같은 자료구조를 쓰더라도 알고리즘은 여러가지가 될 수 있다.
🤔 그렇다면 더 좋은 알고리즘은 무엇일까 ?
사용자의 요구에 따라 다를 것이다.
메모리를 더 적게 사용하고 싶은 사용자라면 메모리를 더 적게 사용하는 알고리즘이 좋은 알고리즘이고, 어떤 사용자는 속도가 더 빠른 알고리즘을 원할 것이다. 이때는 메모리를 더 사용하더라도 속도가 빠른 알고리즘이 성능이 좋은 알고리즘이다.
사용자에 따라 중요시하는 것이 다르지만 일반적으로 알고리즘의 속도를 성능의 척도로 사용한다.
이를 시간 복잡도라고 부른다.
📌 시간 복잡도란 ?
특정 알고리즘이 어떤 문제를 해결하는 데 걸리는 시간을 말한다.
하지만 시간을 측정해서 알고리즘을 평가하기에는 현실적으로 어려움이 있다. 같은 알고리즘이더라도 사용자의 컴퓨터 사양은 다르기 때문에 컴퓨터에서 알고리즘의 실행시간은 다르다.
따라서 알고리즘을 평가할 때는 시간을 측정하는 방식이 아닌 코드에서 성능에 많은 영향을 주는 부분을 찾아 실행시간을 예측하는 것이다.
🤔 그렇다면 코드에서 성능에 많은 영향을 주는 부분은 어떤 것일까?
정답은 반복문이다.
반복문이 여러 번 반복될수록 실행 시간이 길어진다. 따라서 특정 알고리즘의 성능을 평가할 때는 해당 알고리즘의 반복문을 보고 성능을 평가한다.
예시를 통해 알아보자.
🔍 주어진 배열에서 5를 찾으시오
1,3,5,7배열의 0번 인덱스부터 끝까지 순회하며 5인지 아닌지를 검사한다. (방법은 여러개)
우리가 찾는 데이터가 배열의 어디에 있는지에 따라서 성능은 천차만별이다.
-
찾는 데이터가 배열의 첫번째 원소에 있다면 즉 최선의 경우, 한 번 만에 찾아버린다.
- 최선의 경우 한 번에 찾음Big-Ω -
찾는 데이터가 배열의 마지막 원소에 있다면 즉 최악의 경우 배열의 길이만큼 순회해야 찾을 수 있다
- 최악의 경우 배열의 길이만큼 걸림Big-O -
어떤 경우는 데이터가 배열의 중간 인덱스에 잇다면 즉 평균의 경우 배열의 중간에서 찾는다.
- 평균의 경우 배열의 길이 중간 만큼 걸림Big-⍬
이 중에서 Big-O 와 Big-⍬를 사용하는데 가장 많이 사용하는 것은 Big-O이다.
