DB schema(스키마)
: data model(relational model이 가장 중요하고 보편화된 모델)을 바탕으로 database의 구조를 기술한 것이기 때문에 스키마는 DB를 설계할 때 정해지며 한 번 정해진 후에는 자주 바뀌지 않는다.
각 데이터는 어떤 속성(atribute)를 가지는지 알 수 있고 데이터가 어떤 식으로 구성되어있는지 전체 큰 그림을 이해할 수 있음.
three-schema architecture
: database system을 구축하는 architecture 중의 하나.
=>데이터 베이스의 구조를 표현하는 것.
user application으로부터 물리적인 database를 분리시키는 목적, 즉 물리적인 데이터베이스가 바뀔 수 있는데 그 때에도 실제로 DB를 사용하는 user application에는 영향을 끼치지 않도록 하는 것임.
=> 안정적으로 DB를 운영하기 위함.
세 가지 level이 존재하며 각각의 level마다 schema가 정의되어있다.
각 level을 독립시켜 어느 level에서의 변화가 상위 레벨에 영향을 주지 않기 위함.
ex) internal schema의 변화가 conceptual schema의 변화로 이어지지 않고 두 schema의 관계 맵핑만 변경시켜주면 됨
external schema와 conceptual schema의 관계 맵핑을 수정하는 것은 까다롭기 때문에 대부분의 DBMS가 완벽하게 나누지는 않음.
-
external schemas
: 실제 사용자가 바라보는 스키마.
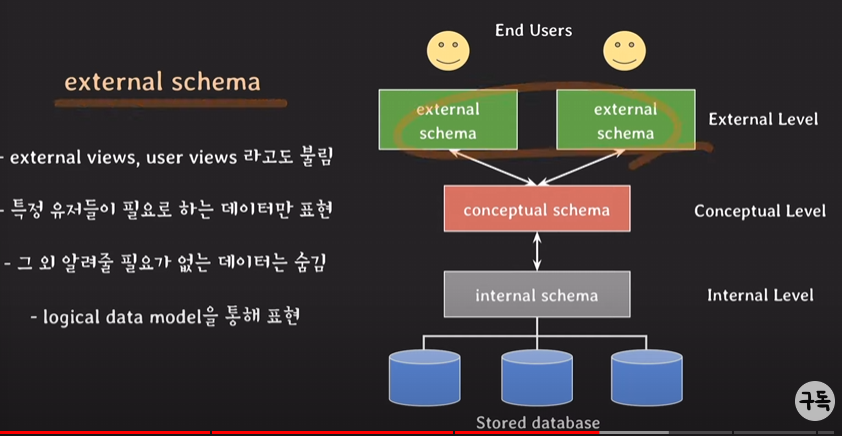
-
conceptual schemas
: 초창기에는 external과 internal schema 밖에 존재하지 않았음. -> 각각의 user마다 필요로하는 데이터가 다름 -> internal level에서 중복되는 데이터 발생(needs에 맞춰 제공하려다보니 같은 데이터임에도 불구하고 조금씩 다른 schema들이 여러개 존재) -> 데이터 불일치와 관리의 어려움 -> 이 문제를 해결하기 위해 conceptual schema 등장.
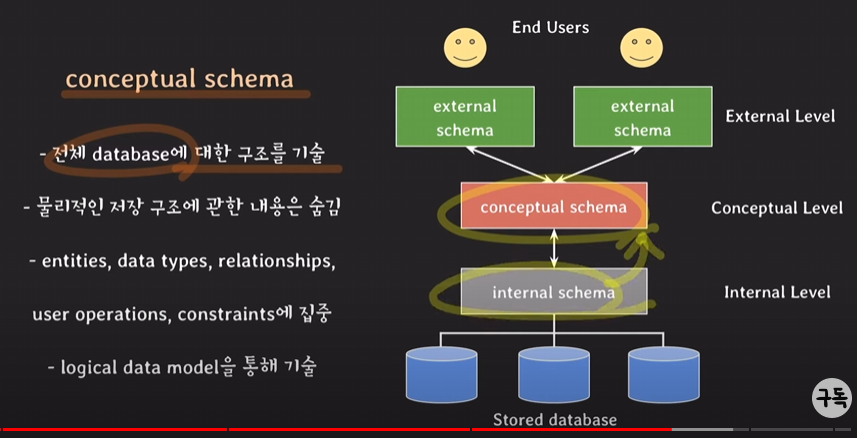
전체 DB 구조를 논리적으로 기술하는 것이기 때문에 internal schema를 추상화한 것이라고 이해하는 것이 좋음.
