JOIN 키워드
: 2개 이상의 각각 다른 table에 들어있는 데이터를 한 번에 조회하는 것
implicit join VS explicit join
- implicit join: 오래된 방식, from절에는 table들만 나열하고 where절에 join condition을 명시하는 방식
where절에 select 조건과 join 조건이 같이 있어서 가독성 ↓
SELECT D.name
FROM employee AS E, department AS D
WHERE E.id = 1 and E.dept_id = D.id; - explicit join: from절에 JOIN ON 키워드와 함께 joined table을 직접 명시하는 방식.
사실상 INNER JOIN임.
SELECT D.name
FROM employee AS E JOIN department AS D
ON E.dept_id = D.id
WHERE E.id = 1inner join VS outer join
- inner join: 두 table에서 join condition을 만족하는 tuple들로 result table을 만듦
따라서 join condition에서 null값을 가지는 tuple은 result table에 포함되지 못한다.
SELECT D.name
FROM employee AS E [INNER]JOIN department AS D
ON E.dept_id = D.id- outer join: 두 table에서 join condition을 만족하지 않는 tuple들도 result table에 포함하는 join
<종류>
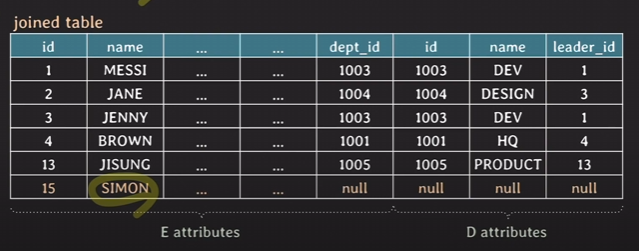
- LEFT JOIN ON: 왼쪽 테이블을 기준으로 result table에 데이터가 만들어짐
SELECT *
FROM employee E LEFT [OUTER] JOIN department D
ON E.dept_id = D.id;일 때 E 테이블에서 null값을 가지고 있는 사원은 포함되어 null값을 나타내는 result table이 됨.
- RIGHT JOIN ON: 오른쪽 테이블을 기준으로 result table에 데이터가 만들어짐
SELECT *
FROM employee E RIGHT [OUTER] JOIN department D
ON E.dept_id = D.id;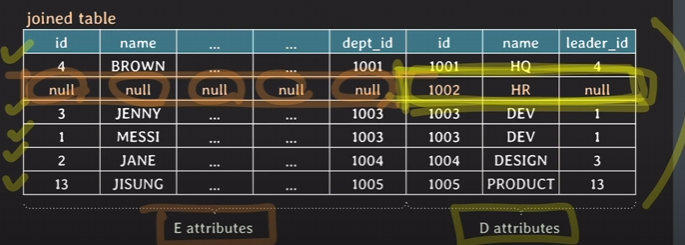
부서아이디 1002를 가지고 있는 사원이 아무도 없기 때문에 이런 결과가 나타남
- FULL JOIN ON: mySQL에서는 지원하지 않아서 PostGreSQL에서 구현, 모든 테이블에서 join condition을 만족하지 않는 tuple 모두 result table에 포함
pgrsql#
SELECT *
FROM employee E FULL [OUTER] JOIN department D
ON E.dept_id = D.id;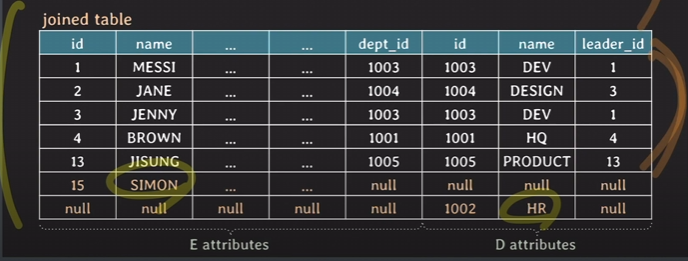
equi join
: join condition에서 =(equality comparator 비교연산자)를 사용하는 join
위에서 사용한 쿼리들 중에 =를 사용한 쿼리들은 모두 equi join이면서 각각의 이름을 가지고 있는 join들이다.
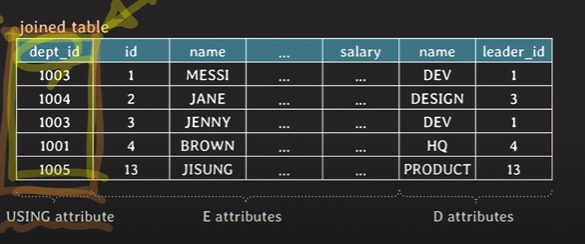
USING 키워드
: 두 table이 equi join할 때 attribute의 이름이 같다면, USING으로 간단하게 작성할 수 있다.
SELECT *
FROM employee E JOIN department D USING (dep_id);USING을 쓰게 되면 합쳐진 attribute는 맨앞쪽으로 위치하게 된다.
NATURAL JOIN
: 두 table에서 같은 이름을 가지는 *모든* attribute pair에 대해서 equi join 실행
join condition을 따로 명시하지 않는다
왜? 같은 이름인 모든 attribute pair들은 그냥 암묵적으로 수행함
SELECT *
FROM employee E NATURAL JOIN department D;결과는 위의 USING의 결과와 같음
그런데 만약, 같은 이름이지만 attribute 내용은 다른 상황이라면?
