중 클래스가 "rank"인 것을 선택합니다.
따라서, 이 코드는 HTML 문서에서 <td> 요소 내부에 있는 클래스가 "rank"인 <span> 요소를 모두 선택하여 ranks 변수에 저장하게 됩니다. 이렇게 선택된 요소들은 후속 작업에서 사용될 것으로 예상됩니다.
python
#노래제목 가져오기
song_titles = html.select('.ellipsis.rank01 > span > a')주어진 코드는 Python을 사용하여 웹 페이지에서 노래 제목을 가져오기 위해 사용되는 코드 스니펫입니다. 아래에 각 줄의 설명을 한국어로 제공해 드리겠습니다.
-
song_titles = html.select('.ellipsis.rank01 > span > a'):- 이 줄은
html변수에서 CSS 선택자를 사용하여 노래 제목을 가져와song_titles라는 변수에 저장하는 코드입니다. html은 웹 페이지의 HTML 코드가 들어있는 객체 또는 변수일 것이며, 이 코드에서는 웹 페이지의 HTML을 어떻게 가져왔는지에 대한 정보가 누락되어 있습니다.
- 이 줄은
-
.select('.ellipsis.rank01 > span > a'):- 이 부분은 CSS 선택자를 사용하여 웹 페이지에서 원하는 요소를 선택하는 부분입니다.
.ellipsis.rank01 > span > a는 CSS 클래스가 "ellipsis"와 "rank01"인 요소 안에 있는<span>태그 안에 있는<a>태그를 선택합니다.- 이것은 일반적으로 웹 페이지에서 노래 제목이 포함된 링크를 선택하는 방법 중 하나일 것입니다.
이 코드를 사용하려면 웹 페이지에서 html 변수를 어떻게 가져왔는지에 대한 정보가 필요하며, 이 코드는 BeautifulSoup 또는 다른 웹 스크래핑 라이브러리와 함께 사용될 것입니다. 이 코드는 웹 페이지에서 특정 요소를 선택하고 그 요소에서 노래 제목을 추출하는 데 도움을 줄 것입니다.
python
#아티스트 가져오기
artists = html.select('.ellipsis.rank02 > span')이 코드는 웹 페이지에서 아티스트 정보를 가져오는 작업을 수행하는 파이썬 코드를 보여줍니다. 코드의 주요 부분은 HTML 요소를 추출하는 것입니다. 아래는 코드의 각 부분에 대한 설명입니다:
-
artists변수 선언:- 이 부분은
artists라는 변수를 선언하고, 웹 페이지에서 아티스트 정보를 추출하여 저장할 것을 나타냅니다.
- 이 부분은
-
html.select('.ellipsis.rank02 > span'):- 이 부분은 BeautifulSoup 라이브러리를 사용하여 웹 페이지의 HTML에서 원하는 정보를 선택하는 부분입니다.
.select()메서드는 CSS 선택자를 사용하여 특정 HTML 요소를 선택합니다.'.ellipsis.rank02 > span'는 CSS 선택자로, 웹 페이지에서 클래스가 "ellipsis"와 "rank02"인 요소의 하위에 있는<span>요소를 선택하라는 의미입니다.
따라서, 이 코드는 웹 페이지에서 클래스가 "ellipsis"와 "rank02"인 요소의 하위에 있는 <span> 요소를 선택하여 아티스트 정보를 추출하고, 이 정보를 artists 변수에 저장하는 역할을 합니다.
len(ranks),len(song_titles),len(artists)len(ranks), len(song_titles), len(artists)는 각각 Python 프로그램에서 리스트 또는 배열의 길이를 계산하는 코드입니다. 다음은 각 코드의 설명입니다.
