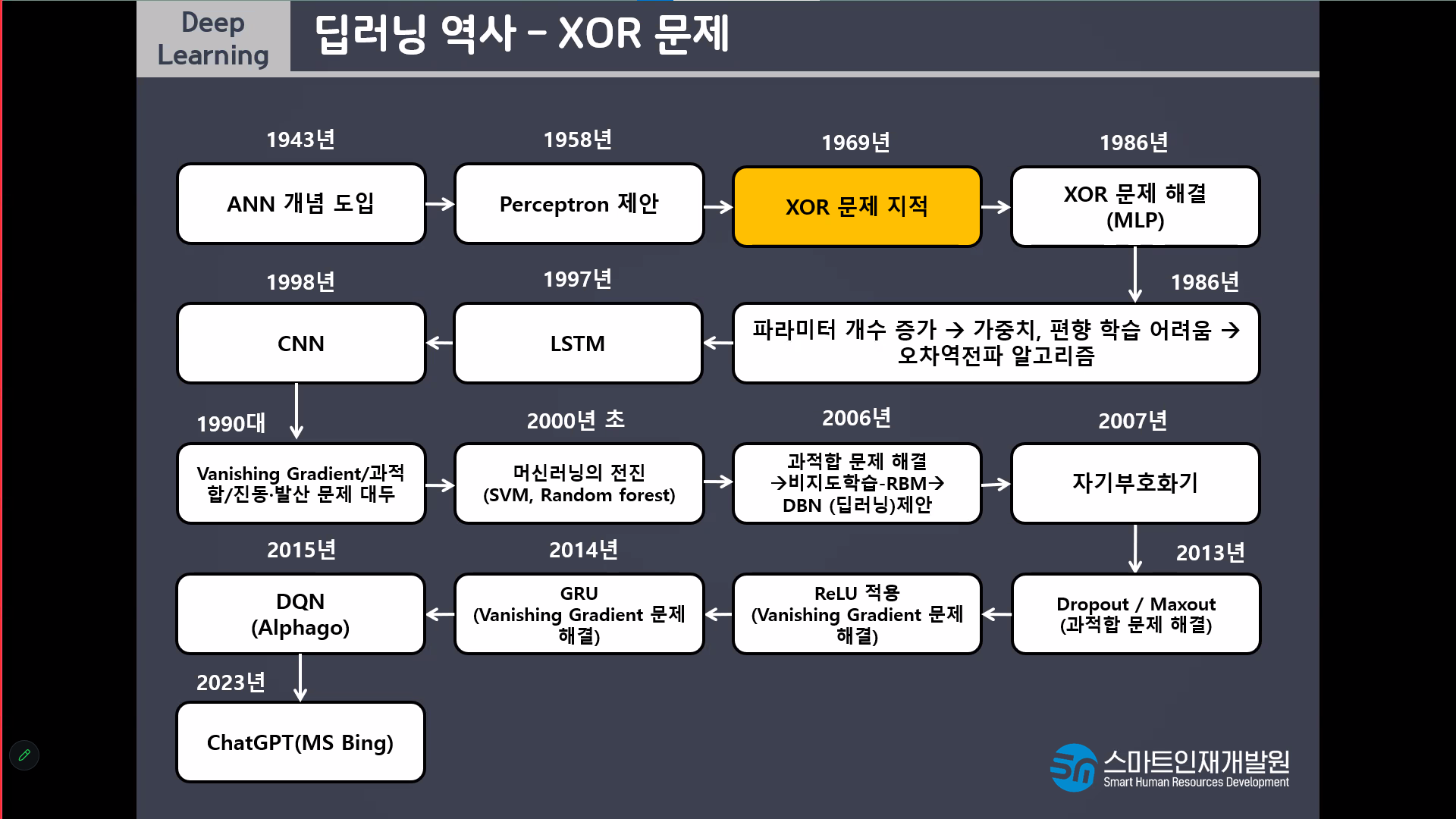
딥러닝

![]
(https://velog.velcdn.com/images/hjoo/post/c59a29a0-5344-4f2e-b8e0-72d166d35cc7/image.png)
머신러닝(기계학습)기계가 생각을 함으로써 데이터 안에서 규칙을 찾는것.
새로운 데이터가 들어왔을때 예측을 함.
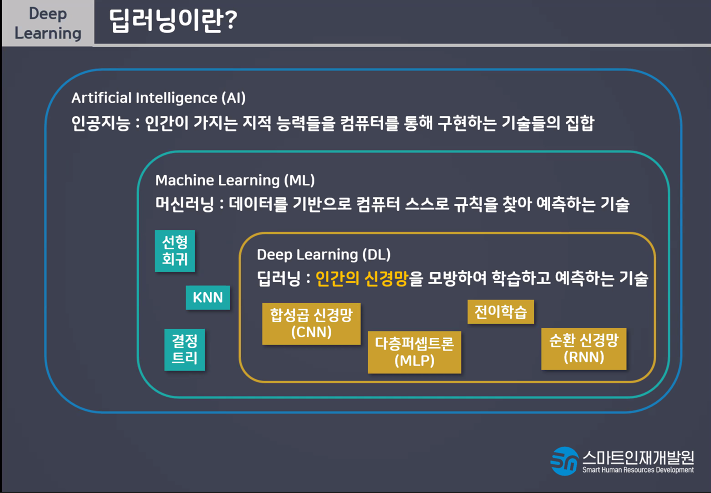
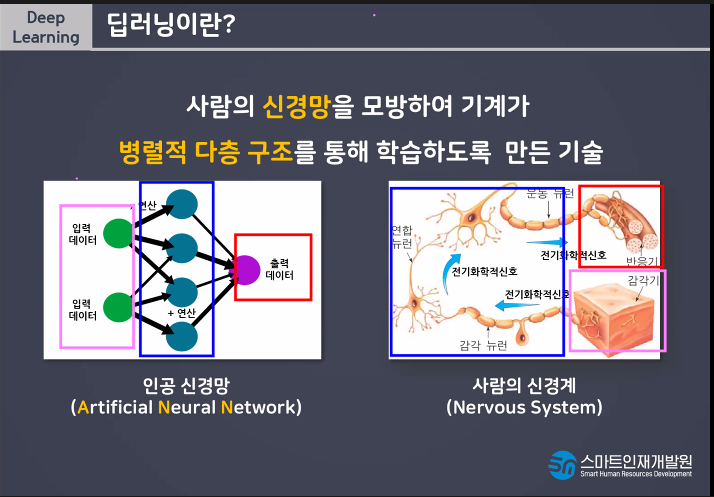
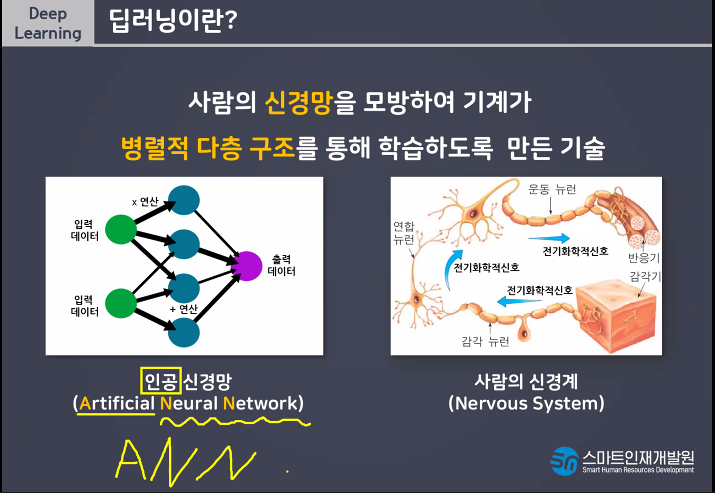
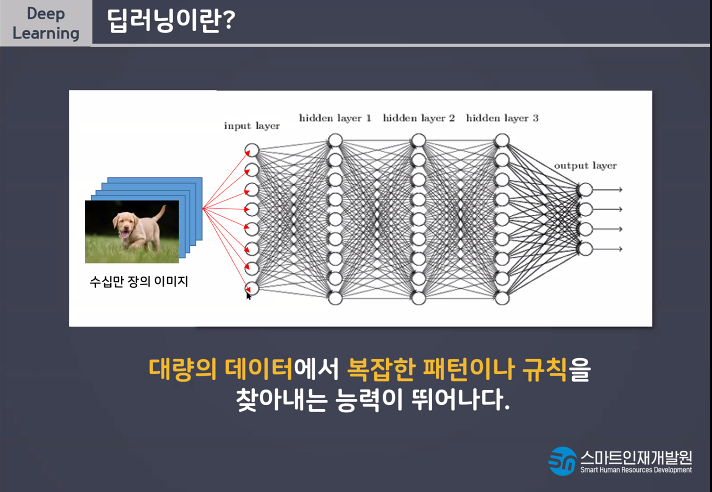
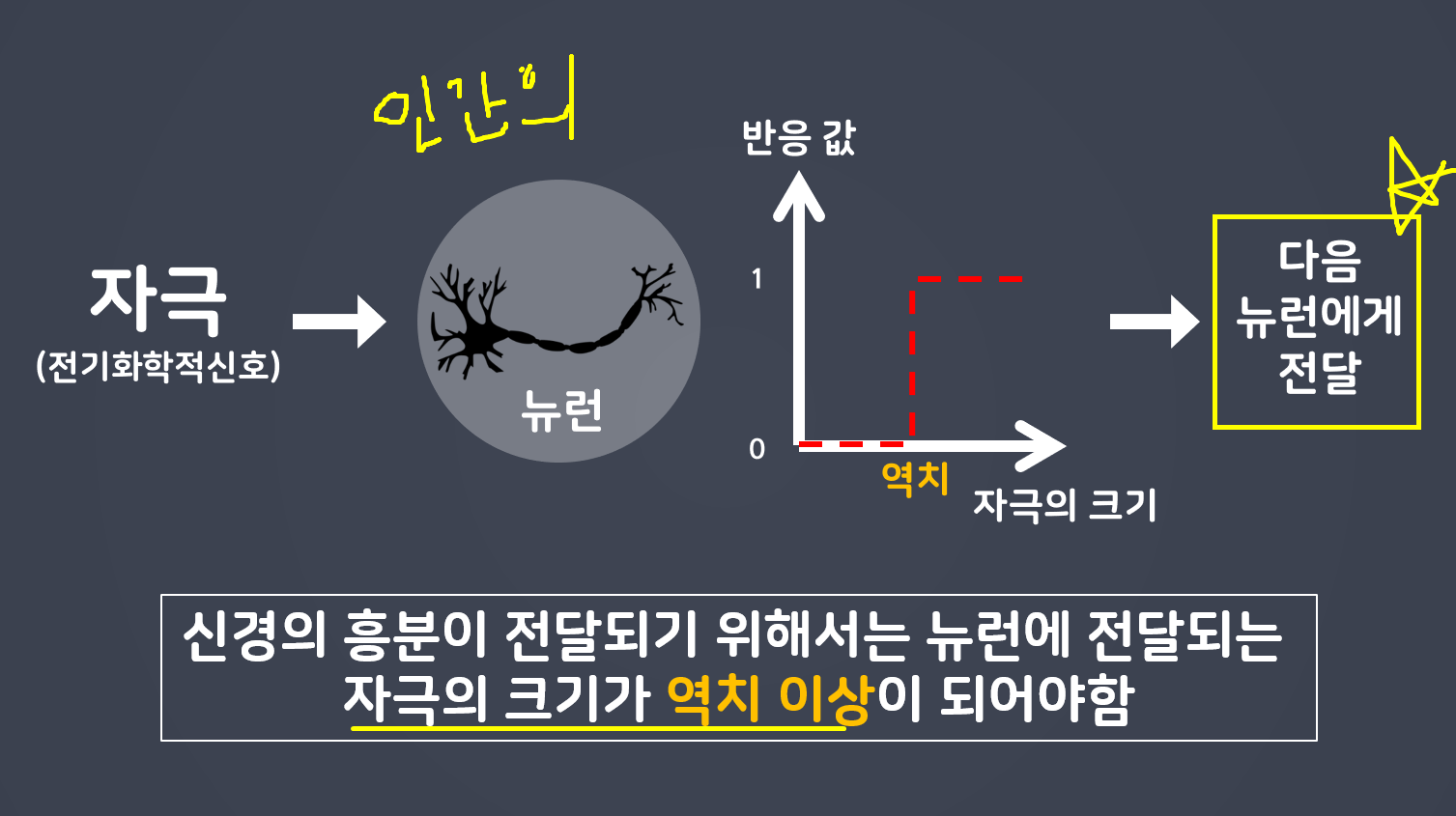
딥러닝이란 사람의 신경망을 모방하여 기계가 병렬적 다층 구조를통해 학습하도록 만든 기술
{kind=link}
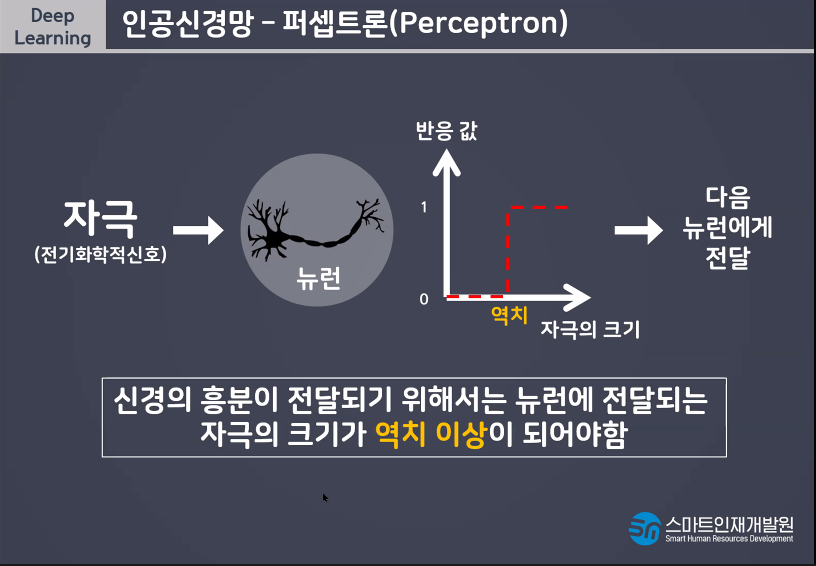
감각기 부분이 입력층이라고 생각해라
전기화학신호를 통해서 연산을 하는데 그 부분이 가운데(파란색) 반응기가 출력층이다.
