왜 ConcurrentHashMap은 Hashtable을 대체했을까?
멀티스레드 환경에서 안전하게 사용할 수 있는 Map 구현체로 자바는 오랫동안 Hashtable을 제공해 왔습니다.
하지만 시간이 지나면서 더 높은 성능과 동시성이 요구되었고, 그 결과로 ConcurrentHashMap을 포함한 concurrent 컬렉션들이 등장하게 되었습니다.
1. Hashtable의 탄생: “쓰레드 안전한 Map”
초기 자바에서는 멀티스레드 환경에서 사용할 수 있는 기본 자료구조로 Vector, Hashtable처럼 동기화된 컬렉션을 함께 제공했습니다.
Hashtable은 Map 인터페이스의 초창기 구현체로, 여러 스레드가 동시에 접근해도 데이터 일관성을 보장한다는 점이 강점이었습니다.- 이를 위해 대부분의 메서드가
synchronized키워드를 사용해 구현되어 있습니다.
즉, “동시에 접근할 수 있는 안전한 해시 기반 Map”이라는 요구에 대한 초창기 해답이 바로 Hashtable이었습니다.
2. 불편함과 한계: 전역 락의 비용
문제는 멀티코어 CPU와 높은 동시성을 요구하는 서버 애플리케이션이 일반화되면서부터 드러났습니다.
2-1. 모든 메서드에 걸린 synchronized
Hashtable의 주요 메서드는 모두 synchronized로 선언되어 있습니다.
get,put,remove등 거의 모든 연산에 대해 인스턴스 전체에 하나의 락을 사용합니다.- 어떤 스레드가
get()을 실행 중이면, 다른 스레드는put()은 물론 다른get()호출조차 동시에 수행할 수 없습니다.
결과적으로:
- 스레드 수가 늘어날수록 락 경합(lock contention)이 매우 커집니다.
- 읽기 비율이 높은 상황에서도, 모든 연산이 락을 잡으므로 병렬 성능이 거의 나오지 않습니다.
2-2. 논리적 안전성의 한계
Hashtable이 “각 메서드 단위로는” 동기화를 제공하지만, 복수 메서드를 묶어 사용하는 패턴에서는 레이스 컨디션이 발생할 수 있습니다.
if (!hashtable.containsKey(key)) {
hashtable.put(key, value);
}위와 같은 코드는 두 메서드 호출 사이에 다른 스레드가 끼어들 수 있기 때문에, 여전히 동시성 버그가 발생할 수 있습니다.
즉, 단순 synchronized 메서드만으로는 고수준의 동시성 제어를 완전히 해결하기 어렵습니다.
3. Concurrent 패키지와 ConcurrentHashMap의 등장
자바 5에서는 java.util.concurrent 패키지와 함께 보다 정교한 동시성 도구들이 도입되었습니다.
ConcurrentHashMap은 “멀티스레드 환경에서 안전하면서도 고성능인 Map”을 목표로 설계된 구현체입니다.- 자바 공식 문서에서도 “전체 읽기에 대한 완전한 동시성과, 업데이트에 대한 높은 기대 동시성”을 제공하는 해시 테이블이라고 설명합니다.
핵심 설계 목표는 다음과 같았습니다.
- 쓰레드 안전성은 유지.
- 단일 전역 락 대신, 세분화된 동기화로 병목을 최소화.
- 멀티코어 환경에서 스레드가 많아질수록 처리량이 함께 늘어날 수 있도록.
4. 기술적 차이: Lock Striping과 세분화된 동기화
4-1. Hashtable: 전체를 잠그는 구조
- 하나의 인스턴스를 하나의 락이 보호합니다.
- 어떤 키에 대한 연산이든, 항상 동일한 락을 두고 경쟁하게 됩니다.
이 때문에:
- 스레드 수가 많아질수록 대부분의 스레드가 BLOCKED 상태에서 락을 기다리게 됩니다.
- 고부하 서버 환경에서는 치명적인 병목이 됩니다.
4-2. ConcurrentHashMap: 락을 쪼개는 Lock Striping
ConcurrentHashMap은 내부 구조를 나누어, 부분별로 다른 락 또는 CAS를 사용합니다.