- internal schemas
: 물리적인 저장장치들과 가장 가까이 위치함.
실제 데이터가 존재하는 곳은 여기에만.
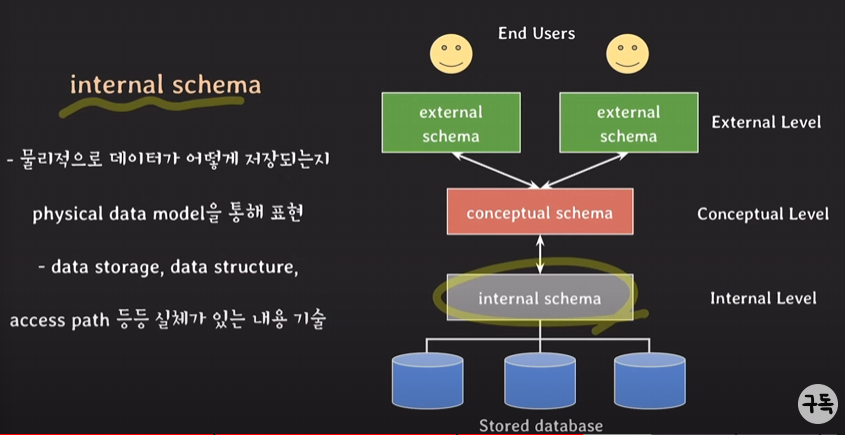
DDL(data definition language)
: conceptual schema를 정의하기 위해 사용되는 언어.(internal schema까지 정의하는 경우도 존재)
대부분의 DBMS에서는 DDL이 VDL(view definition language, external schemas를 정의하기 위해 사용되는 언어)역할까지 수행
DML(data manipulation language)
: database에 있는 실제 data 활용을 위한 언어
ex) data 추가, 삭제, 수정, 조회 등의 기능 제공
SQL(relational database language)
: 요즘의 DBMS는 DDL, VDL, DML이 따로 존재하지 않고 통합된 언어인 SQL로 존재한다.
관계형 데이터베이스
: relation data model에 기반하여 구조화된 database
여러개의 relation으로 구성된다.
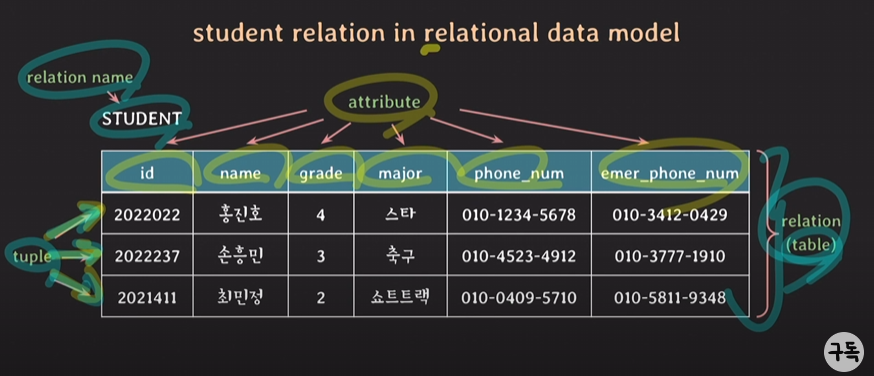
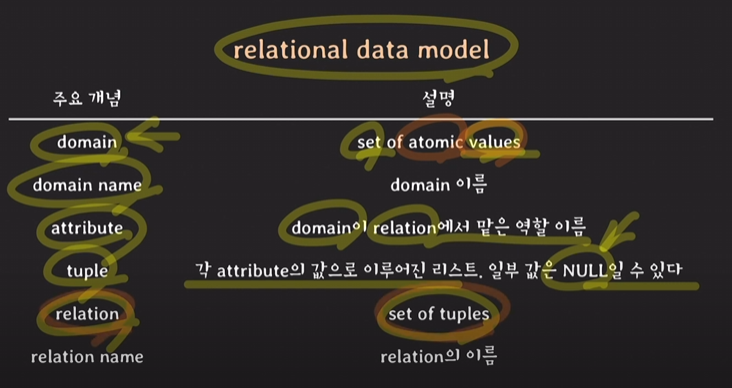
- relation schema: relation의 구조를 나타냄.
relation의 이름과 attributes 리스트로 표기
ex) STUDENT(id, name, grade, major, phone_num)
relation 특징
- 중복된 tuple을 가질 수 없다.
- tuple을 식별하기 위해 attribute의 부분집합을 key로 설정한다.
- tuple의 순서는 중요하지 않다. (=어떤 기준으로 정렬하든지 상관x)
- 하나의 relation에서 attribute의 이름은 중복되지 않는다.
- attribute는 atomic(원자적인, 나눠질 수 없는)해야 한다.
ex) address 라는 attribute의 실제 데이터가 "서울특별시 강남구 청담동" 이라면 서울특별시/강남구/청담동으로 나누어질 수 있기 때문에 이렇게 되면 안 된다.
super key
: relation에서 tuple을 unique하게 식별할 수 있는 attributes set(집합)