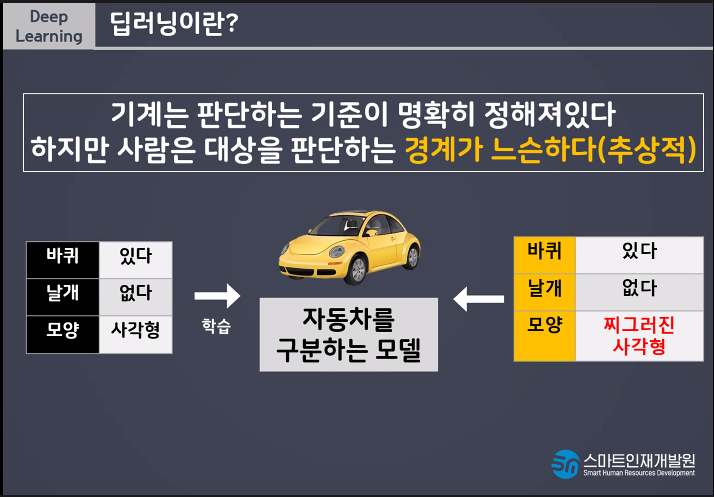
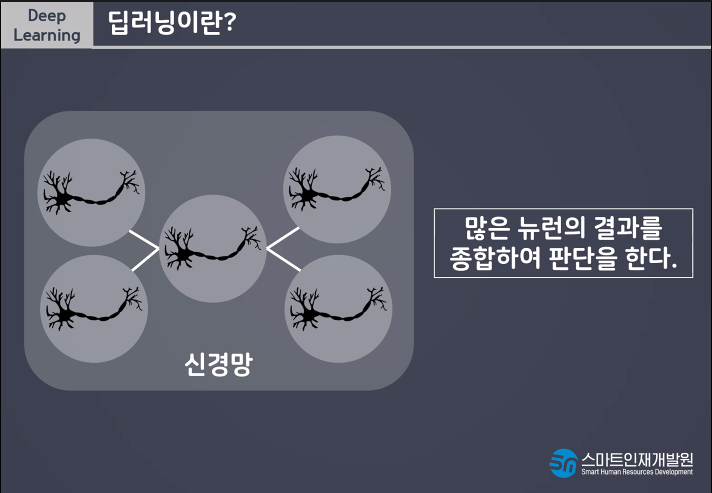
유연한 사고를 한다!!
사람처럼 학습하게 하려면 어떻게 해야할까?!?!?!?!
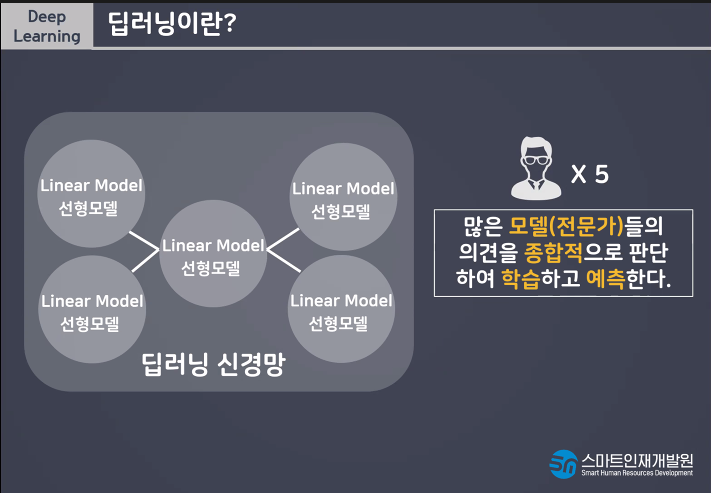
선형모델 하나만 사용하는것이 아니라 더 많은 선형모델을 사용함으로써 유연한 사고가 가능하다.

perceptron이란?
왜 perceptron이 나오게되었을까?
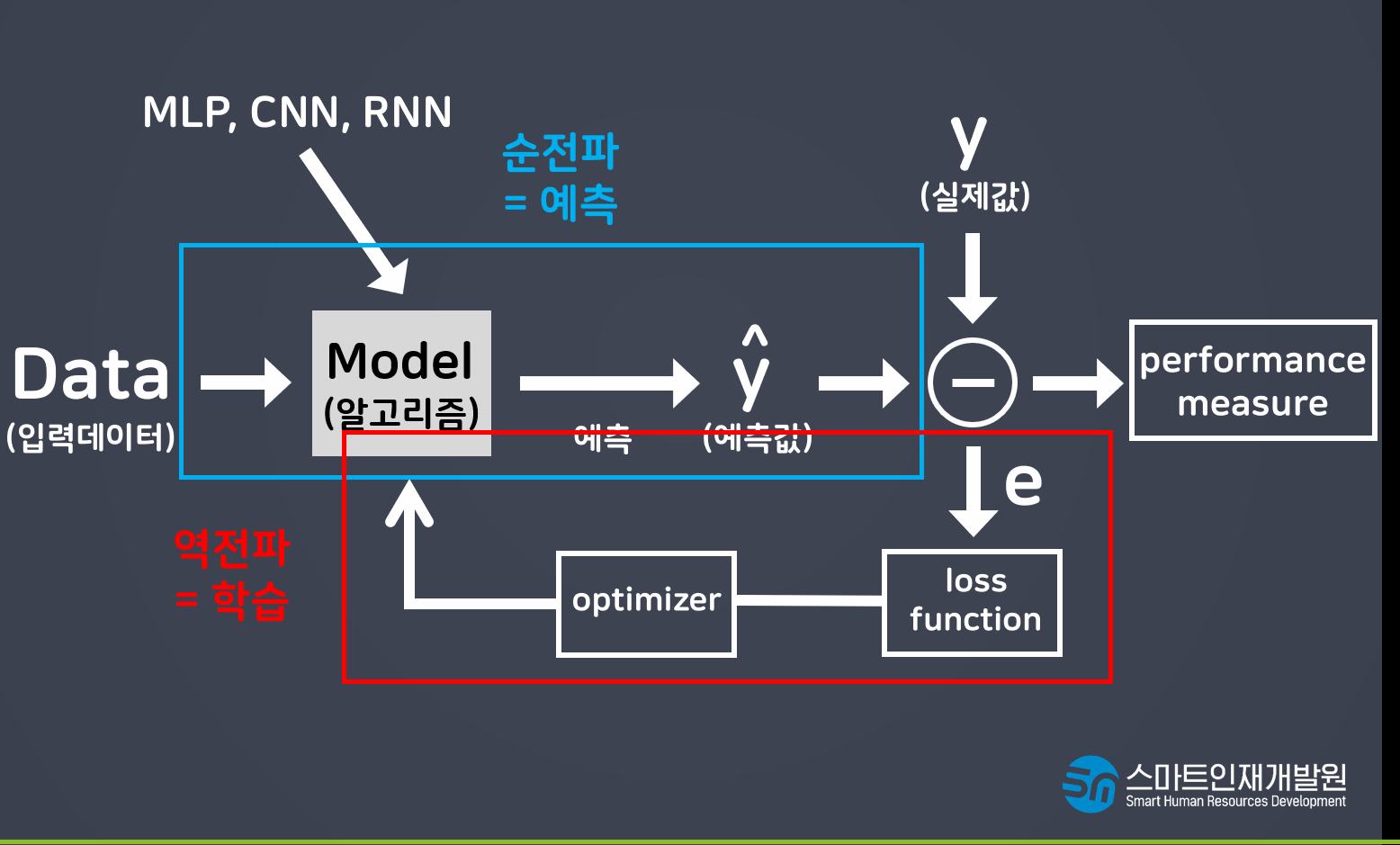
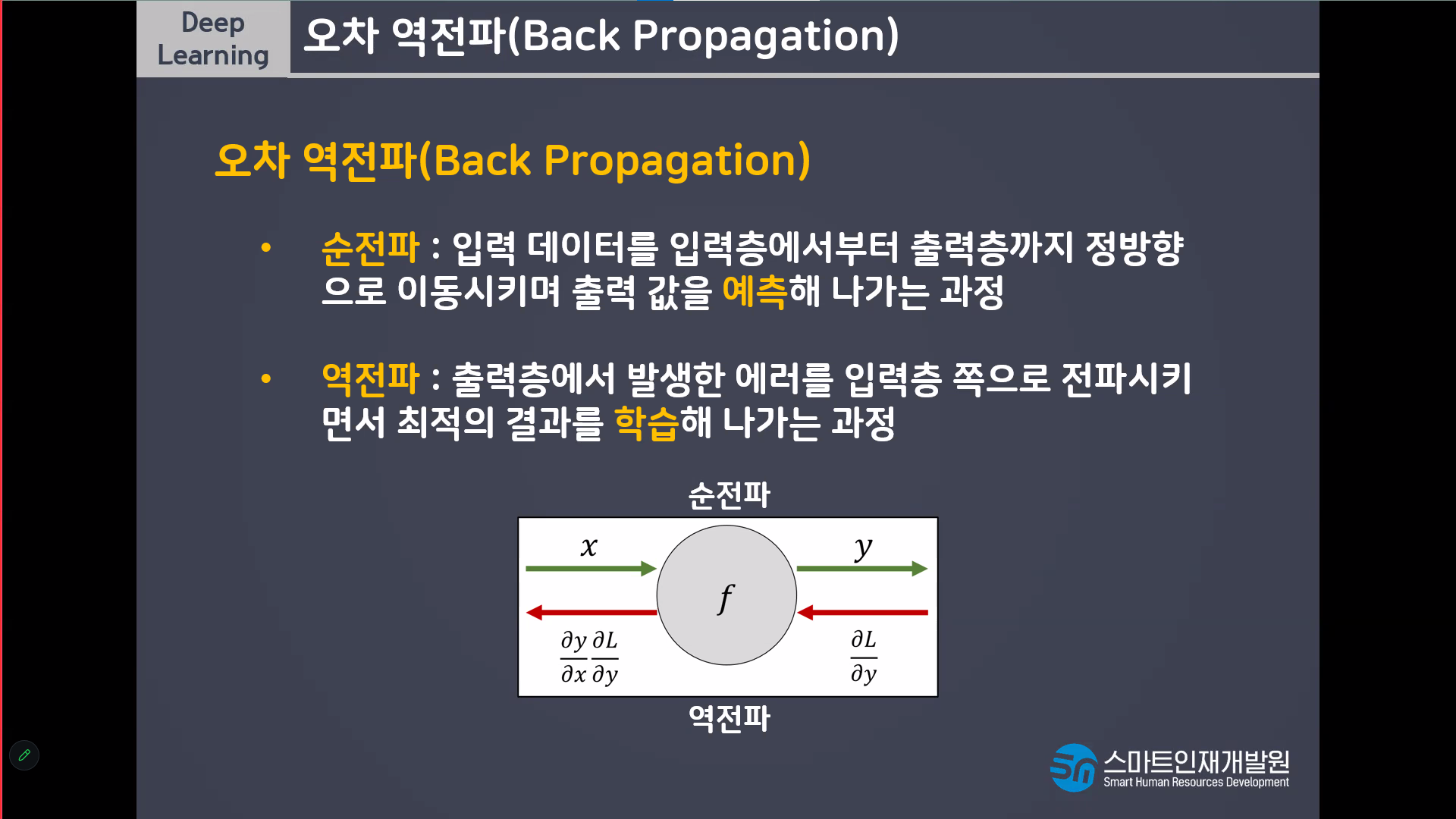
loss function(에러)
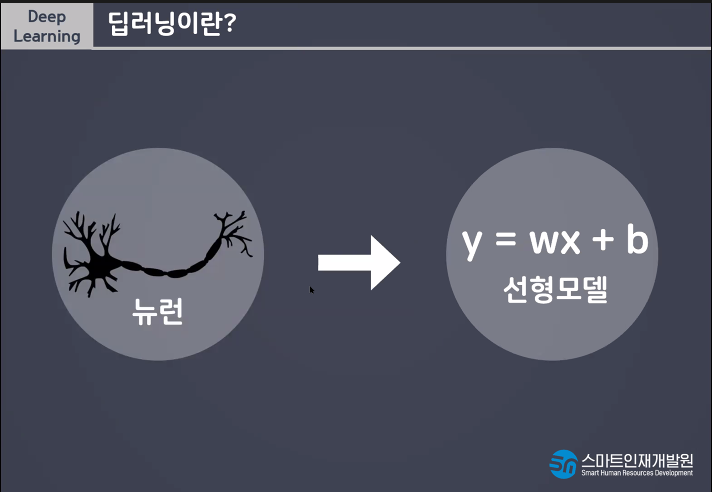
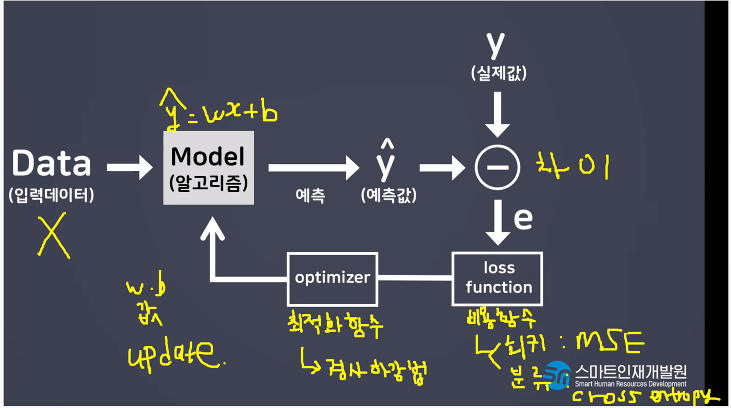
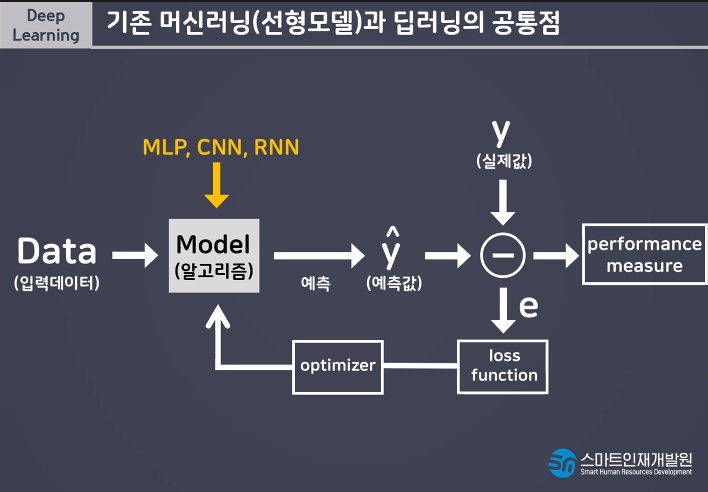
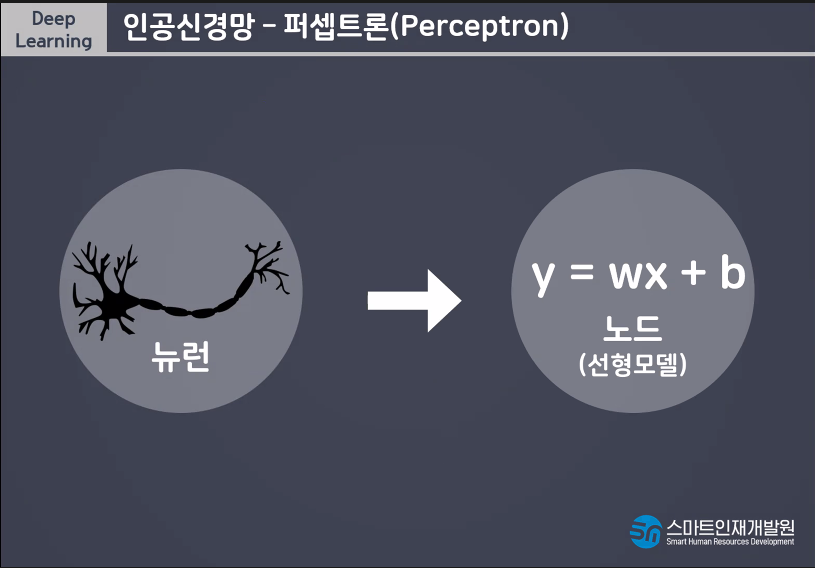
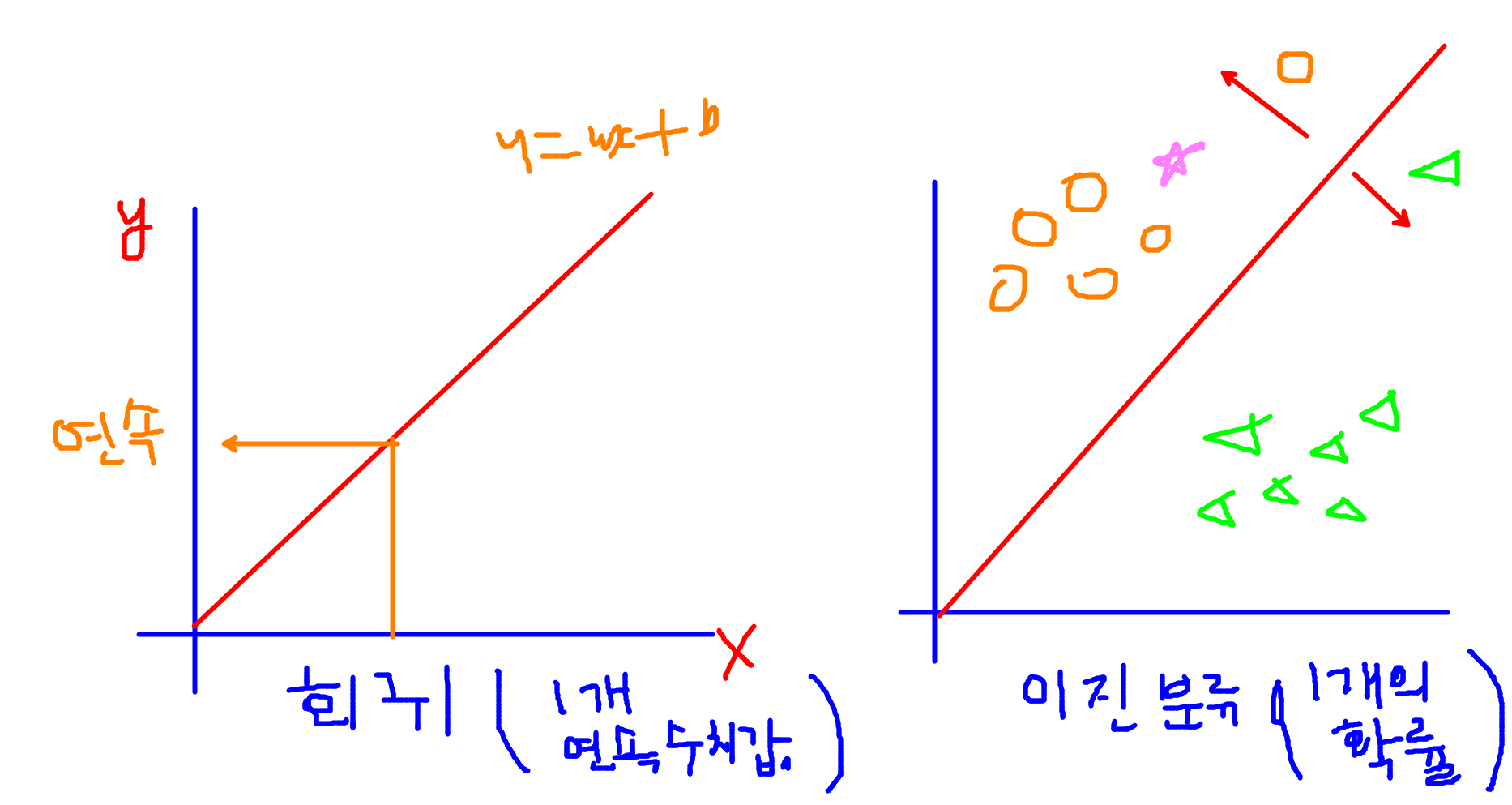
Model(알고리즘) y=wx+b
그림 잘 알고있어야해!!