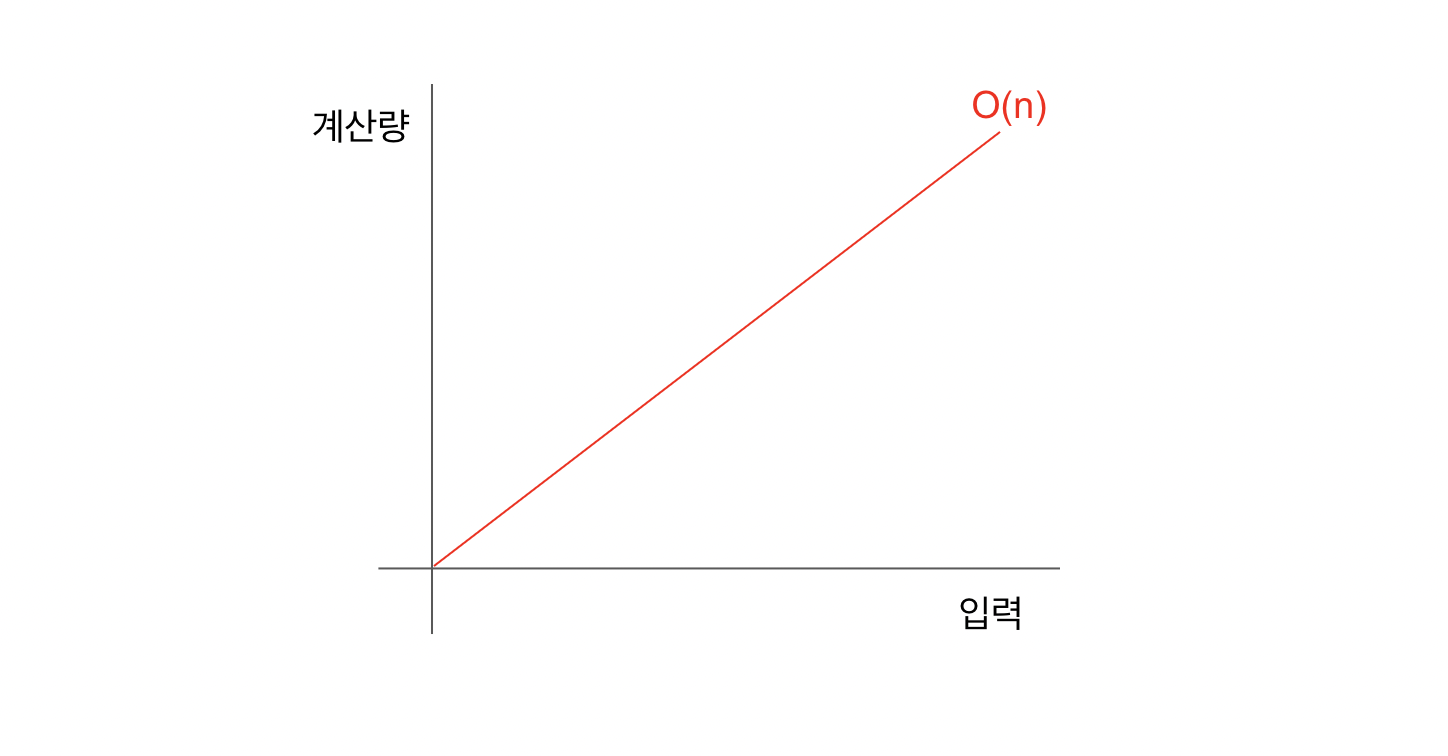
배열의 첫 번째 원소부터 마지막 원소까지 비교하면서 찾으므로 최악의 경우는 찾는 데이터가 가장 뒤에 있는 경우이다. 만약 입력이 n이라면, 즉 배열에 데이터가 n개가 있다면 최악의 경우 n번 만에 데이터를 찾을 수 있다. 이를 빅 오 표기법으로 O(n) 이라 한다.
그래프로 표기하면 일차함수의 모양으로 데이터 수를 나타내는 n에 1을 넣으면 계산량은 1, n에 5를 넣으면 계산량은 5가 된다.