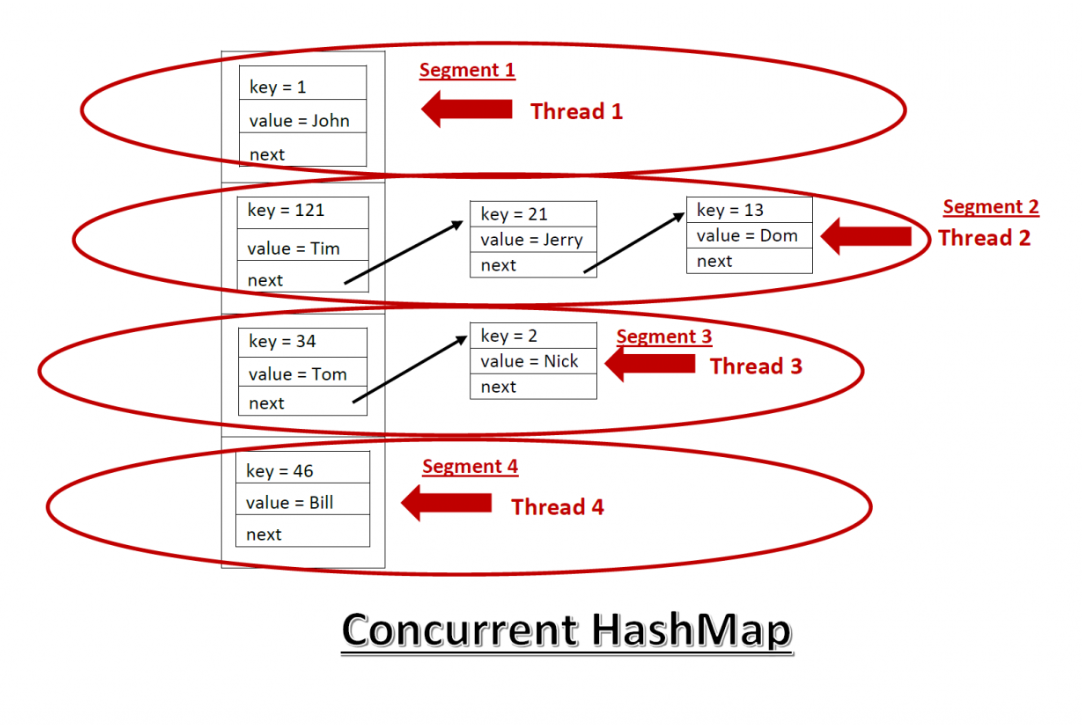
- 자바 7 이전: 내부를 여러 개의 세그먼트(Segment)로 나누고, 세그먼트마다 별도의 락을 사용.
- 자바 8 이후: 세그먼트 대신 버킷/노드 단위 락 + CAS(Compare-And-Swap)로 더 세밀한 동기화를 구현.
이러한 기법을 Lock Striping(락 스트라이핑)이라고 부르며, 핵심 아이디어는 다음과 같습니다.
“맵 전체에 하나의 락을 쓰지 말고, 여러 조각으로 나눈 뒤
서로 다른 조각에 대해서는 동시에 접근 가능하게 만들자.”
4-3. 그 결과 얻는 이점
- 여러 스레드가 서로 다른 키에 접근할 경우, 각기 다른 락을 사용하므로 경합이 크게 줄어듭니다.
- 읽기(
get)는 대부분 락 없이 진행되도록 설계되어, 읽는 비율이 높은 워크로드에서 특히 강점을 보입니다. - 동시에 많은 스레드가 작업해도, 전체 처리량이 잘 스케일됩니다.
5. 실무에서의 선택: 왜 이제는 ConcurrentHashMap인가
정리해 보면:
-
Hashtable- 장점: 오래된 코드와의 호환성, 단순한 동기화 모델.
- 단점: 전역 락으로 인한 심각한 병목, 현대적인 동시성 패턴과 어울리지 않음.
-
ConcurrentHashMap- 장점: 세분화된 락과 CAS 덕분에 높은 동시성 + 좋은 성능.
- 장점:
putIfAbsent,compute,merge등 고수준 동시성 연산 지원. - 실무에서 “멀티스레드 환경의 Map”이 필요할 때의 사실상 기본 선택지.
자바 커뮤니티에서는 Hashtable을 사실상 레거시로 보고, 신규 코드에서는 사용을 권장하지 않습니다.
대신, 동시성이 중요하다면 ConcurrentHashMap, 단순히 동기화된 Map이 필요하다면 Collections.synchronizedMap(new HashMap<>()) 같은 대안이 일반적입니다.
개인적으로는 ConcurrentHashMap은 사용해봤지만 Hashtable을 사용해본적이 없어 과거 개발자들의 개발적 고충이 느껴지는 발전 과정을 알아보는 흥미로운 경험이었습니다.
6. ConcurrentHashMap의 put()이 동작하는 과정
말로만 설명을 들어서는 잘 감이 안올 수 있다. 실제 데이터를 넣을 때 어떤 방식으로 동작하는지 알아보자.
이 putVal은 “ConcurrentHashMap에 키/값을 넣을 때, 동시성을 보장하면서도 락을 최소화하려는” 핵심 메서드다.
큰 흐름만 단계별로 쪼개서 보면 훨씬 덜 복잡하게 보인다.
6-1. 초반부: 기본 체크와 해시 계산
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {null키/값은 허용하지 않기 때문에 바로 NPE.spread는 해시를 섞어서 상위 비트까지 골고루 쓰도록 만드는 함수.tab = table을 잡고 무한 루프를 돌면서, 상태에 따라 적절한 경로를 선택하는 구조다.
