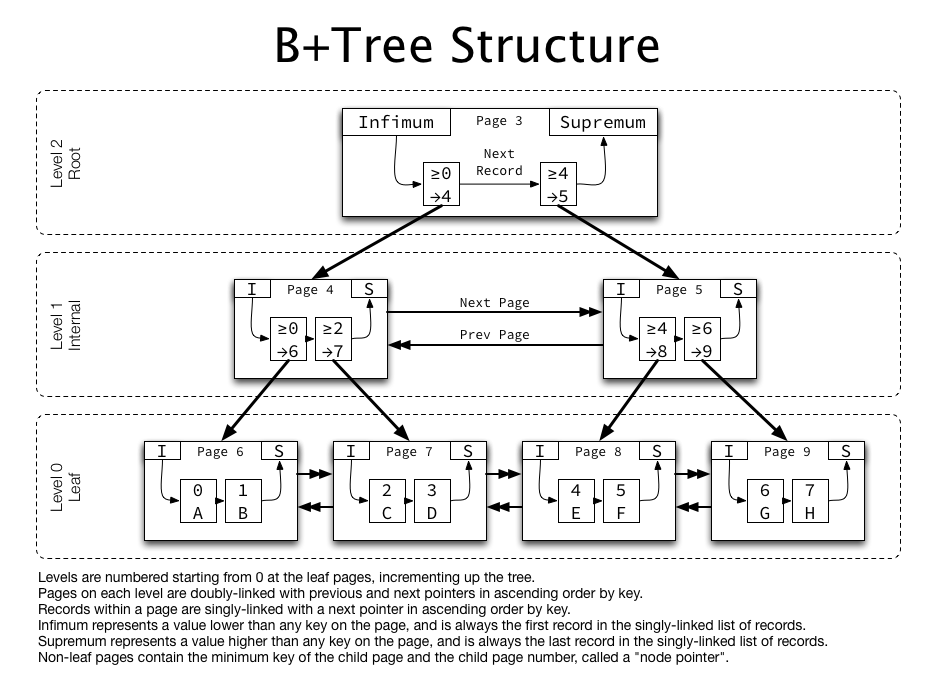
Index가 무엇인가요?
"Index는 데이터베이스에서 특정 컬럼의 값을 기준으로 데이터를 빠르게 검색하기 위한 자료구조입니다. 책의 목차처럼 원본 테이블과 별도로 관리되며, 컬럼 값과 해당 레코드의 물리적 위치 정보를 정렬된 형태로 저장합니다.
대부분의 RDBMS에서는 B+Tree 구조를 사용하는데, 이는 균형 잡힌 트리 구조로 탐색, 삽입, 삭제 연산이 모두 O(log N)의 시간복잡도를 가지기 때문입니다. Index를 통해 Full Table Scan 없이 필요한 데이터에 직접 접근할 수 있어 조회 성능을 크게 향상시킬 수 있습니다."
이것이 내가 생각한 완벽한 답안이고 이걸 하나씩 풀어보겠다.
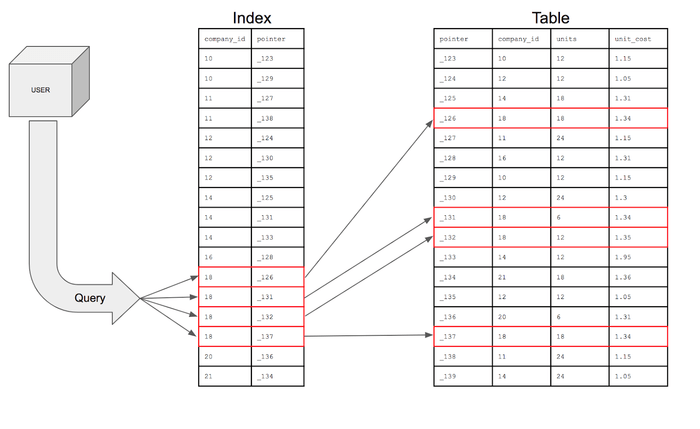
특정 컬럼의 값을 기준 : 그림에서 company_id 값을 정렬하고 그 위치인 pointer 에 맞춰서 company_id, pointer를 가지고 있는 Index가 생성된다.
RDBMS 에서는 B+Tree 구조 : 정렬된 데이터를 이분탐색 형태로 조회하기 때문에 O(log N)의 시간복잡도를 통해서 조회할 수 있다.
복합인덱스는 무엇인가요?
저 사진은 company_id가 18인 레코드를 찾아주세요 였다면
만약 SELECT * FROM TABLE WHERE company_id = 18 AND units = 18 이라면 어떨까?
CREATE INDEX(company_id, units) 를 통해서 복합인덱스를 생성해준다.

이렇게 생성이 되고 company_id 를 우선적으로 정렬 그리고 18이 같은 경우 units를 정렬하여 생성이 된다. 그렇게 company_id 와 units를 빠르게 찾아서 값을 반환할 수 있다.
정리하자면
"복합 인덱스는 여러 컬럼을 하나의 인덱스로 묶어서 생성하는 것으로, 지정한 컬럼 순서대로 정렬된 B+Tree 구조를 만듭니다. 첫 번째 컬럼을 기준으로 먼저 정렬하고, 같은 값 내에서 두 번째 컬럼으로 정렬하는 방식입니다.