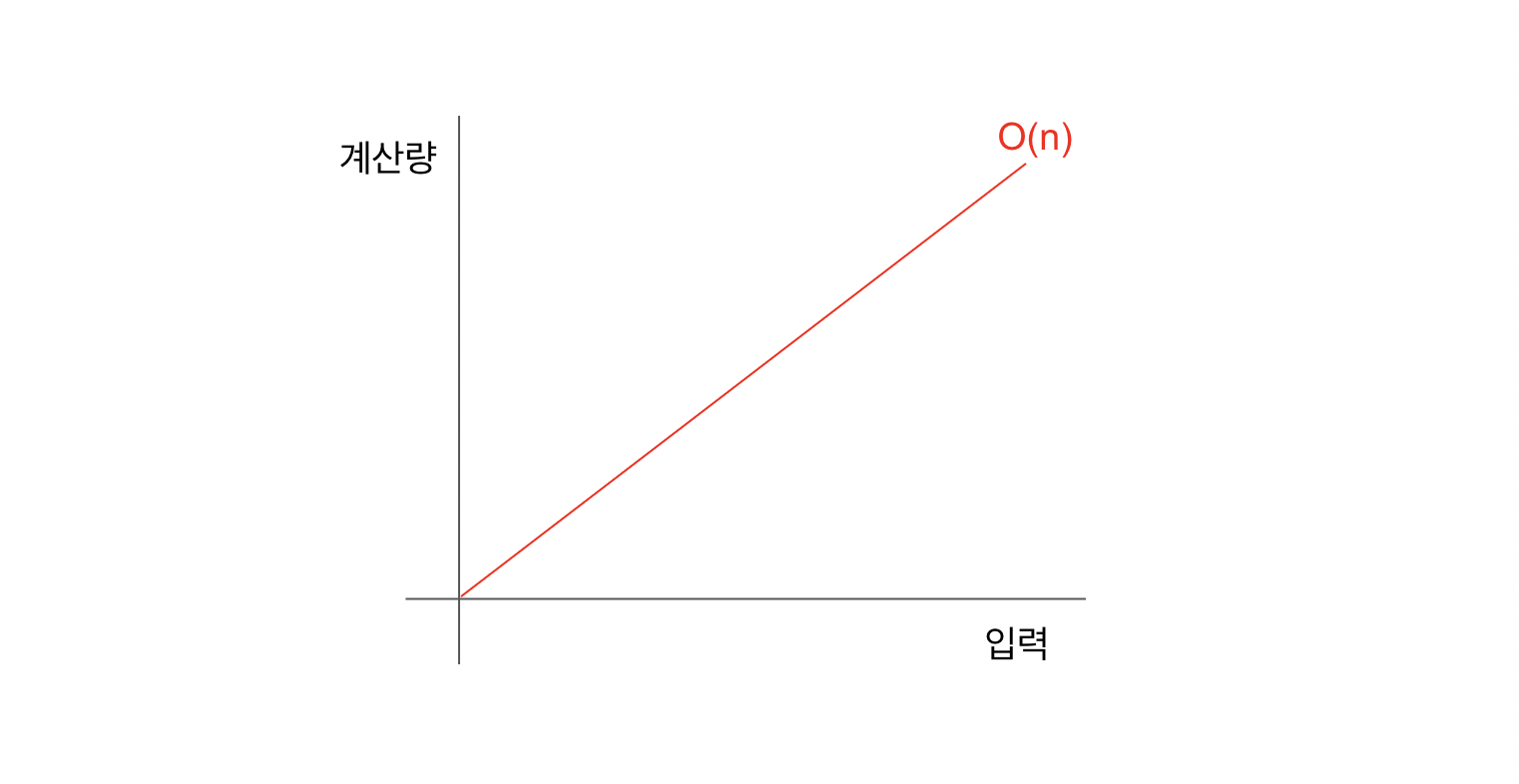
데이터가 많아지면 그에 비례해서 계산량이 많아진다는 것을 알 수 있다.
그래서 O(n)의 알고리즘은 선형시간 알고리즘이라고 부른다.
선형시간 알고리즘 외에도 다른 종류의 알고리즘이 존재한다.
