논문 리뷰 : An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (ICLR, 2021)
논문 리뷰
PDF : https://arxiv.org/pdf/2010.11929.pdf
CODE : https://github.com/google-research/vision_transformer
논문 요약
- NLP분야에서 거둔 트랜스포머의 성과와 대조되게, Vision 분야에서는 여전히 CNNs이 지배적이다. 본 논문에서는 vision분야에서 cnn모델의 사용이 필수불가결한 것이 아님을 보여준다.
- 이미지 데이터에 NLP분야에서 주로 사용되는 pure transformer 모델을 적용할 수 있고 image classification task를 매우 잘 수행하는 것을 보여준다.
- vision transformer가 많은 양의 데이터에 대하여 사전학습을 하였을 때 mid-size 혹은 small-size의 이미지 인식 task(Image Net, CIFAR-100, VTAB,etc.)에 대하여 cnn에 필적하는 매우 훌륭한 성능을 달성할 수 있음을 보여준다. 더불어 train과정에 필요한 연산 resources은 cnn보다 더 작다.
1. 이미지를 patch로 split
본 논문에서는 standard transformer모델을 최소한의 변화만 주어 이미지 데이터에 바로 적용을 했다. 이를 위해 이미지를 여러개의 patch들로 나누고 linear embedding의 sequence를 주었다. 패치들을 NLP에서의 토큰처럼 생각하는 것이다. 이 패치들이 트랜스포머모델의 Input이 된다.이미지 Classification에 대하여 모델은 supervision 방식으로 학습되었다.
2. 많은 양의 데이터를 사전학습하여 inductive bias를 극복
논문에서는 처음에는 ImageNet과 같은 mid-sized datasets을 강한 regularization없이 훈련시켰다. 그 결과 ResNets보다 몇 퍼센트 포인트 더 낮은 정확도를 보였다. 이 실험의 실패 요인을 본 논문에서는 다음과 같이 봤다.
트랜스포머모델은 cnn모델에 내제되어있는 locality, translation equivariance와 같은 inductive biases가 부족하다. 그 결과 불충분한 양의 데이터를 훈련시켰을 때 모델의 일반화성능이 떨어진다.
그러나 훨씬 더 많은 양의 데이터를 모델이 학습하게 된다면 inductive bias를 뛰어넘는다는 것을 본 논문에서 발견했다.
Vision Transformer는 충분한 양의 데이터를 사전학습한 후 각각의 태스크에 전이학습을 진행하였을 때 훌륭한 성능을 보인다.
추가) 사전지식
inductive bias
학습시에 만나보지 않았던 상황에 대해 정확한 예측을 하기 위해 사용하는 추가적인 가정이다.
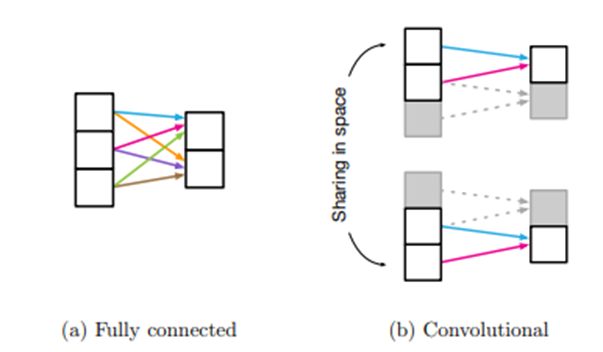
CNN의 inductive bias에는 대표적으로 Locality와 Translation Invariance가 있다.
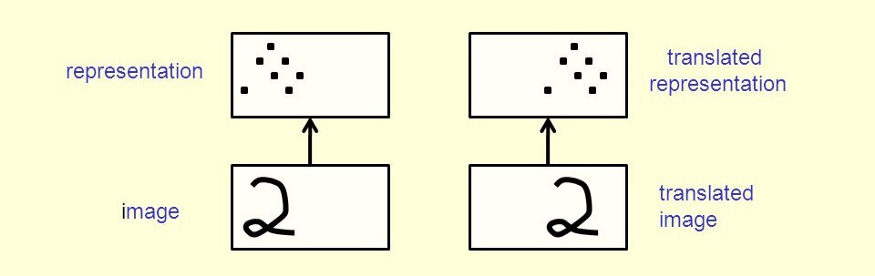
- Locality : 근접한 픽셀끼리는 종속성이 있다.
