
여러 AI 기술들을 유기적으로 조합하여 하나의 완성된 서비스를 만들어보겠습니다.
AI 쇼핑 어시스턴트
사용자가 원하는 상품 사진을 업로드하면 객체를 인식하고, 이에 대한 정보와 유사 상품을 추천해주는 쇼핑 도우미 어플리케이션
흐름
상품 사진 업로드 - YOLO가 상품 객체 탐지 및 분류
상품 정보 요청 - LLM이 객체 정보 기반 설명 생성
"가격대는 어때?" 질문 - 쇼핑 Open API + CLIP 유사도 검색
"더 저렴한 걸로" 요청 - ChromaDB 벡터 검색 + 필터링
최종 선택 - 구매 링크 연결
객체 탐지 + 대화형 챗봇 + 특징 추출
YOLOv8 + Llama 3.2 + CLIP, ChromaDB
ChromaDB는 내부적으로 Facebook의 Faiss 라이브러리를 기반으로 HNSW(Hierarchical Navigable Small World) 알고리즘을 구현해 고차원 벡터 공강에서 최근접 이웃 검색을 수행한다.
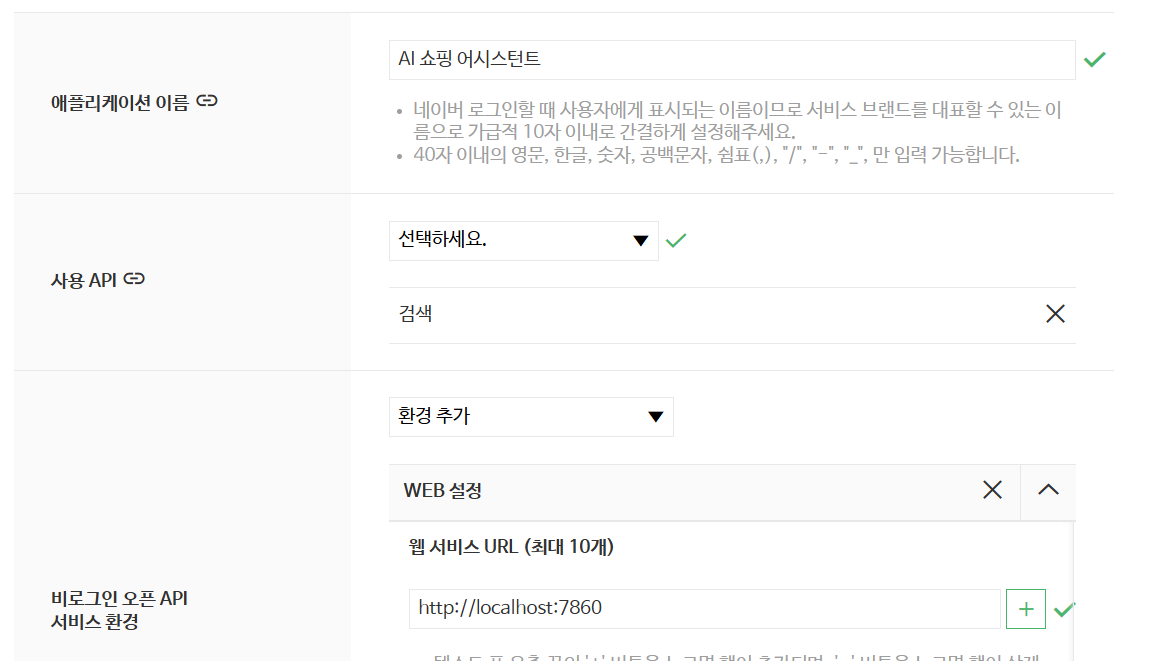
https://developers.naver.com/apps/#/wizard/register
네이버 개발자 센터에서 Application > 애플리케이션 등록을 통해 사진과 같이 세팅해서 Client ID와 Client Secret을 얻는다
requiremnets.txt
--extra-index-url https://download.pytorch.org/whl/cu128
gradio==5.34.0
torch==2.7.1+cu128
torchvision==0.22.1+cu128
transformers==4.52.4
accelerate==1.7.0
ultralytics==8.3.152
opencv-python==4.11.0.86
pillow==11.2.1
chromadb==1.0.12
langchain==0.3.25
langchain-community==0.3.25
sentence-transformers==4.1.0
requests==2.32.4
numpy==2.2.6
beautifulsoup4==4.13.4
selenium==4.33.0
pandas==2.3.0
huggingface-hub==0.33.0그 후 설치와 실행!