딥러닝은 선형모델그림을 기본으로 한다.
선형모델 굉장히 중요해 딥러닝의 근간이 되기때문에.
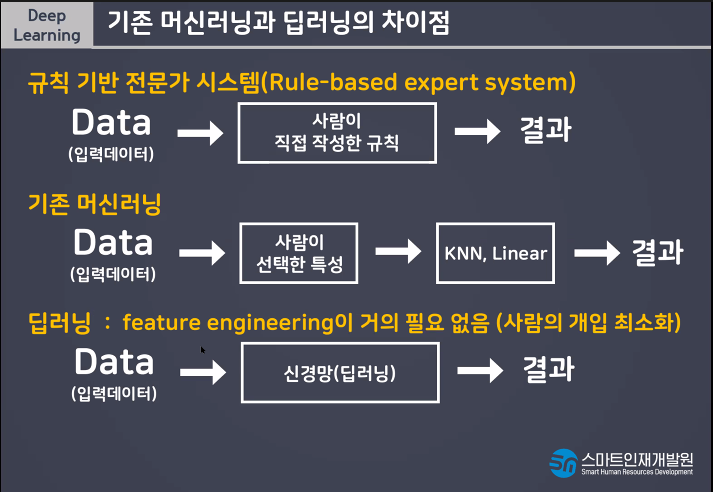
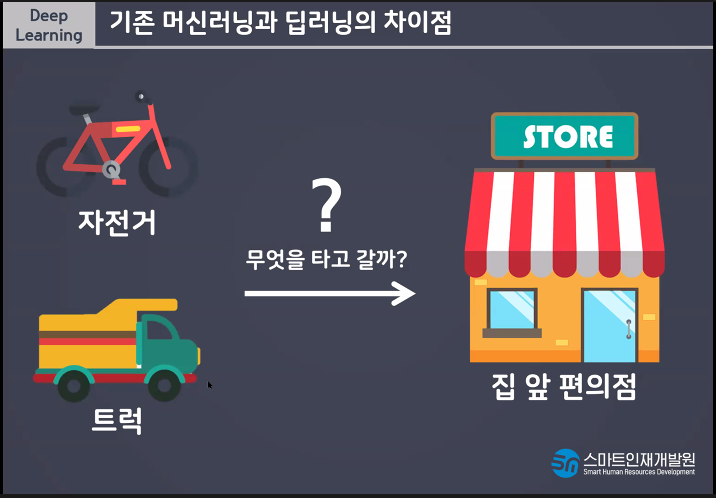
딥러닝은 트럭같은 친구 자전거는 머신러닝같은 친구





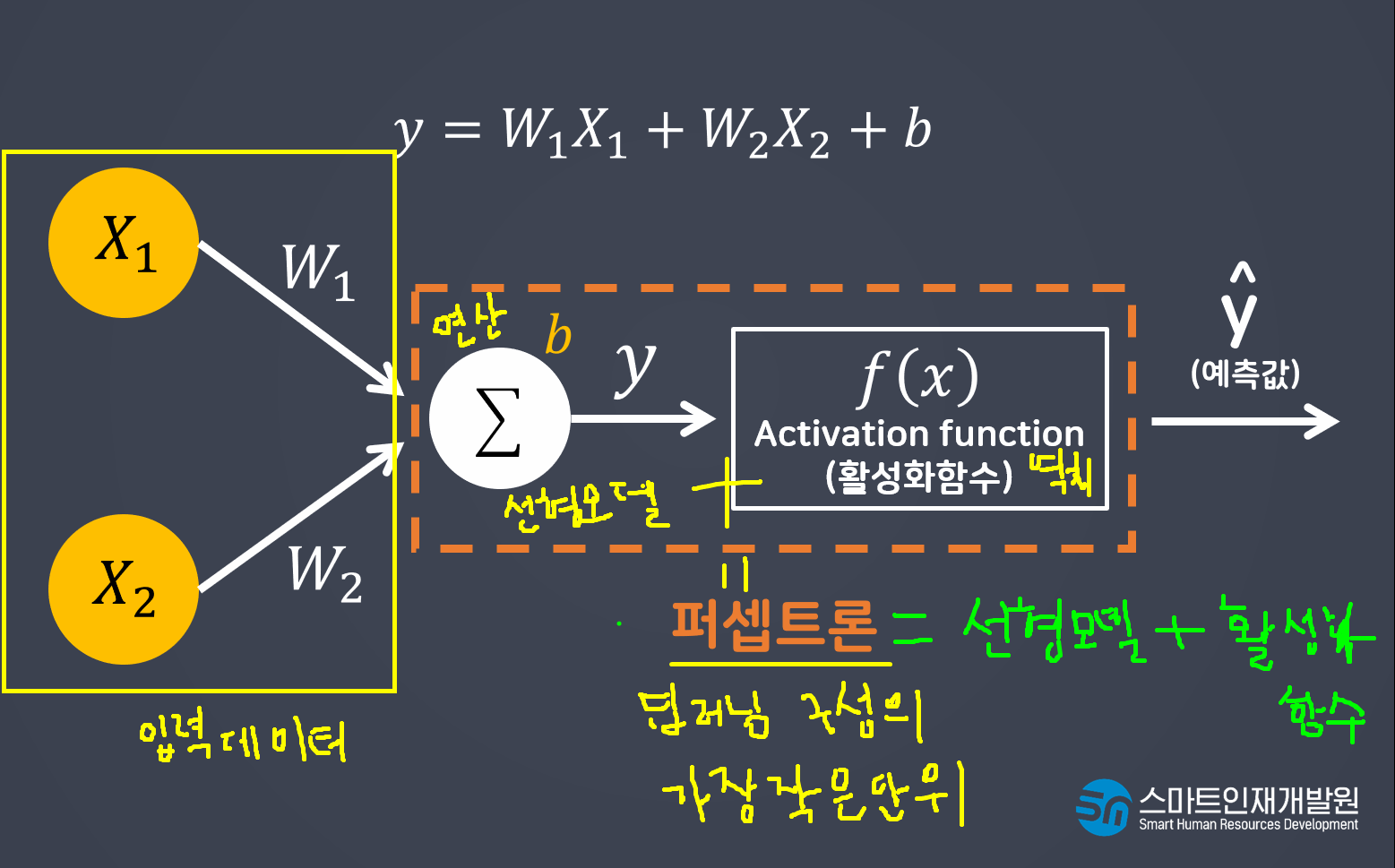
입력데이터가 들어오면 선형 데이터가 연산을 진행한다
연산을 진행 한 결과를 활성함수가 넘겨줄지 안넘겨줄지를 정한다(역치)
선형모델+활성함수 = 퍼셉트론 -> 딥러닝의 가장 기본적인 단위
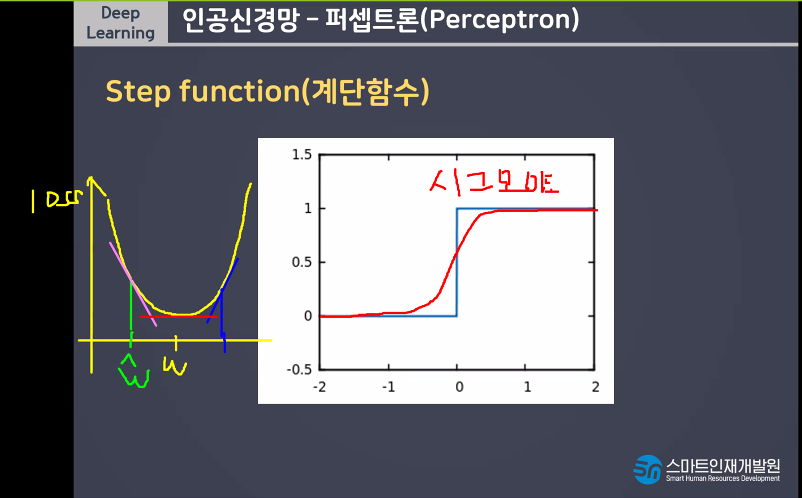
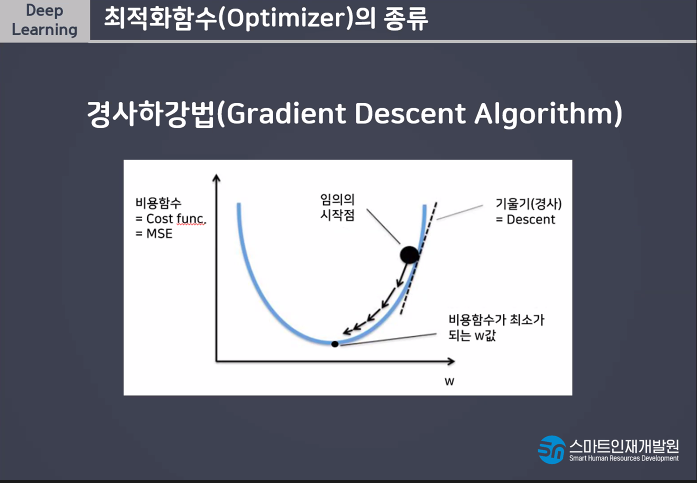
나의 예측값 W값 당시의 기울기를 그린다.
기울기가 (음수)내려가면 오른쪽으로 이동함.
