
1차 프로젝트를 진행하면서 상품을 컨셉과 카테고리 별로 정렬해 보여주는 페이지를 구현하는 기능을 만들었다. 그런데 컨셉을 필터링하는 과정에서 QuerySet에 동일한 Instance가 중복되어 들어간다는 사실을 깨닫게 되었다. 이를 해결하기 위해
distinct()method를 사용하였는데, 이 외에 다른 해결법이 있는지 고민해봤다.
Error

웹사이트에서 보여주는 상품의 Filtering은 위와 같이 category인 텐미닛 플래너, 태스크 매니저, 플랜 보드, .., concept인 오리지널, 그리고 option인 31 DAYS, 100 DAYS, .. 의 세 가지로 이루어진다.
백엔드는 프론트엔드가 요청한 상품 데이터를 먼저 category와 option으로 Filtering하고, 그 item들을 **concept의 정보와 concept별 item으로 묶은 Dictionary 형태**로 보내준다.
results = [
{
'concept' : concept.name if not main else None,
'concept_description' : concept.content if not main else None,
'concept_id' : concept.id if not main else None,
'information' : [
{
'id' : item.id,
'name' : item.name,
'price' : item.price,
'discount' : item.discount,
'stock' : item.stock,
'color' : item.color.name if not item.color is None else None,
'image' : item.image_set.get(main=1).image_url
} for item in (Item.objects.filter(Q(concept_id=concept.id)&Q(option_id=option_id)) if not main else [concept])]
} for concept in concepts]이 때, 가장 큰 for문에 들어가는 concepts는 category가 Planner인 Item의 모든 concept을 필터링한 Queryset으로, 아래와 같은 결과물을 생각하고 코드를 짰다.
Concept.objects.filter(item__category_id = category_id)
<QuerySet [<Concept: Concept object (1)>, <Concept: Concept object (2)>, <Concept: Concept object (3)>, <Concept: Concept object (4)>]>그런데 알고보니 실제로 concepts의 형태는 중복되는 Instance가 한데 뭉쳐진 결과물이었다.
<QuerySet [<Concept: Concept object (1)>, <Concept: Concept object (1)>, <Concept: Concept object (1)>, <Concept: Concept object (2)>,
<Concept: Concept object (2)>, <Concept: Concept object (2)>, <Concept: Concept object (2)>, <Concept: Concept object (2)>,
<Concept: Concept object (2)>, <Concept: Concept object (2)>, <Concept: Concept object (2)>, <Concept: Concept object (2)>,
<Concept: Concept object (3)>, <Concept: Concept object (3)>, <Concept: Concept object (3)>, <Concept: Concept object (4)>,
<Concept: Concept object (4)>, <Concept: Concept object (4)>]>왜 이런 결과가 도출되었을까 생각해봤더니(꽤 긴 시간을), 생각보다 원인은 명료했다.
Cause of Error
concept를 선언하기 위해 사용한 Query문에 존재하는 concept, category, item의 관계를 살펴보면 아래와 같다.