-
len(ranks): 이 코드는ranks라는 리스트 또는 배열의 길이를 계산합니다. 즉,ranks리스트에 저장된 요소의 개수를 반환합니다. 예를 들어, 만약ranks리스트에 순위 정보가 들어 있다면, 이 코드는 순위 목록의 길이를 반환합니다. -
len(song_titles): 이 코드는song_titles라는 리스트 또는 배열의 길이를 계산합니다. 따라서song_titles리스트에 저장된 노래 제목의 개수를 반환합니다. -
len(artists): 이 코드는artists라는 리스트 또는 배열의 길이를 계산합니다.artists리스트에 저장된 아티스트(가수 또는 밴드)의 개수를 반환합니다.
이 코드들을 사용하면 리스트의 크기를 알 수 있으며, 데이터 분석 및 처리에 유용하게 활용할 수 있습니다.
rank_list = []
song_title_list = []
artist_list = []
for i in range(len(ranks)):
# print(ranks[i].text)
# print(song_titles[i].text)
# print(artists[i].text)
# print()
rank_list.append(ranks[i].text)
song_title_list.append(song_titles[i].text)
artist_list.append(artists[i].text)
len(rank_list), len(song_title_list), len(artist_list)이 코드는 세 개의 빈 리스트인 rank_list, song_title_list, 그리고 artist_list를 만들고, 이 리스트들을 채우는 작업을 수행하는 파이썬 코드입니다. 이 코드를 한국어로 설명해드리겠습니다:
-
rank_list,song_title_list,artist_list라는 빈 리스트를 만듭니다.rank_list: 노래의 순위 정보를 저장할 리스트song_title_list: 노래 제목 정보를 저장할 리스트artist_list: 노래의 아티스트 정보를 저장할 리스트
-
for루프를 사용하여ranks리스트의 길이만큼 반복합니다.ranks리스트는 노래의 순위 정보가 있는 것으로 가정합니다. -
주석 처리된 부분은 각 루프 반복에서
ranks,song_titles, 그리고artists리스트의 요소를 출력하는 부분입니다. 이 부분은 주석 처리되어 있으므로 현재 코드 실행에는 영향을 주지 않습니다. -
rank_list,song_title_list, 그리고artist_list에 각각ranks[i].text,song_titles[i].text, 그리고artists[i].text를 추가합니다. 여기서i는 루프 반복의 인덱스를 나타냅니다. -
len(rank_list),len(song_title_list), 그리고len(artist_list)를 사용하여 각 리스트의 길이를 반환합니다. 이것은 각 리스트에 저장된 데이터의 수를 나타냅니다.
따라서 이 코드는 ranks, song_titles, 그리고 artists 리스트로부터 노래의 순위, 제목, 아티스트 정보를 추출하여 각각의 리스트에 저장하는 작업을 수행합니다. 마지막으로, 각 리스트의 길이를 확인하여 데이터의 수를 확인할 수 있습니다.
melon_dic = {
'순위':rank_list,
'노래제목':song_title_list,
'아티스트':artist_list
}주어진 코드는 파이썬에서 사용되는 딕셔너리를 만드는 예제입니다. 딕셔너리는 키-값 쌍을 저장할 수 있는 데이터 구조입니다. 주어진 코드에서는 세 개의 리스트(rank_list, song_title_list, artist_list)를 사용하여 딕셔너리를 만들고 있습니다. 각 리스트에는 멜론 음악 차트의 정보가 들어가겠죠.
이 딕셔너리를 설명하면 다음과 같습니다:
-
'순위' 키:
rank_list변수의 값을 값으로 가지고 있습니다. 이 키는 음악 차트에서 각 노래의 순위를 나타내는 데이터를 저장합니다. -
'노래제목' 키:
song_title_list변수의 값을 값으로 가지고 있습니다. 이 키는 음악 차트에서 각 노래의 제목을 나타내는 데이터를 저장합니다. -
'아티스트' 키:
artist_list변수의 값을 값으로 가지고 있습니다. 이 키는 음악 차트에서 각 노래의 아티스트 이름을 나타내는 데이터를 저장합니다.
