이준석 교수님의 유튜브 강의 Lec 12. RNN-based Video Models 영상을 참고해서 정리한 내용입니다. 다른 출처표기가 없는 이미지는 유튜브 영상에서 가져온 것임을 밝힙니다.
이전 포스팅에서 이어서 RNN을 이용하여 비디오 데이터를 처리하는 것을 살펴보자. 그리고 더욱 중요한 Attention 매커니즘에 대해 제대로 이해해보도록 하자.
Beyond Short Snippets
Beyond Short Snippets: Deep Networks for Video Classification은 2014년 논문이기에 비디오 쪽에서는 초창기 논문 중 하나이다. 이 당시에는 말은 영상이지만 사실상 요즘 움짤에 가까운 정도, 아주 짧은 영상 데이터만 가지고 연구를 했지만 본 연구에서는 maximum 5분짜리 영상을 가지고 연구를 진행했다.
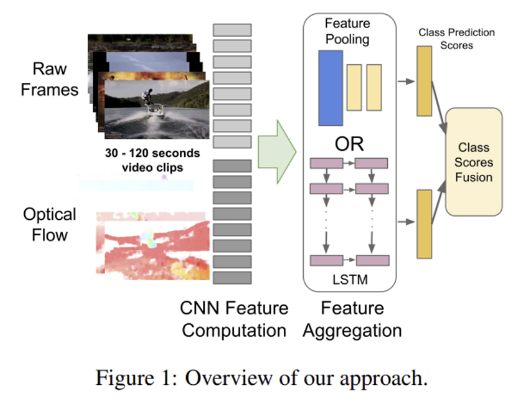
- Raw Frames - 긴 비디오인 만큼 1fps(1초에 1프레임)을 추출해서 사용
- Optical flow - 위에서 적은 프레임을 사용하다 보니 움직임 정보를 모두 잃을 것을 대비하여 15fps의 optical flow를 함께 sampling
이때 aggregation을 보면 단순히 LSTM에 넣는 것 외에도 Feature pooling의 방법을 시도하기도 했다. Feature pooling 이란 말 그대로 프레임별로 얻은 features를 어떻게 해야 전체 비디오를 나타내는 feature로 만들지에 대한 것이며, 실험적으로 여러 try를 했다.
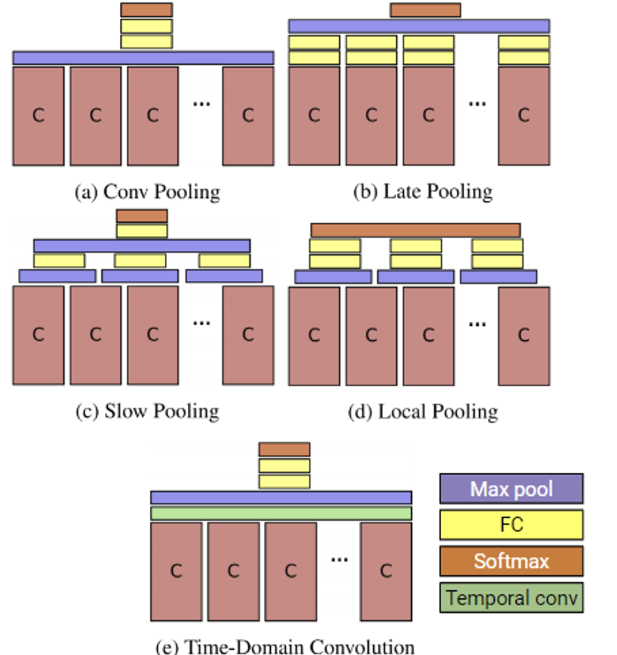
❓ (a) Conv Pooling은 Max Pooling과 동일하다. 결국 위에서 실행한 다섯 가지 pooling 실험들은 모두
Max pool을 하고 있는데, 왜average pool은 시도하지 않았을까?
