논문 리뷰
1.논문 리뷰 : How to Read Paper

'논문 읽는법'에 대한 논문이다. 논문을 효율적으로 읽는 방법에 대해 설명하고 있다. computer science 교수님이 쓰신 논문이라, 이쪽 분야의 논문 읽기에 더 특화된 방법인 것 같다. 1. The Three-Pass Approach 논문을 3 단계에 걸쳐
2.논문 리뷰 : How Powerful Are Graph Neural Networks? (ICLR, 2019)
0. Abstract Graph Neural Networks (GNNs)는 그래프의 representation 학습에 있어서 효과적인 프레임워크다. 많은 gnn 변형 모델들이 고안되었으며 노드와 그래프 분류 문제에 있어서 뛰어난 성과를 보였다. 그러나 GNN의 혁명적인
3.논문 리뷰 : An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (ICLR, 2021)
PDF : https://arxiv.org/pdf/2010.11929.pdf CODE : https://github.com/google-research/vision_transformer 논문 요약 > - NLP분야에서 거둔 트랜스포머의 성과와 대조되게, Vision
4.[논문 리뷰] COMET : Commonsense Transformers for Automatic Knowledge Graph Construction (ACL, 2019)
PDF : https://arxiv.org/pdf/1906.05317.pdf정해진 형식(two entities with a known relation)이 있는 전통적인 knowledge base와 다르게 commonsense knowledge는 느슨하게 구조화
5.[논문 리뷰] PERCEIVER IO : A General Architecture For Structured Inputs & Outputs (ICLR, 2022)
📃 Paper : https://arxiv.org/pdf/2107.14795.pdf Introduction 지금까지 대부분의 머신러닝 연구들은 각각의 Data type과 task에 특화된 모델들을 개발하는데에 집중해왔다. Multiple Modalities를 다루
6.[논문 리뷰] Zerocap : Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic (CVPR, 2022)

