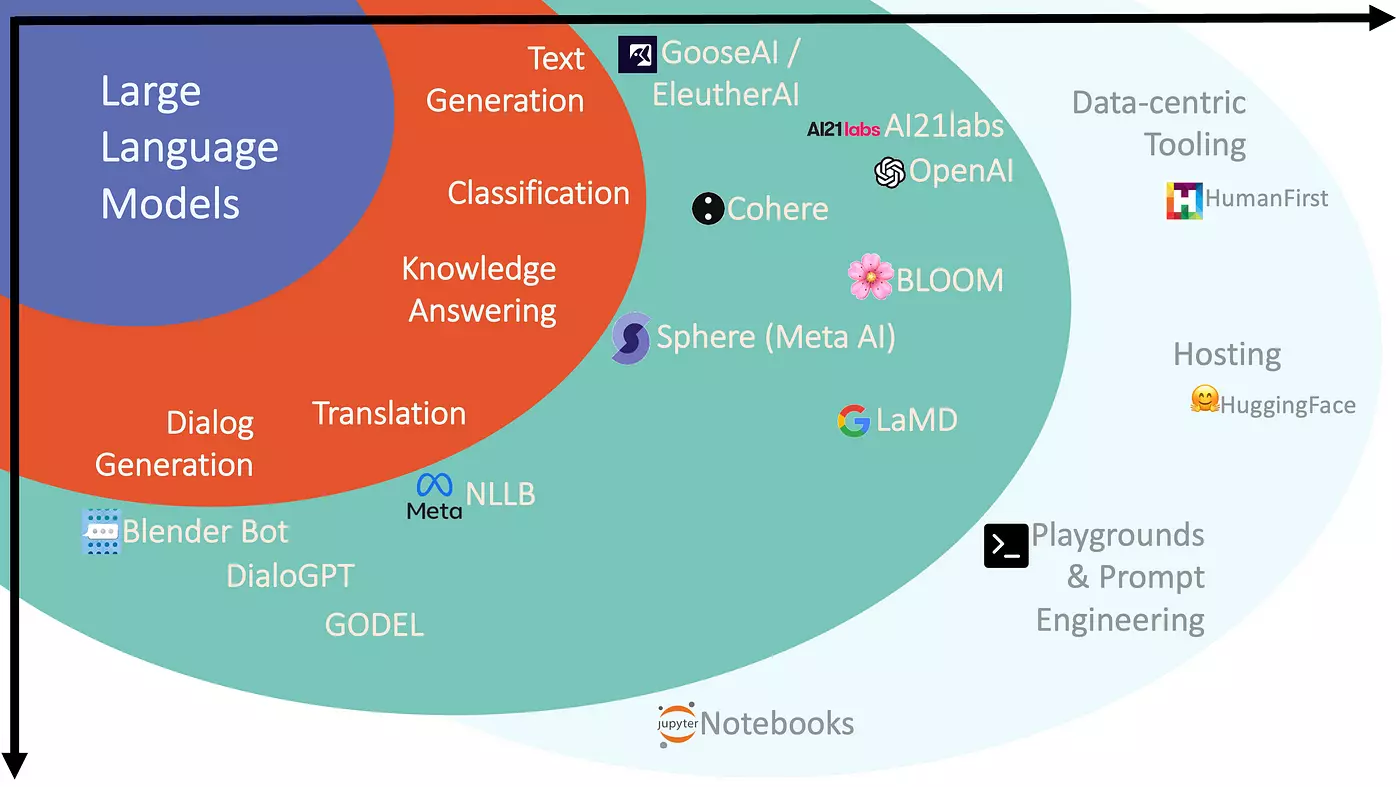
AI를 프로젝트에 적용하기 전 어떤 AI가 존재하고 우리의 도메인에 맞게 적용시킬 수 있을까 정리해보겠습니다.
개발 환경 설정
NVIDIA 그래픽 드라이버 설치 및 CUDA
NVIDIA 그래픽 드라이버를 설치한 후 CMD에서
nvidia-smi를 통해 CUDA 버전을 확인한다.
