브로커
카프카 브로커란
- 데이터를 보관하는 중간 프로세서이다.
- 하나의 물리 장비, 서버, 인스턴스에서 동작된다. k8s환경이라면 인스턴스
- 프로듀서가 브로커로 데이터를 보내고, 컨슈머가 데이터를 브로커에서 읽는다.
- 파일시스템 기반으로 데이터를 저장하기때문에 장애가 발생해도 데이터가 유실되지 않는다.
- 거의 대부분의 경우 하나의 클러스터에 3대 이상의 브로커를 사용한다. 클러스터는 브로커가 여러대 묶여서 운영된다.
- 브로커 끼리는 데이터가 복제되서 저장된다. 따라서 하나의 브로커에 장애가 발생해도 다른 브로커에는 데이터가 저장되있기 때문에 다른 브로커에서 데이터를 가져다 읽으면 된다.
- 브로커 한대로도 기본기능은 다 제공된다고 보면 된다.
브로커의 역할
컨트롤러
하나의 카프카 클러스터를 3대의 브로커로 구성한다고 가정하면,
1대의 브로커는 컨트롤러 브로커로 선정된다.
이 한대의 컨트롤러가 나머지 브로커의 상태를 체크한다.
컨트롤러가 이렇게 브로커의 상태를 체크하는것을 헬스체크라고 한다.
2번 브로커가 헬스체크에 실패했다면, 0번 컨트롤러는 해당 브로커가 가진 리더파티션을 살아있는 0,1으로 분배한다.
컨트롤러가 장애가 난다면, 다른 브로커가 컨트롤러의 역할을 맡는다.
각 브로커는 토픽/파티션/메시지를 모두 공유한다.
데이터 삭제
컨슈머가 데이터를 읽어도 데이터는 삭제되지 않는다.
어디까지 읽었는지를 표현하는 수치인 컨슈머 오프셋이 변경될 뿐이다.
컨슈머나 프로듀서는 데이터 삭제를 요청할 수 없다.
오직 브로커만이 데이터 삭제가 가능하다.
데이터 삭제는 파일 단위로 이뤄지는데 이 파일 단위를 로그 세그먼트라고 한다.
브로커 delete 설정에 따라서 시간이나 용량별로 데이터를 자동삭제하게끔 설정 가능하다.
컨슈머 오프셋 저장
컨슈머 그룹은 특정 파티션에서 데이터를 가져가고 어디까지 읽었음을 표시하기 위해서 consumer_offset이라는 토픽에 커밋을 한다.
이 consumer_offset이라는 토픽은 자동 생성되는 토픽이다.
여기에 저장된 오프셋을 토대로 컨슈머 그룹은 다음 레코드를 가져가서 처리한다.
그룹 코디네이터
코디네이터는 컨슈머 그룹의 상태를 체크하고 파티션을 컨슈머와 매칭되도록 분배하는 역할을 말한다.
예를 들어서 하나의 컨슈머가 컨슈머 그룹에서 제외되는 경우가 있다.
이런 경우 코디네이터는 리밸런싱을 발생시켜서 모든 파티션이 하나의 컨슈머를 할당받도록 한다.
참고로 하나의 파티션에서 복수개의 컨슈머가 컨슈밍을 할 수는 없다.
데이터 저장
카프카 브로커는 데이터를 파일 시스템으로 저장한다.
카프카가 실행되면서 config/server.properties의 log.dir에 정의된 디렉토리 하위에 데이터를 저장하게 되고,
파티션 별 하나의 디렉토리를 갖게 된다.