그때의 순간 기울기는 양수가 되므로 왼쪽으로 이동함
점점점 최적의 W값을 찾아가는것이 경사하강법이다
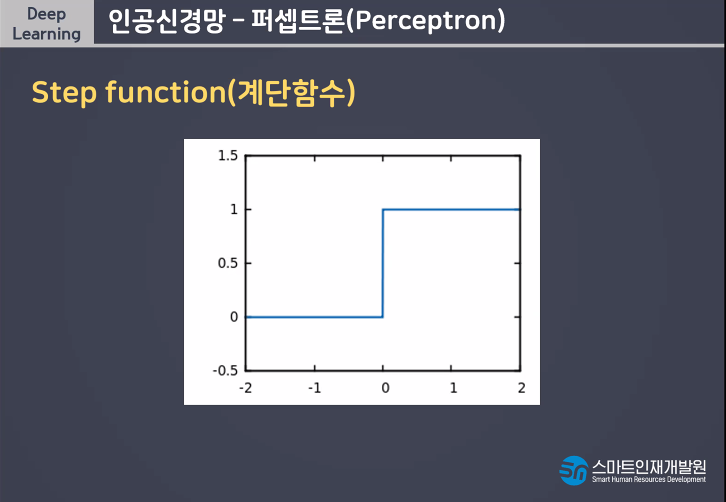
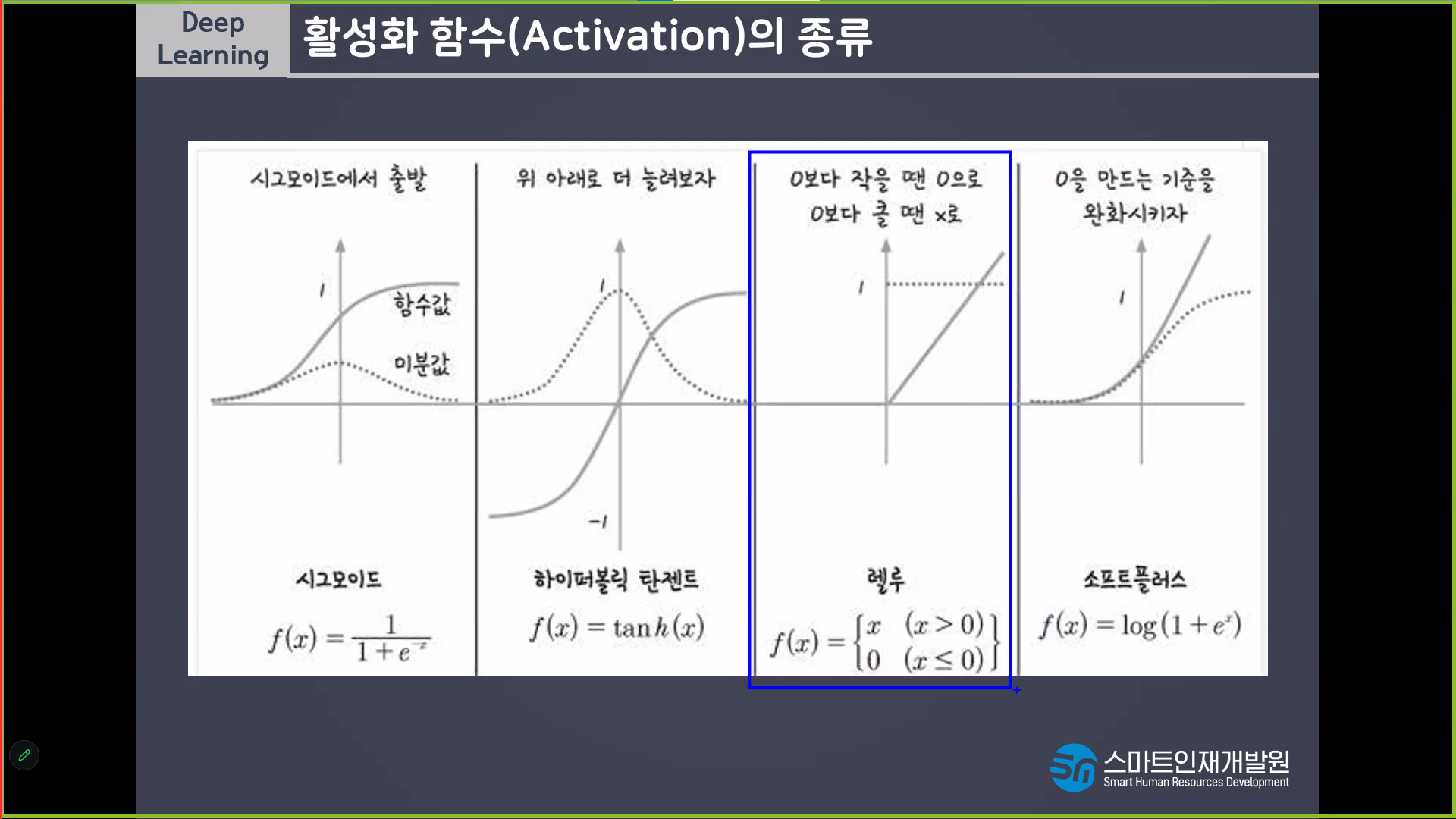
2차함수에서 1차함수가 되려면 미분을 해야한다.
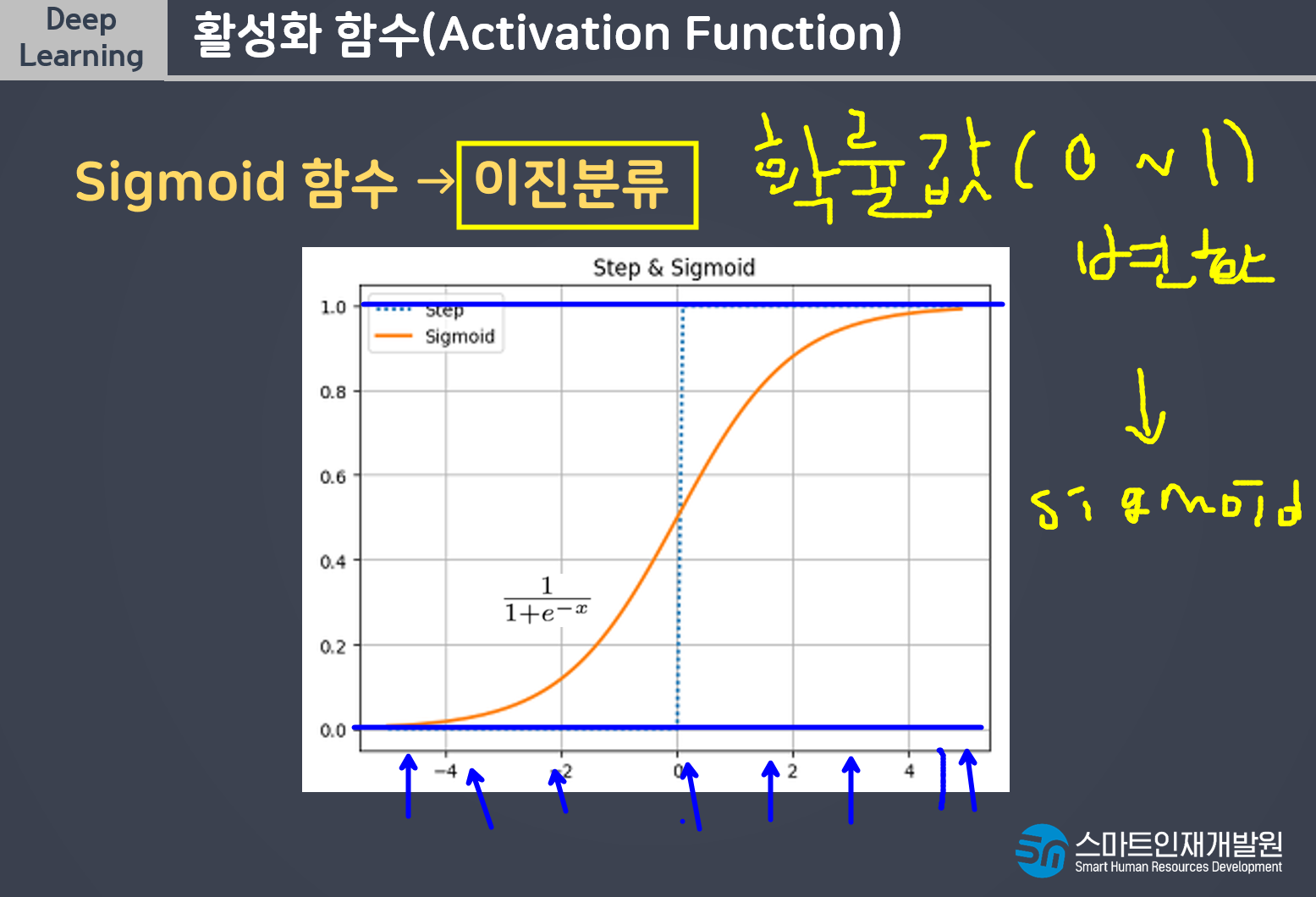
계단함수는 미분을 할수가없다
역치의 개념을 가지고가면서도 기울기가 있는 친구를 쓸 수 없을까 해서 나온것이 SIGMOID이다
계단함수의 모양은 가져가면서 기울기가 있어야한다 => SIGMOID
기울기가 있으면서도 역치의 개념이 있는것이 SIGMOID이다.
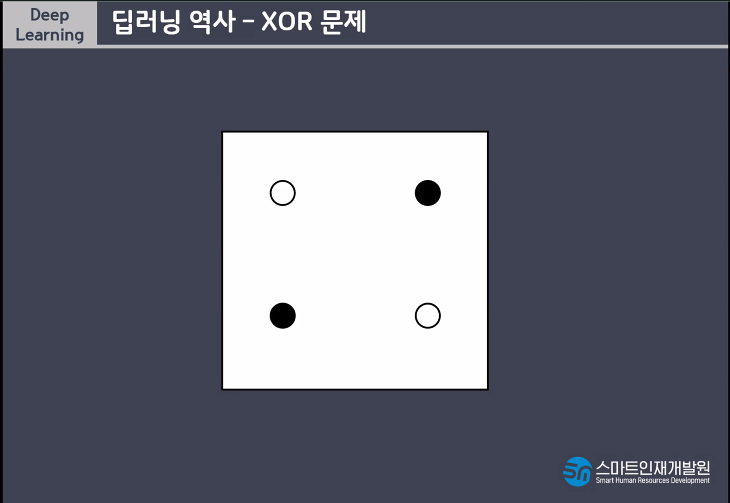
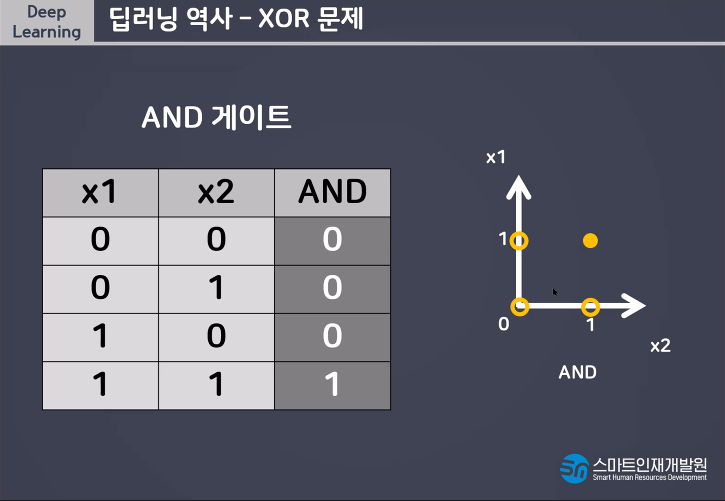
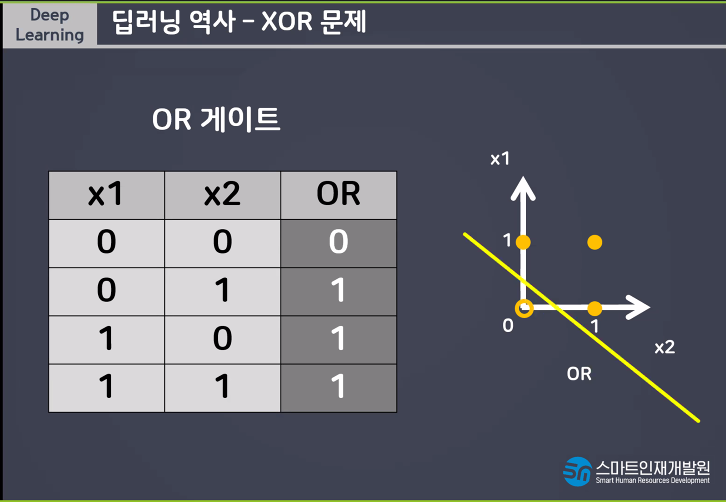
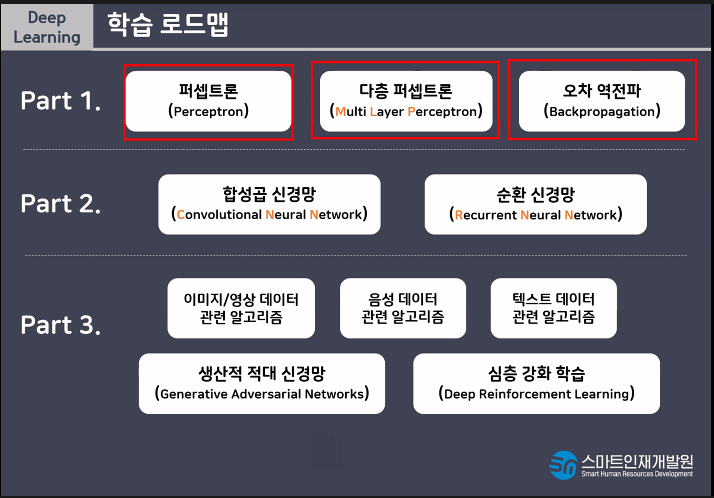
AND, OR는 해결이 가능하지만 간단한 XOR문제는 해결할 수 없기때문에 MLP(Muti Layer Perceptron)라는 개념이 등장하게되었다
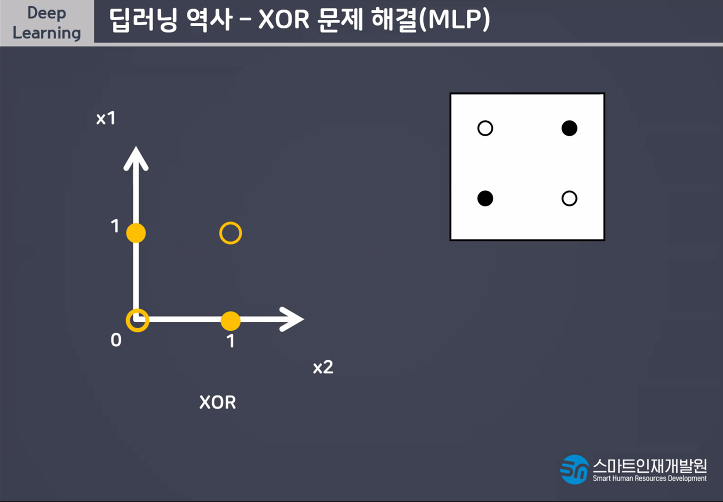
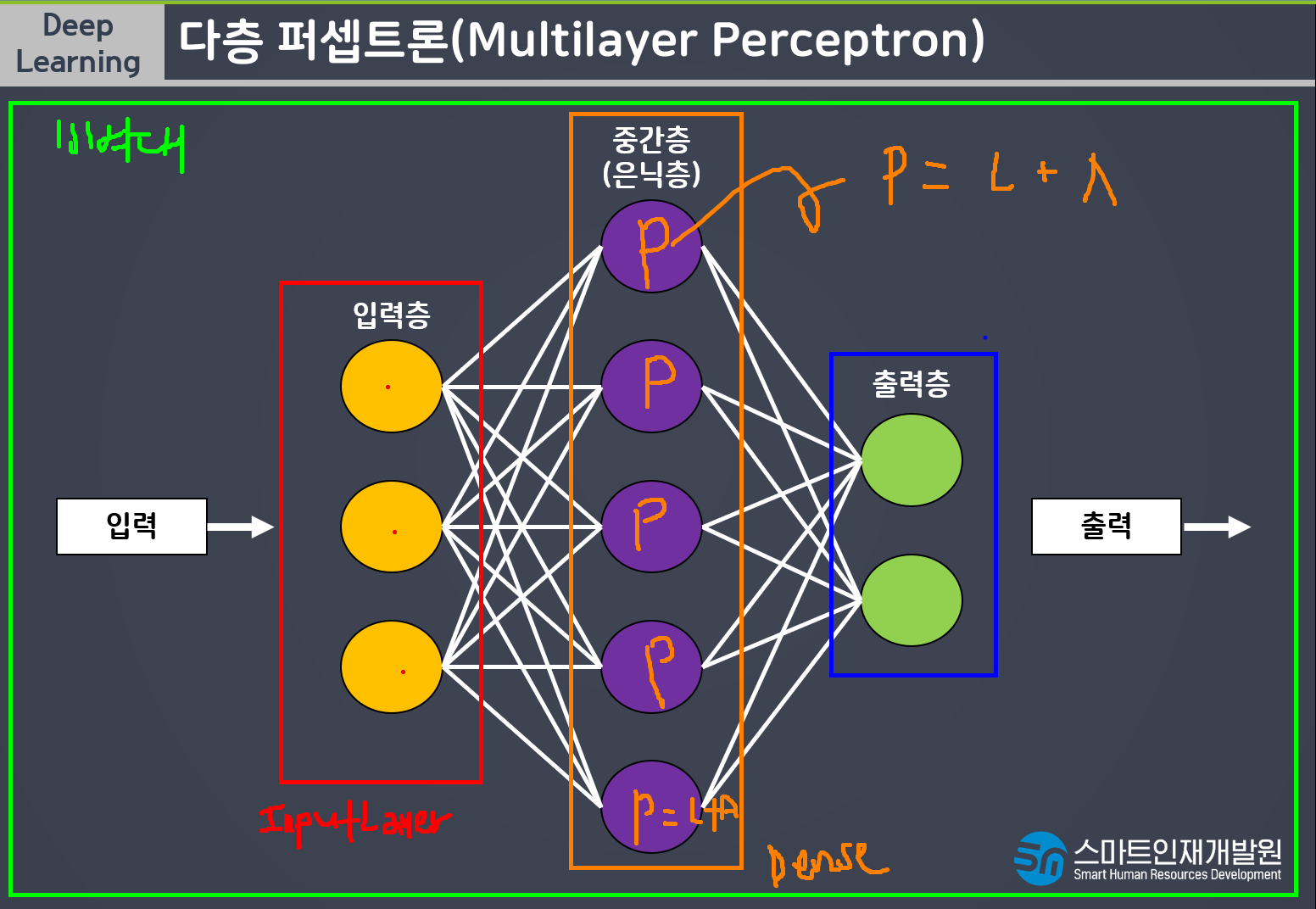
다층퍼셉트론(Multi Layer Perceptron)이란 퍼셉트론을 여러개의 층으로 구성하여 만든 신경망이다.