Python 개발 환경 설정
Miniforge3 설치
conda init // 자동 환경 변수 설정
conda create -n ai_env python=3.10 // ai_env라는 Python 3.10 버전 기반의 가상 환경 생성
conda activate ai_env // 가상환경 활성화
python // 버전 확인
exit() // 종료
conda deactivate // 비활성화
conda env remove -n ai_env // 가상 환경 삭제
conda env list // 가상 환경 목록 조회
딥러닝 프레임워크와 라이브러리 설치
PyTorch
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128 CUDA 12.8 용으로 빌드 된 PyTorch 2.7을 설치
그 후 AI 개발에 공통적으로 필요한 필수 라이브러리 설치
numpy 2.2.6
pandas 2.2.3
matplotlib 3.10.3
scikit-learn 1.6.1
py-opencv 4.11.0
transformers 4.51.3
datasets 3.6.0
ipykernel 6.29.5
밑 명령어로 설치
conda install numpy pandas matplotlib
conda install -c conda-forge opencv scikit-learn
pip install transformers datasets
pip install jupyter ipykernelTensorflow도 대중적이지만 최신 버전의 의존 패키지들과 호환되지 않는 경우가 있어 설치 생략
IDE 및 버전 관리
vscode
Extension : Python 과 Jupyter 설치
Ctrl + Shift + P 입력 후 Interpreter를 ai_env로 설정
git과 sourcetree는 개인 선택!
AI 모델 및 데이터셋 허브 플랫폼
Hugging Face Hub
사전학습 모델과 데이터셋의 저장소 역할 최신 딥러닝 모델을 쉽게 찾아 활용 가능
Kaggle
머신러닝 경진대회와 데이터셋, 노트북 공유로 유명
현재 세계 최대 규모의 데이터과학 커뮤니티
AI Hub (인공지능 허브)
우리말로 된 방대한 AI 학습용 데이터와 각종 AI 서비스 API, 컴퓨팅 자원 정보 등은 제공해서 국내 AI 개발을 지원하는 것이 목적
도메인 별 특화된 AI
컴퓨터 비전
기계가 이미지와 영상을 이해하고 분석하는 AI 기술 분야로, 사람의 시각 능력을 컴퓨터에 구현하는 기술
주로 이미지 분류, 객체 탐지, 얼굴 인식, 이미지 분할 등의 작업 수행 CNN (합성곱 신경망)이 핵심 기술로 활용된다.
1) 객체 탐지 (Object Detection)
이미지 내 객체들의 위치와 종류를 동시에 식별하는 컴퓨터 비전 기술
자율주행 자동차의 보행자 인식, 보안 시스템, 산업용 자동화 등에 활용
YOLO (You Only Look Once)
단일 신경망을 사용해 이미지(영상)를 한번에 분석하여 객체의 위치와 클래스를 동시에 예측하는 실시간 객체 탐지 기술
실시간 처리 속도와 쉬운 사용법
YOLO는 기본적으로 학습 시에 images/ 및 labels/ 폴더를 읽는다. (기존 데이터들로 학습)
학습 시간이 너무 오래 걸린다면 epochs(얼마나 반복)나 batch(한번 학습에 몇개의 이미지 셋)의 수를 줄일 수 있다.
모델의 성능을 개선하기 위해서는
학습 이미지 추가 수집, 백본 교체, 하이퍼파라미터 조정 (학습률, 옵티마이저 파라미터, 데이터 증강 강도, 앵커 튜닝) 로 성능을 개선할 수 있다.