- Translation Invariance : 이동에 대해서 불변하게 하는 성질. 위치만 바뀐 동일한 사물에 대한 이미지 데이터에 대하여 같은 사물로 인식하도록 하는 성질이다.
이미지 출처 : https://towardsdatascience.com/translational-invariance-vs-translational-equivariance-f9fbc8fca63a
이미지 출처 : https://arxiv.org/pdf/1806.01261.pdf
FCN의 경우 개별 유닛들이 서로 모두 연결되어있기 떄문에 추가적인 가정이 상대적으로 덜 필요하다.

Related Work
-
Cordonnier et al.(2020) : input image에서 2*2 사이즈의 패치를 추출한 후 full-self attention 진행. VIT와 매우 유사하지만 VIT는 Large sclae pretraining이 vanila transformer가 sota인 CNN과 비슷하거나 더 나은 성능을 보임을 밝혀냄.
-
Cordonnier et al.(2020) : 2*2 픽셀의 작은 패치 사이즈를 사용하여 낮은 해상도의 이미지에만 적용 가능. VIT는 중간 해상도의 이미지도 다룰 수 있음.
-
등등 (생략)
본 논문에서는 기존의 ImageNet dataset보다 더 큰 규모의 데이터셋에서의 이미지 인식에 관심을 두고 연구를 진행하였다.
Method
Vision Transformer(VIT)
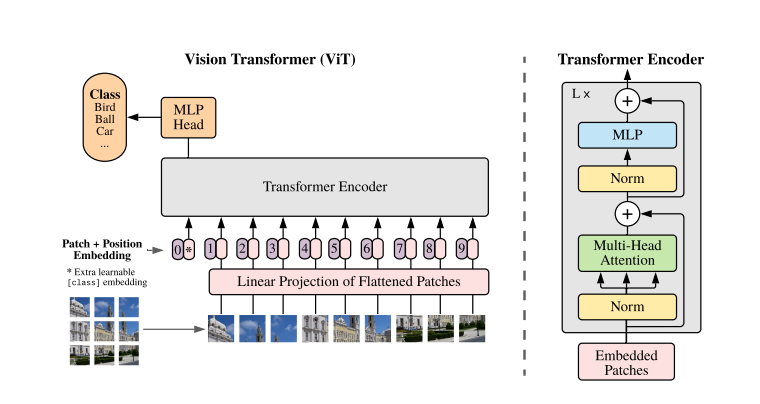
모델은 Original Transformer를 최대한 따르며 고안되었다. 그 이유는 NLP트랜스포머 아키첵쳐의 확장성과 효율적인 implementation을 그대로 VIT에 가져오기 위함이다.
1.input
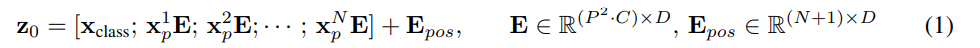
- 2D 이미지를 다루기 위해 를 로 reshape한다. ()
트랜스포머에 적합한 효율적인 Input sequence length로 바꾸어준 것이다.
