참고글: 링크텍스트
참고강의 : CS224W
그래프는 무엇인가?
정의
그래프는 점들과 그 점들을 잇는 선으로 이루어진 데이터 구조이다. 관계나 상호작용을 나타내는 데이터를 분석할 때 주로 쓰인다.
정의
V : 점 집합, E: 두 점을 잇는 선 집합
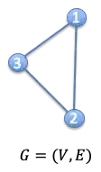
G=(V,E)
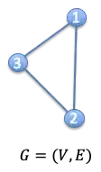
이 그래프는 G=({1,2,3},{{1,2},{2,3},{1,3}})으로 정의할 수 있다.
그래프의 자료 구조
그래프는 node(= vertex)와 edge로 구성되며 Non-Euclidean Space이다. 그래프의 자료 구조는 feature matrix 와 adjacency matrix로 표현된다.
1) Node-Feature matrix
노드 자체가 갖고 있는 feature 정보를 담은 행렬
N by D dimension
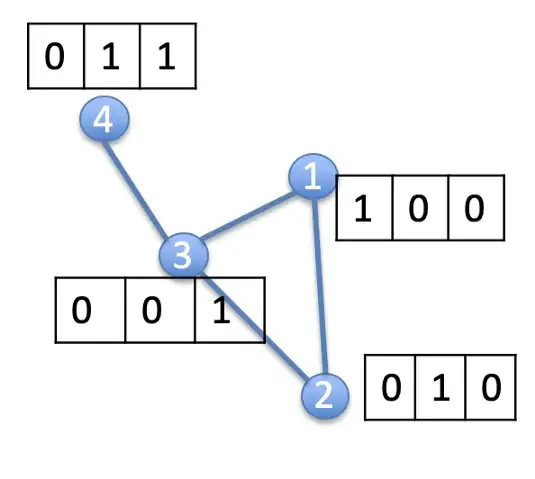
2) 인접행렬
그래프의 연결 관계를 이차원 배열로 나타내는 방식.
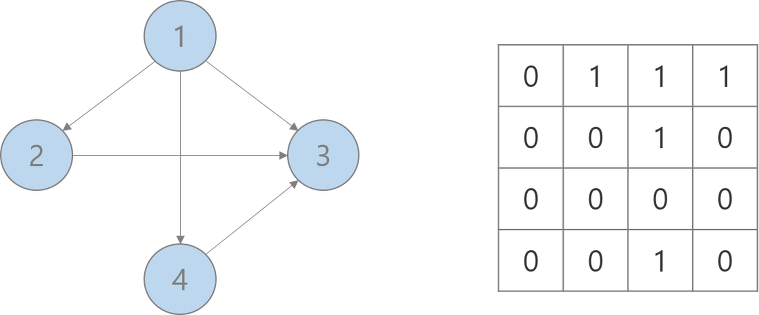
adj[i][j] : 노드 i 에서 노드 j로 가는 간선이 있으면 1, 아니면 0
Directed graph (N by N, Unsymmetric)
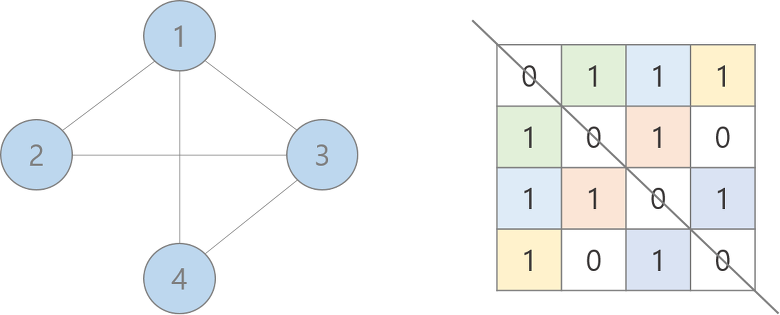
Undirected graph (N by N, Symmetric)
그래프를 왜 사용하는가?
-
관계, 상호작용과 같은 추상적인 개념을 다루기에 적합하다. 추상적인 개념을 시각화 할 때 도움이 된다.
-
소셜 네트워크, 미디어의 영향, 바이러스 확산 등을 연구하고 모델링 할 때 사용할 수 있다.
