자바의 여러가지 자료구조
-
자료의 효율적인 관리는 프로그램의 수행 속도와 밀접한 관계가 있다
-
여러 자료구조 중에서 구현하려는 프로그램에 맞는 최적의 자료구조를 활용해야 하므로 자료구조에 대한 이해가 중요하다.
선형 자료구조
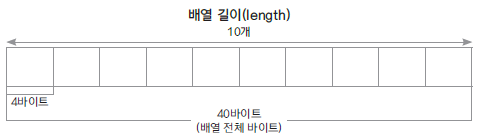
- 배열: Array, 선형으로 자료를 관리, 정해진 크기의 메모리를 먼저 할당받아 사용하고, 자료의 물리적 위치와 논리적 위치가 같음.중간의 요소가 비어있는 경우는 없다. 생성될 때 크기를 지정해야한다.
자료의 삽입과 삭제의 시간복잡도: O(n)
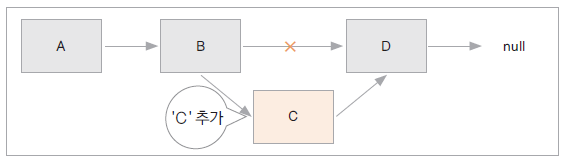
- 연결리스트: LinkedList, 선형으로 자료를 관리, 자료가 추가될 때마다 메모리를 할당 받고 링크로 연결된다. 자료의 물리적 위치와 논리적 위치가 다를 수 있다.
자료와 다음 요소를 가르킬 링크를 갖고 있다.
자료의 삽입과 삭제의 시간복잡도:O(1)
자료 검색의 시간복잡도: O(n) //모든 자료를 처음부터 찾아보아야 한다
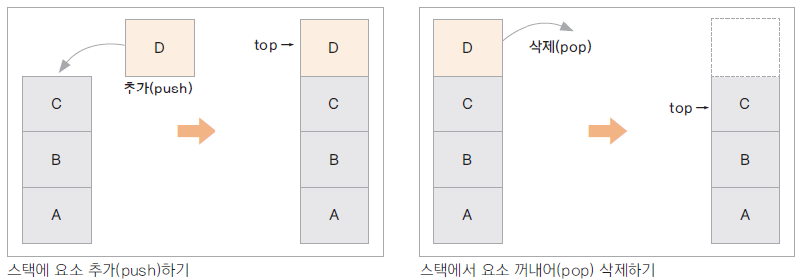
- 스택: Stack, 가장 나중에 입력된 자료가 가장 먼저 출력되는 자료구조. Last In First Out. push(), pop()
바둑에서 수를 무를 때
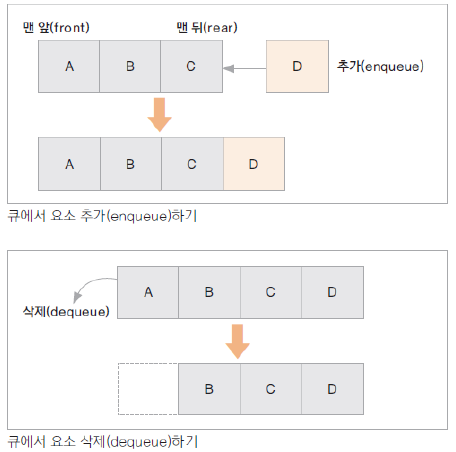
- 큐: Queue, 가장 먼저 입력된 자료가 가장 먼저 출력되는 자료 구조. 앞(front)과 맨 뒤(rear)가 있다. enqueue(), dequeue().
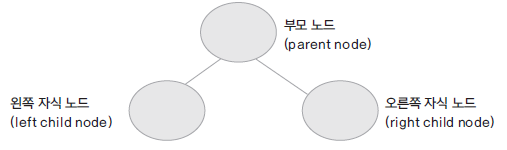
트리: Tree, 부모 노드와 자식 노드 간의 연결로 이루어진 자료 구조
- 이진 트리: binary tree, 부모 노드에 자식 노드가 두 개 이하인 트리
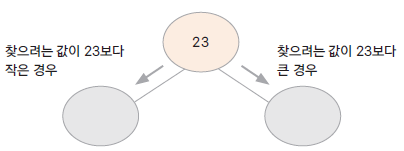
- 이진 검색 트리: binary search tree: 부모 노드보다 작은 수의 값은 왼쪽 노드에, 큰 수는 오른쪽 노드에 있는 트리
자료의 중복이 없어야 한다
자료 검색의 시간복잡도: O(log(n))
- 힙: heap, Priority queue를 구현.
Max heap은 부모 노드가 자식 노드보다 항상 크거나 같은 값을 갖는 것.
Min heap은 부모 노드가 자식 노드보다 항상 작거나 같은 값을 갖는 것.
그래프: 정점과 간선들의 유한 집합 G = (V,E)
정점: vertex, 여러 특성을 갖는 객체, 노드
간선: edge, 객체들을 연결하는 관계, 링크
간선은 방향성이 있는 경우와 없는 경우가 있다
그래프 구현하는 방법: 인접 행렬, 인접 리스트
그래프 탐색하는 방법: BFS, DFS
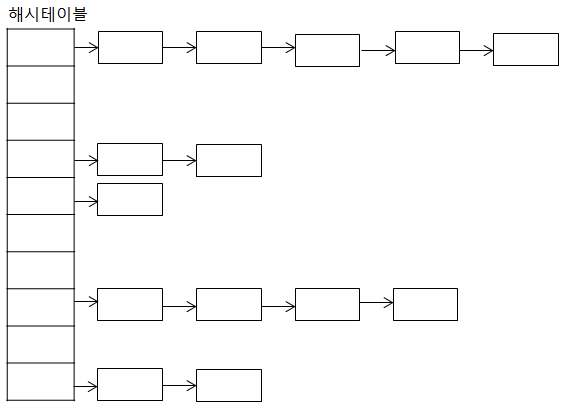
해싱: 자료를 검색하기 위한 자료 구조
key에 대한 자료를 검색하기 위한 사전 개념의 자료 구조
키는 유일하고 이에 대한 value를 쌍으로 저장
index = h(key): 해시 함수가 key에 대한 인덱스를 반환해준다. 해당 위치에 자료를 저장하거나 검색한다
해시함수에 의해 인덱스 연산이 산술적으로 가능 O(1)- 저장되는 메모리 구조를 해시 테이블이라고 한다

- 체이닝: 해시 테이블처럼 안 쓰는 공간이 발생하는 것을 방지
- 배열: Array, 선형으로 자료를 관리, 정해진 크기의 메모리를 먼저 할당받아 사용하고, 자료의 물리적 위치와 논리적 위치가 같음.중간의 요소가 비어있는 경우는 없다. 생성될 때 크기를 지정해야한다.

안녕하세요. Chat JooPT입니다.