생각을 해보면 여기서 사용한 데이터는 최대 5분짜리의, 상대적으로 상당히 긴 영상이다. 즉 프레임마다 장면 전환 등이 훨씬 많을 것이다. 이때 단순히 average를 취해버리면 다양한 프레임들의 정보를 잃어버릴 가능성이 높다. 따라서 max pool을 취해서 프레임마다의 중요한 정보들을 유지하고자 하는 아이디어이다.
ConvLSTM
ConvLSTM에서는 CNN + RNN인 모델이라 보면 된다. RNN 과정에서 CNN이 어디에 쓰이냐 하며는 바로..
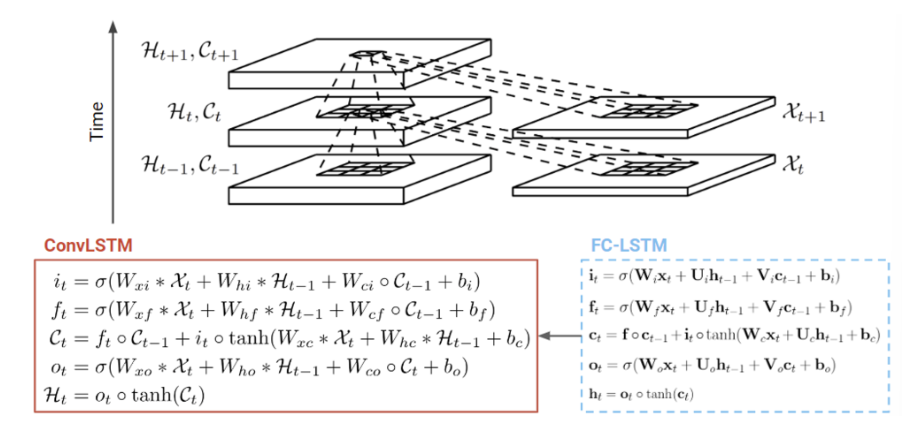
입력 데이터(x)가 주어졌을 때 기존에는 W matrix를 곱해서 사용을 했다면, 이번에는 모든 연산을 convolution (*)으로 바꿔서 수행하는 것!
따라서 x가 입력으로 들어갈 때 fc 방식으로 weight matrix를 곱하는 것이 아니라 conv 연산을 수행하여 2d로 입력된다. 그에 따라서 hidden state 인 h와 c, 그리고 세 게이트 i, f, o 또한 더이상 1차원 벡터가 아닌 2D가 된다.
🌟 Attention 🌟
Attention mechanism에 대해서 다시 한 번 정리하고 가자.
Attention function
Attention(Q, K, V) = Attention Value
Attention은 Query, Key, Value 값을 이용하여 최종적으로 attention value를 출력한다. 이때 사용되는 Query, Key, Value는 아래와 같이 정의할 수 있다.
Query: 현재 상황, ContextKey: Attention weight을 계산하기 위한 referenceValue: Attention value를 계산하기 위한 reference
즉, Query가 주어지면 그에 따른 Attention score를 계산하기 위해서 Key : Value pair를 사용한다는 의미이다. 이때 Attention score는 values의 weighted sum 이라 볼 수 있으며, 이때 weight을 계산하기 위해 key 가 사용된다.
그럼 RNN처럼 seq2seq 모델에서는 attention이 어떻게 작동할까?