primary key
: relation에서 tuple을 unique하게 식별하기 위해 선택된 key

foreign key
: 다른 relation의 PK를 참조하는 attributes set

contstraints
: relational database의 relation들이 언제나 항상 지켜야하는 제약 사항
데이터의 일관성을 보장하기 위함.
- schema-based constraints(=explicit constraint)
: 주로 DDL을 통해 schema에 직접 명시할 수 있는 constraints
<종류>- domain constraints
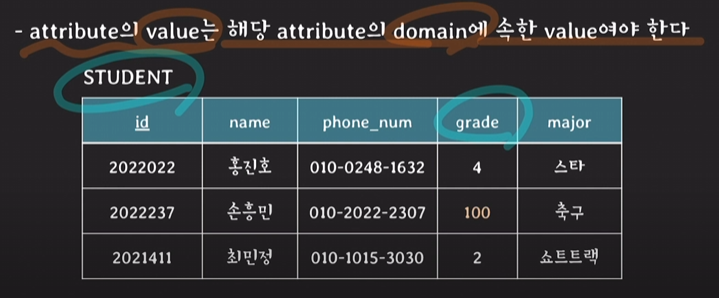
100학년은 존재하지 않음.
- key constraint
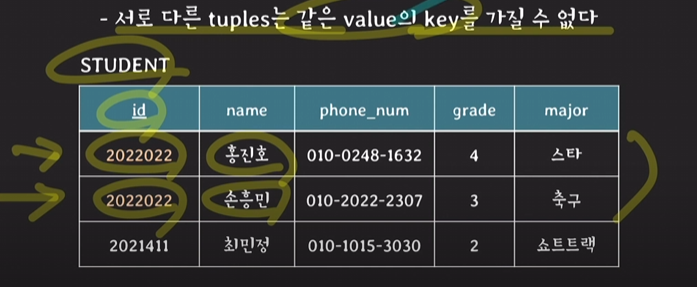
같은 id에 다른 이름의 사람이 존재할 수 없다.
- NULL value constraint
attribute가 NOT NULL로 명시됐다면 NULL을 값으로 가질 수 없다.
- entity integrity constraint:
PK는 value에 NULL을 가질 수 없다.
- referential integrity constraint

team_id가 TEAM 테이블의 id를 참조하고 있는데 team_023 값이 존재하지 않으므로 위반됨.
SQL(Structured Query language) 기본 개념
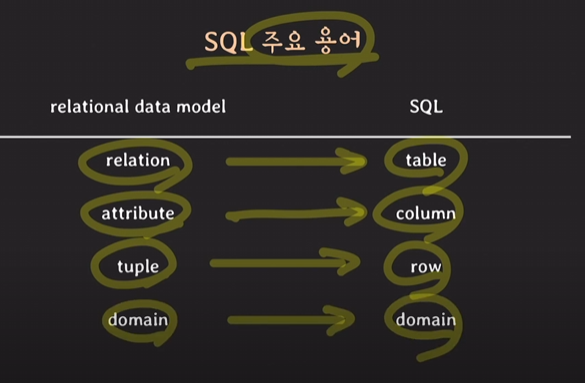
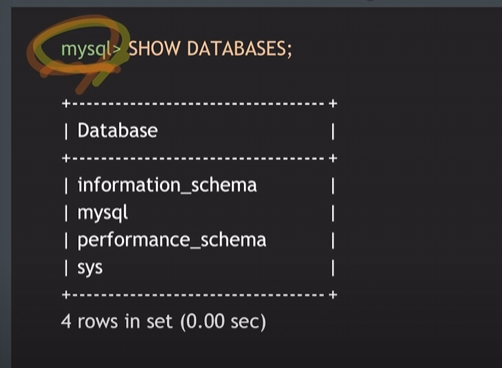
- MYSQL의 어떤 DB들이 있는지 확인
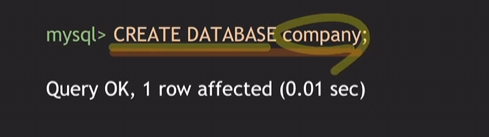
- DB 생성
- DB 조회
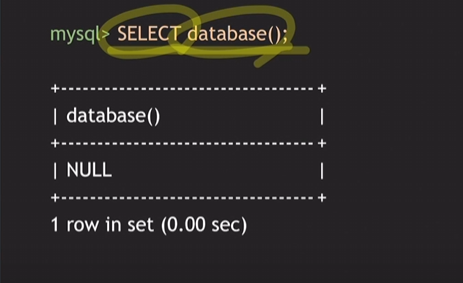
NULL일 경우엔 아직 어떤 DB를 사용하겠다 지정해주지 않은 것.
- DB 지정
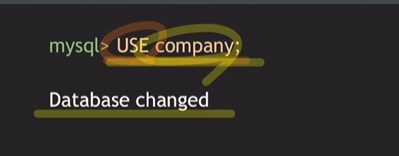
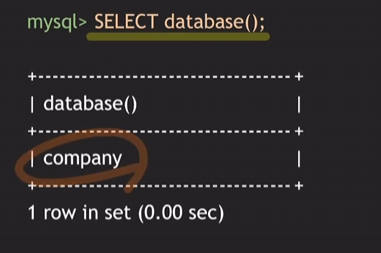
company라는 DB 선택된 상태.
- DB 삭제