Node Embeddings
1) Traditional ML for Graphs
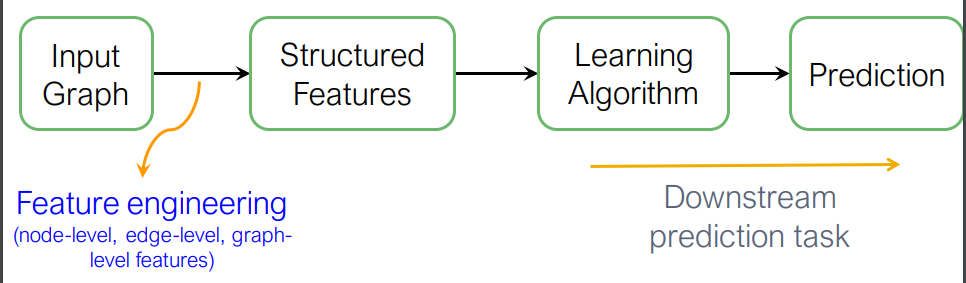
전통적인 머신러닝 기법들은 그래프를 각각의 태스크에 맞게 feature engineering하여 노드, 엣지, 그래프 레벨의 변수들을 생성했다. 이러한 방식은 각 태스크마다 새롭게 feature engineering을 진행해야 하기 때문에 비효율적이다.
2) Graph Representation Learning
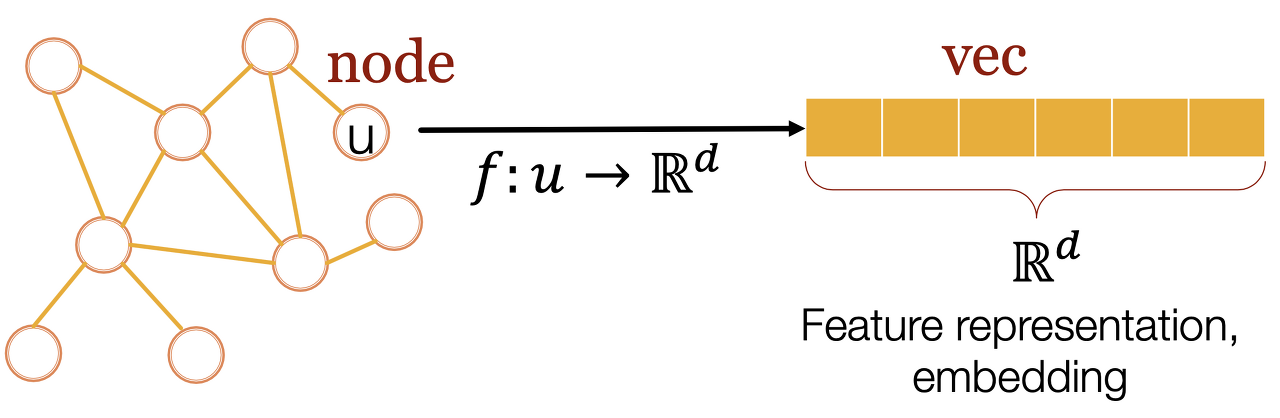
태스크마다 새롭게 feature engineering 할 필요가 없는 효율적인 방법이 필요하다(Automatically learn the features, task independent). 그래프의 구조(노드, 링크, 그래프)를 벡터로 바꾸는 Feature representation(Embedding)이 그 방법이다.