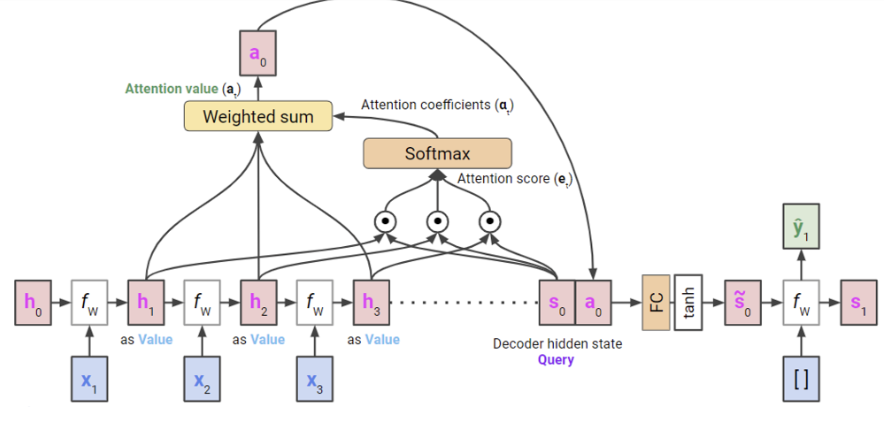
Query: 디코더의 hidden state
(Decoder는 Encoder의 모든 hidden state에 대한 정보를 압축하고 있는 상태로, 현재 output을 내야하는 단계에서의 hidden state를 쿼리로 본다.)Key: Encoder의 모든 hidden states (h1, …, hT)Value: Encoder의 모든 hidden states (h1, …, hT)
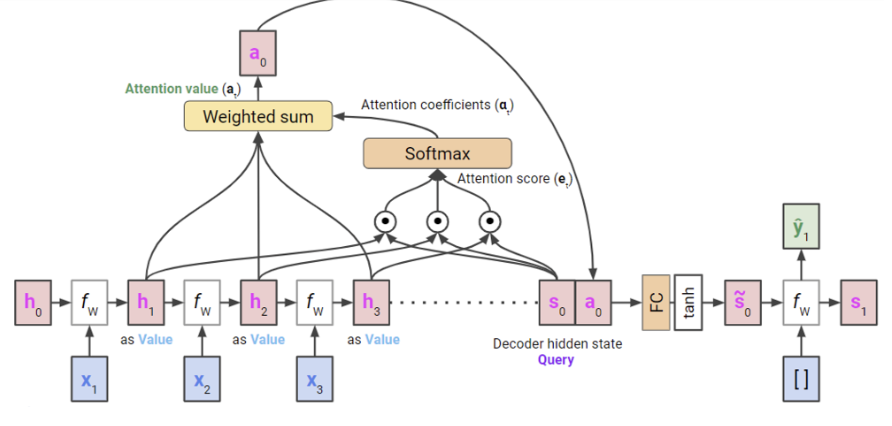
위 그림을 말로 설명해보면 다음 단계로 이루어져 있다.
-
Encoder에서 모든 입력 x에 대해 hidden state h1, h2, h3이 있다고 가정하자. 그럼 마지막 hidden state
h3은 decoder의initial hidden states0이 될 것이다. 이때 마지막 hidden state는 이전 hidden states (h1, h2)에 대한 정보를 모두 가지고 있다고 간주한다. -
여기서
Query는 현재 decoder hidden state인 s0가 된다. -
이때
Key와Value는 encoder hidden states인 h1, h2, h3가 된다. -
우선
Query와Key사이에 내적 등을 통하여 similarity를 계산한다. () -
이를 확률 값처럼 사용할 수 있도록 softmax를 취해 attention coefficients 를 구한다. 그럼 이게 value들의 weight이 된다.
-
모든
value와attention coefficients를 이용해 weighted sum을 구한다. 그럼 최종적으로 attention score인 가 나온다. -
query와 attention score를 이용하여 현재 output 를 생성한다.
Application
그럼 이 attention mechanism을 어디에 이용할 수 있을까?
우선 비디오를 다루고 있는 만큼 temporal 혹은 spatial하게 attention을 계산할 수 있을 것이다.