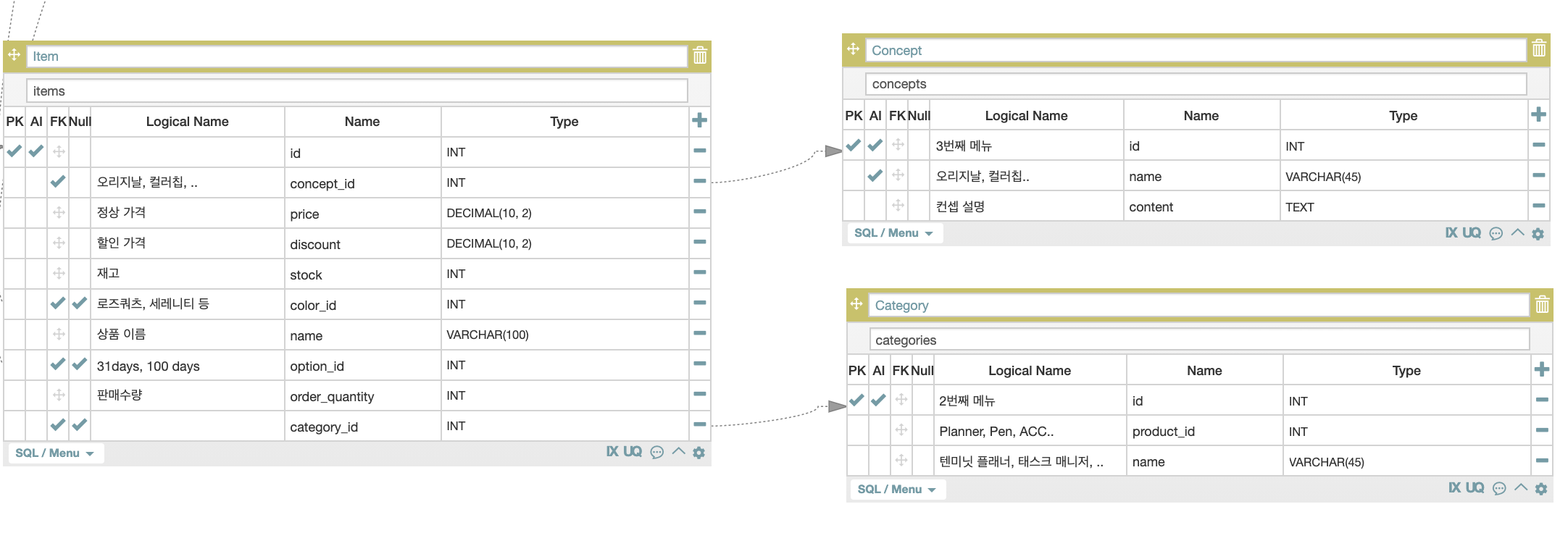
concept와category가item이라는 중간 Table을 두고 있는 ManyToMany Relationship이었다! 게다가 제대로 Normalization을 하지 않은 탓에 여러item이 동일한 (concept,category) 값을 가지고 있었다.
예를 들어 item id=1,2,3인 상품들이 모두 concept가 오리지널, category가 텐미닛 플래너 이기 때문에 concepts Queryset에 <Concept: Concept object (1)> Instance가 3개나 중복되어 들어간 것이다..
Simple Solution - distinct()
처음에 이런 근본적인 원인을 찾지 못한채로, Filtering했을때 중복되는 QuerySet에서 어떻게 중복을 제거해야하는가를 고민했다. 그에 대한 답은 바로 distinct() method였다.
Django에서
distinct()methods는 정렬이 된 QuerySet의 중복을 제거해준다.
구글링을 통해 이 방법을 찾고 바로 concepts Queryset에 distinct()를 써주니 중복이 제거 되어 내가 원했던 QuerySet이 반환되었다.

사실 distinct()를 쓰지 않고 filtering하는 과정에서 어떻게든 중복을 피할 수 있는 방법이 없을까 계속 찾아봤지만, 방법을 찾지 못했다..
Eliminate the Root Cause
distinct()같은 method를 쓰지 않고, 코드를 유지한 채로 해결할 수 있는 방법이 있다. 그것은 바로.. ERD를 수정하는 것이다..
위에서 확인한대로 item이 중간 테이블 역할을 수행하는데, 정규화가 제대로 되지 않아 concept와 category가 동일한 item이 다수 존재하게 된다. 따라서 concept와 category를 이어주는 중간테이블을 따로 생성하고, item이 이를 참조하게 하면 해결된다.