예를 들어 WHERE 절에서 여러 컬럼을 함께 조회하는 패턴이 많을 때 유용하며, 특히 인덱스 구성 순서가 쿼리 조건의 순서와 일치할 때 최대 효율을 발휘합니다.
다만 복합 인덱스는 최좌측 컬럼부터 순차적으로 사용되기 때문에, 컬럼 순서가 매우 중요합니다. 첫 번째 컬럼 조건 없이 두 번째 컬럼만으로 조회하면 인덱스를 활용할 수 없습니다. 따라서 카디널리티가 높고 자주 조회되는 컬럼을 앞쪽에 배치하는 것이 일반적입니다."
카디널리티란 무엇이고 인덱스와 어떻게 관련이 있나요?
"카디널리티는 특정 컬럼에서 중복을 제외한 고유한 값의 개수를 의미합니다. 카디널리티가 높다는 것은 고유한 값이 많아 중복이 적다는 뜻이고, 카디널리티가 낮다는 것은 같은 값이 반복되어 중복이 많다는 의미입니다.
인덱스는 데이터를 빠르게 필터링하기 위한 목적으로 사용되는데, 카디널리티가 높을수록 인덱스를 통해 걸러지는 데이터 범위가 좁아져서 효율이 높아집니다. 반대로 카디널리티가 낮으면 하나의 인덱스 값이 많은 레코드를 가리키게 되어, 결국 많은 데이터를 스캔해야 하므로 인덱스 효과가 떨어집니다.
다만 카디널리티가 낮더라도 데이터 분포가 편향되어 있거나 특정 값만 자주 조회된다면, 부분 인덱스나 필터링된 인덱스로 효율을 높일 수 있습니다."
클러스터 인덱스와 논클러스터 인덱스의 차이는 뭔가요?
"Clustered Index는 테이블 데이터 자체가 인덱스 키 순서대로 물리적으로 정렬되어 저장되는 방식입니다. InnoDB에서는 Primary Key를 Clustered Index로 사용하며, PK가 없으면 Unique Key를, 그것도 없으면 내부적으로 생성한 Row ID를 사용합니다. 테이블당 하나만 존재할 수 있고, Leaf Node에 실제 데이터 전체가 저장되어 있어서 한 번의 접근으로 데이터를 가져올 수 있습니다.
Non-Clustered Index는 실제 데이터와 별도로 존재하는 인덱스로, Secondary Index라고도 부릅니다. 책의 색인처럼 인덱스 컬럼 값과 함께 해당 데이터의 Primary Key 값을 저장합니다. InnoDB의 경우 Non-Clustered Index로 조회하면 먼저 Secondary Index에서 PK를 찾고, 그 PK로 다시 Clustered Index에 접근해서 실제 데이터를 가져오는 2단계 과정을 거칩니다. 테이블당 여러 개 생성할 수 있습니다."
결론: Index 설계 원칙
데이터베이스 성능 최적화에서 Index는 핵심적인 역할을 합니다. 효과적인 Index 설계를 위해서는 다음 원칙들을 고려해야 합니다.
1. 쿼리 패턴 분석이 우선
Index는 조회 성능을 위한 것이므로, 실제로 자주 실행되는 쿼리의 WHERE, JOIN, ORDER BY 절을 분석하여 필요한 컬럼을 파악해야 합니다.
2. 카디널리티를 고려한 선택
고유값이 많은 컬럼(높은 카디널리티)에 Index를 생성해야 필터링 효과가 좋습니다. 성별이나 Boolean 같이 값의 종류가 적은 컬럼은 Index 효과가 미미합니다.
3. 복합인덱스는 순서가 중요
복합인덱스는 최좌측 컬럼부터 순차적으로 사용됩니다. 따라서:
- 카디널리티가 높은 컬럼을 앞에 배치
- 등호(=) 조건을 범위 조건보다 앞에 배치
- 가장 자주 조회되는 컬럼을 앞에 배치
4. Trade-off를 이해하고 균형잡기
Index는 조회 성능을 향상시키지만:
- 추가 저장 공간 필요
- 쓰기 성능(INSERT, UPDATE, DELETE) 저하
- Index가 많을수록 옵티마이저의 선택지가 많아져 오히려 잘못된 Index 선택 가능
따라서 꼭 필요한 Index만 생성하고, 사용되지 않는 Index는 주기적으로 제거해야 합니다.
5. MySQL InnoDB의 특성 활용
- PK는 Clustered Index로 동작하므로 PK 크기를 작게 유지 (BIGINT 권장)
- Secondary Index는 PK를 참조하므로 PK가 작을수록 모든 Index 크기 감소
- Covering Index를 활용하면 테이블 접근 없이 Index만으로 조회 가능
6. 실행 계획으로 검증
EXPLAIN SELECT * FROM table WHERE column = value;EXPLAIN으로 실제 Index가 잘 동작하는지 확인하고, type이 const, ref, range인지 체크해야 합니다. ALL(Full Table Scan)이 나오면 Index가 제대로 동작하지 않는 것입니다.