6-2. 테이블 초기화/버킷 선택
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}tab이 비어 있으면initTable()로 초기화.(n - 1) & hash로 인덱스i계산 → 이게 사용될 버킷.- ConcurrentHashMap은 테이블 크기를 2의 제곱으로 유지하기 때문에, hash % n 대신 (n - 1) & hash로 인덱스를 계산해 빠르게 0 ~ n-1 범위로 매핑한다.
tabAt(tab, i)로 해당 위치의 첫 노드f를 읽는다 (volatile read).
만약 그 버킷이 비어 있으면(f == null):
casTabAt(tab, i, null, new Node(...))- 이 위치가 여전히
null인 경우에만 CAS로 새 노드를 꽂는다. - 성공하면 락 없이 삽입 종료 → “빈 버킷에 넣을 때는 완전 무락 경로”다.
- 이 위치가 여전히
6-3. 리사이즈 중인 경우 처리
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);f.hash == MOVED는 “현재 테이블이 리사이징 중이다”를 나타내는 특수 마커.- 이 경우
helpTransfer를 호출해서 현재 스레드도 리사이즈 작업을 조금 도와준 뒤, 새 테이블에서 다시 시도한다.
6-4. onlyIfAbsent 최적화 (락 없이 첫 노드 검사)
else if (onlyIfAbsent
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;putIfAbsent처럼 “이미 값이 있으면 바꾸지 말고 기존 값만 돌려줘” 케이스.- 이때는 락을 잡기 전에, 첫 노드만 확인해서 동일 키 + 값 존재하면 바로 리턴한다.
- 즉, 흔한 패턴에 대해 불필요한 락 진입을 줄이려는 최적화다.
6-5. 핵심 구간: bin(버킷) 단위 락 + 체인/트리 갱신
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
...
}여기가 Java 8 ConcurrentHashMap의 버킷/노드 단위 락이 드러나는 부분이다.
-
synchronized (f)- 세그먼트 전체가 아니라, 해당 버킷의 첫 노드
f에만 락을 건다. - 이게 “버킷/노드 락”이라는 표현의 실체.
- 세그먼트 전체가 아니라, 해당 버킷의 첫 노드
-
if (tabAt(tab, i) == f)- 락을 잡는 동안 다른 스레드가 이 bin을 건드려서 교체해 버렸는지 확인.
- 여전히 같은 노드일 때만 이 락이 유효하다고 보고 이어서 처리.
-
fh >= 0→ 일반 체인(연결 리스트)for (e = f; ; ++binCount)루프로 체인을 순회.- 같은 해시+키를 찾으면 값 업데이트, 없으면 체인 끝에 새 노드 연결.
binCount로 bin 내 노드 개수를 센다.
-
f instanceof TreeBin→ 트리화 된 bin- 노드 수가 많아지면 bin이 트리 구조(
TreeBin)로 바뀐다. - 이 경우
putTreeVal로 레드블랙 트리에 삽입/갱신.
- 노드 수가 많아지면 bin이 트리 구조(
-
ReservationNode- 내부적으로 특수 상황(예: 재귀 갱신) 표시용 노드로, 여기 들어오면 예외 던져서 이상 상태를 막는다.
6-6. 트리화 여부 체크 + 카운트 증가
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
...
addCount(1L, binCount);
return null;binCount≥TREEIFY_THRESHOLD(보통 8)이면 해당 bin을 트리 구조로 바꾼다.- 기존 값이 있었다면 그 값을 반환, 없었다면
null반환 (put의 반환 규칙). addCount는 전체 요소 수를 증가시키면서 필요 시 리사이즈 트리거를 거는 부분.
6-7. 요약: 이 메서드가 보여주는 것
이 putVal 한 메서드에 ConcurrentHashMap의 설계 포인트가 거의 다 들어 있다.
- 빈 버킷에는 CAS로 락 없이 삽입 → 경합 최소화.
- 리사이즈 중이면 helpTransfer로 분산 리사이즈.
- onlyIfAbsent 최적화로 불필요한 락 회피.
- 수정이 꼭 필요할 때만 버킷 첫 노드에 synchronized → 세그먼트 전체 락보다 훨씬 세밀한 동기화.
- 노드 수가 많아지면 트리화(TreeBin)로 탐색 성능 유지.
다음 주제는 CAS(Compare And Swap)로 비동기 작업을 지원하는 여러 클래스에서 활용하는 동기화 기법에 대해 준비해보겠습니다.
[참고]
https://www.geeksforgeeks.org/java/difference-between-hashtable-and-synchronized-map-in-java/
https://velog.io/@alsgus92/ConcurrentHashMap%EC%9D%98-Thread-safe-%EC%9B%90%EB%A6%AC
https://learncodewithdurgesh.com/tutorials/core-java-tutorial-for-beginners/concurrenthashmap-in-java-internal-working-thread-safety-examples
https://devlog-wjdrbs96.tistory.com/269
https://hgggny.tistory.com/entry/Hashtable%EC%9D%98-%EB%8F%99%EA%B8%B0%ED%99%94synchronization