2) OCR
이미지에서 텍스트를 인식하고 추출해서 기계가 읽을 수 있는 텍스트로 변환하는 기술 (텍스트 탐지 + 텍스트 인식)
대표적인 OCR : Easy OCR, TrOCR
성능 개선 포인트
데이터 전처리 및 증강, 학습 하이퍼 파라미터 최적화, 사전 학습 모델 교체, 후처리 강화
자연어 처리 (NLP)
인간의 언어를 컴퓨터가 이해하고 생성할 수 있도록 하는 분야
텍스트 분류, 감정 분석, 기계 번역, 요약, STT(Speech To Text), TTS(Text To Speech) 등 다양한 응용
(1) 감정 분석
KoBERT : 한국어 BERT 모델로 감정 분석에 파인튜닝하면 높은 성능
(2) 텍스트 요약
KoBART : 한국어 말뭉치로 사전학습한 한국어 전용 BART, 요약과 같은 새로운 문장을 생성하는 데 특화
성능 개선 방향
하이퍼 파라미터 조정, 사전 학습 모델 교체, 훈련 전략 변경 (LoRA 대신에 전체 모델을 학습 시도), 데이터 품질 확인
(3) STT
Whisper : 범용 음성인식 모델, 거대 멀티언어 데이터로 학습, Encoder-Decoder Transformer 구조이며 한국어에 대해서도 강인한 성능
(4) TTS
텍스트를 자연스러운 음성으로 변환하는 기술로 내비게이션, 스크린 리더, 콘텐츠 접근성 개선등에 활용
MMS-TTS : VITS 아키텍처를 기반으로 자연스럽고 고품질의 음성을 생성하며, 오픈소스로 제공되어 누구나 활용 가능
Coqui TTS + XTTSv2 : 최신 신경망 TTS 모델을 손쉽게 불러와 학습, 합성할 수 있는 오픈소스 Python 라이브러리로, 다양한 언어와 화자를 지원
3) 추천
사용자의 선호도와 행동 패턴을 분석하여 관련성 높은 상품, 콘텐츠, 서비스를 제안하는 AI 기술. 전자상거래, 스트리밍 서비스, 소셜 미디어 등 다양한 플랫폼에서 사용자 경험을 향상
(1) 협업 필터링
Surprise : SVD, KNN 기반 협업 필터링, 행렬 분해 등 다양한 알고리즘 제공하고 성능 평가 용이. 특히 메모리 효율성이 높다.
(2) 컨텐츠 기반 추천
scikit-learn, TF-IDF + 코사인 유사도 : TF-IDF는 텍스트 데이터에서 각 단어의 중요도를 수치화하는 기법 이를 통해 사용자가 좋아했던 아이템과 유사한 새로운 아이템을 추천한다.
4) 예측
(1) 시계열 예측
시간의 순서에 따라 수집된 연속적인 데이터로, 예를 들어 월별 판매량, 일별 기온, 연도별 인구수 등. 이렇게 과거 및 현재의 데이터 패턴을 기반으로 미래의 데이터 값을 예측하는 기술
ARIMA : 자기회귀 누적 이동 평균, 과거 데이터의 패턴이 강하게 이어지는 시계열에서 효과적
(2) 이상 탐지
정상 패턴에서 벗어나는 비정상적인 데이터 포인트를 식별하는 기술. 사기탐지, 네트워크 보안, 장비 고장 감지 등에 사용
Isolation Forest : 결정 트리 구조를 활용한 비지도 학습 기반 이상 탐지 알고리즘 , 무작위 분할을 통해 데이터를 분리하는 방식으로 작동한다.
5) LLM (대규모 언어 모델)
방대한 텍스트 데이터로 사전 학습된 초거대 AI 모델로 다양한 언어 작업 수행할 수 있다. (GPT, LLaMa, Claude, Gemini)
LLM을 활용할 때는 16GB의 VRAM이 권장된다.
(1) 질의 응답
Llama 3.2 : GPT와 유사한 성능을 제공하면서도 상업적 이용이 가능하고, 다양한 크기의 모델을 제공해서 사용자의 하드웨어 환경에 맞게 선택할 수 있다.
RAG (검색 증강 생성) : 외부 문서를 검색하여 생성 모델에 추가 정보를 제공하여 더 정확하고 사실에 기반한 응답을 생성해주는 기법
(2) 도메인 특화 챗봇
ex) 의료 분야 데이터로 Fine-Tuning 한 Hugging Face 공개 모델을 활용, AIHub의 민사법 LLM 사전 학습 및 Instruction Tuning 데이터 학습
6) 생성형 AI
새로운 콘텐츠를 창작할 수 있는 인공지는 기술, 주로 GAN, VAE, 확산 모델 등의 생성 방법론을 기반으로 한다.
(1) 이미지 생성
Stable Diffusion : 확산 과정을 통해 노이즈에서 점진적으로 이미지를 생성, LAION-5B 데이터셋으로 훈련됨
(2) 비디오 생성
Stable Video Diffusion : 텍스트에 따라 짧은 영상 클립 생성
(3) 음악 생성
MusicGen : 텍스트에 따라 다양한 장르와 스타일의 음악 생성
(4) 3D 그래픽 생성
Point-E : 텍스트 설명을 입력하면 먼저 2D 이미지를 생성한 후 이를 3D 포인트 클라우드로 변환하는 2단계 접근 방식을 사용, 기존 3D 모델링 방법보다 훨씬 적은 컴퓨팅 자원으로 빠르게 3D 객체를 생성할 수 있어 효율적이다.



AI 마스터시군요