DATABASE vs SCHEMA
: MySQL에서는 DataBase와 schema가 같은 뜻. 그래서 DB안에서 table이 정의된다 보면 됨.
그러나 다른 RDBMS에서는 다름!
ex) PostgreSQL에서는 schema가 DataBase의 namespace를 의미. 따라서 DB안에 schema가 정의되고 schema 안에서 table이 정의가 되는 개념.
table 정의하기

precision: 몇개의 숫자를 표현하는지
scale: 소수점 뒤 몇 자리까지 표현하는지
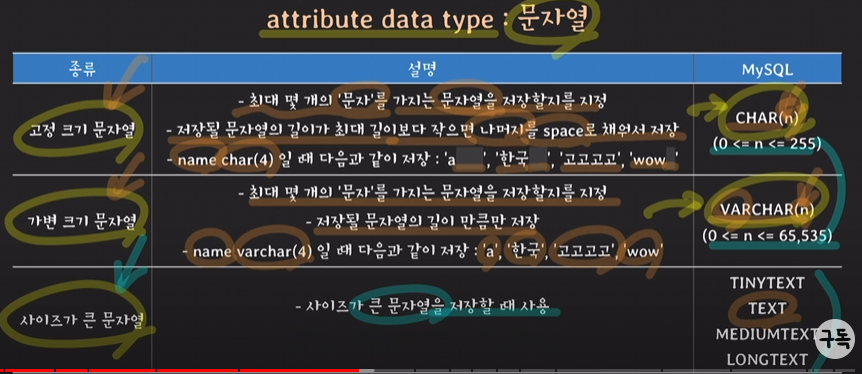
CHAR(n)와 VARCHAR(n)은 데이터 크기와 속도의 차이가 있는데 VARCHAR(n)가 데이터 용량을 절약할 수 있는 반면, CHAR(n)가 데이터를 읽어오는 속도가 훨 빠르기 때문에 전화번호와 같은 고정적인 값은 CHAR(n)으로 정의해주는 것이 좋음.
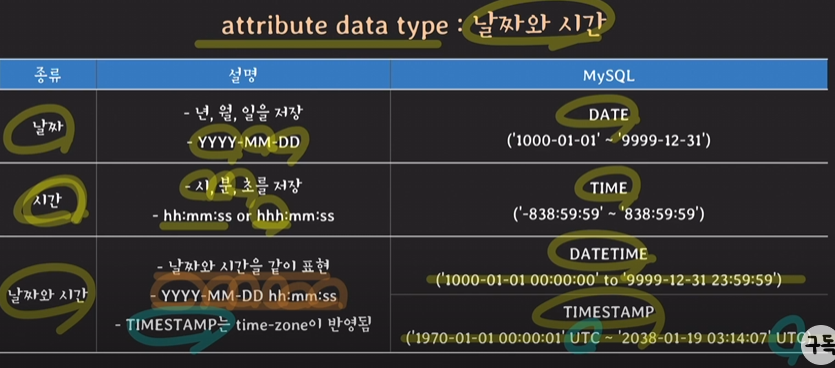
UTC는 표준시간을 의미. 표준시간대로 저장을 했다가 다시 읽어올 때는 표준시간을 MySQL의 time-zone을 반영해서 가져옴

암호화 관련하여 암호화key는 보통 byte-string으로 저장함.