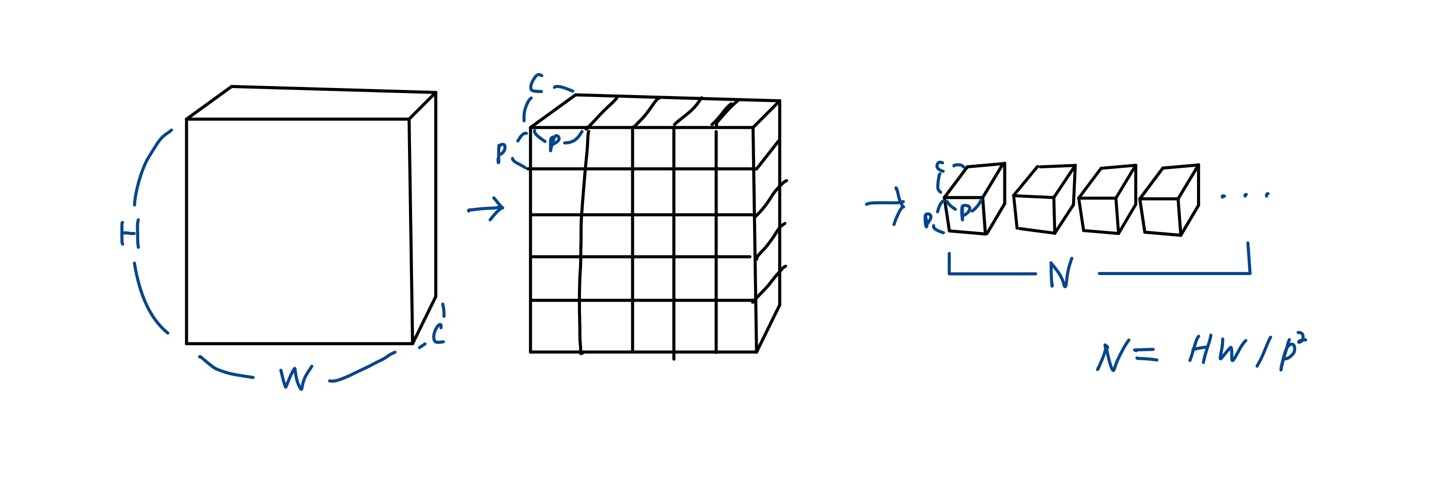
-
트랜스포머는 모든 레이어에서 유지되는 latent vector size D를 갖는다. 따라서 의 크기를 갖는 N개의 패치 각각을 학습 가능한 linear projection에 통과시켜 D 차원으로 맵핑한다. 이 과정의 결과물이 patch embedding이 된다.
-
BERT의 CLASS TOKEN과 유사하게, Patch embedding 앞에 학습 가능한 [class] embedding을 덧붙인다 (). 이 임베딩은 트랜스포머 인코더의 아웃풋에서() 이미지의 Representation y를 반환한다. pre-training과 fine-tuning과정 동안 classification head가 에 추가로 붙는다. pre-training 과정에서는 one hidden layer with MLP로 fine-tuning과정에서는 a single linear layer를 통해 구현된다.
-
위치정보를 나타내기 위해 Position embedding이 patch embedding에 더해진다. standard learnable 1D position embedding을 사용하였다. (처음에는 2D-aware position embedding을 사용했으나 큰 성능차이가 없었다고 함.) 이 과정까지 거친 임베딩 벡터가 트랜스포머 인코더의 인풋이 된다.
2. Transformer encoder structure
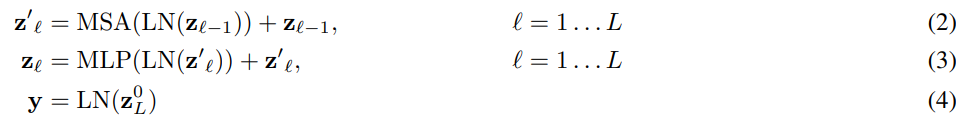
- multiheaded self-attention(MSA) block
- MLP block : MLP contains two layers with a GELU non-linearity
- Layernorm(LM) is applied before every bock
- Residual connections after every block
3. Hybrid Architecture
image patch의 다른 대안으로, CNN의 feature map을 input sequence로 사용할 수 있다. 하이브리드 모델에서는 patch embedding 대신 CNN Feature map에 projection E를 진행한다. class embedding 과 position embedding은 기존과 같은 방식으로 더해진다.
Fine-tuning And Higher Resolution
보통 VIT를 큰 데이터셋에 대하여 사전학습을 시키고, downstream task에 대하여 fine-tune을 진행하게 된다.
fine-tuning 과정에서는 pre-trained prediction head를 제거하고 0으로 초기화된 feedforward layer를 추가한다. (는 downstream task의 클래스 수)
이는 사전학습단계에서의 이미지 해상도보다 fine-tuning 단계에서의 이미지 해상도가 더 높을 때 효과적이다. ( 근거 논문 : "Fixing the train-test resolution discrepancy" )
고해상도의 이미지를 사용할 때는 패치사이즈를 동일하게 유지하여 더 긴 Sequence length를 사용한다. 다만 pre-trained 단계의 포지션 임베딩은 더이상 의미가 없기 때문에 2D interpolation(보간법)을 pre-trained position embedding에 대하여 수행한다.