상수시간 알고리즘 O(1)
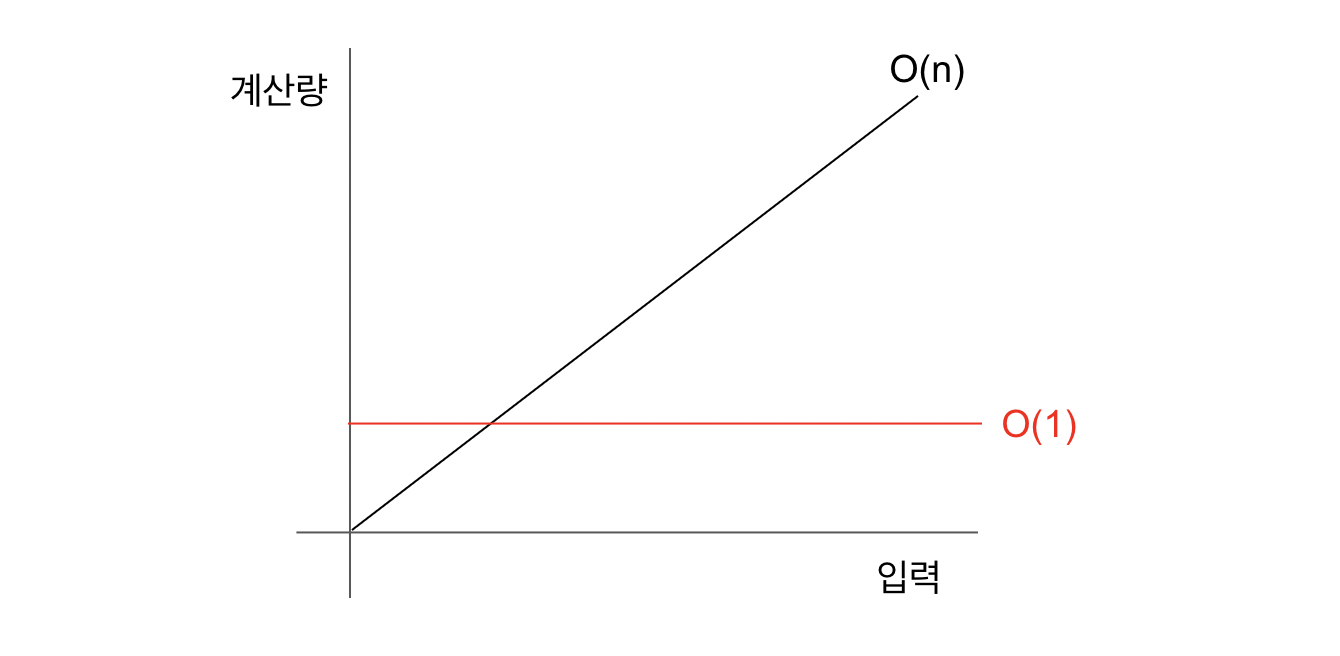
입력의 크기에 상관없이 상수의 시간이 걸린다는 의미로 계산량이 꼭 한 번일 필요가 없다. 문제를 해결하는데 입력의 크기에 상관없이 100번의 계산이 걸린다고 하더라도 상수이기 때문에 O(1) 으로 표기한다.
사실 빅 오 표기법은 성능을 정확하게는 표현하지 못한다. 단순히 해당 알고리즘의 입력이 늘어날 때 계산량이 얼마나 늘어나는지 표현하는 방법이기 때문이다.
이외에도 O(logn), O(nlogn), O(n2), O(2n), 0(n!) 가 있고, 왼쪽으로 갈 수록 성능이 좋지 않은 알고리즘이다.
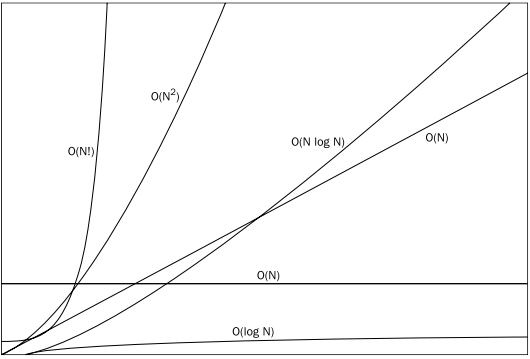
📌 빅오 표기법의 특징
-
입력이 늘어날때 계산량이 늘어나는 척도를 나타내기 위한 것
-
빅오 표기시 상수는 제거한다. 2n2 + 100n = O(N2)