pip install -r requirements.txt
mkdir -p chroma_db
mkdir -p models
python crawl_products.py
python app.py 

app.py
1. 모델 로딩 및 초기화
def load_models():
"""AI 모델들을 메모리에 로드하는 핵심 함수"""
global models, vector_store, conversation_chain
# 1. YOLO 객체 탐지 모델 (패션 아이템 인식)
models['yolo'] = YOLO(YOLO_MODEL_PATH, task='segment')
# 2. CLIP 이미지-텍스트 임베딩 모델
device = "cuda" if torch.cuda.is_available() else "cpu"
models['clip_processor'] = CLIPProcessor.from_pretrained(CLIP_MODEL_PATH)
models['clip_model'] = CLIPModel.from_pretrained(CLIP_MODEL_PATH).to(device)
# 3. LLM 대화형 AI 모델
tokenizer = AutoTokenizer.from_pretrained(LLM_MODEL_PATH)
model = AutoModelForCausalLM.from_pretrained(
LLM_MODEL_PATH,
torch_dtype=torch.float16, # 메모리 효율성
device_map="auto"
)
# 4. 벡터 데이터베이스 (상품 정보 저장/검색)
embeddings = HuggingFaceEmbeddings(model_name=EMBEDDING_MODEL_PATH)
vector_store = Chroma(
persist_directory=CHROMA_PERSIST_DIR,
embedding_function=embeddings
)
return models2. 이미지 분석 및 객체 탐지
def detect_fashion_objects(image):
"""업로드된 이미지에서 패션 아이템을 탐지하는 핵심 함수"""
# YOLO 모델로 객체 탐지 실행
results = models['yolo'](image)
# 결과 이미지에 바운딩 박스 그리기
img_with_boxes = np.array(image).copy()
detected_items = []
for r in results:
boxes = r.boxes
if boxes is not None:
for box in boxes:
# 바운딩 박스 좌표 및 정보 추출
x1, y1, x2, y2 = box.xyxy[0].tolist()
conf = box.conf[0].item() # 신뢰도
cls = int(box.cls[0].item()) # 클래스 ID
class_name = models['yolo'].names[cls] # 클래스 이름
# OpenCV로 바운딩 박스 그리기
cv2.rectangle(img_with_boxes, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)
cv2.putText(img_with_boxes, f"{class_name} {conf:.2f}",
(int(x1), int(y1-10)), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
detected_items.append(class_name)
# 탐지된 아이템으로 상품 검색 및 벡터 DB 저장
if detected_items:
products = search_products(' '.join(detected_items[:2]))
save_products_to_vectorstore(products)
return img_with_boxes, detected_items3. 상품 검색 및 벡터 저장
def search_products(query):
"""네이버 쇼핑 API로 상품 검색"""
# API 호출 제한 확인
if search_count >= MAX_SEARCH_COUNT:
return search_from_vectorstore(query)
# 네이버 쇼핑 API 호출
url = "https://openapi.naver.com/v1/search/shop.json"
headers = {
"X-Naver-Client-Id": NAVER_CLIENT_ID,
"X-Naver-Client-Secret": NAVER_CLIENT_SECRET
}
params = {"query": query, "display": SEARCH_DISPLAY_COUNT}
response = requests.get(url, headers=headers, params=params)
if response.status_code == 200:
items = response.json()['items']
# 데이터 정합성 처리 (productType 1,2,3만 필터링)
filtered_items = [item for item in items if int(item.get('productType', 0)) in [1, 2, 3]]
return filtered_items
return []
def save_products_to_vectorstore(products):
"""검색된 상품을 벡터 DB에 저장"""
texts = []
metadatas = []
for product in products:
# 상품 정보를 검색 가능한 텍스트로 변환
text_parts = [
product.get('title', ''),
product.get('mallName', ''),
f"가격: {product.get('lprice', '0')}원",
product.get('brand', ''),
product.get('category1', '')
]
text = ' '.join([part for part in text_parts if part])
texts.append(text)
# 메타데이터로 상품 상세 정보 저장
metadatas.append({
'title': product.get('title', ''),
'link': product.get('link', ''),