이렇게 딕셔너리를 사용하면 각 정보를 논리적으로 그룹화하고, 각각의 정보에 쉽게 접근할 수 있게 됩니다.
melon_df = pd.DataFrame(melon_dic)
melon_df.head()이 코드는 Python 프로그래밍 언어를 사용하여 데이터 분석 및 조작을 위한 pandas 라이브러리를 활용하는 것으로 보입니다. 여기서 주어진 코드를 각 줄별로 한국어로 설명해 드리겠습니다.
-
melon_df = pd.DataFrame(melon_dic): 이 줄은pd라는 이름의 판다스 라이브러리를 가져와서 사용한다고 가정합니다.melon_dic라는 데이터로부터 새로운 데이터 프레임(DataFrame)을 생성합니다. 데이터 프레임은 표 형태의 데이터 구조로, 여기에서는melon_dic이라는 데이터를 사용하여 새로운 데이터 프레임을 생성하고 이를melon_df라는 변수에 할당합니다. -
melon_df.head(): 이 코드는melon_df데이터 프레임의 처음 몇 개의 행을 출력하는 역할을 합니다.head()함수는 데이터 프레임의 상위 5개 행(기본값)을 기본적으로 반환하며, 표시할 행 수를 지정할 수도 있습니다. 이것을 사용하여 데이터 프레임의 처음 몇 행을 확인할 수 있습니다.
즉, 주어진 코드는 melon_dic라는 데이터로부터 데이터 프레임을 생성하고, 그 데이터 프레임의 처음 몇 개의 행을 출력하는 것입니다. 이를 통해 데이터를 살펴보고 분석하는데 도움이 됩니다.
melon_df.to_excel('멜론차트_Top100.xlsx', index=False)이 코드는 Python 프로그래밍 언어를 사용하여 데이터프레임을 Excel 파일로 저장하는 명령입니다. 여기에서 "melon_df"는 데이터프레임 객체를 나타내며, ".to_excel" 메서드를 사용하여 데이터프레임을 Excel 파일로 내보냅니다. 이 메서드의 인자로는 다음과 같은 내용이 들어갑니다:
-
'멜론차트_Top100.xlsx': 이 부분은 Excel 파일의 이름을 지정하는 곳입니다. 여기서는 '멜론차트_Top100.xlsx'로 파일명을 설정했습니다. 이 이름은 필요에 따라 다른 이름으로 변경할 수 있습니다.
-
index=False: 이 부분은 데이터프레임에서 행 번호(index)를 Excel 파일에 포함하지 않도록 하는 옵션입니다. 즉, Excel 파일에 저장될 때 행 번호가 열로 추가되지 않습니다.
따라서, 이 코드는 'melon_df' 데이터프레임을 '멜론차트_Top100.xlsx'라는 이름의 Excel 파일로 저장하며, 행 번호는 파일에 포함되지 않습니다.
포켓몬 이미지 수집
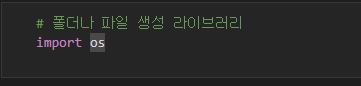
"import os"는 폴더나 파일생성 라이브러입니다. 운영 체제와 파일 시스템 관련 작업을 수행할 때 필요한 함수 및 메서드에 액세스할 수 있으며, 이러한 기능을 통해 파일 및 디렉토리 관리를 프로그램에 통합할 수 있습니다.
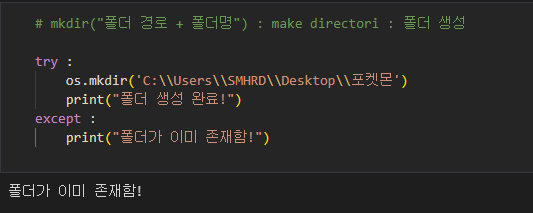
try:: 이 부분은 예외(에러)가 발생할 수 있는 코드를 감싸는 부분을 나타냅니다. 코드를 실행하면서 예외가 발생하면 except 블록이 실행됩니다.