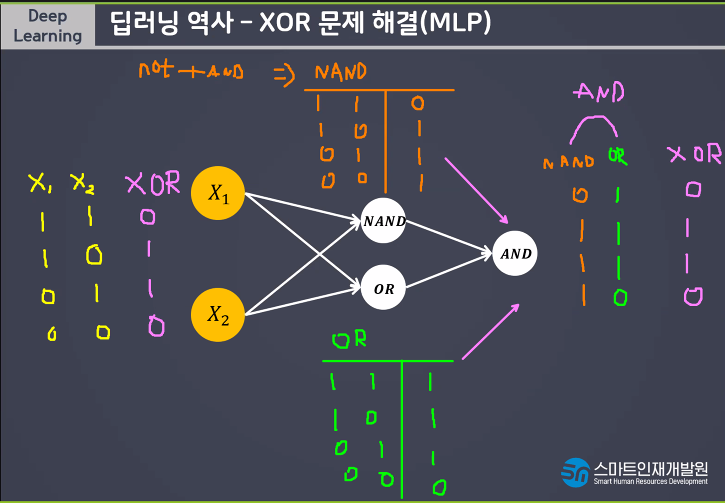
nand연산자란 not and라는 뜻이다.
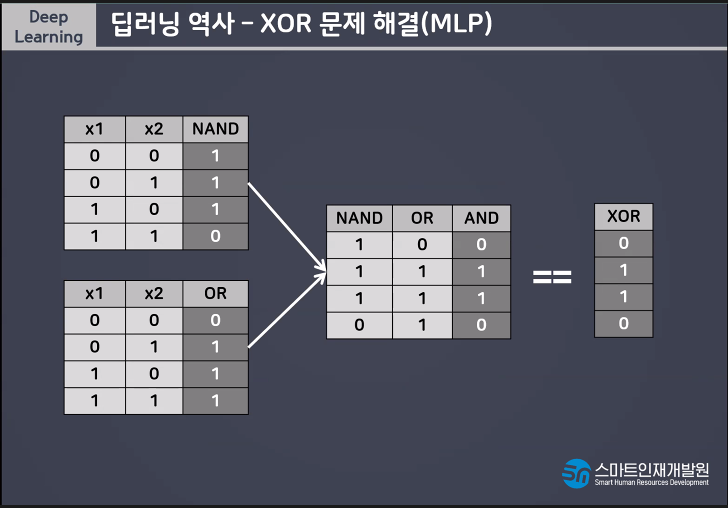
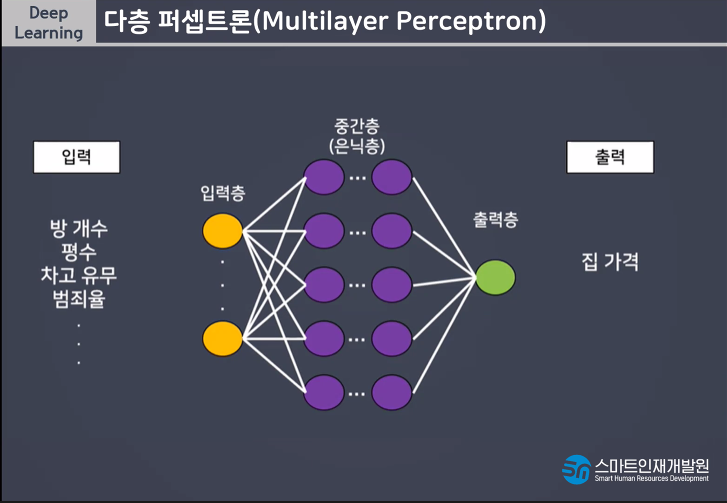
다층퍼셉트론은 한번의 연산으로 해결되지않는 문제를 해결할 수 있다는 장점이 있지만 단층에 비해 학습시간이 오래걸리고 모델(신경망)이 복잡해지면서 학습시 과대적합되기 쉽다는 단점이있다

성적은 범주형도 될 수 있고 연속형도 될 수 있다

각각의 확률을 소프트맥스 확률을 거치면 전체적으로 1이 된다
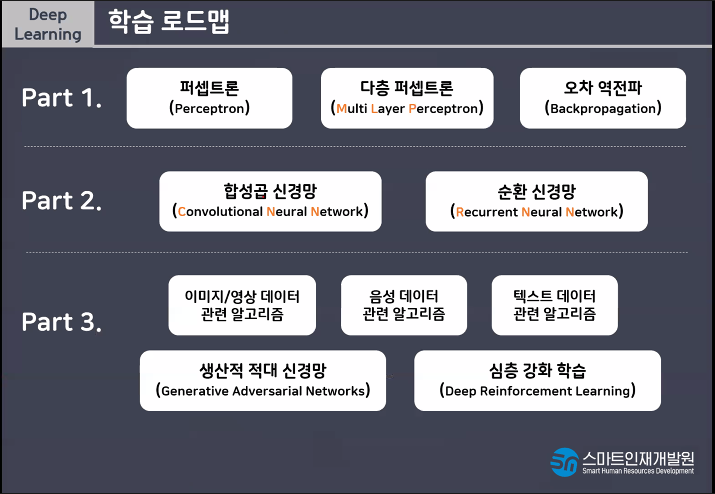
[딥러닝 개념정리]
- 딥러닝이란? 인간의 뉴런, 신경망을 모방하여 데이터를 학습 및 예측하는 기술
- 퍼셉트론(perceprtron): 딥러닝을 구성하는 가장 작은 단위
(퍼셉트론 = 선형모델 + 활성화함수 activation)
- 딥러닝모델설계
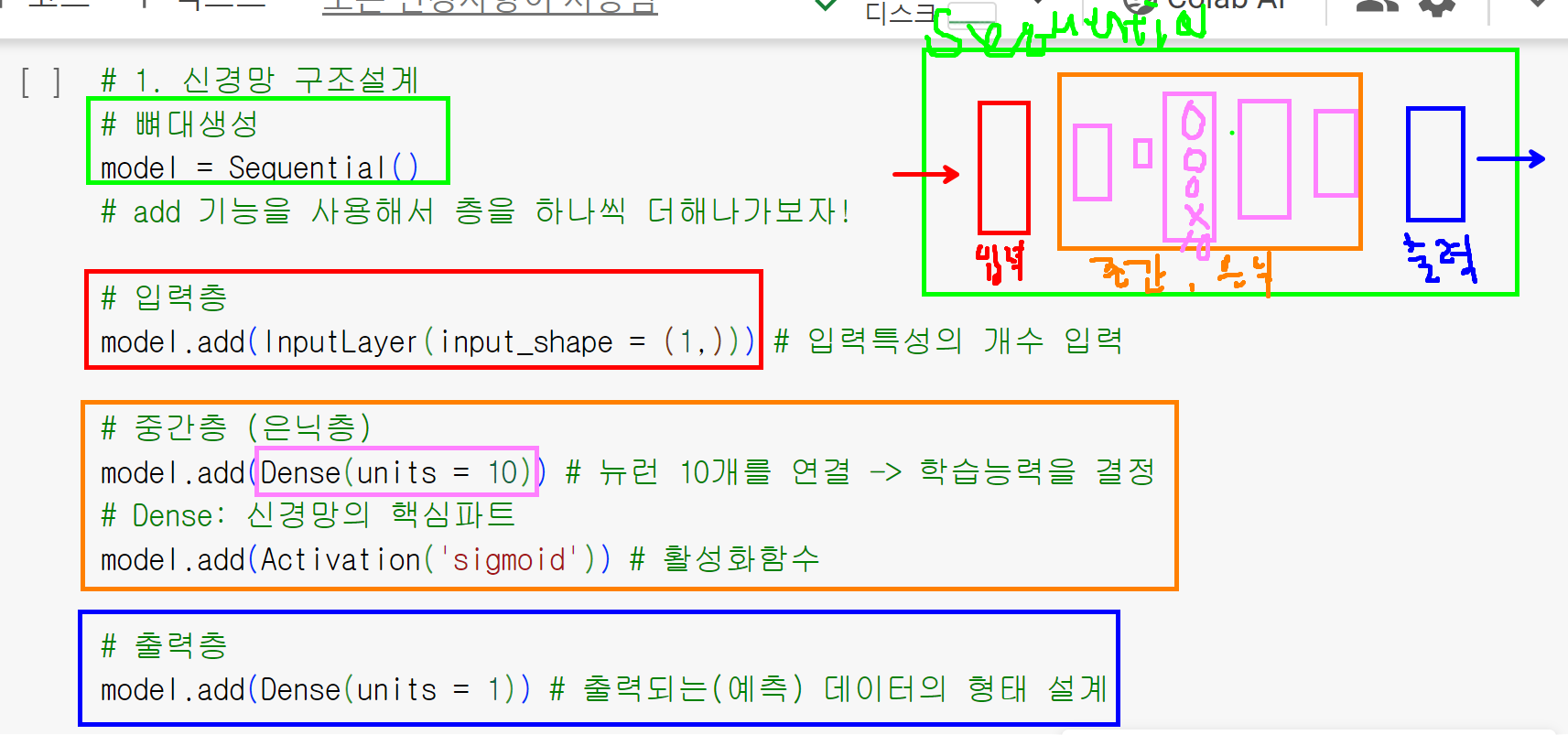
1. 신경망 구조 설계
1) 뼈대생성
2) 입력층 -> 입력하고자하는 데이터에 따라 변경
3) 중간층(은닉층)
4) 출력층 -> 출력하고자하는 데이터에 따라 변경
2. 신경망 학습방법 및 평가방법 설계
3. 모델 학습
4. 모델 평가
[활성화함수 -> 중간층,출력층 활용도가 다름!]