Temporal Attention
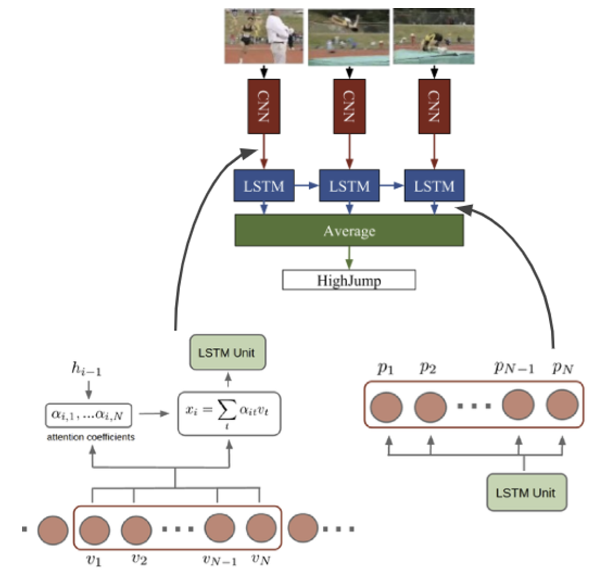
Encoding 단계에서 현재 frame을 인코딩할 때 이전 프레임까지 참고하는 모델
Query: 이전 hidden stateKey,Value: N개의 최근 input framesAttention Value: N개의 최근 input frame features의 weighted sum
Spatial Attention
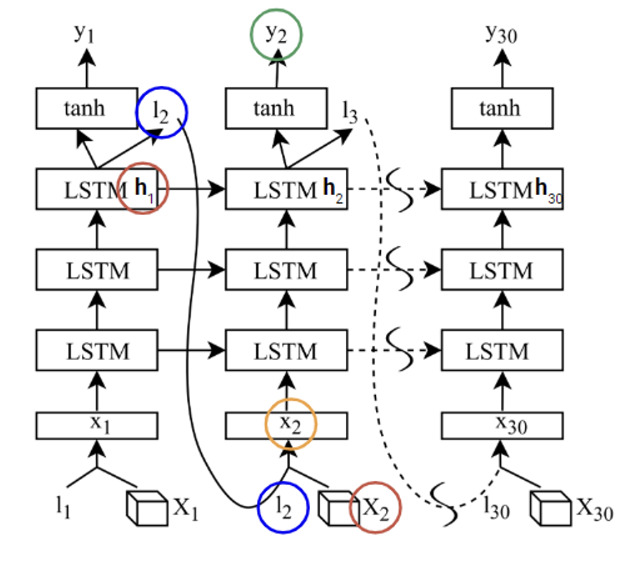
frame 상에서 공간적인 정보를 이용하여 spatial attention 수행하는 모델
Query: 이전 hidden stateKey,Value: input 에 대한 K x K regional featuresAttention Value: region features에 대한 weighted sum
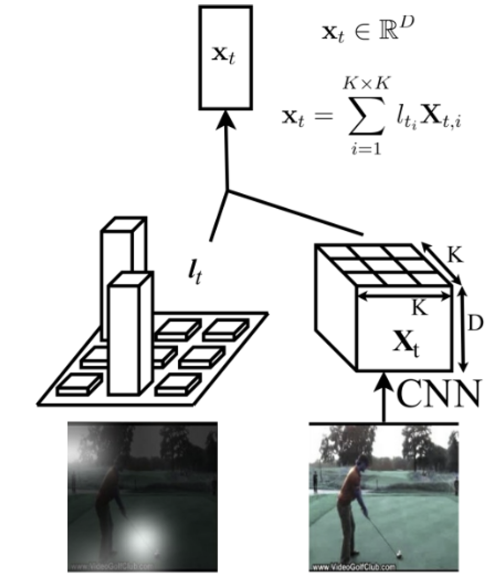
따라서 이를 해석해보면
“현재 time step이 주어졌을 때, 즉 이전 frames에 대한 semantics 정보들이 주어졌을 때, video clip을 분류하기 위해서 frame의 어느 부분에 더 attention해서 봐야하는가?” 를 결정하는 과정이다.
그렇기에 왼쪽 그림과 같이 attention이 K x K 공간 정보를 가진 feature map에서 어느 부분(픽셀)에 가중치를 더 높게/낮게 주는지를 계산한다.
이렇게 Attention에 대한 간략한 정리를 해보았다. 이어서 할 포스팅에서는 드디어 다루는 Transformer에 대해 자세히 정리해볼 예정이다. 🤔💭