os.mkdir('C:\Users\SMHRD\Desktop\포켓몬'): 이 부분은 실제로 폴더를 생성하는 부분입니다. os 모듈을 사용하여 mkdir 함수를 호출합니다. 이 함수는 인자로 전달된 경로에 폴더를 생성하려고 시도합니다. 여기서 전달된 경로는 'C:\Users\SMHRD\Desktop\포켓몬'로 지정되어 있습니다. 'C:\Users\SMHRD\Desktop'는 사용자의 데스크톱 경로를 나타내며, '포켓몬'은 새로 생성하려는 폴더의 이름입니다.
print("폴더 생성 완료!"): 폴더 생성에 성공한 경우, "폴더 생성 완료!"라는 메시지를 출력합니다.
except:: 이 부분은 try 블록에서 예외가 발생했을 때 실행되는 부분을 나타냅니다.
print("폴더가 이미 존재함!"): 폴더 생성에 실패하고 예외가 발생한 경우, "폴더가 이미 존재함!"라는 메시지를 출력합니다.
코드의 목적은 'C:\Users\SMHRD\Desktop' 경로에 '포켓몬'이라는 이름의 폴더를 만드는 것입니다. os.mkdir 함수는 해당 경로에 폴더가 이미 존재하는 경우 예외가 발생할 수 있으며, 이러한 경우 예외를 처리하여 "폴더가 이미 존재함!" 메시지를 출력합니다. 그렇지 않으면 폴더가 성공적으로 생성되었다는 메시지를 출력합니다.
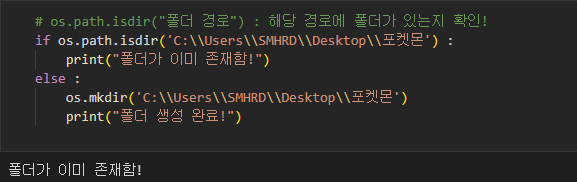
이 코드는 Python에서 폴더의 존재 여부를 확인하고, 폴더가 없을 경우 해당 경로에 새로운 폴더를 생성하는 작업을 수행합니다. 코드의 주요 부분을 하나씩 설명하겠습니다:
os.path.isdir('C:\Users\SMHRD\Desktop\포켓몬'): 이 부분은 주어진 경로에 폴더가 존재하는지 여부를 확인하는 것입니다. os.path.isdir() 함수는 주어진 경로가 폴더인 경우 True를 반환하고, 그렇지 않은 경우 False를 반환합니다.
if os.path.isdir('C:\Users\SMHRD\Desktop\포켓몬'):: 이 부분은 os.path.isdir() 함수를 사용하여 지정된 경로에 폴더가 있는지 확인합니다. 만약 해당 경로에 폴더가 이미 존재한다면, 이 조건문은 참(True)이 되고 다음 라인이 실행됩니다.
print("폴더가 이미 존재함!"): 이미 폴더가 존재하는 경우, 위의 조건문이 참이므로 이 메시지가 출력됩니다.
else:: 이 부분은 만약 폴더가 존재하지 않는 경우 실행됩니다.
os.mkdir('C:\Users\SMHRD\Desktop\포켓몬'): 이 부분은 os.mkdir() 함수를 사용하여 지정된 경로에 새로운 폴더를 생성합니다. 폴더가 존재하지 않는 경우, 이 라인이 실행되어 폴더를 생성합니다.
print("폴더 생성 완료!"): 폴더가 성공적으로 생성되면 이 메시지가 출력됩니다.
요약하면, 이 코드는 특정 경로에 폴더가 이미 존재하는지 확인하고, 폴더가 존재하지 않으면 새로운 폴더를 생성하는 작업을 수행합니다. 이것은 유용한 방법이며, 예를 들어 파일 또는 데이터를 저장하기 전에 폴더가 존재하는지 확인하고 필요한 경우 폴더를 생성하는 데 사용할 수 있습니다.
