AlexNet 이론 정리에 이어서 이번글은 Pytorch로 직접 구현을 해봤다.
블로그 참고 및 Pytorch 함수들을 공부하면서 진행했다.
Alexnet model 구현
1. AlexNet 모델 정의
- 구현에 쓰인 학습 데이터셋은 pytorch.datasets에 내장되어 있는 FashionMNIST를 사용했다.
- 논문과 다르게 입력 채널 수는 grey scale이므로 1, out_features는 데이터셋의 Class가 10개이므로 10이다.
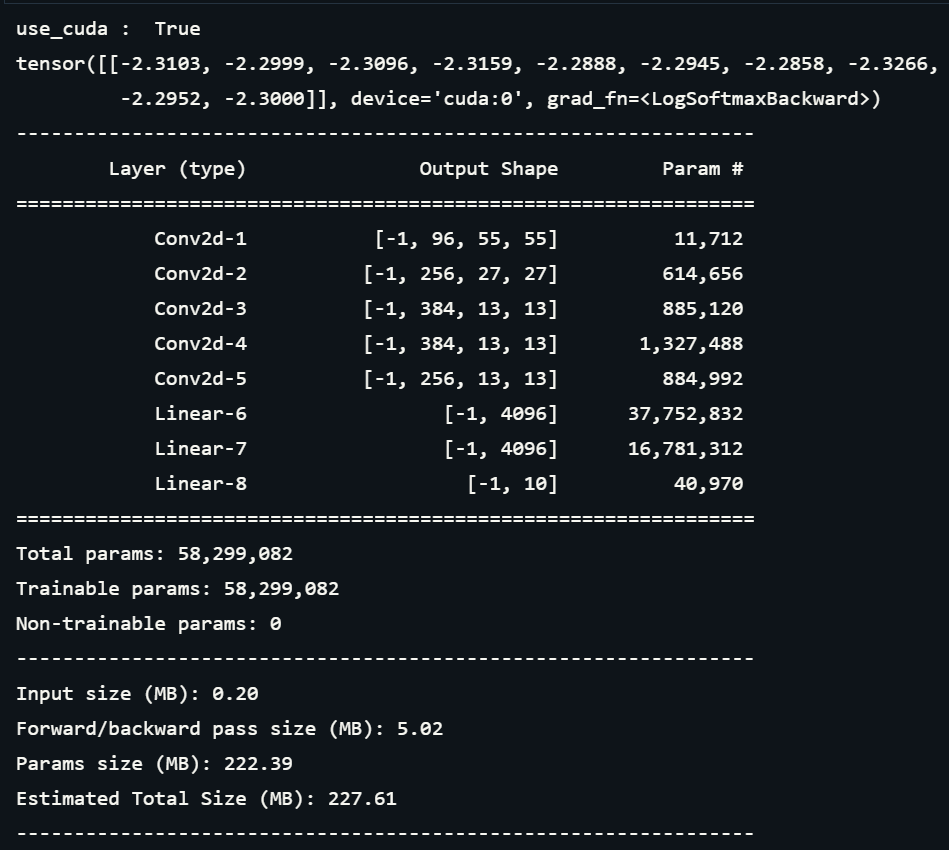
- 모델을 정의하고 마지막에 summary로 Output shape와 parameter를 확인한다.
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
from torchvision import transforms
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=96, kernel_size=11, stride=4)
self.conv2 = nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, padding=2)
self.conv3 = nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, padding=1)
self.conv4 = nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, padding=1)
self.conv5 = nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, padding=1) # conv5와 fc1 사이에 view 들어간다.