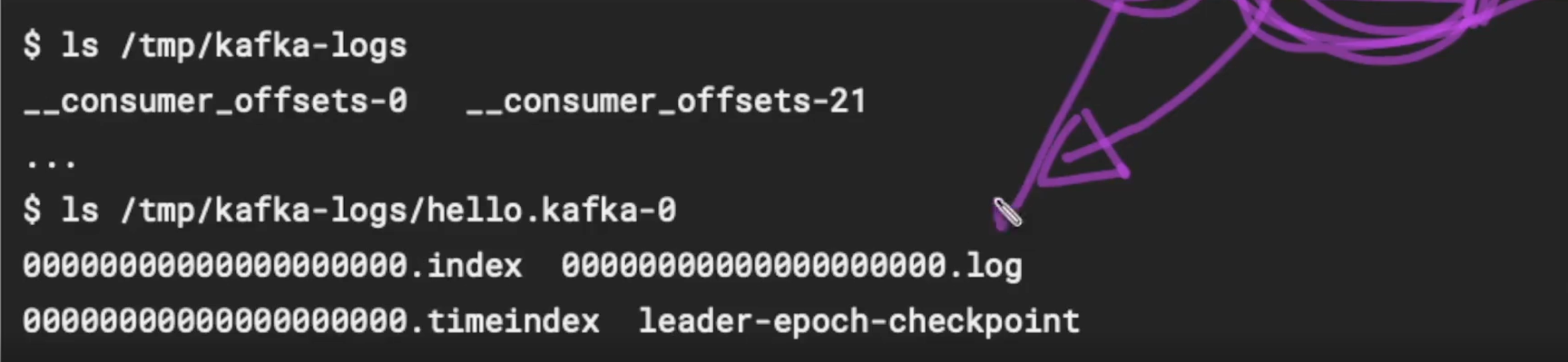
- index 파일은 오프셋으로 인덱싱한 정보가 저장된다.
- log 는 메타데이터 + 메시지
- timeindex는 timestamp로 인덱싱한 정보가 저장된다.
복제(replication)
한대의 브로커에서 장애가 발생해도 다른 브로커가 동일하게 처리가 가능하다.
이를 위해서는 브로커는 동일한 데이터를 갖고 있어야 한다.
이를 위해서 복제가 발생한다.
데이터 복제 단위는 파티션 단위로 이뤄진다.
복제 옵션은 직접 설정하는데, 최소 1대/최대 n대(브로커의 수)로 설정이 가능하다.
이 복제 옵션을 replication factor
일반적으로는 2이상의 replication factor를 사용한다. 기본값은 1이다.
토픽마다 다른 replication factor을 설정할 수도 있다.
클러스터 내 모든 브로커에 동일하게 설정되야 한다.
운영중에도 해당 값을 변경할 수 있다. -> 재설정된 브로커가 재시작된다.
replication은 파티션을 복제하는 것을 말하는데,
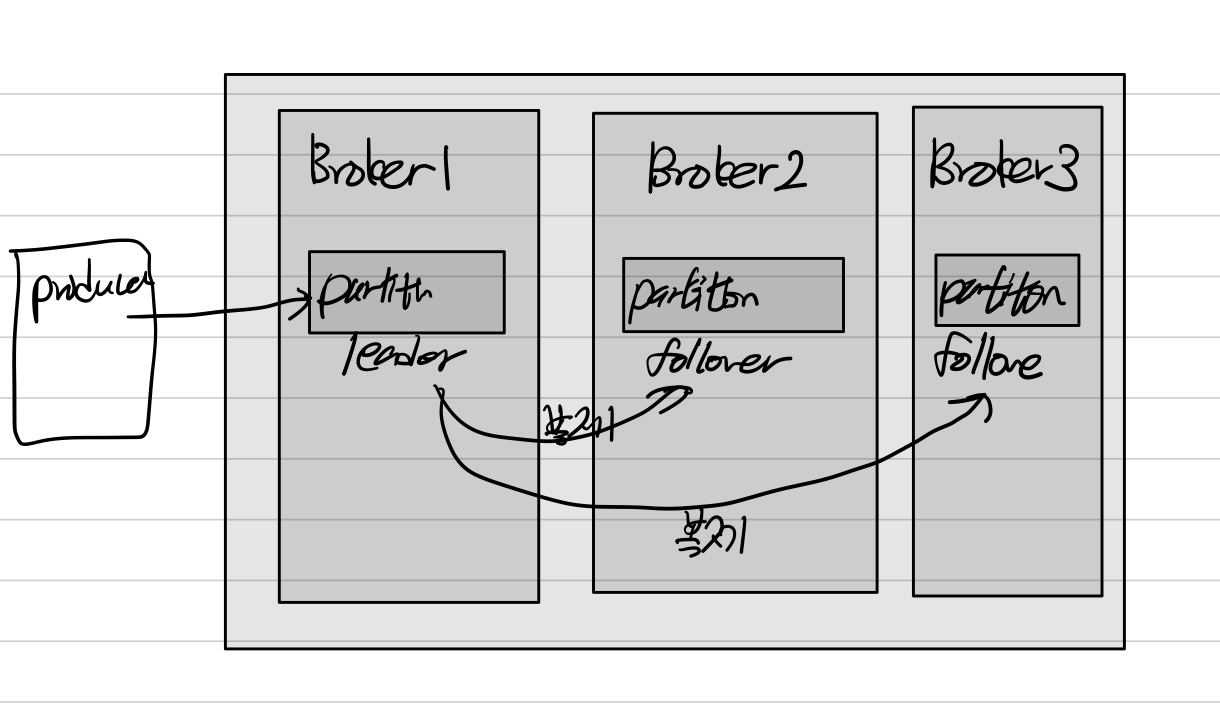
리더 파티션으로 데이터가 유입되고, 해당 파티션이 2,3번 프로커의 팔로워 파티션으로 복제된다.