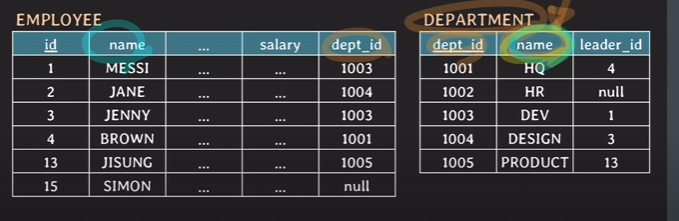
name은 같지만 그 안의 내용은 같은 내용이 아닌 상황.
위의 코드를 풀어쓰면
SELECT *
FROM employee E JOIN department D
ON E.dept_id = D.dept_id AND E.name = D.name;을 의미하기 때문에 사원명 != 부서명 이어서 도출되는 결과가 없다.
CROSS JOIN
: 두 table의 tuple pair로 만들 수 있는 *모든* 조합(Cartesian product)을 result table로 반환한다.
join condition이 없음
공통점이 아닌 그냥 정말 모든!! 조합!
SELECT *
FROM employee CROSS JOIN department
또는
SELECT *
FROM employee, department 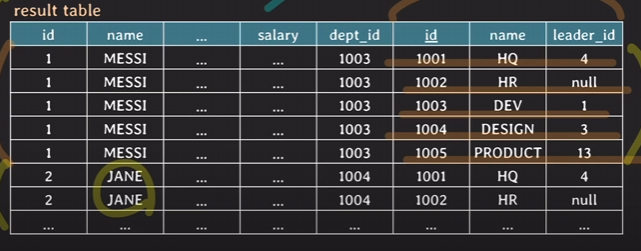
주의!
MySQL에서는 특별하게 cross join = inner join = join 이라서
- CROSS JOIN에 ON(또는 USING)을 같이 쓰면 INNER JOIN으로 동작한다
- INNER JOIN(또는 JOIN)이 ON(또는 USING)없이 사용되면 CROSS JOIN으로 동작한다.
SELF JOIN
: table이 자기 자신에게 join하는 경우가 있다. 는 것만 알아두기
ORDER BY 키워드
: 조회결과를 특정 attributes 기준으로 정렬하여 가져오고 싶을 때
default는 오름차순
- ASC: 오름차순
SELECT * FROM employee ORDER BY salary [ASC];
//급여를 기준으로 오름차순하여 보여줌- DESC: 내림차순
SELECT * FROM employee ORDER BY salary DESC;
//급여를 기준으로 내림차순하여 보여줌
SELECT * FROM employee ORDER BY dept_id ASC, salary DESC;
//부서내에서 연봉을 보여주고 싶을 때aggregate funtion
: 여러 tuple들의 정보를 요약하여 하나의 값으로 추출하는 함수.
NULL값들은 제외하고 요약 값을 추출한다.
<종류>
-COUNT : 중복을 포함하여 attribute 수를 세는 함수
-SUM
-MAX
-MIN
-AVG
//tuple 수를 세고 싶을 때
SELECT COUNT(*) FROM employee; // 16
또는
SELECT COUNT(position) FROM employee; // 16
//중복 상관없이 count함
SELECT COUNT(dep_id) FROM employee; // 14
// null은 포함하지 않고 세기 때문에 position과는 다른 결과-프로젝트 2002에 참여한 임직원 수와 최대 연봉과 최소 연봉과 평균 연봉을 구하시오
SELECT COUNT(*),MAX(salary),MIN(salary),AVG(salary)
FROM works_on W JOIN employee E ON W.empl_id = E.id
WHERE W.proj_id = 2002;GROUP BY
어떠한 attribute를 기준으로 그룹을 나눠서 그룹별로 aggregate function(집계함수)을 적용하고 싶을 때 사용
NULL값이 존재할 때 NULL값을 가지는 tuple끼리 묶인다.
각 프로젝트에 참여한 임직원 수와 최대연봉과 최소연봉과 평균연봉을 구하라
SELECT W.proj_id,COUNT(*),MAX(salary),MIN(salary),AVG(salary)
//그룹의 원하는 것을 추출해야하기 때문에 어떤 그룹인지 표기
FROM works_on W JOIN employee E ON W.empl_id = E.id
GROUP BY W.proj_id;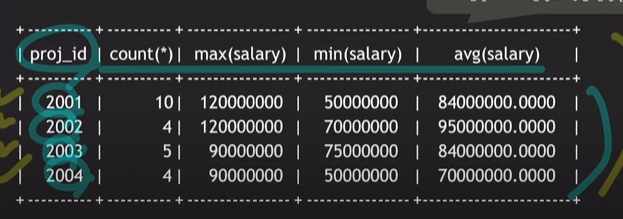
proj_id별 임직원 수와 최대연봉과 최소연봉과 평균연봉
HAVING
: group by가 된 기준으로 조건을 걸고 싶을 때 사용
프로젝트 참여 인원이 7명 이상인 프로젝트들에 대해서
각 프로젝트에 참여한 임직원 수와 최대연봉과 최소연봉과 평균연봉을 구하라
SELECT W.proj_id,COUNT(*),MAX(salary),MIN(salary),AVG(salary)
FROM works_on W JOIN employee E ON W.empl_id = E.id
GROUP BY W.proj_id
HAVING COUNT(*) >= 7;
최종적으로
SELECT attribute or aggregate_function //조회할 것 지정
FROM table [JOIN ON] //어느 테이블에서 조회할 것인지
[WHERE condtion] //tuple에 대해 조건이 필요하면
[GROUP BY group attribute] //그룹별로 조회하고 싶을 때
[HAVING group condition] //특정 그룹만 필터링 하고 싶을 때
[ORDER BY attribute]; //정렬이 필요하면출처: https://www.youtube.com/watch?v=E-khvKjjVv4&list=PLcXyemr8ZeoREWGhhZi5FZs6cvymjIBVe&index=8
