
강화 학습
-
강화 학습이란?
- "순차적 의사결정 문제 에서 누적 보상을 최대화 하기 위해 시행착오를 통해 행동을 교정하는 학습 과정"
- 쉽게 말해, "시행착오를 통해 발전해 나가는 과정"
-
강화 학습의 간단한 예시
- 스스로 시행착오를 통해 자전거 타는 법을 학습하는 아이
순차적 의사결정 문제
- 강화 학습이 풀고자 하는 문제는 바로 순차적 의사결정 문제입니다.
순차적 의사결정의 예시 - 샤워하는 남자
- 우리는 샤워를 할 때 대략적으로 다음과 같은 4단계를 거칩니다.
- 옷을 벗는다.
- 샤워를 한다.
- 물기를 닦는다.
- 옷을 입는다.
- 그리고 이 4단계는 반드시 순서에 맞게 이루어져야 합니다. 만일 순서가 뒤바뀌면 어떻게 될까요?
④ 옷을 입고, ② 샤워를 하고, ③ 물기를 닦고, ① 옷을 벗는다
-> 벌거 벗은 채로 끝나겠네요.
③ 물기를 닦고, ② 샤워를 하고, ① 옷을 벗고, ④ 옷을 입는다.
-> 물기는 왜 닦는걸까요?
-
이처럼 아무리 간단한 과정이라 하더라도 이를 성공적으로 마치기 위해서 우리는 몇 가지 의사결정을 순차적으로 해 주어야 합니다.
-
각 상황에 따라 하는 행동이 다음 상황에 영향을 주며, 결국 연이은 행동을 잘 선택해야 하는 문제가 바로 순차적 의사결정 문제입니다.
보상
-
의사결정을 얼마나 잘하고 있는지 알려주는 신호
-
강화 학습의 목적은 과정에서 받는 보상의 총합, 즉 누적 보상 을 최대화하는 것입니다.
보상의 특징 - 어떻게 X 얼마나 O
-
보상은 "어떻게"에 대한 정보를 담고 있지 않고, 어떠한 행동을 하면 그것에 대해 "얼마나" 잘 하고 있는지 평가해 줍니다.
-
그렇다면 "어떻게"에 대한 정보를 아무도 알려주지 않는데 어떻게 학습을 할 수 있는 것일까요?
- 그것은 바로 수많은 시행착오 덕분입니다.
-
에이전트가 자신의 행동을 교정할 수 있는 이유는 에이전트가 잘 했을때는 잘했다 하고, 못 했을 때는 못 했다고 평가해 주는 신호가 있기 때문입니다.
- 그것이 바로 보상입니다.
-
보상이 어떻게 해야 할지를 직접적으로 알려주지는 않지만, 사후적으로 보상이 낮았던 행동들은 덜 하고, 보상이 높았던 행동들은 더 하면서 보상을 최대화하도록 행동을 조금씩 수정해 나갑니다.
보상의 특징 - 스칼라
-
보상은 스칼라 입니다.
- 스칼라는 벡터 와 달리 크기를 나타내는 값 하나로 이루어져 있습니다.
-> 따라서 오직 하나의 목표만을 가져야 합니다.
- 스칼라는 벡터 와 달리 크기를 나타내는 값 하나로 이루어져 있습니다.
-
그렇다면 다수의 목표들을 어떻게 하나의 스칼라로 표현할 수 있을까요?
- 여러 방법이 있겠지만 그 중 하나는 바로 가중치를 두는 방법입니다.
-
대학교 신입생을 예로 들어보겠습니다. 이들은 학점, 동아리 활동, 연애 등 여러 목표를 가질 수 있습니다. 각각을 x, y, z로 표현하고 이들의 가중치를 각각 50%, 25%, 25% 라고 합시다.
-
이렇게 되면 3개의 목표를 0.5x + 0.25y + 0.25z 라는 하나의 숫자, 즉 스칼라로 표현할 수 있습니다.
-
강화 학습은 스칼라 형태의 보상이 있는 경우에만 적용할 수 있습니다. 만일 어떤 문제는 도저히 하나의 목표만을 설정하기 어렵다면 그 문제에 강화 학습을 적용하는 것은 적절하지 못할 수 있습니다. 다만 잘 정해진 하나의 숫자로 된 목표가 있다면, 강화 학습은 불도저처럼 해당 목표를 최대로 취하도록 최적화할 것입니다.
보상의 특징 - 희소하고 지연된 보상
-
보상은 희소 할 수 있으며 또 지연 될 수 있습니다.
-
행동과 보상이 일대일로 대응이 된다면 강화 학습은 한결 쉬워집니다.
- 행동에 대한 평가가 즉각적으로 이루어지는 만큼 좋은 행동과 안 좋은 행동을 가려내기 쉽기 때문입니다.
-
하지만 보상은 선택했던 행동의 빈도에 비해 훨씬 가끔 주어지거나, 행동이 발생한 후 한참 뒤에 나올 수 있고 이 때문에 행동과 보상의 연결이 어려워집니다.
-
만일 행동을 10번 해야 보상이 1번 나타나거나, 행동을 10번 하고 나서야 과거 처음 한 행동의 보상이 주어진다면 이 보상이 어떤 행동 덕분인지 책임 소재가 불분명해지면서 그만큼 학습도 어려워집니다.