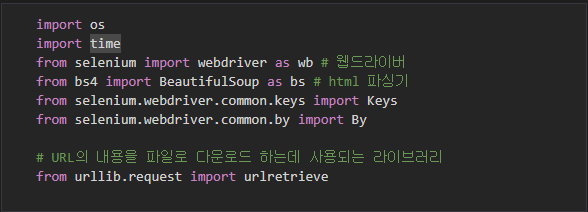
위의 코드는 Python에서 웹 스크래핑과 웹 자동화를 위해 사용되는 다양한 라이브러리를 import하고 있습니다. 아래는 각 라이브러리와 모듈의 역할에 대한 간단한 설명입니다:
-
import os:os모듈은 운영 체제와 상호 작용하기 위한 함수를 제공합니다. 파일 및 디렉토리 작업을 수행하는 데 사용될 수 있습니다. -
import time:time모듈은 시간 관련 함수와 메서드를 제공하며, 코드 실행을 지연시키거나 시간을 측정하는 데 사용될 수 있습니다. -
from selenium import webdriver as wb: Selenium은 웹 애플리케이션을 자동으로 테스트하거나 웹 페이지에서 데이터를 스크랩하는 데 사용되는 도구입니다.webdriver모듈은 웹 브라우저를 제어하고 웹 페이지와 상호 작용하는 데 사용됩니다. -
from bs4 import BeautifulSoup as bs: BeautifulSoup은 HTML 및 XML 문서를 파싱하고 데이터를 추출하는 데 사용되는 파싱 라이브러리입니다.BeautifulSoup모듈은 웹 스크래핑 시 웹 페이지의 HTML 내용을 분석하고 추출하는 데 사용됩니다. -
from selenium.webdriver.common.keys import Keys: Selenium에서 키보드 입력을 시뮬레이트하고 웹 페이지와 상호 작용하는 데 사용됩니다.Keys모듈은 특수 키 및 조합 키를 나타냅니다. -
from selenium.webdriver.common.by import By: Selenium에서 요소를 식별하는 데 사용되는 다양한 방법을 제공하는By모듈입니다. -
from urllib.request import urlretrieve:urlretrieve함수는 웹에서 파일을 다운로드하는 데 사용됩니다. 주어진 URL에서 파일을 가져와 로컬 디스크에 저장합니다.
이 코드에서는 이러한 라이브러리와 모듈을 사용하여 웹 페이지 스크랩, 웹 브라우저 자동화 및 파일 다운로드 작업을 수행하는 데 필요한 도구를 가져오고 있습니다.

이 코드는 Python을 사용하여 웹 브라우저를 자동화하는 Selenium 라이브러리를 활용하여 웹 페이지를 열고 특정 URL(https://www.pokemonkorea.co.kr/pokedex#pokedex_1)로 이동하는 것을 수행합니다. 코드는 다음과 같이 동작합니다:
-
wb.Chrome()를 사용하여 Chrome 웹 브라우저의 드라이버를 생성합니다. 이 드라이버는 Python 코드를 사용하여 웹 브라우징 작업을 자동화하는 데 사용됩니다. -
url변수에 "https://www.pokemonkorea.co.kr/pokedex#pokedex_1"을 할당합니다. 이 URL은 포켓몬 공식 웹사이트의 포켓몬 도감 페이지를 가리킵니다. -
driver.get(url)을 사용하여 Chrome 웹 브라우저를 열고url에 지정된 주소로 이동합니다. 이 동작은 해당 URL의 웹 페이지를 로드하고 표시합니다.
이 코드를 실행하면 Chrome 웹 브라우저가 열리고 "https://www.pokemonkorea.co.kr/pokedex#pokedex_1" 주소의 포켓몬 도감 페이지로 이동합니다. 이후에는 Selenium을 사용하여 웹 페이지에서 다양한 작업을 수행할 수 있습니다.