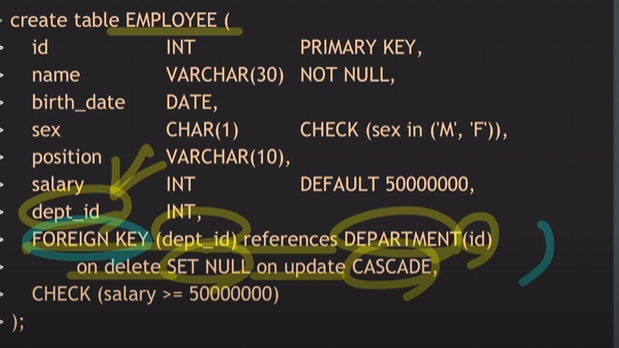
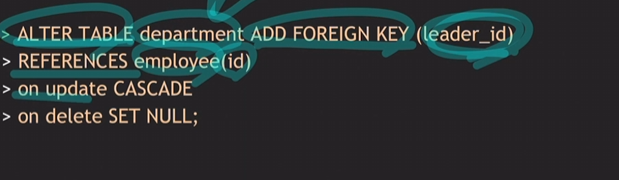
references 참조할테이블명(참조할컬럼)
on delete/update: 참조하고 있던 값이 삭제/변경 될 때 실행될 옵션. 총 5가지가 있으며 MySQL은 CASCADE, SETNULL, RESTRICT의 3가지를 지원한다.
NO ACTION은 RESTRICT와 유사하지만 한 트랜잭션내에 여러개의 SQL문이 실행되는 동안에는 참조값이 삭제/변경되는 것을 허용하지만 트랜잭션이 끝났을 때 여전히 Referntial integrity constraint를 위반하고 있다면 금지한다.
constraint 이름 명시하기
: 이름을 붙이면 어떤 constraint를 위반했는지 쉽게 파악
constraint를 삭제하고 싶을 때 해당 이름으로 삭제 가능
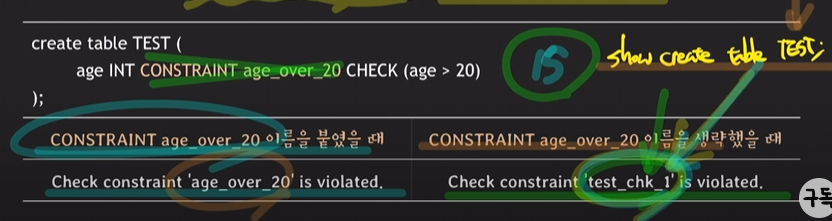
이름을 생략했을 때 test_chk_1이 무엇을 의미하는지 쉽게 파악이 되지 않고 MySQL은 show create table 테이블명을 적으면 무엇을 의미하는지 화면에서 확인 가능함.
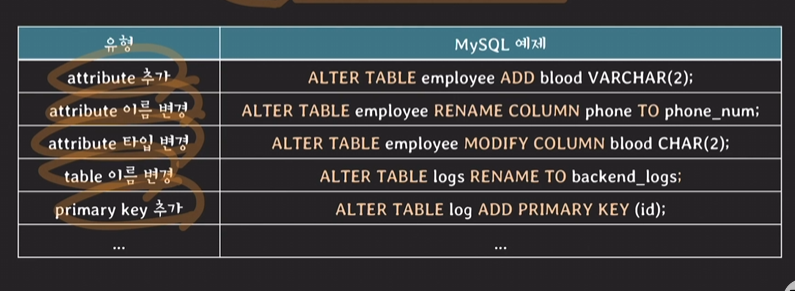
테이블의 스키마 수정하기
: 이미 서비스 중인 table의 schema를 변경하는 것이라면 변경작업 때문에 서비스의 백엔드에 영향이 없을지 검토한 후에 변경하는 것이 중요!
DB에 데이터 추가,수정,삭제,조회
- INSERT INTO 테이블명 VALUES( );
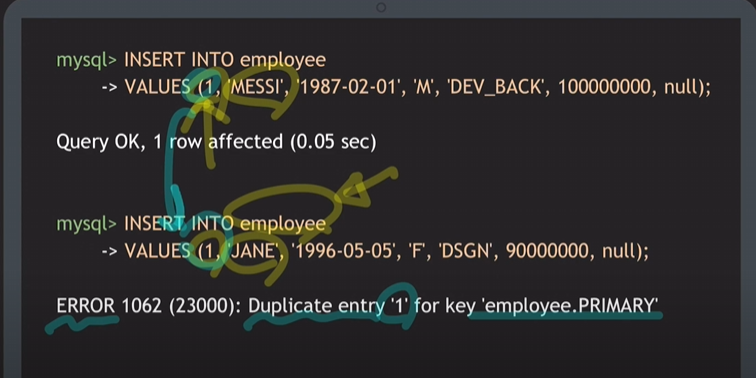
1이라는 기본키가 중복되어서 에러
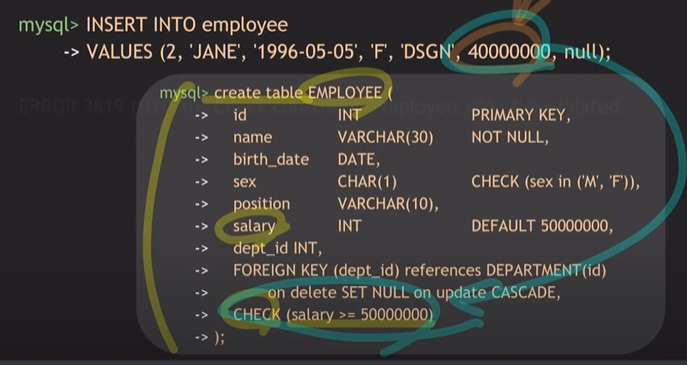
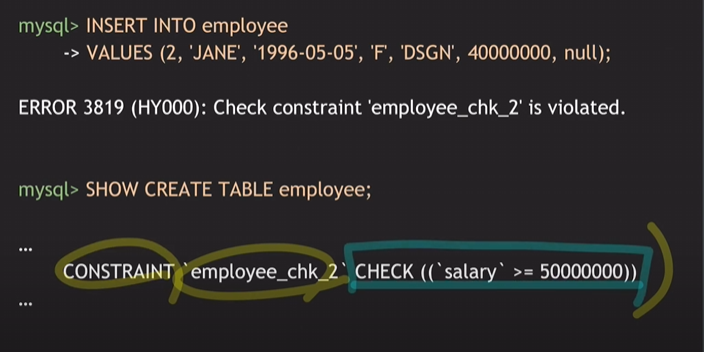
Check constraint 'employee_chk_2' is violated. 오류
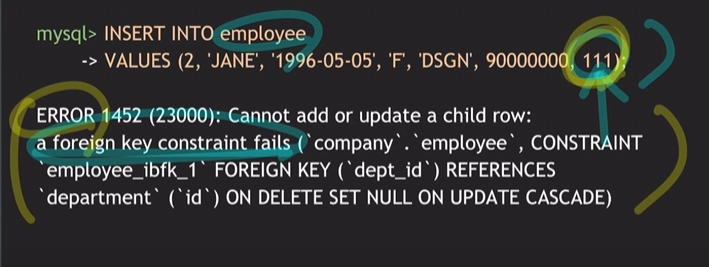
참조하는 값이 실제로 그 테이블에 존재할 때만 값을 지정해줄 수 있음. (=존재하지 않는 값을 넣으면 에러 발생)