📃 Paper : https://arxiv.org/pdf/2111.14447.pdf💻 Code : https://github.com/YoadTew/zero-shot-image-to-text한 줄 요약 : visual-semantic model을
7.[논문 리뷰] Rethinking the value of network pruning (ICLR, 2019)
(✨ 기존의 network pruning 방식에 의문을 제기하면서 다양한 pruning기법들을 소개하고 비교하기 때문에, 어떠한 network pruning 방식들이 연구되어왔는지 개괄적으로 살펴보기에 좋은 논문인 것 같다.)over-parameterization은 딥
8.[논문 리뷰] A Generalization of Transformer Networks to Graphs (AAAI workshop, 2021)
📃 paper: https://arxiv.org/pdf/2012.09699.pdf💻 code: https://github.com/graphdeeplearning/graphtransformerNLP분야에서 뛰어난 성능을 거둔 Transformer는
9.[논문 리뷰] Rethinking Attention with Performers (ICLR, 2021)
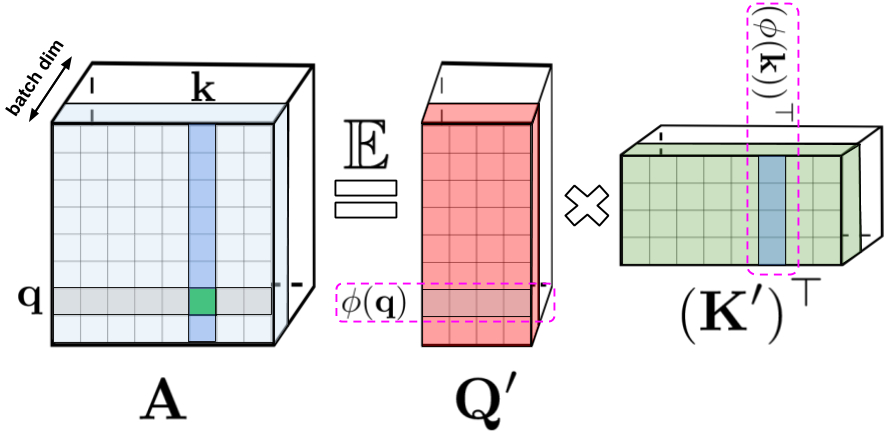
📃 paper : https://arxiv.org/pdf/2009.14794.pdfOriginal transformer model은 뛰어난 성능을 자랑하지만 quadratic한 space and time complexity를 수반하여 long-sequence
10.[논문 리뷰] HittER: Hierarchical Transformers for Knowledge Graph Embeddings (EMNLP, 2021)
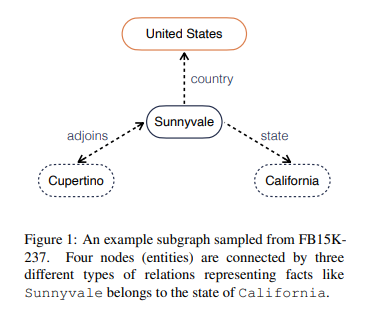
Knowledge Graph(지식 그래프)에서는 위의 그림과 같이 Entity(ex.Sunnyvale)와 Relation(ex.country)로 이루어져 있다. 지식 그래프는 subject entity(=head entity), predicate(=relation),
11.[논문 리뷰] Relphormer : Relational Graph Transformer for Knowledge Graph Representation (arXiv, 2022)
pure graph 와 다르게 knowledge graph(KG)는 여러개의 노드 타입으로 구성된 Heterogeneous graph 이다. 따라서 Transformer architecture가 KG modeling에 적합한지 여부는 아직 풀리지 않은 문제다. 구체적으
12.[논문 리뷰] SimKGC : Simple Contrastive Knowledge Graph Completion with Pre-trained Language Models (ACL, 2022)
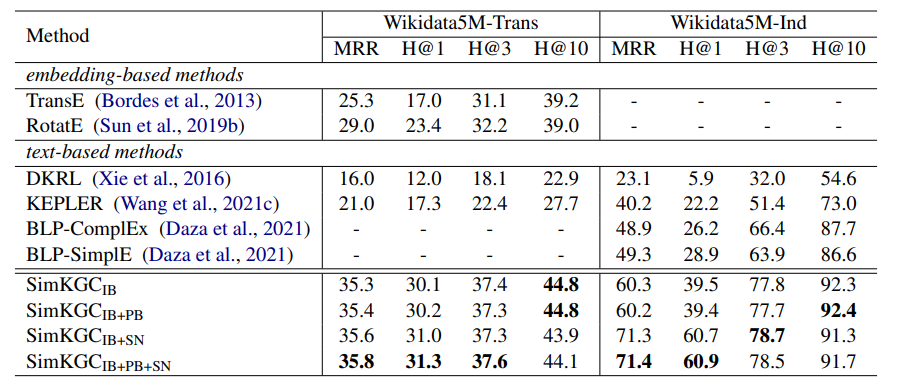
key word : Knowledge graph completion, contrastive learning, bi-encoder, BERT, 1. Introduction Knowledge graph completion 분야에서는 최근들어 Knowledge graph
13.[논문 리뷰] Do Pre-trained Models Benefit Knowledge Graph Completion? (ACL, 2022)
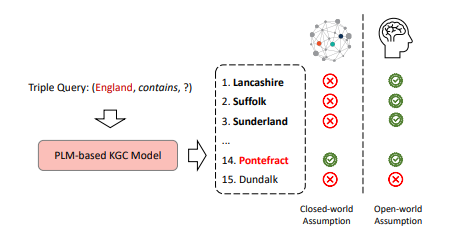
Pretrained language Models을 기반으로 하는 Knowledge graph completion Models에 대한 많은 연구가 이어져 오고 있다. 하지만 기존 연구에는 다음과 같은 문제점들이 존재한다. 1) Inaccurage evaluation se
14.[논문 리뷰] From Discrimination to Generation: Knowledge Graph Completion with Generative Transformer (WWW, 2022)
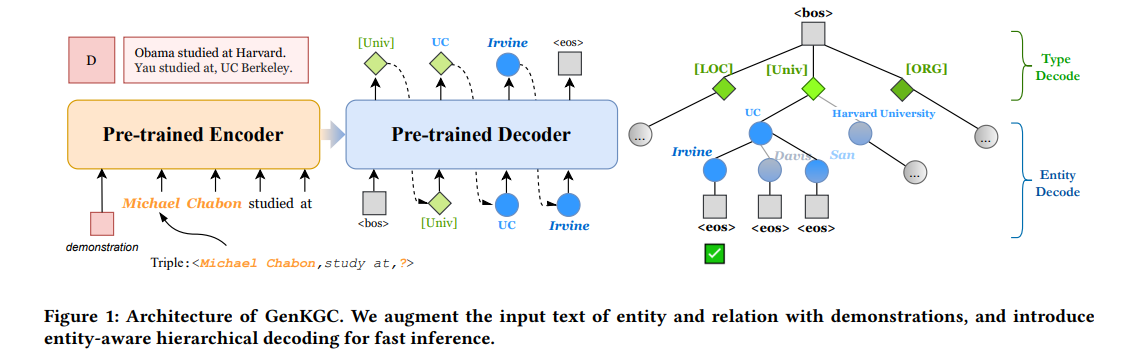
mainly target Link Prediction Propose new model named GenKGC Convert link prediction to sequence to sequence generation. Use pretrained lanuage model
15.[논문 리뷰] Text Generation from Knowledge Graphs with Graph Transformers (NACCL, 2019)
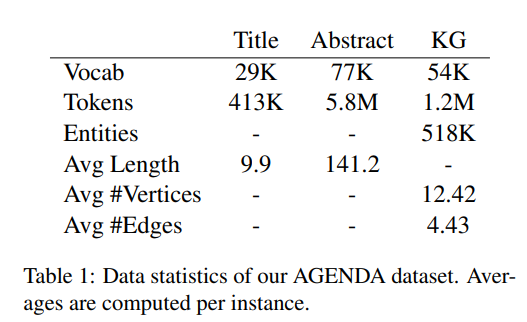
1. Introduction 컴퓨팅 파워의 증가와 모델 능력의 향상으로 문법적으로 거의 완벽한 문장 길이의 자연어 텍스트를 생성해내는 것이 가능해졌다. 그러나 Scientific writing과 같이 다양한 topic들이 관련되어 있고 처리과정이나 어떠한 현상을 설명
16.[논문 리뷰] Sequence to Sequence Knowledge graph Completion and Question Answering (ACL, 2022)

저자들은 Knowledge graph completion을 하는 method들이 아래와 같은 필요 조건들을 만족해야 좋은 모델이라고 말하고 있다. scalablility : have model size and inference time independent of the