빠름의 민족 한국인들은 홈페이지에서 천천히 게시물을 찾지 않고 무조건 검색을 활용한다!!(물론 나도..)
무수히 많은 글 목록들 중에서 내가 원하는 글을 찾기 위해서는 검색은 필수...☆
효율적인 홈페이지 제작을 위해 검색기능을 넣어봤는데 너무 신기해
우선 검색 기능을 넣기 전 전체적인 검색 흐름에 대해서 알아보자.
검색
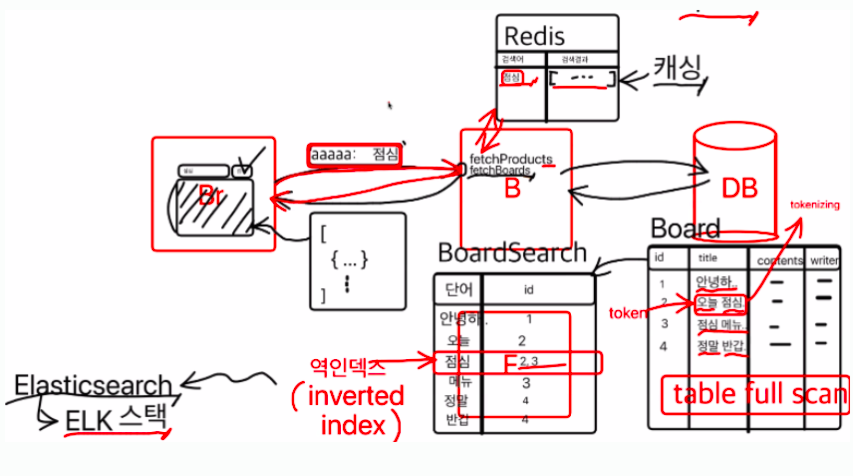
프론트엔드에서는 검색을 요청하고 요청된 페이지를 refetch를 해주게 되고,
이후 백엔드에서는 요청된 검색 관련 글을 객체로 보내준다.
관련 글을 찾아오기 위해 백엔드에서는 테이블에 있는 무수히 많은 글들을 스캔해야 하는데 이를 테이블 풀 스캔(table full scan)이라고 부른다
기존에는 주어진 문장이 있으면 단어(token)별로 나눠서(tokenizing) 단어에 맞는 id를 지정해 놓은 BoardSearch라는 것을 추가로 만들어 단어를 찾았었는데 이를 역인덱스 방식(inverted index)이라고 불렀다.
하지만 역인덱스 방식은 문장이 생길 때마다 단어를 등록해야하는 번거로움이 있기 때문에 최근에는 elasticsearch 방식(ELK 스택)이 도입되었다.
데이터베이스는 영구저장이 되는 디스크를 기반으로 하는 것이 안정적이지만 느리다는 단점이 있어
메모리를 기반으로 하는 데이터베이스인 Redis를 사용한다.
Redis는 영구저장은 아니어서 안정성이 떨어진다는 단점이 있지만 임시저장(캐싱)이 되어 자주 검색하는 단어가 저장이 되어있다면 매우 빠르게 검색이 가능하다.
따라서 백엔드에서는 Redis에서 저장되어 있는 검색어가 있는지 먼저 확인 후 있으면 바로 Redis를 통해 받아내고, 저장되어 있는 검색어가 없으면 다시 BoardSearch로 이동하여 데이터를 전해준다.
Debouncing vs Throttling
백엔드로부터 받아온 검색 내역을 프론트에서도 관리를 해야하는데
Debouncing을 사용하게 된다.
Debouncing이란 요청을 기다렸다가 요청이 끝난 후 특정시간을 기준으로 마지막에 한 번 실행되는 것을 말한다.
따라서 특정시간 이전에 요청된 내용들은 무시하게 되기 때문에
예를 들어보면
//비효율적인 예시(onChange가 실행될때마다 무수히 많은 데이터가 보내짐
const onChangeSearch = (event: ChangeEvent<HTMLInputElement>) => {
setSearch(event.target.value);
};
//효율적인 예시(onChange가 끝난 후 0.2초 후에 딱 한번 데이터가 보내짐
const getDebounce = _.debounce((aaa) => {
refetch({ search: aaa, page: 1 });
}, 200);
const onChangeSearch = (event: ChangeEvent<HTMLInputElement>) => {
getDebounce(event.target.value);
};위의 예시와 같이 debouncing을 하지 않게 되면 자음, 모음 한개씩 쓸 때마다 너어어어무 많은 데이터 보내져 매우 비효율적인 것을 볼 수 있다.
따라서 debouncing을 해주어 입력 후 몇초 뒤를 입력의 끝으로 보고 그때 데이터를 한번 보내주는 것이 매우 효율적이다.
📌 참고: setTimeout으로 직접 만들어 볼 수 있다!
Throttling이란 Debouncing과는 반대로 요청이 먼저 실행되고 기다리는 것이다.
Throttling은 무한스크롤에서 주로 사용되는데
스크롤을 내릴때 추가 데이터가 있으면 fetchMore가 요청이 되고 스크롤을 중지하여 다음 데이터가 있을 때까지 기다린다.
데이터가 없는데도 스크롤이 내려가면 비효율적이기 때문에 fetchMore가 있을 때까지 기다렸다가 요청 있으면 실행하고 기다리기를 반복한다.