여러개의 데이터를 한번에 추가할 때 ( ),( ),( );를 사용하여 추가 가능
- UPDATE 테이블명 SET 속성명 = 변경할값 WHERE 조건절;
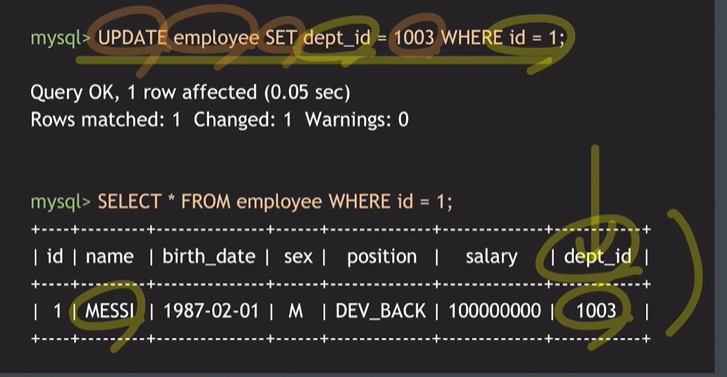
참조되는 테이블의 조건에서 변경할 값이 있을 때
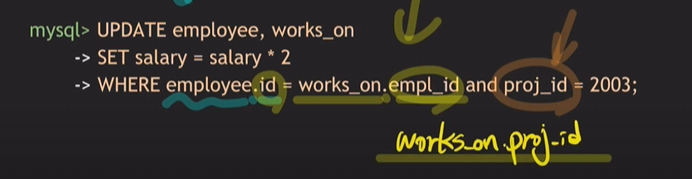
- DELETE FROM 테이블명 WHERE 조건절;