- 중간층: 활성화/비활성화(역치)
- 초기: StepFunction (계단함수) -> sigmoid 변경
왜? 최적화알고리즘(optimizer) 을 진행하는 과정에서 경사하강법을 적용하기 위함 (미분을 하기 위해서는 기울기가 필요)
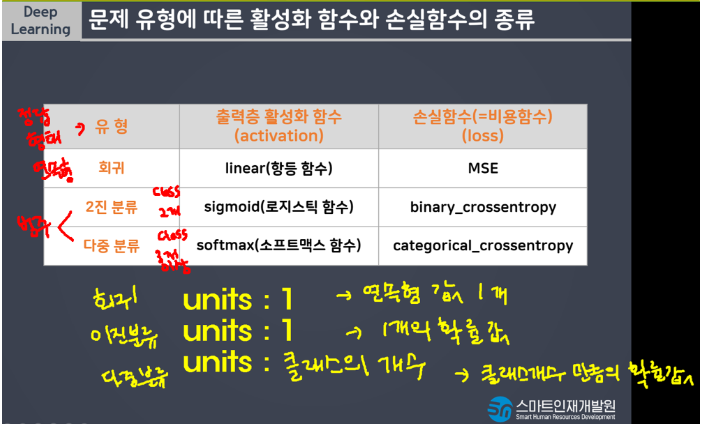
- 출력층: 출력하고자하는 데이터의 형태를 지정
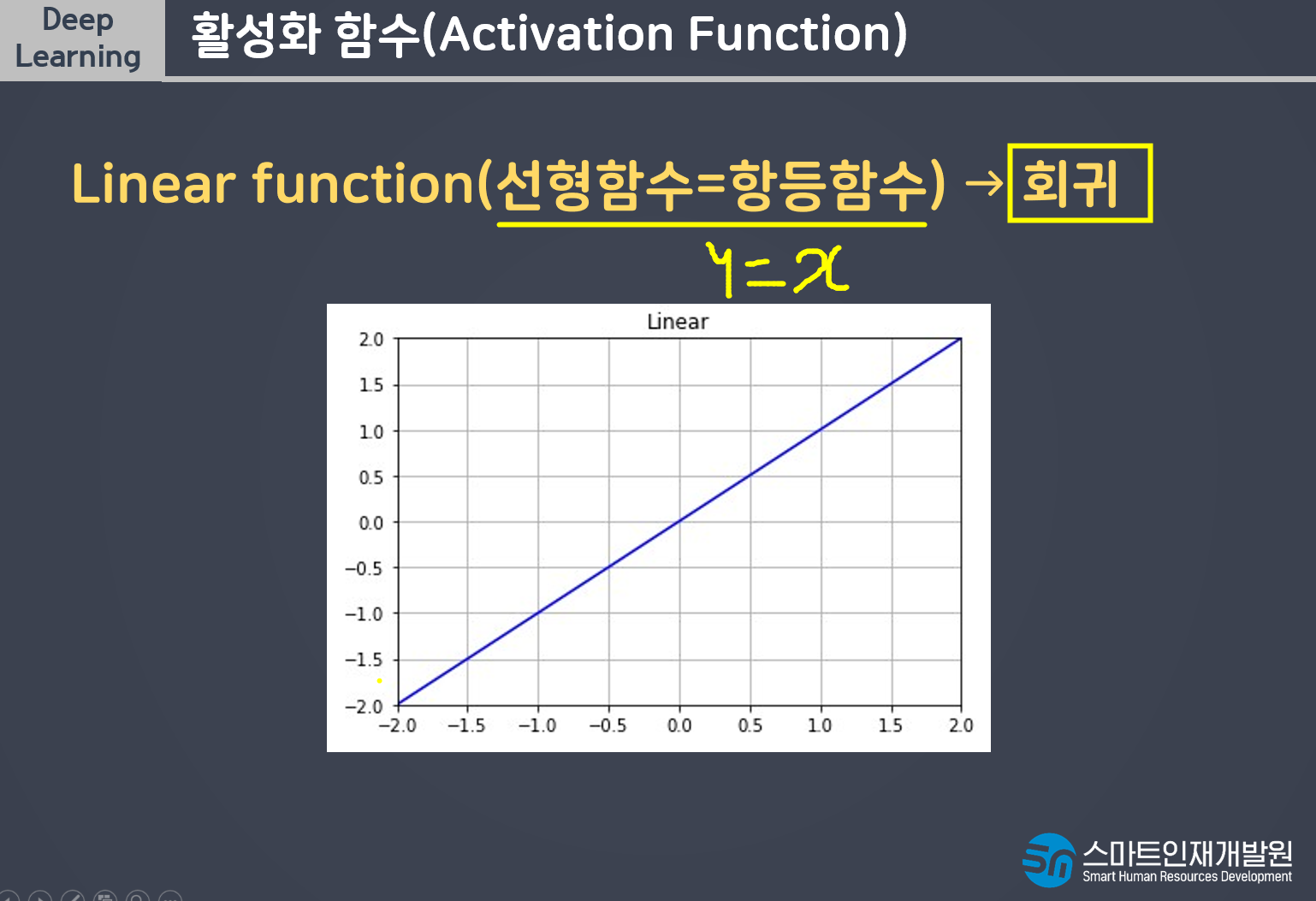
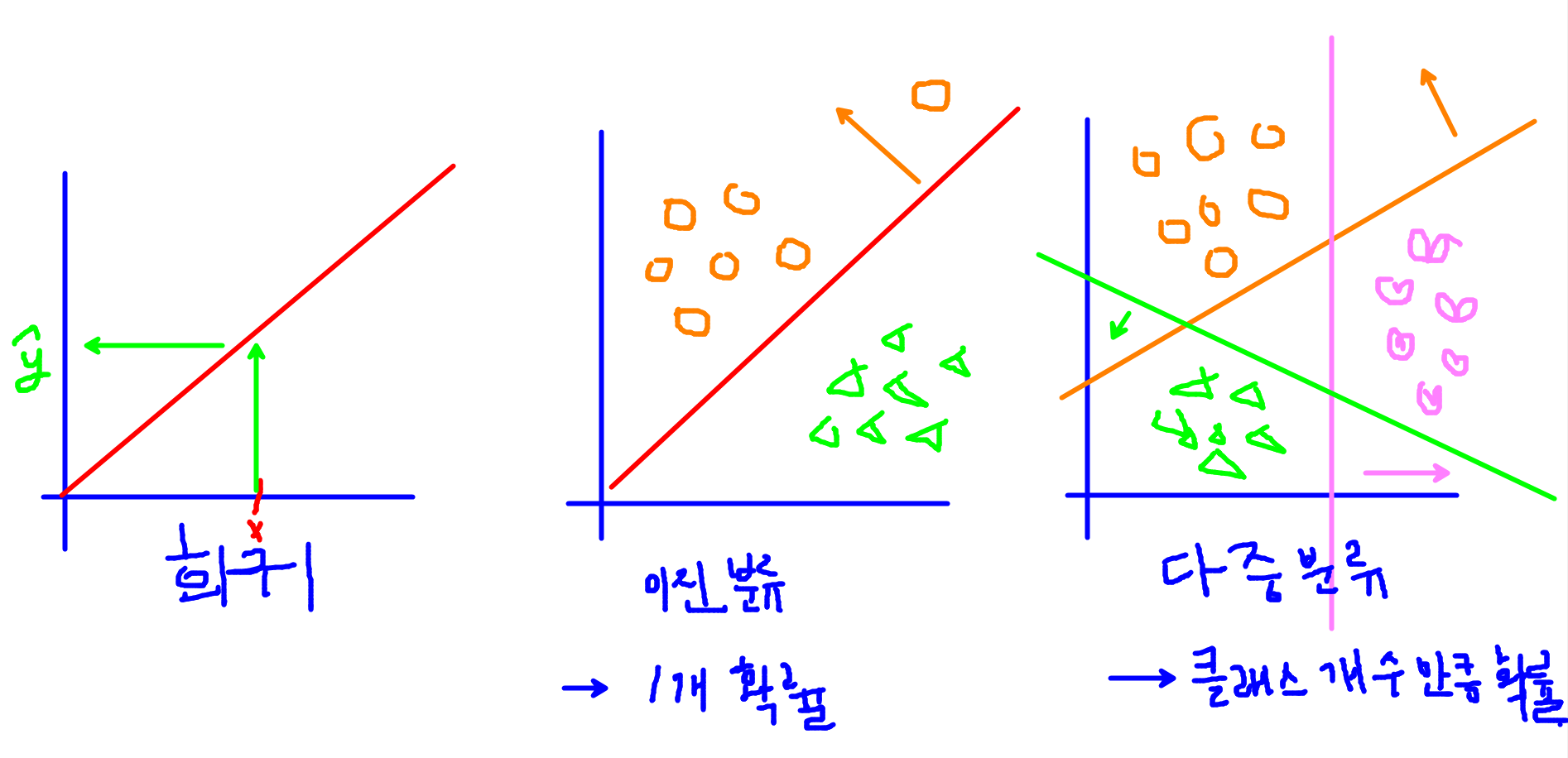
- 회귀: linear(항등함수, y=x) 선형모델이 예측한 값을 그대로 출력 default값으로 따로 작성해줄 필요는 없음.
- 이진분류: sigmoid, 선형모델이 예측한 연속형값을 0~1사이의 확률값으로 변경
- 다중분류: softmax, 클래스 개수만큼의 값을 총합이 1인 확률값으로 변경
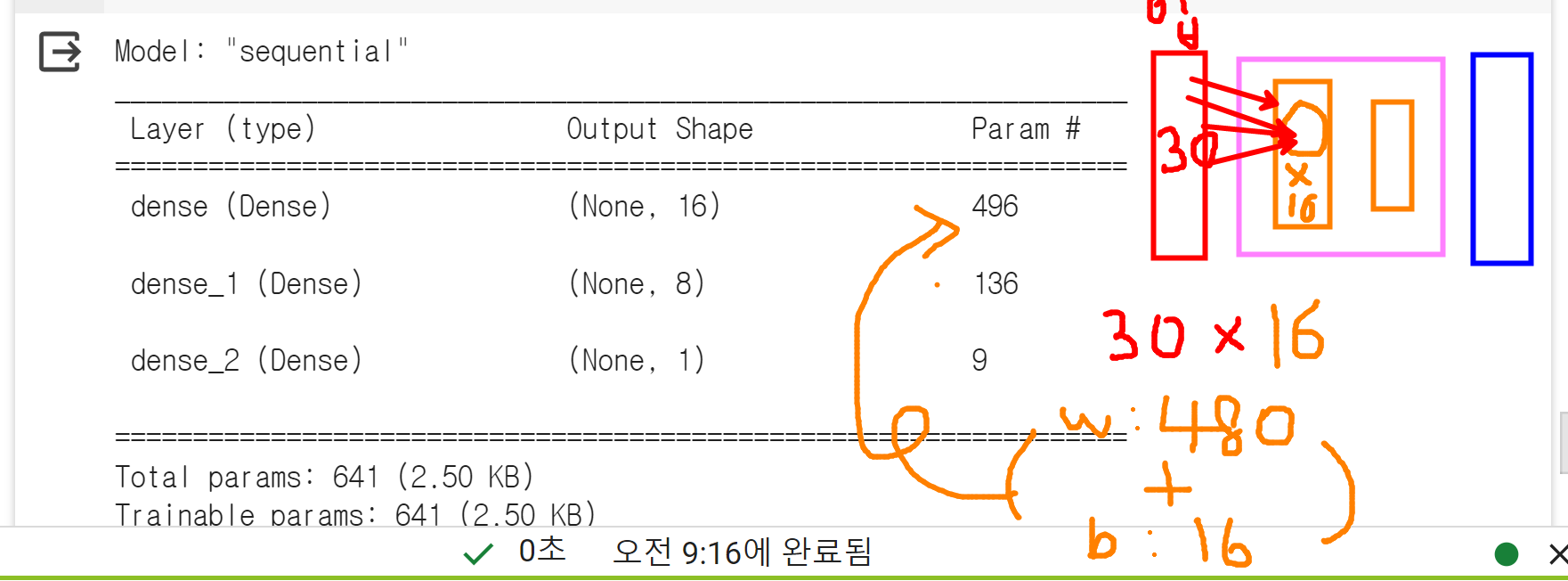
[출력데이터 따른 units 의 개수]
- 회귀: units = 1
- 이진분류: units = 1 (1개의 확률값 / 인지아닌지)
- 다중분류: units = 클래스의 개수(클래스개수만큼의 확률값)
[학습방법 및 평가방법 설정/ compile]
- loss(오차함수, 비용함수)
- 회귀: mean_squared_error
- 이진분류: binary_crossentropy
- 다중분류: sparse_categorical_crossentropy
- metrcis(평가지표)
- 회귀: mse(평균제곱오차)
- 분류: accuracy (정확도)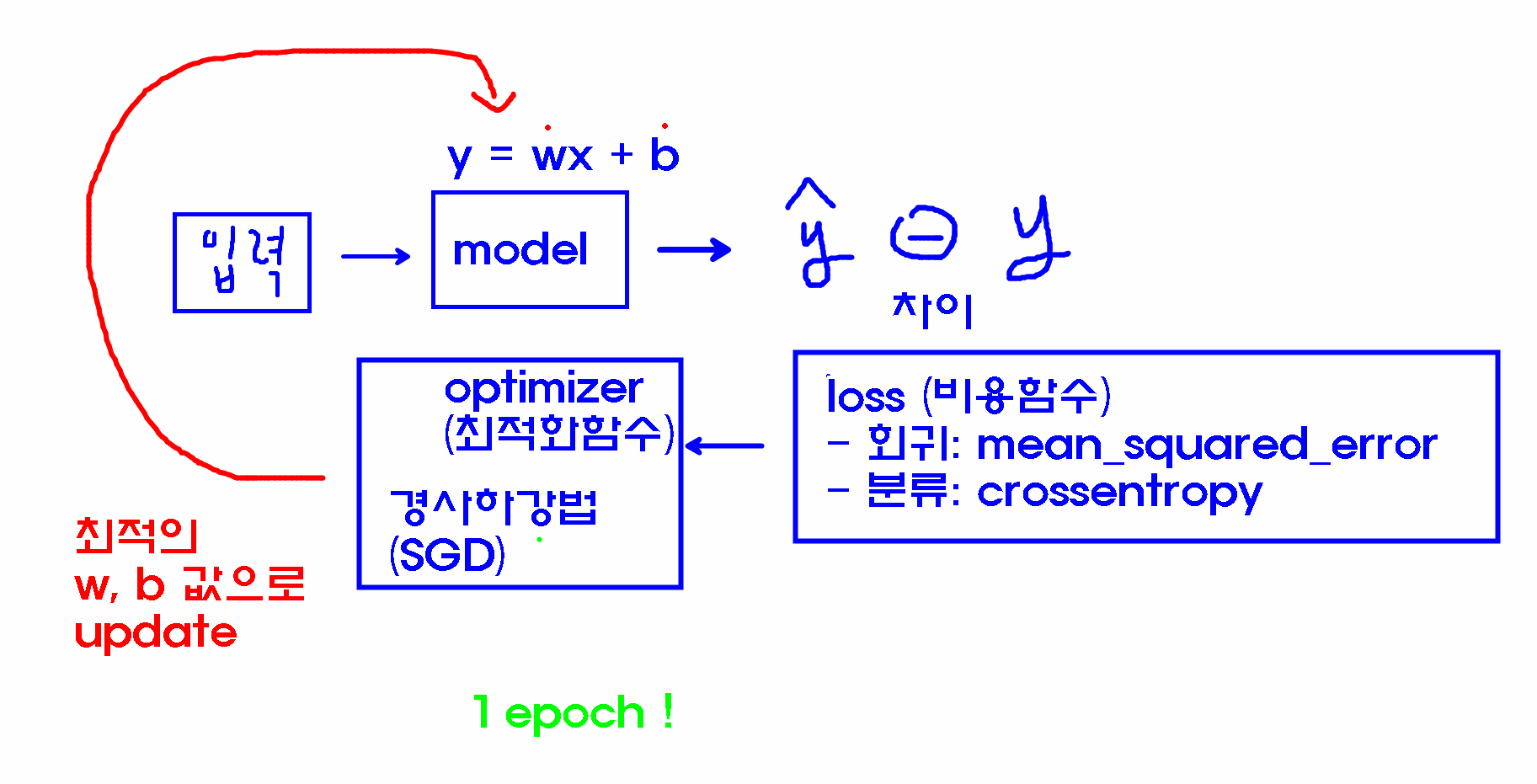
- 활성화함수 (중간층,출력층 활용도가 다름!)
- 중간층 활성화함수 역할: 역치 (활성화/비활성화)
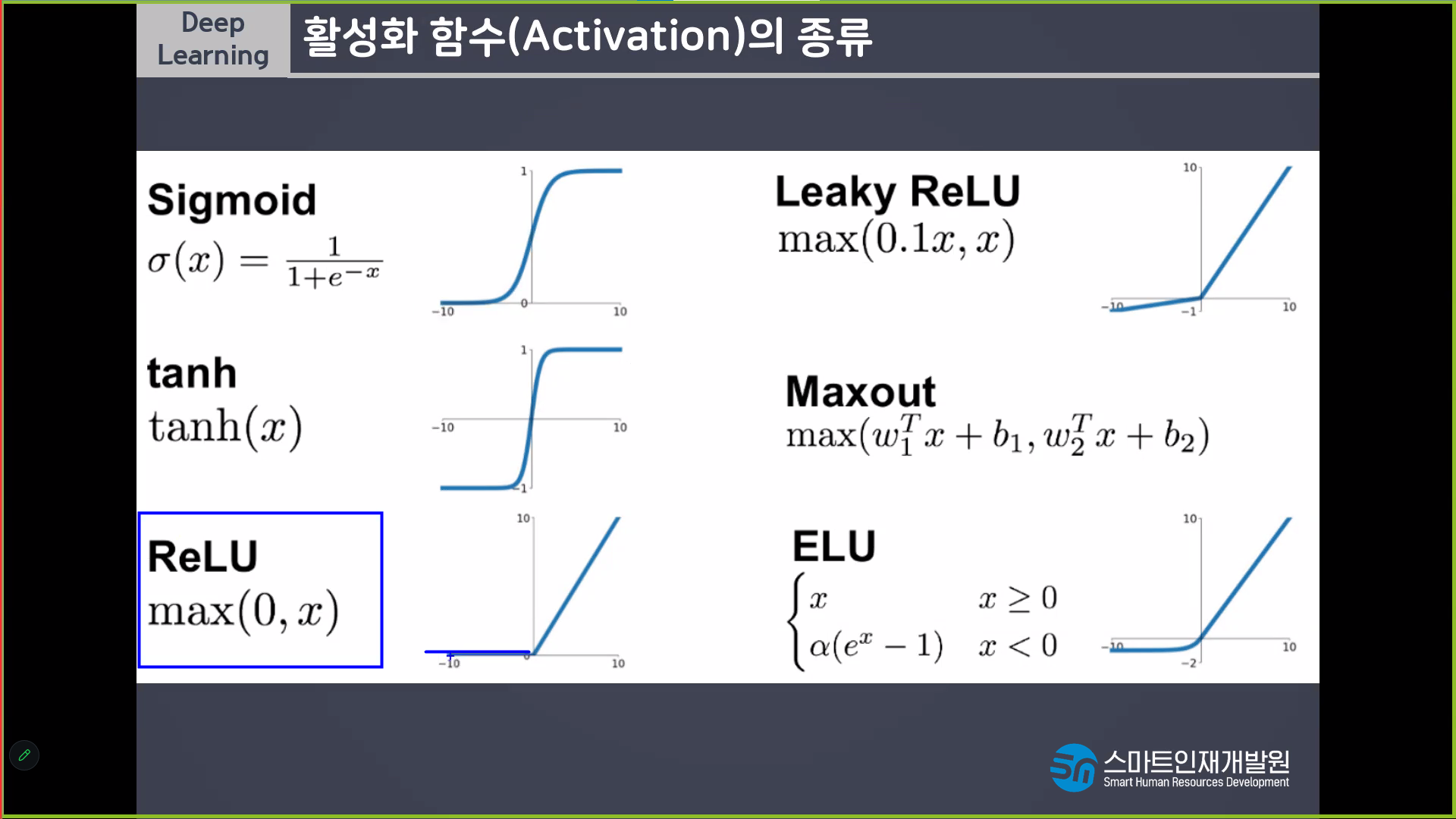
- stepfunction -> sigmoid -> Relu (오차역전파 진행시 기울기 소실문제 발생)
- 출력층 활성화함수 역할: 출력받고싶은 데이터 형태 지정 (units, activation)
- 회귀: units = 1, activation = 'linear
- 이진분류: units = 1, activation = sigmoid
- 다중분류: units = 클래스의 개수, activation = 'softmax'
-- 학습방법 및 평가방법 설정
- 회귀: loss = 'mean_squared_error, metrics = 'mse'
- 이진분류: loss = 'binary_crossentropy', metrics = 'accuracy'
- 다중분류: loss = 'categorical_crossentropy' , metrics = accuracy'
* 정답데이터의 형태와 출력층에서의 데이터의 형태를 맞춰줘야함!