이 코드는 Python에서 웹 스크래핑(웹 페이지에서 데이터를 추출)을 수행하는 데 사용되는 BeautifulSoup 라이브러리를 사용하는 코드입니다. BeautifulSoup는 웹 페이지의 HTML 또는 XML 구조를 파싱하고 데이터를 추출하는 데 도움이 되는 도구입니다.
여기서 사용된 코드를 설명해보겠습니다:
-
soup = bs(driver.page_source, 'lxml'): 이 줄은 BeautifulSoup을 사용하여 웹 페이지의 HTML 또는 XML을 파싱하는 작업을 수행합니다. 코드는 다음과 같은 구성요소로 이루어져 있습니다:bs: BeautifulSoup 객체를 생성하는 함수입니다.driver.page_source:driver객체의page_source속성을 통해 현재 웹 페이지의 소스 코드(HTML 또는 XML)를 가져옵니다.driver는 아마 Selenium을 사용하여 웹 브라우저를 제어하는 객체일 것입니다.'lxml': HTML 또는 XML을 파싱하는 데 사용할 파서(parser)를 지정합니다. 'lxml'은 파서의 종류 중 하나로, 일반적으로 빠르고 유연한 파서로 알려져 있습니다. 다른 파서를 사용할 수도 있지만, 'lxml'은 많은 상황에서 잘 작동합니다.
-
soup: 이 코드 라인은 BeautifulSoup 객체를soup변수에 저장합니다. 이 객체는 웹 페이지의 구조를 파싱하고 데이터를 추출하기 위해 사용됩니다.
이제 soup 변수를 사용하여 웹 페이지에서 필요한 정보를 추출하거나 조작할 수 있습니다. BeautifulSoup를 사용하면 HTML 또는 XML 문서를 탐색하고 특정 요소를 검색하거나 텍스트 데이터를 추출하는 등의 작업을 쉽게 수행할 수 있습니다.
특정 Youtube채녈의 영상 데이터 수집
- 제목, 영상URL, 조회수

이 코드는 Python을 사용하여 웹 자동화를 수행하는 데 사용되는 Selenium 라이브러리를 사용하고 있습니다. Selenium은 웹 브라우저를 제어하고 웹 페이지와 상호 작용하는 데 도움을 주는 라이브러리로, 주로 웹 스크래핑, 웹 테스트 자동화 및 웹 데이터 수집에 사용됩니다.
코드의 각 부분을 설명해보겠습니다:
import time: Python의 time 모듈을 가져옵니다. 이 모듈은 시간과 관련된 함수를 제공합니다. 코드에서는 시간 지연을 생성하는 데 사용됩니다.
from selenium import webdriver as wb: Selenium 라이브러리에서 webdriver 모듈을 가져와서 이를 wb로 별칭(alias) 지정합니다. 이 모듈은 웹 브라우저를 제어하는 데 사용됩니다.
from selenium.webdriver.common.keys import Keys: selenium.webdriver.common.keys 모듈에서 Keys 클래스를 가져옵니다. 이 클래스는 특수 키 입력(Enter, Escape 등)을 처리하는 데 사용됩니다.
from selenium.webdriver.common.by import By: selenium.webdriver.common.by 모듈에서 By 클래스를 가져옵니다. 이 클래스는 웹 요소를 식별하는 데 사용되는 다양한 방법을 정의합니다.

주어진 코드는 Python에서 문자열 변수 yt_url을 정의하는 코드입니다. 이 변수에는 YouTube 채널 또는 사용자의 URL이 저장되어 있습니다.
주어진 URL은 'https://www.youtube.com/@hoseobiiiiiii._.0410/videos'입니다. 이 URL은 YouTube의 특정 사용자 또는 채널의 동영상 목록을 가리키는 것으로 보입니다.
코드는 단순히 이 URL을 문자열 변수에 저장한 것이며, URL 자체에 대한 HTTP 요청이나 다른 작업을 수행하지는 않습니다. 이 코드를 통해 yt_url 변수에 URL을 저장하고, 이 URL을 나중에 사용하여 YouTube 채널 또는 사용자의 동영상 목록에 액세스하는 데 사용할 수 있습니다.