self.fc1 = nn.Linear(in_features=256 * 6 * 6, out_features=4096) # fc layer
self.fc2 = nn.Linear(in_features=4096, out_features=4096)
self.fc3 = nn.Linear(in_features=4096, out_features=10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, kernel_size=3, stride=2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, kernel_size=3, stride=2)
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
x = F.relu(self.conv5(x))
x = F.max_pool2d(x, kernel_size=3, stride=2)
x = x.view(x.size(0), -1) # 4차원을 1차원으로 펼쳐주는 층 (역할) -> flatten
x = F.relu(self.fc1(x))
x = F.dropout(x, p=0.5)
x = F.relu(self.fc2(x))
x = F.dropout(x, p=0.5)
x = F.log_softmax(self.fc3(x), dim=1)
return x
@staticmethod
def transform():
return transforms.Compose([transforms.Resize((227, 227)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.1307,), std=(0.3081,))])
if __name__ == "__main__":
# if gpu is to be used
use_cuda = torch.cuda.is_available()
print("use_cuda : ", use_cuda)
FloatTensor = torch.cuda.FloatTensor if use_cuda else torch.FloatTensor
device= torch.device("cuda:0" if use_cuda else "cpu")
net = AlexNet().to(device)
X = torch.randn(size=(1, 1, 227, 227)).type(FloatTensor)
print(net(X))
print(summary(net, (1, 227, 227))) 2. Model summary
3. Model Trainning and Test
if __name__=="__main__":
# hyper parameter
batch_size = 512
num_epochs = 20
learning_rate = 0.0001
# data load
root = './MNIST_Fashion'
transform = AlexNet.transform()
train_set = datasets.FashionMNIST(root=root, train=True, transform=transform, download=True)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=batch_size, shuffle=True)
test_set = datasets.FashionMNIST(root=root, train=False, transform=transform, download=True)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=batch_size, shuffle=True)
# if gpu is to be used
use_cuda = torch.cuda.is_available()
print("use_cuda : ", use_cuda)
device = torch.device("cuda:0" if use_cuda else "cpu")
model = AlexNet().to(device)
criterion = F.nll_loss
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
target = target.type(torch.LongTensor)
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if (batch_idx + 1) % 30 == 0:
print("Train Epoch:{} [{}/{} ({:.0f}%)]\tLoss: {:.6f}".format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target, reduction='sum').item()
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print("\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n".format(
test_loss, correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset)))
print('='*50)4. Accuracy and loss check
for epoch in range(1, num_epochs + 1):
train(model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)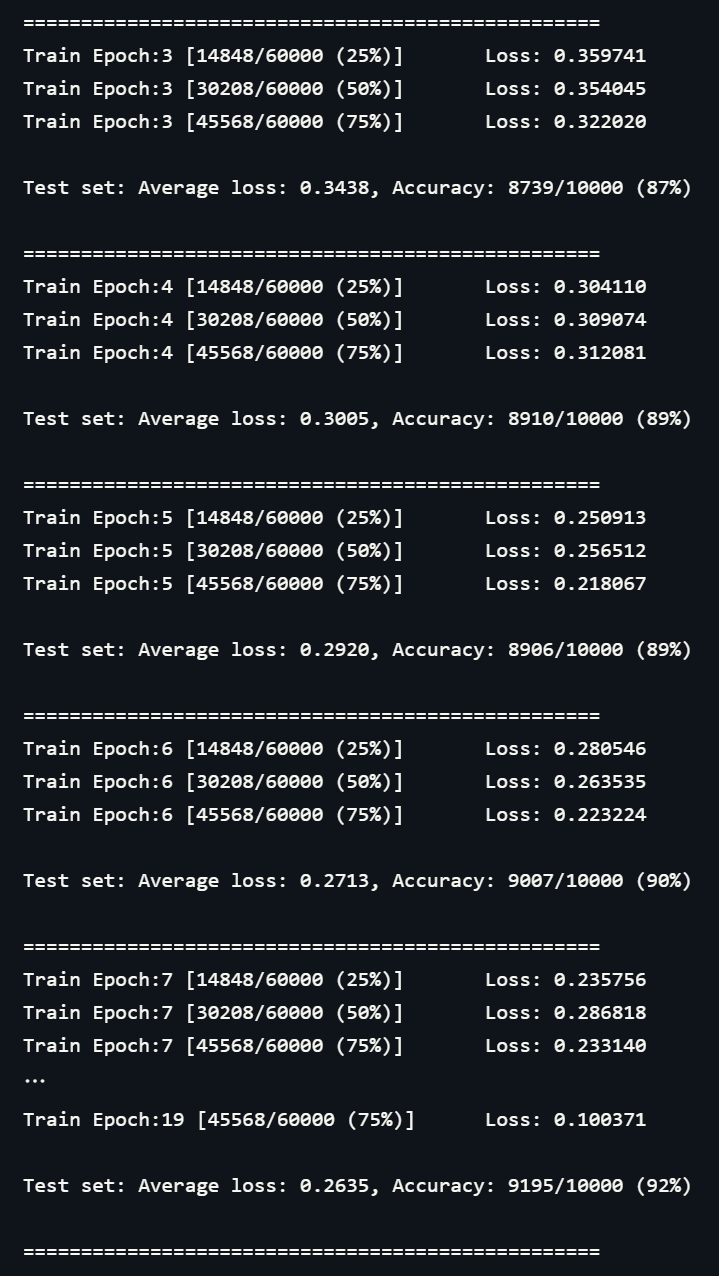
정확도 92%의 결과가 나왔다. 이것으로 Alexnet 구현을 완료했다.

성장하는 애기 개발자~
근데 이거 gpu 2대로 하는 게 아닌 것 같은데 괜찮은건가요?
보니까 conv1 에서 output 96이 그대로 나가네요.
cuda를 쓰는 것과 뭔가 관련이 있는 건가요?