1. 정답데이터를 원핫인코딩(to_categorical)
2. keras 에서 제공해주는 알아서 변경 후 비교 해주는 방법
- loss = 'sparse_categorical_crossentropy'
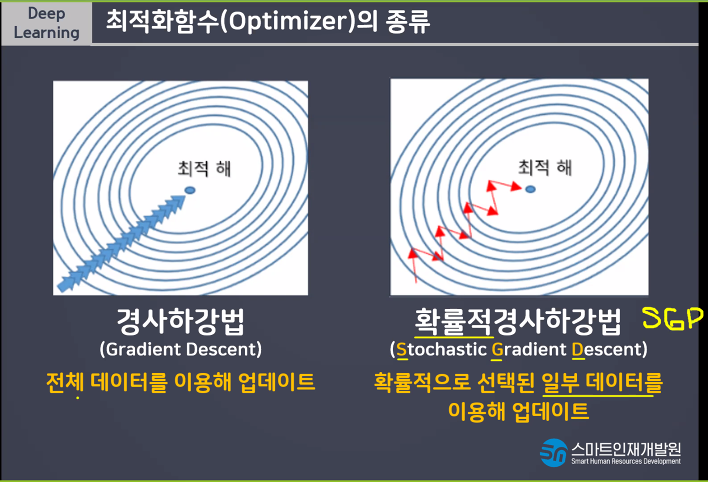
데이터를 나누는것을 Batch_size라고 함.


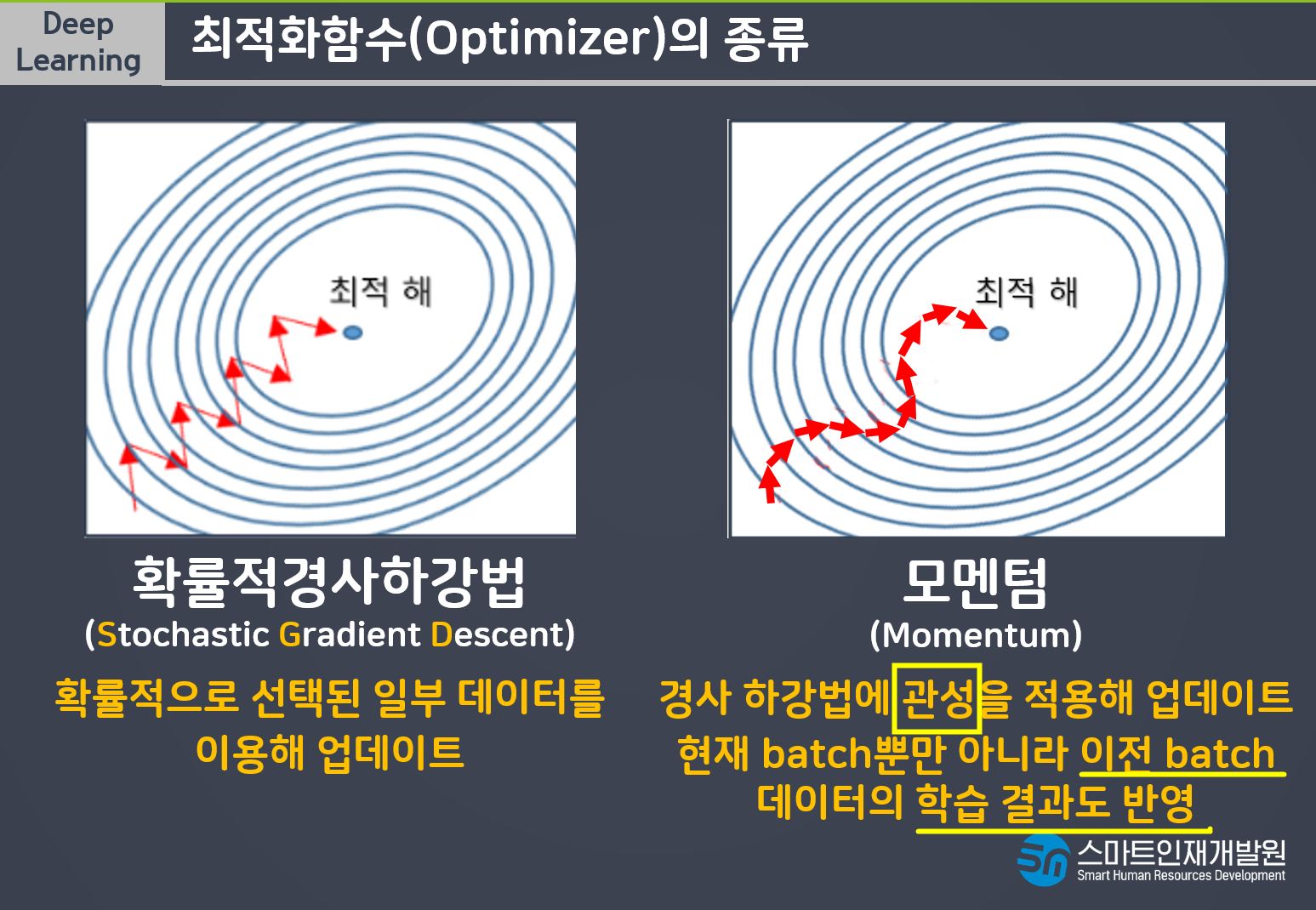
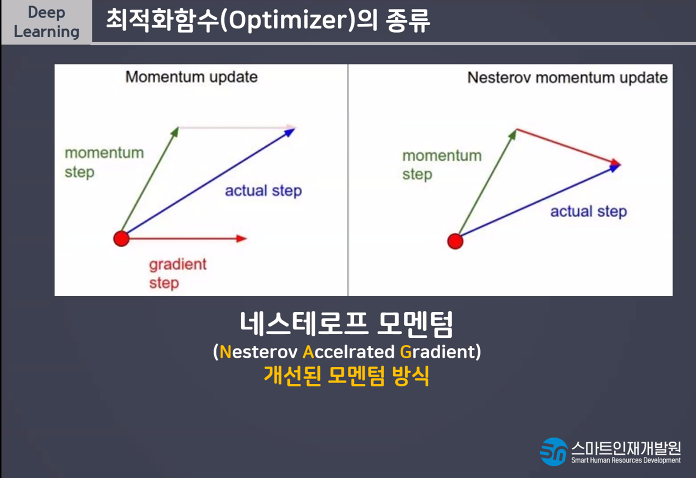

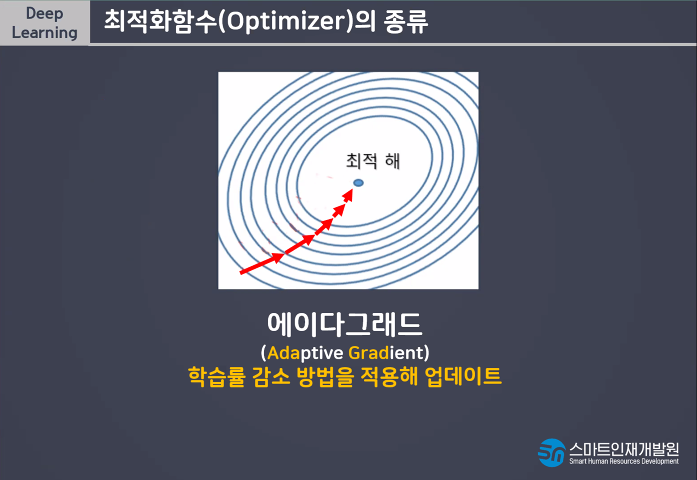
Learning Rate(보폭)
빠르고 큰 보폭으로 다가가다가 가까이 갈수록 보폭을 줄여서 미세조정하는 방법
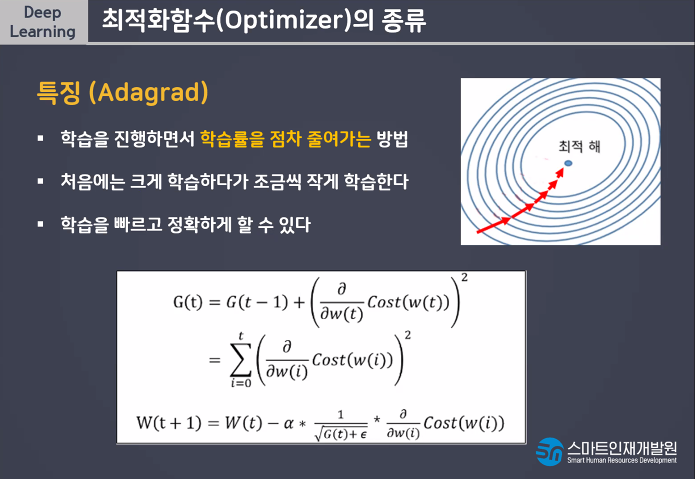
빠르고 정확한 학습을 할 수 있다
callback 함수
- 모델저장 및 조기학습중단
* 모델저장 : 딥러닝 모델 학습시 지정된 epochs를 다 끝내면 과대적합이 되는 경우가 있다 -> 중간에 일반화된 모델을 저장할 수 있는 기능이 필요하다 - 조기학습 중단 : epochs를 크게 설정한 경우 일정 횟수 이후로는 모델의 성능이 개선되지않는 경우가 있다 -> 시간, 비용이 낭비 -> 일정횟수 이후로 모델의 성능이 개선되지않는 경우에는 모델 조기학습 중단하는 기능이 필요하다
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
# 모델 중간 저장 : ModelCheckpoint
# 모델 중간 멈춤 : EarlyStopping# 모델저장 객체생성
# 모델을 저장할 경로 설정
model_path = '\\content\\drive\\MyDrive\\Colab Notebooks\\Deep Learning\\data\\digit_model\\dm_{epoch:02d}_{val_accuracy:0.2f}.hdf5'
mc = ModelCheckpoint(filepath= model_path, # 모델을 저장할 경로
verbose = 1,
# 로그출력: 0 (로그출력 X), 1 (로그 출력 o), 몇번째에 저장되는지 확인이 가능)
save_best_only = True,
# 모델성능이 최고점을 갱신할때만 저장 (False 설정시 매 epoch 마다 저장)
monitor = 'val_accuracy') # 모델의 성능을 확인할 기준
# 일반화 확인을 위하여 val_accuracy 로 선택!
# 모델저장 객체 생성 완료~
# 하지만 사용은 아직 안한것! > 학습시 객체를 불러와서 사용할것!# 조기학습중단 객체생성
es = EarlyStopping(monitor = 'val_accuracy', # 학습을 중단할 기준값 설정
verbose = 1, # 로그출력
patience = 10) # 모델성능개선을 기다리는 최대 횟수
# 조기학습중단 객체 생성 완료MLP(Multi Layer Perceptron)
MLP는 여러개의층(퍼셉트론 다발)으로 구성된 딥러닝 모델이다. 선형모델(퍼셉트론)여러개가 연결되어 이쓴 구조이다
머신러닝과 비교를 하자면 딥러닝은 모델을 직접 구현하고 알아서 여러번 학습해서 최적의 결과를 출력한다는 점이다.