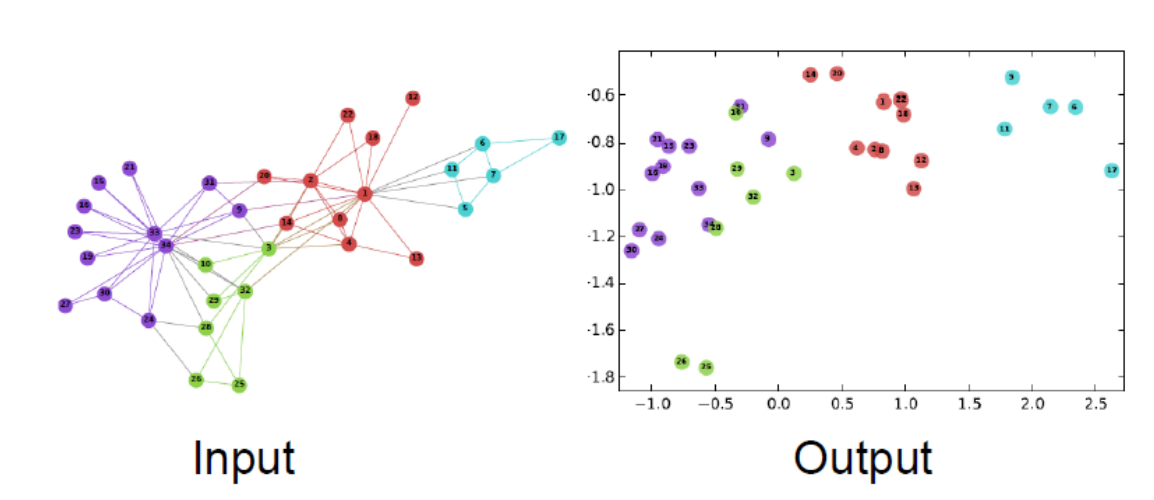
네트워크에서의 유사도가 임베딩에서의 유사도로 잘 나타낼 수 있도록 그래프의 구조를 2차원 공간에 잘 맵핑되도록 하는 작업이다.
임베딩을 하면 많은 종류의 down stream task 수행이 가능해진다.
3) Node Embeddings
goal : encode nodes so that similarity in the embedding space approximates similatity in graph
행렬의 내적으로 유사도 계산.
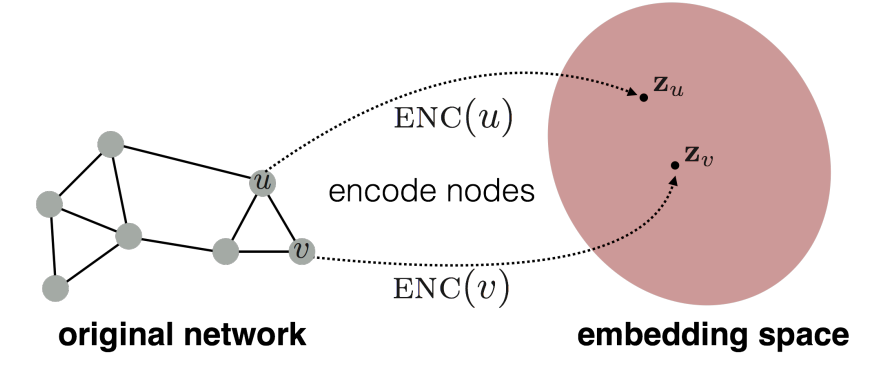
framework
1. Encoder : 인코더를 통해 각 node를 low-dimensional vector로 맵핑한다.
가장 쉬운 방법은 shallow encoding
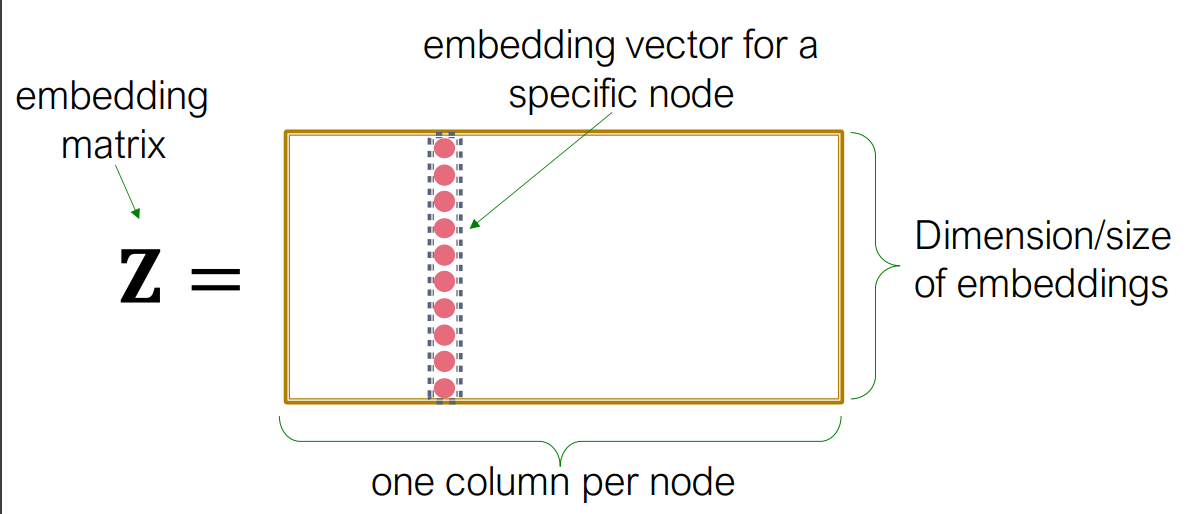
Encoder is just an embedding-lookup.(룩업 테이블에서 입력으로 주어진 인덱스의 열만 출력하는 것)
가장 간단한 방법으로, 각각의 노드가 개별적인 임베딩 벡터를 갖고 있게 되는 것이다. (we directly optimize the embedding of each node). 그러나 이는 노드 수가 많아지게 될 경우 가지고 있어야 하는 룩업 테이블이 매우 커지게 된다는 단점이 있다.