마지 master-slave DB와 같이 동작한다.
리더 파티션이 프로듀서, 컨슈머와 직접 통신하는 파티션이다.
모든 읽기 쓰기가 발생하는 파티션이다.
팔로워는 리더 파티션의 복제본이다.
복제를 할때는 팔로워 파티션과 리더 파티션과의 Offset의 차이를 보고 복제여부를 결정한다.
이렇게 복제가 일어나면 브로커의 숫자만큼의 전체적인 용량이 증가하지만, 안정성이 보장된다.
카프카 클러스터를 구성하는 모든 브로커가 죽지만 않는다면, 카프카는 안정성을 보장한다.
장애대응
브로커 하나에 장애가 발생한다면, 해당 브로커의 리더파티션은 사용할 수 없다.
따라서 팔로워 파티션중에 하나가 리더 파티션이 된다.
ISR in-sync-replication
ISR은 리더파티션과 팔로워파티션이 싱크가 된 상태를 의미한다.
싱크가 됐다는 말은 동일한 데이터를 들고있다는 말이고, 각 파티션의 offset의 갯수가 같다는 말이다.
ISR이 되지 않았다는건 아직 데이터가 복제되지 않았다는 말이다.
ISR은 메카니즘적으로 피할 수가 없는데, 그 이유는 마치 복제지연과 같이 리더파티션에만 읽기/쓰기가 발생하고 팔로워파티션에는 연속적으로 복제가 발생하기 때문이다.
처음 쓰기가 리더파티션에게 발생하고, 팔로워파티션은 싱크를 확인하고 offset을 맞추기 위해서 데이터를 리더파티션에게서 가져온다.
리더 파티션에게서 팔로워 파티션이 데이터를 가져오지 못하는 경우에는 싱크가 깨져버리는데,
리더는 주기적으로 팔로워들이 자신의 데이터를 확인하고 있는지를 체크한다.
만약에 설정된 주기만큼 확인 요청이 오지 않는다면, 리더는 팔로워의 이상을 감지하고 해당 팔로워는 리더로 승급될수 없고 ISR 그룹에서 장애가 발생한 팔로워 파티션을 제외시킨다.
그러면 장애상황에서도 제외된 파티션은 리더 승급의 대상이 아니게 된다.
모든 브로커가 다운된 경우
문제는 모든 브로커가 다운된 상황이다.
1. 리더 파티션이 살아날때까지 기다린다.
2. 리더이던 팔로워 이던 살아나는 파티션이 바로 리더파티션이 된다.
1번으로 갈지 2번으로 갈지 결정하는게 unclean.leader.election.enable이다.
이 값을 true로 하면 2번으로 적용이 된다.
ISR이 깨진 상황에서도 팔로워 파티션이 리더로 승급될 수 있다.
이 경우에는 당연히 데이터 유실이 발생할 수 있다.
살아난 파티션이 리더가 아니었던 경우, 팔로워는 리더가 갖고 있는 데이터를 동일하게 갖고 있다는 보장이 없다.
false로 하면 데이터 유실을 감수하지 않고, 브로커가 복구될때까지 통신은 중단된다.