실제로 이 URL을 사용하여 웹 스크래핑을 수행하거나 YouTube API를 통해 데이터를 가져오는 등의 추가 작업을 수행할 수 있을 것입니다. 코드의 목적 및 사용 방법은 yt_url 변수가 어떻게 활용될 것인지에 따라 달라질 것입니다.
driver = wb.Chrome():
wb라는 별칭을 사용하여 Selenium의 웹 드라이버를 생성합니다. 이 코드는 Chrome 웹 브라우저를 자동화하기 위해 Chrome 웹 드라이버를 사용합니다.
즉, 이 코드는 Chrome 웹 브라우저를 열고 조작할 수 있는 인스턴스를 생성합니다.
driver.get(yt_url):
driver 객체를 사용하여 웹 페이지를 엽니다. 이 명령은 yt_url 변수에 저장된 URL로 이동합니다.
yt_url은 YouTube 동영상 페이지의 URL을 나타내며, 코드 실행 중에 해당 페이지로 이동합니다.
따라서 이 코드는 Chrome 웹 브라우저를 열고, 지정된 YouTube 동영상 페이지(yt_url)로 이동합니다. 이를 통해 코드는 웹 페이지를 자동화하고 필요한 작업을 수행할 수 있습니다. 이 작업은 웹 스크래핑, 웹 페이지 조작, 데이터 수집 및 기타 웹 관련 작업을 자동으로 수행하는 데 사용됩니다.

driver.maximize_window() 코드는 Selenium을 사용하여 웹 브라우저 창을 최대화하는 명령입니다. 이 명령을 사용하면 현재 웹 브라우저 창을 사용 가능한 최대 크기로 확장합니다.
##네이버 지도 검색 데이터 수집 실습 Selenium
웹 애플리케이션을 테스트하고 웹 브라우저를 자동화하는 데 사용되는 도구 및 라이브러리
selenium은 웹사이트 테스트를 위한 도구로 브라우저 동작을 자동화할 수 있습니다. 셀레니움을 이용하는 웹크롤링 방식은 바로 이점을 적극적으로 활용하는 것입니다. 프로그래밍으로 브라우저 동작을 제어해서 마치 사람이 이용하는 것 같이 웹페이지를 요청하고 응답을 받아올 수 있습니다.
import time #파이썬 프로그램에서 시간과 관련된 기능을 사용하기 위해 필요함
from selenium import webdriver as wb #웹 드라이버
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time은 파이썬 프로그램에서 시간과 관련된 기능을 사용하기 위해 필요한 코드입니다
from selenium import webdriver as wb는 Selenium 웹 자동화 라이브러리에서 webdriver 모듈을 wb로 별칭(alias) 지정하는 것을 의미합니다.
from selenium.webdriver.common.keys import Keys는 Selenium 웹 자동화 라이브러리에서 사용되는 Keys 클래스를 가져오는 코드입니다.
driver = wb.Chrome()은 Selenium을 사용하여 Chrome 웹 브라우저를 제어하기 위한 웹 드라이버를 초기화하고, 이 드라이버 객체를 'driver'변수에 할당하는 역할을 합니다. 이렇게 초기화된 driver 객체를 사용하여 웹 페이지를 불러오고 상호작용하며 웹 자동화 테스트를 수행할 수 있습니다.
driver.get(nvr_map_url)은 Selenium 웹 드라이버 객체인 driver를 사용하여 지정된 nvr_map_url 변수에 저장된 URL로 이동하고 해당 웹 페이지를 로드하는 작업을 수행합니다.