MLP의 단점은 이미지를 잘 예측하지 못하고 모델을 직접 구현한다는 점이다. 그래서 다른 모델을 불러서 사용한다
MLP에서 기억해야할것은 활성화(activation), compile(loss, optimizer, metrics), Dense이다. Dense에서 주가되는 모델이 바로 MLP이다
CNN
CNN(Convolutinal Neural Network)
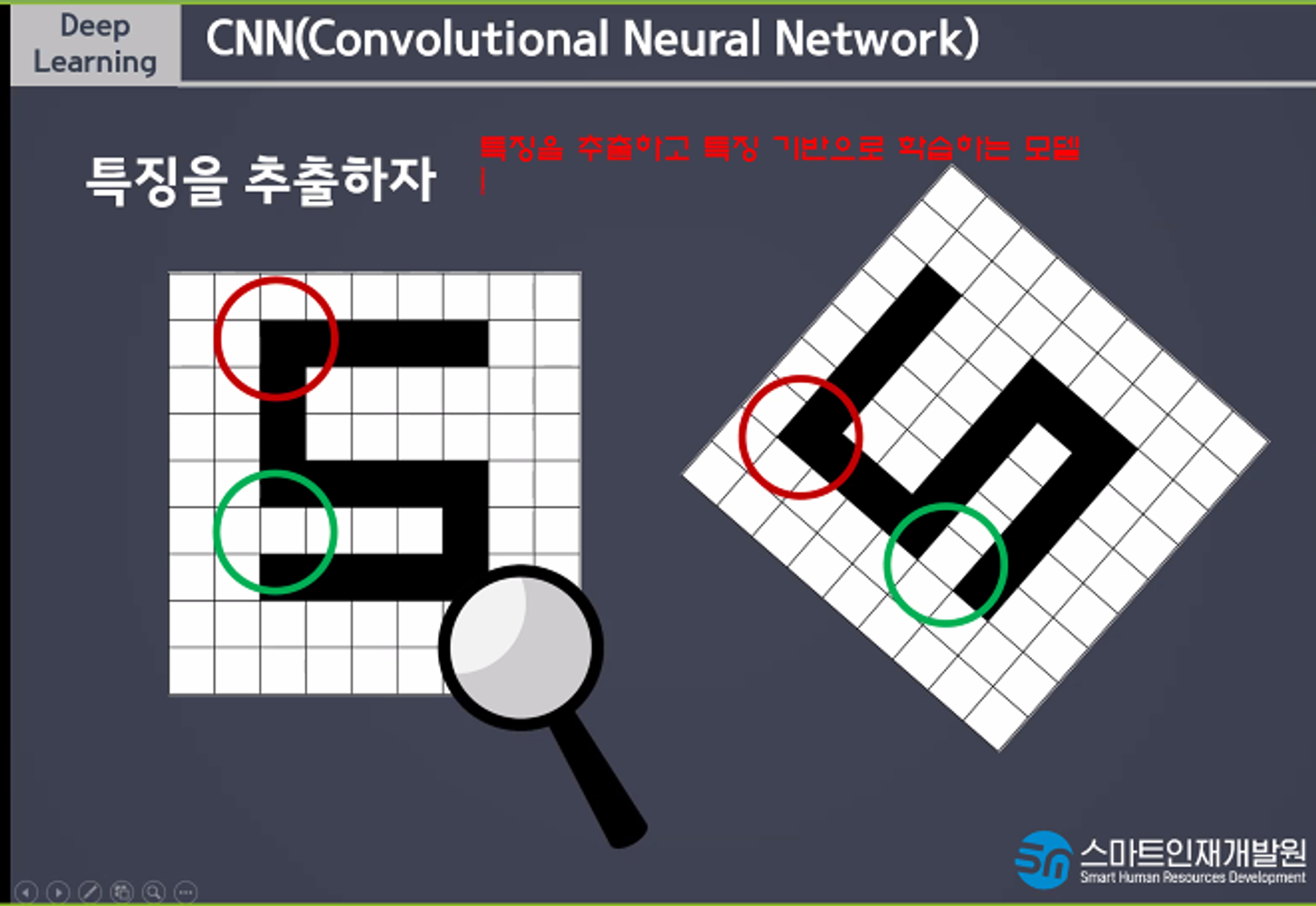
CNN은 특징을 추출하고 특징 기반으로 학습하는 모델이다. 데이터의 일부분을 사용해서 학습한다.
1998년 Yann Lecun 교수에 의해 1950년대 수행했던 고양이의 뇌파 실험에 영감을 얻어 이미지 인식을 획기적으로 개선 할 수 있는 CNN이 제안되었다.
CNN의 구조
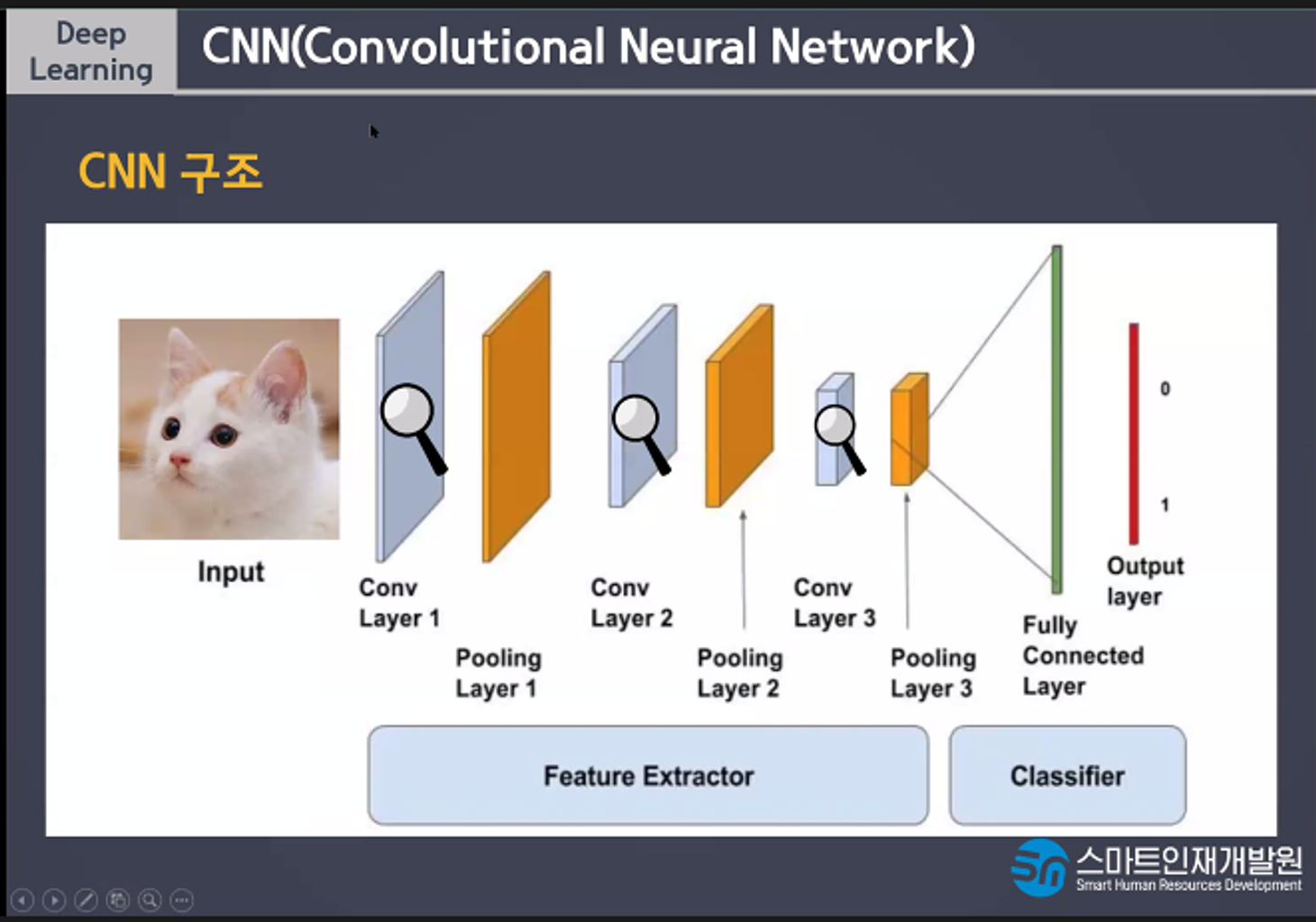
CNN과 MLP의 다른점은
추가적으로 사용되는 층은 Convolutin, Pooling층을 추가사용한다는 점이다
분류분는 특징을 보고 물체를 판단한다. Dense층을 사용한다
특징추출부는 Conv, Pooling을 사용해서 특징만 모아놓은 데이터를 만든다.
Convolution은 특징을 찾고 Poolling은 특징이 아닌 부분을 삭제한다.
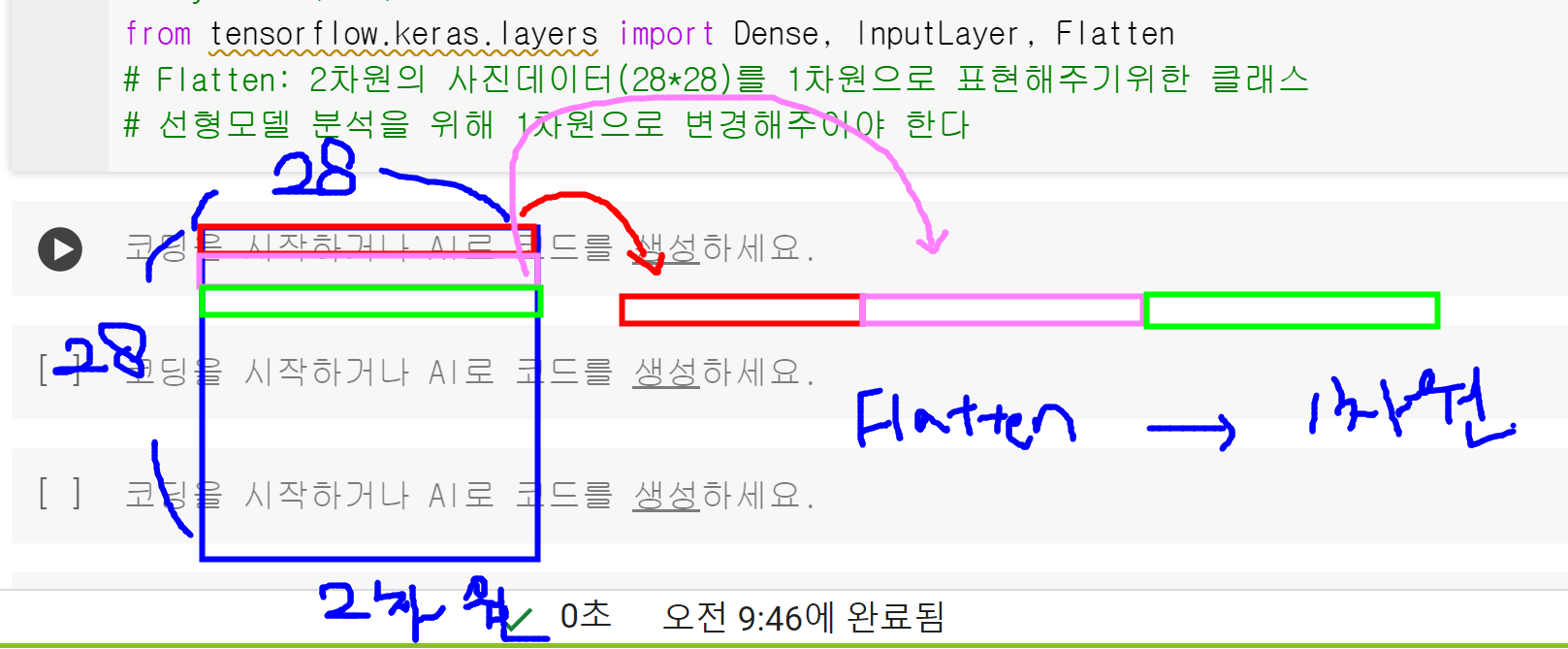
Flatten은 데이터를 1차원으로 만들고 Dense는 특징들을 통해서 사물 구분하는 규칙을 만든다
Dense는 이미지 학습이 잘 안되는데 Conv층이 2차원의 특징을 하나의 픽셀에 정리하기때문에 하나의 픽셀이 모양의 특징값을 가지고 있어서 1차원을 학습해도 모양이 가지는 의미를 학습하기때문에 CNN에서 Dense를 사용한다 ㅡ> 뭔말이냐
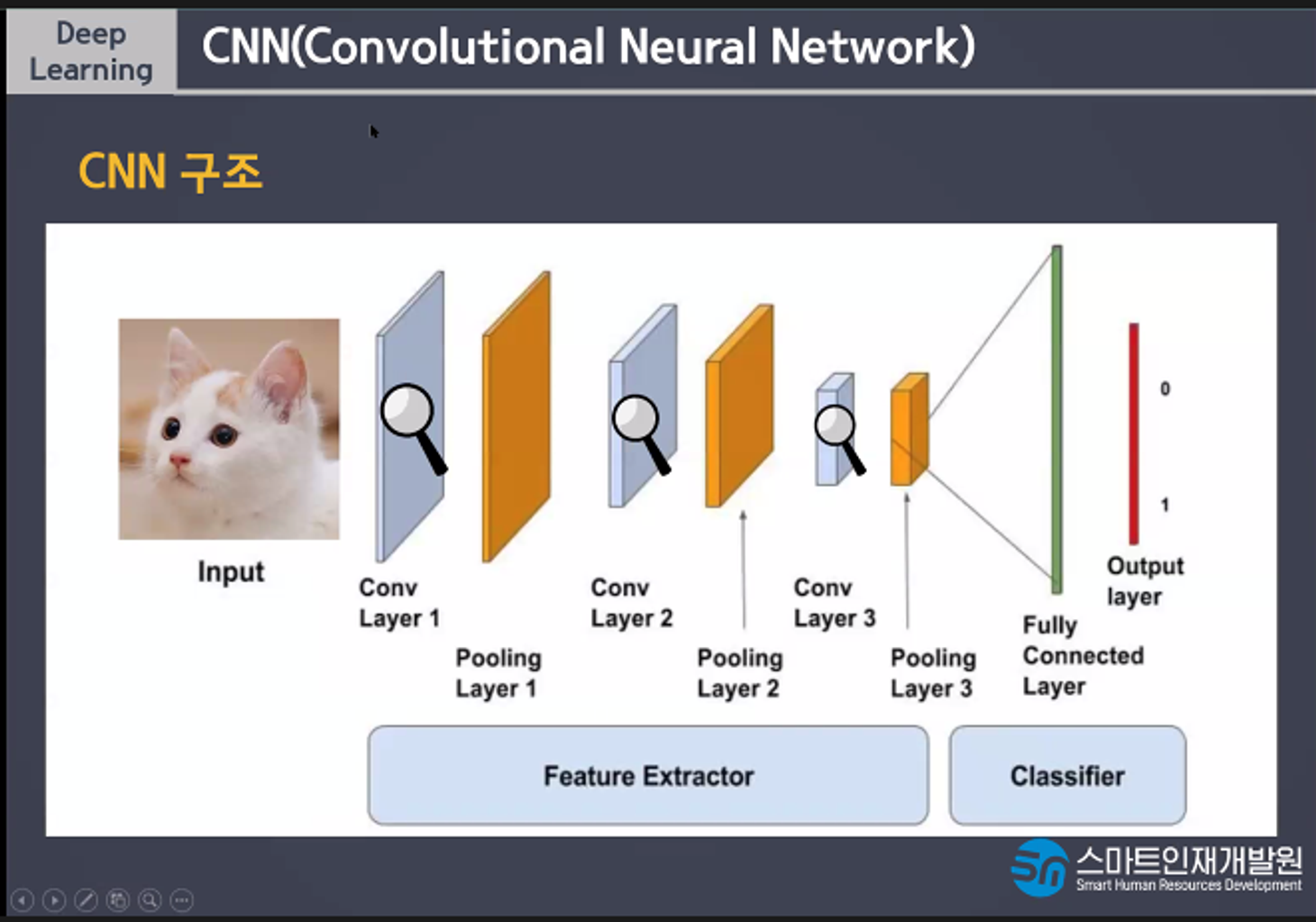
축소 샘플링이란 이미지 크기를 줄이는것이다 특징을 모아놓은것이기 때문에 효율적인 학습을 위해서 데이터의 크기를 줄이는것잉 이득이다. 데이터의 의미는 거의 간직이되기때문에 효율적인 학습이 가능하다.
conv
padding이란 이미지 크기가 줄어드는 것을 막는 방법이다. 필터를 계산하면 줄어드는 이미지를 방지할 수 있다.
stide는 픽셀을 몇개씩 건너뛰면서 계산할지 지정한다.
pooling은 conv결과(특징 모아놓은것)을 전부 다 다음층으로 넘기는것이 아니라 단위크기(2,2)중에서 가장 특징의 값이 큰것만 넘긴다. 픽셀 하나단위로 계산이 되기때문에 인접한 값들은 보통 같은 특징이 있다.
roboflow 실습
!curl -L "https://app.roboflow.com/ds/NbcmlrVdJP?key=MXxFTZTBav" > roboflow.zip; unzip roboflow.zip; rm roboflow.zip
절대로 복사버튼 누르지말고 드래그해서 복붙해!