proj_id가 2001인 것을 제외한 나머지는 모두 지운다
- SELECT 속성명 FROM 테이블명 WHERE 조건절;
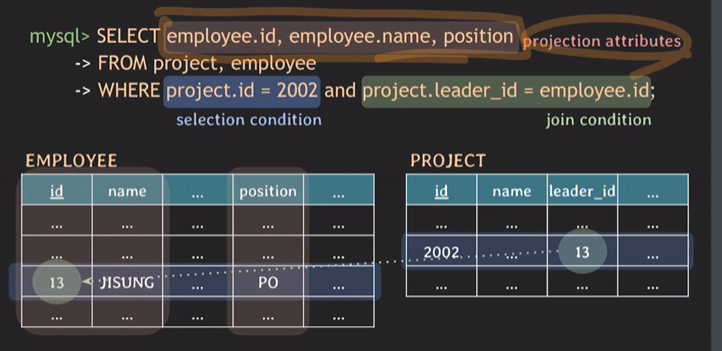
서로 다른 테이블에 같은 속성명이라면 테이블을 명시를 하는 것이 직관적으로 이해하는 것에 도움이 됨.
AS를 이용하여 별칭 붙이기
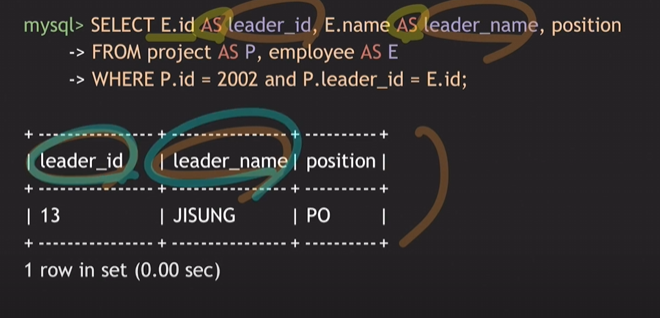
테이블에 별칭을 붙여 짧게 나타낼 수도 있고 속성명에 별칭을 붙여 조회 결과를 나타낼 때는 명시적으로 나타낼 수 있음
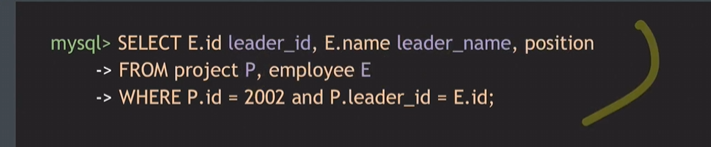
AS가 생략된 상태로 써도 무관함
DISTINCT 키워드
: select 결과에서 중복되는 tuples를 제거

LIKE 키워드
: 글자 조회
- 글자 포함
- WHERE name LIKE 'N%'; : N으로 시작하는 이름
- WHERE name LIKE '%N'; : N으로 끝나는 이름
- WHERE name LIKE '%NG%'; : NG를 포함하는 이름
- 글자수 지정
- WHERE name LIKE 'J___'; : J로 시작하면서 4글자인 이름
- escape 문자
:백슬래시 사용
%로 시작하거나 _로 끝나는 프로젝트 이름을 찾고 싶다면?
SELECT name FROM project WHERE name LIKE '\%%' or name LIKE '%\_';
subquery
: SELECT, INSERT, UPDATE, DELETE에 포함된 query.
반드시 소괄호 안에 기술되며 SELECT부분과 FROM부분, WHERE부분 모두 쓰일 수 있다.
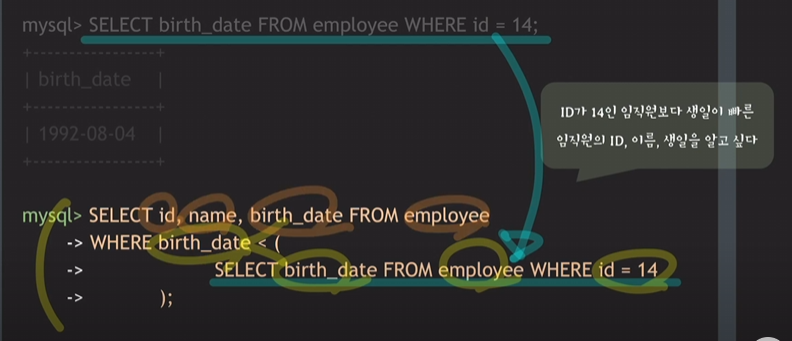
서브쿼리를 포함하고 있는
SELECT id, name, birth_date FROM employee WHERE birth_date
가 outer query가 됨
IN(v1, v2, v3 ...) 키워드
: v가 (v1, v2, v3 ...)중에 하나와 값이 같다면 TRUE를 return 한다.
(v1, v2, v3 ...)는 값들의 집합일 수도 있고 서브쿼리의 결과(set(중복허용) or multiset(중복불허))일 수 있다.
NOT IN(v1, v2, v3 ...): 모든 값과 값이 다르다면 TRUE를 return

임직원들의 ID를 알고 싶은 것이기 때문에 임직원의 아이디가 5인 사람은 제외하고 2001과 2002 프로젝트 모두에 참여한 임직원이 있을 수 있으므로 중복이 발생하기 때문에 DISTINCT로 empl_id 처리해준다.