(보간법 : 알려진 값 사이에 위치한 값을 추정하는 것)
해상도 조정과 patch 추출이 VIT에 인위적으로 추가된 2D IMAGE에 대한 유일한 inductive bias다
Experiments
ResNet, Vision Transformer, hybrid 모델에 대하여 representation learning capability를 평가하였다. 각 모델이 얼마만큼의 DATA를 필요로 하는지 이해하기 위해, 다양한 크기의 데이터셋들을 사전학습하였고 사전학습된 모델을 많은 벤치마크 TASK들에 전이학습하여 평가했다. pre-training 단계의 computational cost 측면에서는 VIT가 sota를 기록했다.
추가로, self-supervision을 사용하여 작은 실험을 진행하였고 self-supervised VIT가 미래에 주요한 모델이 될 가능성이 있음을 보여주었다.
Datasets
Pretrained data set
- ILSVRC-2012 IMAGENET dataset
- ImageNet-21k
- JFT
benchmark tasks
- ImageNet
- CIFAR-10/100
- Oxford-IIIT Pets
- Oxford Flowers-102
추가로 19-task VTAB classification suite에 대한 평가도 진행하였다.(적은 양의 데이터를 이용한 전이학습을 평가할 때 주로 사용됨.)
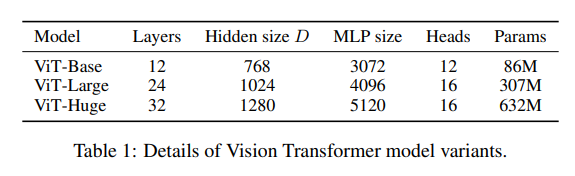
Model Variants
Comparision to State Of The Art
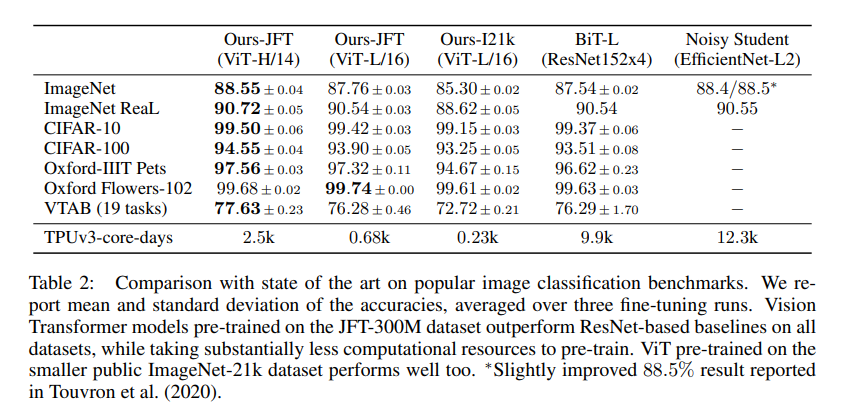
비교모델 : Bit-L (ResNet을 이용하여 supervised transfer learning 수행) , Noisy Student(EfficientNet을 이용하여 semi-supervised learning 수행)
JFT-300M dataset을 사전학습한 Vit-L/16모델이 모든 태스크에 대해서 Bit-L보다 뛰어난 성능을 보이고 있으며 연산량 또한 훨씬 낮다. 더 큰 모델인 VIT-H/14는 더욱 향상된 성능을 보여주고 있다.
Conclusion
정리해보면 기존의 연구들이 비전분야에서 Self-attention을 사용한것과 다르게 본 논문에서는 이미지를 패치들의 시퀀스로 해석하여 NLP분야에서 사용되는 스탠다드 트랜스포머모델의 인코더에 통과시켰다. 이 단순한 전략은 Large-dataset을 사전학습한 경우에 놀랍게도 뛰어난 성능을 보였다. Vision Transformer는 사전학습시 연산량을 작게 유지하면서도 image classification에서의 기존의 sota모델들에 맞먹거나 더 뛰어난 성능을 보였다.
그러나 많은 챌린지들이 여전히 남아있다. 하나는 VIT를 다른 컴퓨터 비젼 태스크들(such as detection and segmentation)에 적용하는 것이고 다른 하나는 self-supervised pre-training 방법을 계속해서 탐구하는 것이다.
앞으로의 VIT의 확장은 더 향상된 성능을 보일것으로 기대된다.