- 강화 학습에서 다루는 문제는 순차적 의사결정 문제이기 때문에 순차성, 즉 시간에 따른 흐름이 중요하고 이 흐름에서 보상이 뒤늦게 주어지는 것이 가능합니다.
에이전트와 환경
- 앞서 설명한 순차적 의사결정 문제를 도식화하면 다음 그림과 같습니다.
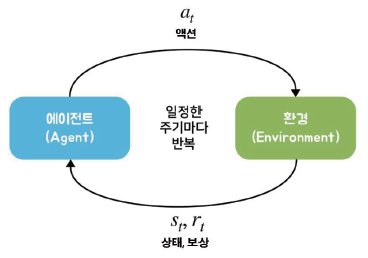
- 에이전트가 액션 을 하고 그에따라 상황이 변하는 것을 하나의 루프 라 했을 때 이 루프가 끈임없이 반복되는 것을 순차적 의사결정 문제라 할 수 있습니다.
에이전트
-
강화 학습의 주인공이자 주체, 학습하는 대상이며 동시에 환경 속에서 행동하는 개체
-
에이전트의 입장에서 위의 루프는 구체적으로 3개의 단계로 이루어져 있습니다.
- 현재 상황 st 에서 어떤 액션을 해야 할지 at 를 결정
- 결정된 행동 at 를 환경으로 보냄
- 환경으로부터 그에 따른 보상과 다음 상태의 정보를 받음
환경
-
에이전트를 제외한 모든 요소
-
에이전트가 어떤 행동을 했을 때, 그 결과에 영향을 아주 조금이라도 미치는 모든 요소들이 환경이라고 할 수 있습니다.
-
현재 상태에 대한 모든 정보를 숫자로 표현하여 기록해 놓은 것을 상태 라고 하는데, 환경은 상태 변화 를 일으키는 역할을 담당합니다.
- 즉, 행동의 결과를 알려주는 것입니다.
-
환경이 하는 일은 다음과 같은 단계로 이루어집니다.
- 에이전트로부터 받은 액션 at 를 통해서 상태 변화를 일으킴
- 그 결과 상태는 st -> s(t+1) 로 바뀜
- 에이전트에게 줄 보상 r(t+1) 도 함께 계산
- s(t+1) 과 r(t+1) 을 에이전트에게 전달
-
이처럼 에이전트가 st 에서 at 를 시행하고, 이를 통해 환경이 s(t+1) 로 바뀌면, 즉 에이전트와 환경이 한 번 상호 작용하면 하나의 루프가 끝납니다.
- 이를 한 틱 이 지났다고 표현합니다.
-
실제 세계는 앞의 그림과 다르게 시간의 흐름이 연속적(continous) 이겠지만 순차적 의사결정 문제에서는 시간의 흐름을 이산적(discrete) 으로 생각합니다.
- 이산적이란, 뚝뚝 끊어져서 변화가 발생한다는 뜻입니다.
-
그리고 그 시간의 단위를 틱 혹은 타임 스텝 이라고 합니다.
강화 학습의 위력
병렬성의 힘
-
인서가 자전거를 배우는 것을 예로 들어 보겠습니다. 여기서 학습시간 (인서 혼자서 수많은 시행착오를 겪으며 배우는 것)이 대략 5시간 정도의 시간이 걸린다고 가정해보겠습니다.
-
하지만 만약 100명의 인서가 시행착오를 겪으며 자전거를 배우고, 모든 시행착오를 서로 공유할 수 있다면 학습시간은 어떻게 될까요?
- 분명히 혼자 하는 것보다는 훨씬 빠르게 학습이 가능할 것입니다.
- 몇 명의 인서가 정보를 공유하냐에 따라 5시간이라는 시간이 5분으로 줄어들 수도 있습니다.
- 이것이 바로 강화 학습이 가지고 있는 병렬성의 힘입니다.
-
에이전트 하나로는 굉장히 오래 걸리는 학습시간을 병렬성의 힘으로 최대한으로 단축시키며 동일한 학습결과를 얻을 수 있습니다.
자가 학습 (self-learning)의 매력
-
알파고를 예시로 들어보겠습니다.
-
알파고는 학습 초기에 프로 바둑 기사들의 기보를 통해 지도 학습을 진행하였습니다.
- 즉, 사람이 두었던 수를 정답으로 입력받아 그것을 잘 따라 하도록 학습했습니다.
-
하지만 그렇게만 학습했다면 사람을 이길 리는 만무했을 것입니다. 사람을 뛰어넘는 것이 가능했던 이유는 자가 학습에 기반을 둔 강화 학습 덕분입니다.
-
승리라는 목표만 알려줬을 뿐 그 과정은 알아서 찾도록 했기 때문에 충분한 계산 능력 과 어우러져 사람이 생각해낼 수 없는 수를 찾아냈던 것이죠.
-
사람이 알려준 지식을 잘 따라하는 데에 그쳤다면 그것을 위대한 지능이라 부를 수 없었을 것입니다.
Reference
- 노승은(2020), 바닥부터 배우는 강화 학습