OR로 쓰기 귀찮을 때 IN 키워드를 사용하여 pro_id에 2001과 2002가 같으면 조회하도록 함
이것을 위의 쿼리와 합치면

이렇게 서브쿼리로 쓸 수 있음
EXISTS 키워드
: subquery의 결과가 최소 하나의 row라도 있다면 true 반환
NOT EXISTS : subquery의 결과가 단 하나의 row도 없다면 true 반환
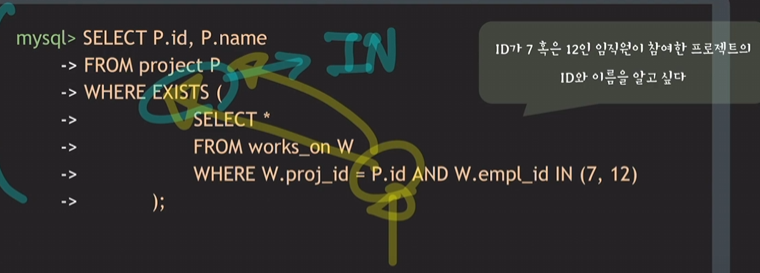
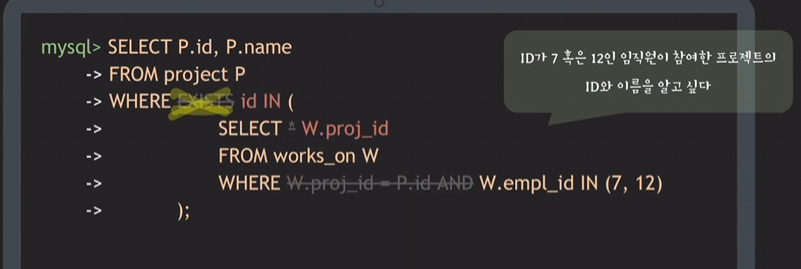
IN으로 변환 가능
ANY(=SOME) 키워드
v 비교연산자 ANY (subquery)
subquery가 반환한 결과들 중에 단 하나라도 v와의 비교 연산이 TRUE라면 TRUE를 반환

ALL 키워드
v 비교연산자 ALL (subquery)
subquery가 반환환 결과들과 v와의 비교 연산이 모두 TRUE라면 TRUE 반환

SQL에서 NULL의 의미
: NULL과 비교할 때는 비교연산자 '='를 쓰면 안 되고 'IS'를 써야 비교가 됨.
SQL에서 NULL과 비교연산 처리를 하게 되었을 때 그 결과는 UNKNOWN이다.
UNKNOWN은 true일 수도 있고 false일 수도 있다는 의미이다.
Three-Valued Logic: 비교/논리 연산의 결과로 true, false, unknown을 가진다.
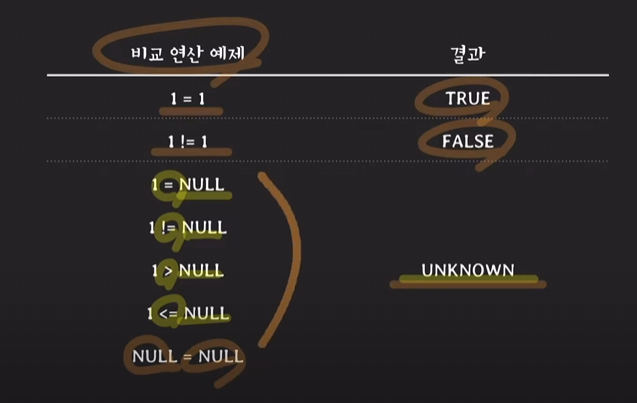
왜 UNKNOWN인가? NULL이라는 값이 실제 유효한 값을 가질 수 있었다면 그게 어떤 값인지에 따라서 결과가 달라지기 때문에


이 논리연산이 왜 중요한가? WHERE절에 있는 condition의 결과가 TURE인 tuple만 선택되므로
즉, 결과가 FALSE거나 UNKNOWN이면 tuple은 선택되지 않는다.

주의! NULL 데이터가 있으면 subquery의 결과가 UNKNOWN이나 FALSE가 되기 때문에 WHERE절은 TRUE일 때만 tuple을 선택하기 때문에 정확한 조회가 안 되는 것.
그렇다면 어떻게 해결해야할까?
방법1. 애초에 employee 테이블에서 dept_id 속성이 NULL값을 가지지 못하도록 NOT NULL constraint설정
방법2. 서브쿼리의 조건절에 'AND E.dept_id IS NOT NULL' 추가하여 서브쿼리가 반환하는 값이 NULL이 없도록 함
방법3. NOT IN을 NOT EXISTS로 변경하여 처리
출처: https://www.youtube.com/watch?v=aL0XXc1yGPs&list=PLcXyemr8ZeoREWGhhZi5FZs6cvymjIBVe&index=1
