카프카 파티션으로 enqueue되는 데이터를 레코드라고 하는데,
이 레코드는 다음과 같은 특성이 있다.
1. 브로커에 저장되면서 결정되는 값, 프로듀서가 직접 설정하는 값으로 나뉜다.
2. 브로커에 저장되고 나서는 값의 수정이 불가능하다.
3. 로그 리텐션 기간, 용량에 따라서 삭제된다. (브로커가 삭제한다.)
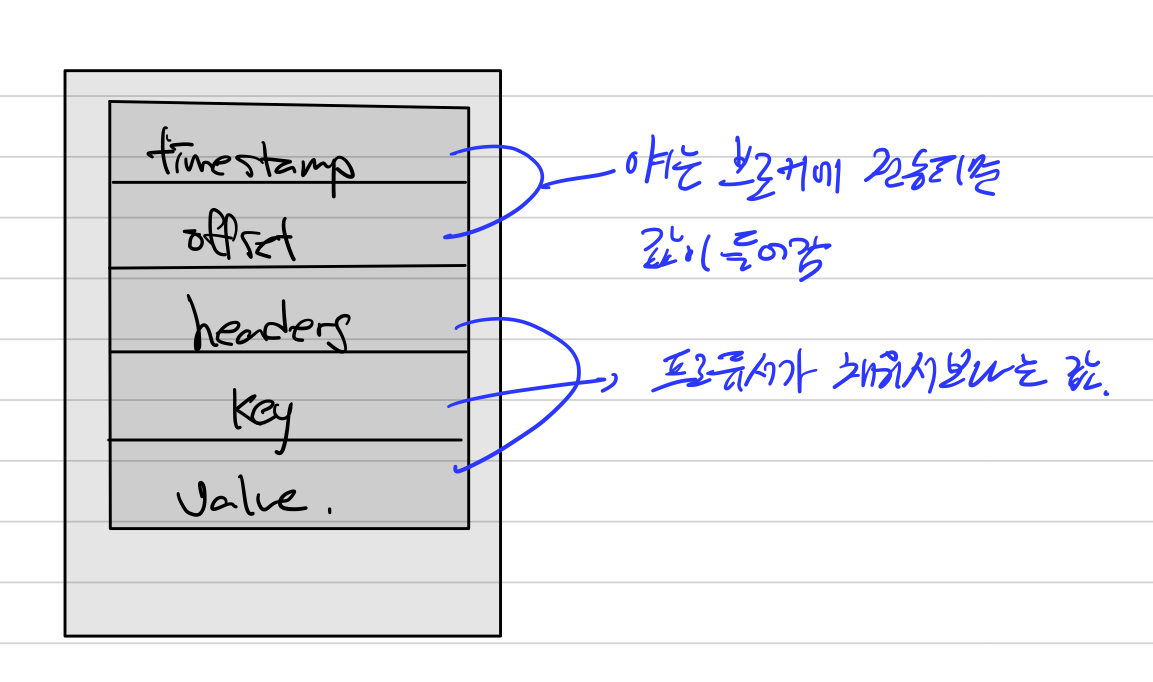
카프카의 레코드는 5개로 나뉜다.
1. timestamp
2. offset
3. headers
4. key
5. value
timestamp와 offset은 브로커에 저장될때 값이 정해진다.
timestamp의 경우 저장할지 말지를 옵션에 따라 줄 수 있다.
timestamp
레코드의 timestamp는 스트링 프로세싱에서 활용하기 위한 시간을 저장한다.
unix timestamp가 사용된다.
프로듀서가 별도로 설정하지 않으면, 기본값으로 Producer Record의 create time이 들어간다.
설정에 따라서 logAppendTime(브로커 적재시간)으로 설정할 수도 있다.
뭐 둘은 네트워크 시간정도의 차이가 있을 수 있겠다.
이 옵션은 토픽단위로 설정이 가능하다.
message.timestamp.type을 사용한다.
offset
프로듀서가 생성한 레코드에는 존재하지 않는다. 프로듀서가 파티션의 상황을 알수는 없으니,,,
브로커에 적재되면서 offset이 매겨진다.
offset은 0부터 시작해서 1씩 증가한다.
이 offset을 기준으로 처리해야할 데이터와 처리한 데이터를 나눌수있다.
컨슈머 커밋의 기준값으로 사용된다.
각 메시지는 파티션별로 고유한 offset을 갖고 컨슈머에서 중복처리를 방지하는데 사용된다.
header
key-value를 저장할 수 있다.
레코드의 스키마 정보나, 포멧과 같이 메타데이터를 저장하는 용도이다.
message key
처리하고자 하는 메시지의 값을 분류하기 위해서 사용된다.
이걸 파티셔닝이라고 한다.
파티셔너가 이 키값을 보고 해당 메시지가 어느 파티션으로 들어갈지 결정한다.
설정하지 않으면 null로 설정되고 이런 경우에는 라운드로빈으로 들어갈 파티션이 결정된다.
균등하게 들어간다고 보면 된다.
null이 아니면 hash값에 따라서 특정 파티션에 매핑되서 들어간다.
핵심은 같은 key이면 같은 파티션에 들어간다.
message value
실질적으로 처리하는 데이터가 들어가는 곳이다.
Float, byte[], String, 등 다양한 포멧으로 저장가능하고 사용자 지정 클래스로 직렬화/역직렬화가 가능하다.
컨슈머는 이러한 포멧을 모르기 때문에 컨슈머는 역직렬화 포멧을 미리 알고 있어야 한다.
