토픽과 파티션
- 토픽 : 카프카에서 데이터를 구분하기 위해서 사용되는 단위. 하나의 토픽에는 적어도 한개의 파티션이 있다.
- 파티션 : 토픽이 갖고 있는 큐들을 의미한다. 파티션에는 프로듀서가 보낸 데이터(로그, 메시지, 레코드)들이 저장된다. 일반적인 큐와 다른 점은 읽는다고 dequeue는 하지 않고 offset commit을 통해서 어디까지 읽었는지를 표시한다. 이 특징때문에 여러 컨슈머 그룹이 토픽의 데이터를 여러번 가져갈 수 있다.
- 레코드 : key-value. 이게 파티션으로 들어가면 offset이 붙는다.
토픽 생성시 파티션이 배치되는 방법
라운드 로빈
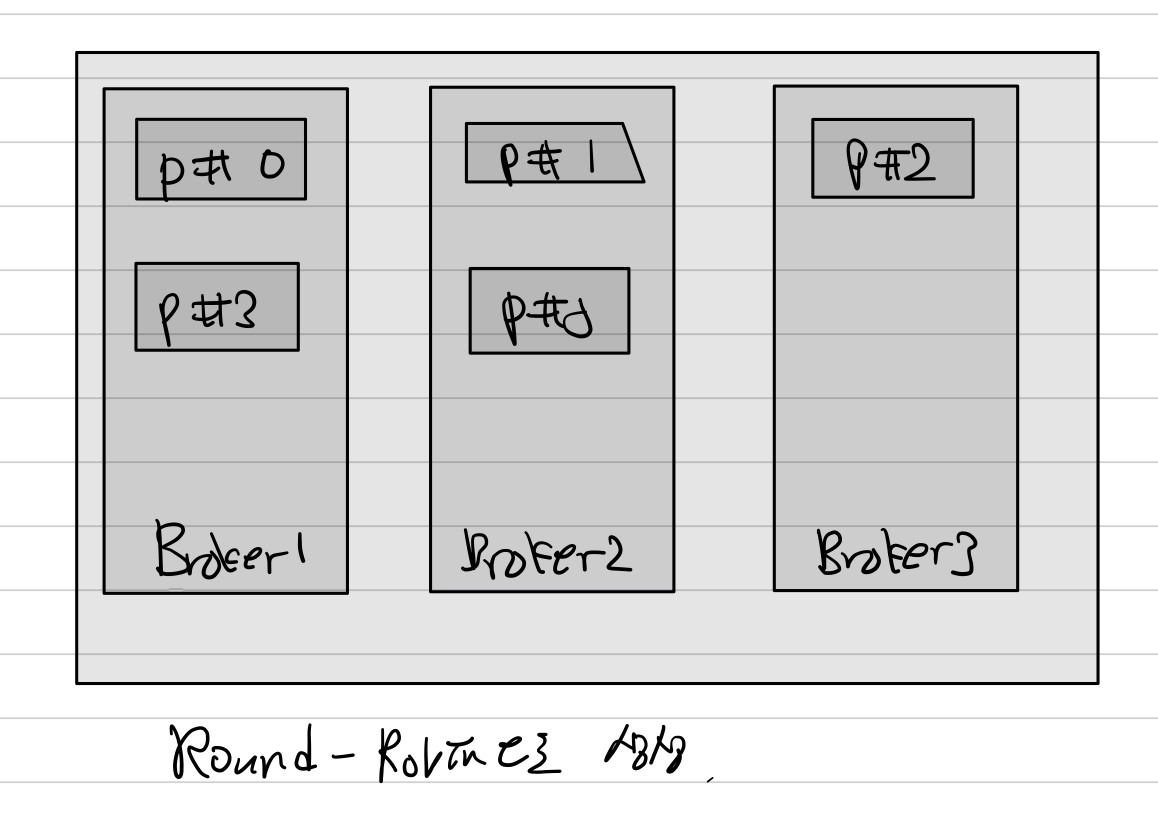
클러스터에는 브로커가 3대, 토픽에는 5개의 파티션이 존재한다.
이런 설정이면 0,1,2,3,4 순으로 파티션이 생성된다.
이렇게 라운드로빈으로 파티션이 생성되면 하나의 브로커에 파티션이 몰리는 hot-spot현상을 방지할 수 있다.
특정 브로커에 파티션이 몰리는 경우에는 kafka-reassign-partitions.sh를 실행해서 파티션을 재분배할 수 있다.
파티션 갯수와 컨슈머 갯수
기본적으로 파티션과 컨슈머는 1:1이다.
하나의 파티션에서 여러 컨슈머가 데이터를 읽을 수는 없다.
데이터 순서 보장이 되지 않기 때문이다.
전체적인 병렬 처리량을 늘리려면 파티션 갯수, 컨슈머 갯수를 늘리면 된다.
하나의 컨슈머에서 장애가 발생한다면, 코디네이터는 헬스체크에서 실패한 컨슈머가 담당하고 있던 파티션을 다른 컨슈머가 할당되도록 한다.
데이터와 트래픽을 고려해서 적절하게 파티션 수와 컨슈머 수를 늘리면 된다.
파티션 갯수를 줄이는것은 불가능
카프카에서 파티션 갯수를 줄이는 것은 불가능하다.
그래서 파티션의 갯수를 늘릴때에는 신중해야 한다.

개발하는 개복치