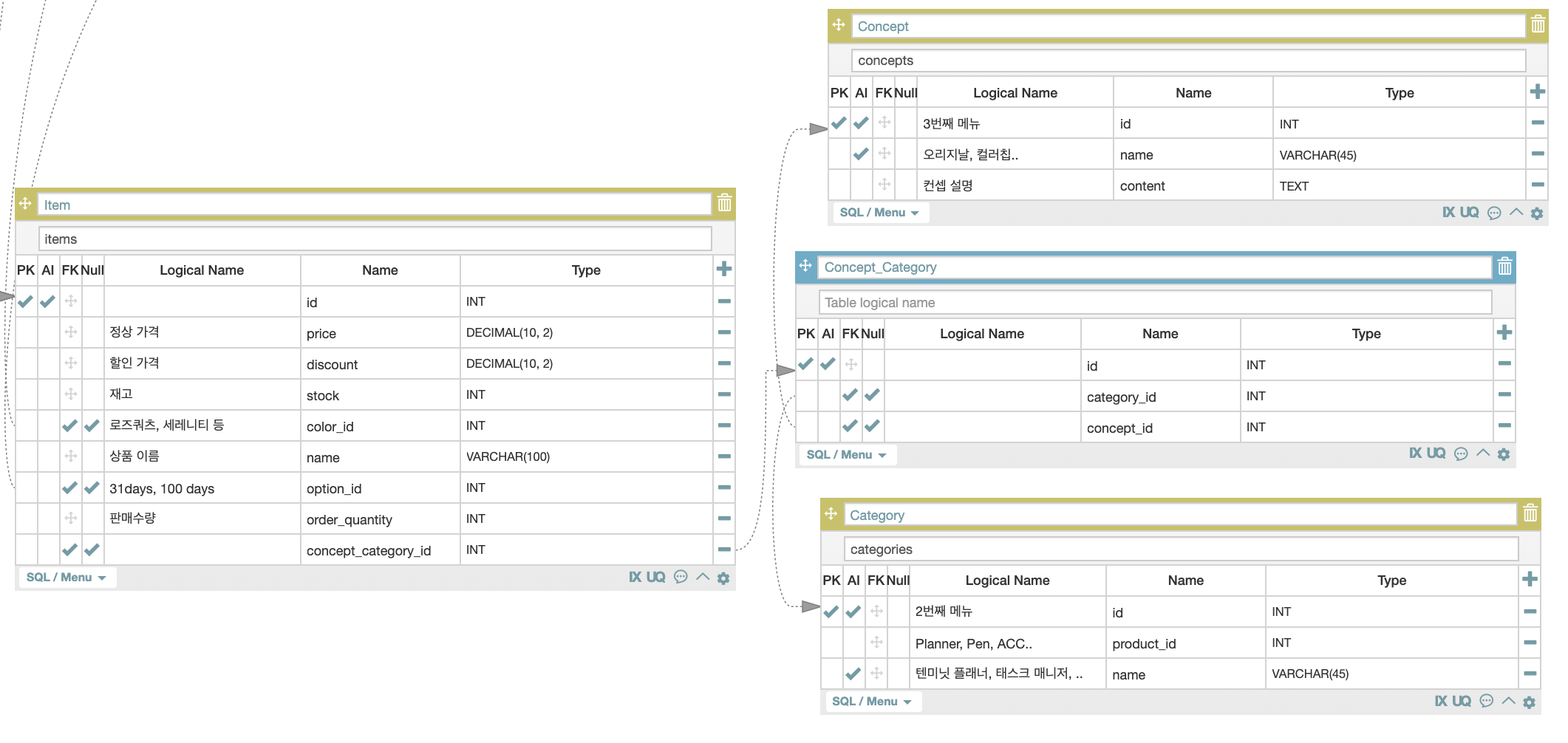
이렇게 연결하면 상품 데이터를 표출하는 페이지에서 category에 따라 concept을 필터링할 경우, item을 거칠 필요 없이 concept_category Table만 참조하면 된다.
concepts = Concept.objects.filter(concept_category__category_id = category_id)
<QuerySet [<Concept: Concept object (1)>, <Concept: Concept object (2)>, <Concept: Concept object (3)>, <Concept: Concept object (4)>]>이렇게 참조할 경우
select_related나 &prefetch_related를 사용하면 데이터베이스에 접근하는 빈도를 줄여 자원낭비를 줄일 수 있다는데, 아직 개념을 잘 이해하지 못해서 다음에 한번 사용해보면서 학습해야겠다.
TIL
이런 오류를 발견한것도 사실 POSTMAN으로 자체 통신을 하면서 우연치 않게 발견했던 것인데, 처음엔 이상하게 concept이 많이 나와서 매우 당황했다. 그리고 원인을 제대로 파악하지 못하고 우선 눈 앞의 문제인 중복을 제거하자고 생각하고 단순한 구글링만 했다.
그런데 근본원인이 무엇인지 곰곰히 생각하다 보니 Database Modeling의 결함을 알 수 있었다. 이제라도 알아서 다행이라고 생각하고, 앞으로도 Modeling을 진행할 때 꼼꼼히 확인하고 이와 같은 문제가 발생하지 않도록 해야겠다.