인코딩하는 다른 방법들로는 Deep walk, node2vec 등이 있다.
deep encoders -> GNNs
2. node similarity function을 정의한다.
노드의 유사도 정의 중 하나로 random walks 가 있다. 그래프의 구조를 보존하면서 직접적으로 노드들의 좌표계를 얻는 방식이다. 노드 임베딩 자체는 비지도 학습 혹은 자기지도 학습의 일종이기 때문에 노드의 레이블이나 변수들은 사용하지 않는다.
(자세한 사항은 추후 학습 예정.)
3. 디코더를 통해 임베딩을 유사도 점수로 맵핑한다.
디코더에서의 계산은 기본적으로 내적을 사용.
4. 인코더의 파라미터를 최적화 하여 original network의 유사도가 임베딩의 유사도로 근사하도록 한다.
GNN은 왜 필요한가
-
그래프는 Euclidean space상에 있지 않다. CNN, RNN 모델에서 사용하는 정형 데이터나 이미지 데이터와 다른 형태의 데이터 구조를 갖고 있다.
-
그래프는 고정된 형태가 아니다. 인접행렬은 같지만 다르게 생긴 그래프가 존재한다.
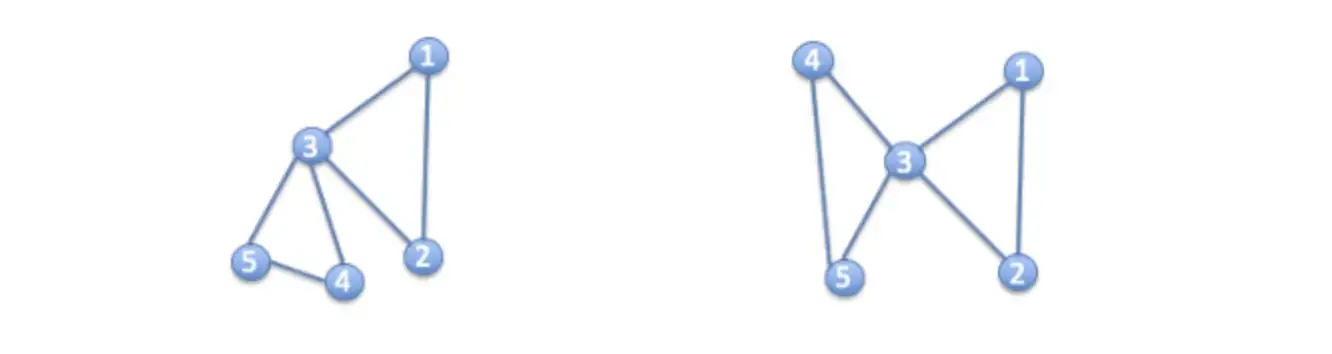
-
점의 개수가 수백, 수천개 이상이면 사람이 해석할 수 있도록 시각화 하기가 어렵다.
따라서 기존의 모델과 다르게 그래프 자료 분석에 적합한 새로운 모델이 필요하다.
이미지 출처
1. https://miro.medium.com/max/202/1*iPRiYrDqM7o6-R_VADaXAw.webp
2.https://img1.daumcdn.net/thumb/R1280x0/?scode=mtistory2&fname=https%3A%2F%2Ft1.daumcdn.net%2Fcfile%2Ftistory%2F21029250584C0F2413
3. https://sarah950716.tistory.com/12

{kind=link}