input_search = driver.find_element(By.CLASS_NAME, 'input_search')는 Selenium 웹 드라이버 객체(driver)에서 클래스 이름이 'input_search'인 웹 요소를 찾아서 해당 웹 요소를 input_search 변수에 할당하는 것을 수행합니다. 이렇게 하면 나중에 input_search 변수를 사용하여 해당 웹 요소와 상호작용할 수 있습니다.
input_search.send_keys('동명동 맛집\n')는 Selenium을 사용하여 웹 페이지의 검색 필드 (input_search)에 '동명동 맛집'을 입력하고 Enter 키를 눌러 검색을 실행하는 역할을 수행합니다.

driver.find_element(By.CSS_SELECTOR, 'span.place_bluelink.TYaxT')는 웹 드라이버 객체를 사용하여 해당 CSS 선택자로 웹 페이지에서 요소를 찾는 동작을 수행합니다. 이 코드는 첫 번째로 일치하는 요소를 반환하며, 이 요소는 span 태그이며 place_bluelink 및 TYaxT 클래스가 적용된 요소여야 합니다.

driver.switch_to.frame('searchIframe')는 현재 웹 페이지 내에서 이름이 'searchIframe'인 프레임으로 전환하는 명령입니다. 이것은 주로 웹 페이지 내에 중첩된 프레임이 있는 경우 해당 프레임으로 전환하여 프레임 내의 요소를 찾거나 조작할 때 사용됩니다.

store_titles = driver.find_elements(By.CSS_SELECTOR, 'span.place_bluelink.TYaxT')는 웹 드라이버(driver)를 사용하여 CSS 선택자를 통해 웹 페이지에서 조건을 만족하는 모든 요소를 찾아서 이를 store_titles 변수에 저장합니다. 이후에 store_titles 변수를 사용하여 이러한 웹 요소들에 대한 조작이나 정보 추출을 수행할 수 있습니다.
store_titles[1].text 코드는 store_titles 변수(또는 데이터 구조)에서 두 번째 항목을 선택하고, 그 항목에서 텍스트 데이터를 추출하는 것을 의미합니다. 이렇게 추출한 텍스트는 나중에 변수에 저장하거나 출력하는 등의 다양한 용도로 사용될 수 있습니다.

store_titles[1].click()는 store_titles 리스트(또는 배열)에서 두 번째 요소(인덱스 1)를 선택하고 해당 요소를 클릭하는 동작을 수행합니다. 클릭 가능한 요소는 주로 웹 페이지에서 링크 또는 버튼과 관련이 있으며, 클릭하면 해당 요소가 나타내는 작업이 실행됩니다.

driver.find_element(By.CSS_SELECTOR, 'span.PXMot.LXIwF') 코드는 Selenium 웹 드라이버 객체를 사용하여 웹 페이지에서 CSS 클래스 선택자 "span.PXMot.LXIwF"를 가지는 첫 번째 요소를 찾는 작업을 수행합니다. 이것은 웹 페이지의 특정 요소를 식별하고 가져올 때 사용됩니다.

driver.switch_to.default_content()을 사용하여 다른 창으로 전환한 후 원래의 상위 프레임 또는 창으로 돌아갈 수 있습니다. 이렇게 하면 원하는 프레임 또는 창에서 작업을 수행한 후에도 기본 컨텍스트로 돌아가서 웹 페이지 내의 다른 요소와 상호작용할 수 있습니다.

driver.switch_to.frame('entryIframe') 코드는 Selenium 웹 드라이버를 사용하여 현재 웹 컨텍스트를 'entryIframe'라는 이름 또는 식별자를 가진 프레임으로 전환하는 명령입니다. 이렇게 하면 이후에 웹 페이지 내에서 해당 프레임 내부의 요소에 접근하고 상호작용할 수 있습니다.

rate = driver.find_element(By.CSS_SELECTOR, 'span.PXMot.LXIwF')
rate.text[3:] 이 코드는 Selenium을 사용하여 웹 페이지에서 특정 CSS 선택자에 해당하는 요소를 찾고, 그 요소의 텍스트 내용을 추출한 다음, 그 텍스트의 세 번째 문자부터 끝까지의 부분을 rate 변수에 저장합니다.