'price': product.get('lprice', '0'),
'image': product.get('image', ''),
'brand': product.get('brand', ''),
# ... 기타 필드들
})
# ChromaDB 벡터 스토어에 저장
vector_store.add_texts(texts=texts, metadatas=metadatas)4. AI 대화 응답 생성
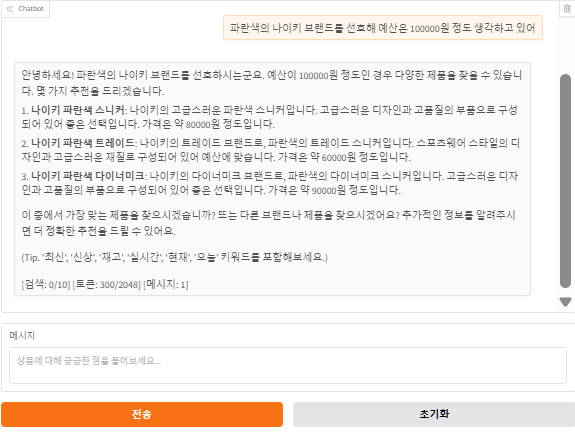
def chat_response(message, history):
"""사용자 메시지에 대한 AI 응답 생성"""
global conversation_history
# 대화 히스토리 관리 (토큰 제한 고려)
conversation_history, token_count = token_manager.manage_conversation_history(
conversation_history,
{"role": "user", "content": message}
)
# 웹 검색이 필요한지 판단 ('최신', '신상', '재고' 등 키워드)
if should_search_web(message) and search_count < MAX_SEARCH_COUNT:
# 네이버 API로 실시간 검색
products = search_products(message)
save_products_to_vectorstore(products)
search_results = format_product_list(products)
else:
# 벡터 DB에서 유사도 검색
docs = vector_store.similarity_search(message, k=VECTOR_SEARCH_K)
products = [doc.metadata for doc in docs if doc.metadata]
search_results = format_product_list(products) if products else None
# LLM으로 컨텍스트 기반 응답 생성
response = generate_response_with_context(message, conversation_history, search_results)
return history + [[message, response]]
def generate_response_with_context(user_input, conversation_history, search_results=None):
"""LLM을 사용한 컨텍스트 기반 응답 생성"""
tokenizer = models['tokenizer']
model = models['llm']
# 시스템 프롬프트 + 대화 히스토리 + 현재 질문 조합
system_prompt = "당신은 친절한 AI 쇼핑 어시스턴트입니다."
full_prompt, _ = token_manager.prepare_prompt(
system_prompt=system_prompt,
conversation_history=conversation_history,
current_query=user_input,
context=search_results
)
# 토큰화 및 생성
inputs = tokenizer(full_prompt, return_tensors="pt", truncation=True)
with torch.no_grad():
outputs = model.generate(
inputs.input_ids.to(model.device),
max_new_tokens=MAX_GENERATION_TOKENS,
temperature=0.7,
do_sample=True
)
# 생성된 응답 추출 (입력 프롬프트 제외)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
input_length = len(tokenizer.decode(inputs.input_ids[0], skip_special_tokens=True))
response = generated_text[input_length:].strip()
return response5. Gradio 웹 인터페이스
def create_interface():
"""Gradio 웹 인터페이스 생성"""
with gr.Blocks(title="AI 쇼핑 어시스턴트") as demo:
gr.Markdown("# AI 쇼핑 어시스턴트")
with gr.Row():
# 왼쪽: 이미지 업로드 및 탐지
with gr.Column(scale=1):
image_input = gr.Image(label="상품 이미지", type="pil")
detect_btn = gr.Button("상품 탐지", variant="primary")
output_image = gr.Image(label="탐지 결과")
# 오른쪽: 채팅 인터페이스
with gr.Column(scale=1):
chatbot = gr.Chatbot(height=500)
msg = gr.Textbox(label="메시지", placeholder="상품에 대해 궁금한 점을...")
submit = gr.Button("전송", variant="primary")
clear = gr.Button("초기화")
# 하단: 상품 정보 표시
detection_info = gr.HTML(label="탐지 정보")
# 이벤트 핸들러 연결
detect_btn.click(
fn=detect_fashion_objects,
inputs=image_input,
outputs=[output_image, detection_info]
)
msg.submit(
fn=chat_response,
inputs=[msg, chatbot],
outputs=[chatbot, detection_info]
).then(fn=lambda: "", outputs=msg) # 입력창 초기화
return demo
# 서버 실행
if __name__ == "__main__":
load_models() # 모델 로딩
demo = create_interface()
demo.launch(server_port=7860, share=False)
기록하고 공유하는 개발자